평가
Amandroid를 적절히 응용하여 포렌식에서 데이터베이스 암호화 분석 자동화라는 주제로 가져온 논문이다. 우선 논문 주제를 굉장히 잘 선정했다는 생각이 든다. Amandroid가 나온 뒤, 비슷한 안드로이드 정적 분석 프레임워크들이 많이 등장하였지만, 포렌식 영역으로 가져온 연구는 없었다.
특별히 새로운 아이디어는 없었던 것으로 보이지만, 현재 연구 동향을 잘 파악하고 적절하게 잘 가져다 써서 만든 논문이다. probability model도 PRIMO라는 도구에서 아이디어를 차용하였다. 이외에도 Amandroid, IC3 등등 다른 논문에서 만든 도구를 적절히 활용하였다.
한계도 명확하다. Probability Model은 가장 가능성이 높은 1개를 선택하는데, 여기에서 오류가 발생한다. 이 부분을 약간 개선해서 새로운 도구를 만들어도 재미있겠다는 생각이 든다. 코드 난독화를 해결하지 못한다고 한다. 구체적으로 어떤 난독화는 해결 가능하고, 어떤 난독화에서 어려움이 있는지 명확히 표현하지 않은 점이 아쉽다. 또한 Amandroid에서는 Android Environment를 직접 만들어주는 과정이 있었는데, 이 논문에서는 Android Environment 내부의 코드는 고려하지 않았다고 한다. 이 부분에 대한 설명도 조금 부족한 듯하다. 도구의 코드를 공개하지 않은 것도 아쉽다.
그리고 느낌적으로 리얼-월드 앱 100개를 가져와서 정확도를 계산했다고 하였는데, 그 출처나 선정 기준이 명시되어 있지 않아 Accuracy rate를 좀 부풀려서 계산한 것은 아닌지 의심이 된다. Environment를 고려하지 않았는데 정확도가 그렇게 높을수가 있나?ㅋㅋ
문장적으로는 중국인들이 번역기를 돌리다 보니 다소 매끄럽지 않거나 이해되지 않는 문장이 많았다. 특히 주술 관계가 명확하지 않은 문장, 반복되는 문장이 많았다. 또 앞문장에서 일부 설명을 하였음에도 굳이 불필요하게 길게 쓰는? 문장이 많았다.
0. Abstract
[스마트폰 포렌식에서 안드로이드 애플리케이션에 대한 분석은 중요함. 대부분이 직접 분석하는데, 정적 분석 자동화 도구를 개발하였음.]
모바일 애플리케이션에 대한 포렌식 분석은 범죄자로부터 정보를 수집하는 데에 중요한 부분이다. 획득한 증거 데이터는 암호화된 데이터베이스에 저장되거나, 그 자체로 암호화되어 있기 때문에, 스마트폰에서 암호화된 데이터베이스에 대한 포렌식 분석은 디지털 범죄 포렌식에서 중요한 과정이다. 그러나 대부분의 데이터베이스에 대한 포렌식 분석은 특정 모바일 앱에 집중한다. 게다가 포렌식 수사의 수요를 충족하기 위해서는 적절한 런타임 환경이 세팅되어야 하기 때문에 동적 분석을 자동화하기도 어렵다.
This paper
정적 분석을 기반으로 데이터베이스 암호화 포렌식 방법을 소개한다. 특정 애플리케이션에 한정되지 않고, 자동화된 분석 기능을 가진다. 안드로이드 애플리케이션에 대한 역 분석을 수행하기 위해 설치 패키지를 이용하고, 프로그램 간 control flow chart를 구성하고, control flow chart를 기반으로 data flow graph를 구성한다. 이 그래프를 기반으로 데이터베이스 암호화 방법이 발견된다. 안드로이드에서 암호화된 데이터에 대한 분석을 자동화할 수 있는 시스템도 구현하였다.
우리의 방법은 self-mad probability 모델을 이용하고 control flow chart와 data flow chart로부터 데이터베이스 암호화를 찾는 알고리즘을 이용하여 정적 분석의 어려움들을 극복하였다. 마지막으로, 우리는 100개의 안드로이드 애플리케이션을 이용하여 검증하였고, 총 39.6 시간만에 성공하였다. 705개의 암호화된 데이터베이스를 찾아내었고, 584개의 데이터베이스 암호화 방법을 발견하여 82.9%의 정확도를 가졌다.
1. Introduction
[DB 암호화에 대한 자동화된 분석이 중요함. 수동 분석, 동적 분석에는 각각의 단점이 있는데, 자동화된 분석은 이를 극복함.]
스마트폰 엄청 많이 씀. 애플리케이션에서 엄청난 개인정보를 다루고 로컬 DB에 저장함. 범죄자 증거도 많이 저장되기 때문에 로컬 저장소의 DB를 분석하는 것은 모바일 기기에 대한 포렌식에서 중요함.
다양한 앱들의 암호화된 데이터베이스들을 분석하기 위해 여러 노력들이 있었음. 일반적인 방법은 직접 리버싱하는 것임. 이 방법은 단점들이 있음.
1) 특정 앱 이외에는 넓게 적용될 수 없음. 버전이 업데이트되면 암호화 라이브러리도 사용 불가능. 2) 애플리케이션들이 너무 복잡해져서, 직접 분석이 어려워짐. 대신 동적 분석이 인기를 얻고 있음. 후킹 등 기법을 이용해서 데이터베이스 패스워드를 가진 함수를 추적하는 것임. 그러나 테스트 환경의 차이가 결과에 영향을 줄 수 있음. 정확성을 확신하기 위해서 다양한 테스트 환경이 필요함. 그러나, 테스트 환경 구성에서 오류가 있을 수 있고, 그래서 정확하지 않을 수 있음.
따라서 모바일 애플리케이션에 대한 자동화된 분석을 해야 됨. 이 논문에서 정적 분석을 통해 안드로이드 애플리케이션에 대한 포렌식 분석 자동화 기법을 소개할 것이다. 우리의 기법은 직접 하는 리버싱과 동적 분석의 단점을 극복한다. 특히 많은 애플리케이션에 확장 가능하다, 인간의 간섭이 필요없고 시간이 적게 걸리기 때문에. 추가적으로 테스트 환경에 대한 고려가 필요하지 않다.
[ICC 통신 분석이라는 챌린지를 해결하기 위해서 CFG와 DFG를 구성하고, probability model을 활용하여 ICFG, IDFG를 구성한다. 그리하여 DB 암호화 방법을 식별할 수 있다]
그러나 정적 분석에도 어려움이 있다. 안드로이드는 컴포넌트-기반의 시스템이기 때문에 컴포넌트-간 통신(ICC)을 이용한다(이게 분석하기 어렵다). 이 문제를 해결하기 위해 안드로이드 애플리케이션의 암호화 방법을 발견할 수 있는 컴포넌트-간 정적 분석 도구를 제시한다. APK를 인풋으로 받아서 Control Flow Graph(CFG)와 Data Flow Graph(DFG)를 구성한다. 이후에는 probability model을 이용해서 컴포넌트들의 호출 순서를 추론하고자 하였다. 그렇게 하면 Inter-component control flow graph(ICFG)를 구성하여 APK 전체의 데이터 의존성와 컨트롤 관계, Inter-component Data Flow Graph(IDFG)를 파악할 수 있다. 데이터베이스 암호화 방법을 ICFG와 IDFG를 넘나들며 알아낼 수 있다. 우리의 방법은 데이터베이스 암호화 방법을 정적 분석을 이용해서 알아내고, 정적 분석이 가지는 문제들을 극복하였다.
Contribution
1) 데이터베이스 암호화 방법을 자동으로 식별하기 위해서 정적 포렌식 기법을 제시.
2) ICC 문제를, 직접 만든 probability model을 결합하여 극복하였고, 정확도를 개선하였음. probability model을 통해, components들의 호출 순서를 추론할 수 있었고, IDFG와 ICFG를 생성하는 시간을 줄여주면서, 정확도도 높였다.
2. Related Work
[자동 분석임을 강조. Amandroid에 기반하고 있지만, content provider component 분석 및 복잡한 ICC 메소드 분석을 지원한다는 차별점이 있음. 다른 연구들에 대해서도 implicit stream과 reflection call processing을 고려한다는 장점이 있음. Primo의 probability model을 차용하였음.]
안드로이드 애플리케이션에서 생성하는 데이터베이스의 암호화 scheme을 알아내기 위한 자동화 연구는 처음이다. 안드로이드 애플리케이션에 대해서 데이터베이스 암호화 방법을 알아내기 위한 연구는 여태껏 많았다. 그러나 수동 분석이었다. 현재 버전 밖에 적용되지 않는 한계가 있다.
게다가 덜 유명한 애플리케이션일지라도 포렌식적으로 의미가 있는 데이터가 있는 경우에는 연구 가치가 있다. 포켓몬Go의 경우에는 실시간 사용자의 위치 정보를 담고 있어 매우 가치가 있으나, 연구 자료와 포렌식 인력의 부족으로 DB 저장 위치를 확신하기 어렵다.
우리의 연구 디자인은 Amandroid의 여러 방법들에(environment 생성 과정 중에 callback collection algorithm) 기초하고 있으나, 중요한 차이가 있다. Amandroid는 정확한 CFG를 생성하기 위해 FlowDroid를 사용한다. 그리고 DDG를 이용하여 ICFG와 IDFG를 생성한다.
우리의 연구는 content provider component를 분석할 수 있고, 복잡한 ICC 메소드(such as startActivityForResult() and bindService()) 분석 기능을 지원한다는 점에서 차이가 있다. 따라서 Amandroid는 content provider component나 이러한 복잡한 ICC 함수로부터의 데이터 유출을 탐지하지 못한다.
WeChecker은 process, context, objects, fields에 sensitive한 정확한 도구이다. ICC의 intent를 분석함으로써 call chain을 만든다. 또한 context-sensitive한 alias 분석을 통해 변수에 대한 정확한 추정을 한다. 그러나, implicit stream과 reflection call processing을 고려하지 않는다. 이건 우리 도구가 참 잘한다.
DroidSafe는 ~~ 하지만 implicit stream 추적과 reflection methods를 처리하지 못한다. 그 밖에도 여러 연구들이 있었는데, ICC 기반의 개인정보 유출은 탐지하지 못했다. link 추론에 대한 여러 연구들이 false positive를 많이 만들었다.
Primo는 probability model을 통해 true positives가 될 수 있는 가능성에 기반한 정적 분석을 통해 개연성 있는 연결을 추론하였다. probability model을 이용해 ICC intent를 추론하는 것이 false positives를 줄이고, ICC 추론의 정확성을 높인다.
3. Research Background
3.1. Database Encryption Method
안드로이드 애플리케이션에서 사용하는 데이터베이스는 SQLite이다. 저장 경로는 data/data/package/database 폴더이고, root 권한을 통해 DB를 획득 가능하다. 데이터 암호화는 일반적으로 2개의 방법을 통해 이루어진다.
1) 데이터베이스가 암호화 키를 통해 암호화되는 방식.
2) 저장되는 데이터가 암호화되고, 모바일 기기의 시그니처가 암호화하려는 데이터와 함께 사용되어 암호화되는 방식.
3.2. Motivating Example
Wechat의 코드 조각을 통해, 가능성을 엿보려고 한다.

우리 분석 방법의 핵심은 키-암호화 명령어의 파라미터, 그리고 그것의 생성 경로를 결정하는 것이다(openDatabase()의 두 번째 파라미터와 같은). data flow analysis를 통해 data 의존성을 분석하여 이것을 달성할 수 있다.
정적 분석을 통해 이루고자 하는 목표는 IDFG와 ICFG를 만들고, data 의존성과 control 관계를 분석하여, 애플리케이션의 데이터 흐름 분석을 하는 것이다.
3.3. ICC Problem
[implicit intents를 모두 처리하면, 오버헤드가 발생하여 적절한 필터링 기법이 필요하다 -> 앞으로 설명하겠지]
Component, ICC, Intent, Intent filter에 대한 기초 설명(생략)
ICC는 source 컴포넌트의 intent와 target 컴포넌트의 intent filter의 매치이다. 매치는 field values가 같은지를 비교하는 과정을 통해 결정된다. 대부분의 기존 연구는 ICC 문제를 target 컴포넌트에 대한 식별로 풀어나갔다. explicit intent와는 달리, implicit intents는 가능한 컴포넌트가 여러개이다. 일반적으로 implicit intent는 보수적으로, 조건을 만족하는 모든 컴포넌트가 적당한 컴포넌트라고 가정하여 다루어진다. 그러나 이것은 상당한 오버헤드를 가져오고, false alarm rate를 증가시킨다. implicit intents에 대한 적절한 필터링 방법을 연구하는 것이 필요하다.
4. Approach
4.1. Overview
[개괄. 2가지 기능이 있는데, 1) IDFG와 ICFG를 구축하는 것. 2) 리포트를 생성하여, 리포트 바탕으로 암호화 방법을 찾는 것]
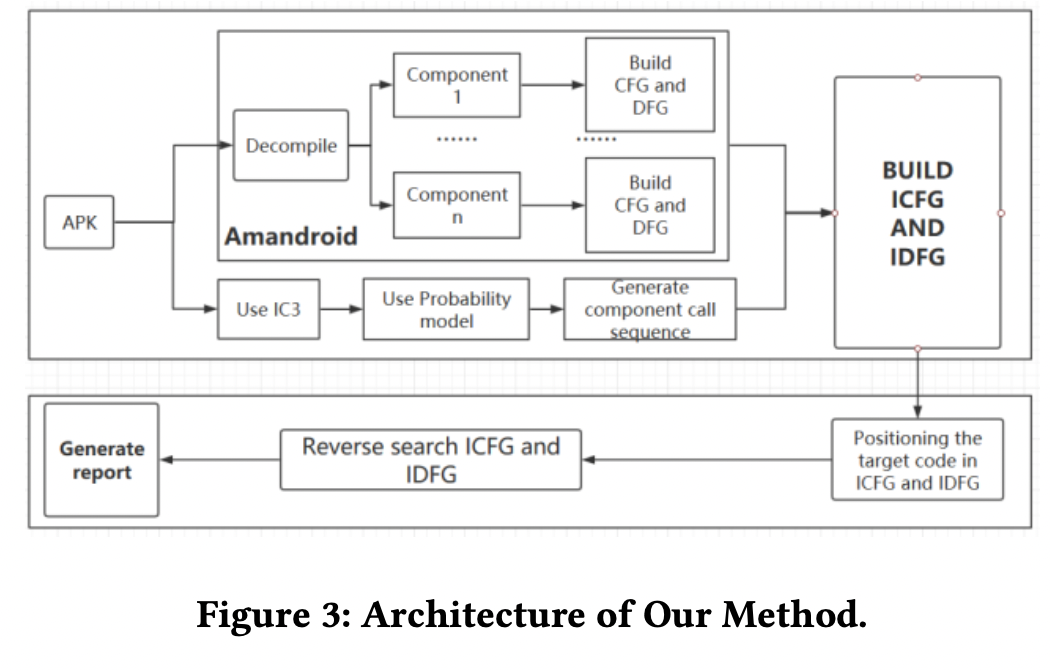
2가지 기능이 있다. 첫 번째는 IDFG와 ICFG를 구축하는 기능이다. 여기에서는 Amandroid를 이용해서 DDG와 CFG를 빌드한다. 그런 후에는 probability model을 이용해서 ICC 문제를 해결하여 target component를 추론한다. 가능성이 높은 컴포넌트 calling sequence 를 분석하고, 각 컴포넌트의 DDG와 CFG를 결합하여, 여러개의 가능성 있는 IDFG와 ICFG를 빌드한다.
두 번째는 ICFG와 IDFG를 바탕으로 암호화 scheme을 찾는 일이다. 결과적으로 데이터베이스 암호화가 적용된 방식이 리포트의 형태로 나오게 된다. 리포트를 역으로 살펴 보면서 복호화 과정을 알 수 있게 된다.
우리의 방법은 결과 리포트를 생성하는데, 데이터베이스 암호화 방법과 scheme을 찾을 수 있도록 분석되어 있다. 데이터베이스 암호화 키를 사용하는 경우에는, 리포트를 key의 재생성에 이용한다. 데이터베이스에 쓰여지기 전에 암호화가 수행된 경우에는, 키를 이용하여 복호화된 데이터베이스로부터 반환될 수 있다(??, 맥락상 이상함)
4.2. Optimizing Algorithms for Generating IDFG and ICFG Based on Probability Model
[연구의 핵심 부분. 연구가 전반적으로 Amandroid에 기반하고 있으나, ICC 처리에 있어 미흡한 부분이 있는 것을, 연구팀에서 probability model을 개발하여 보완함. 여기 부분이 probability model을 어떻게 설계하고 계산하는지에 대한 설명. intent와 intent filter의 각 필드 값들을 비교해서 같은 값이 많을 수록 probability가 높다고 가정함. 결과를 도출하여 가장 가능성 높은 1개를 target component로 가정하고, Amandroid의 원래 ICC 추론 결과를 대체하는 방법으로 결과를 이용함.]
우리의 연구는 Amandroid에 기반한다. 첫 번째로 각 컴포넌트의 DFG를 빌드하고, 그것을 기반으로 DDG를 빌드한다. Amandroid는 ICC를 함수 호출처럼 취급하고, ICC에 기반하여 DDG를 다른 컴포넌트와 연관시키는 IDFG를 빌드한다. 그러나 Amandroid는 constant propagation(?)을 문자열에 대해서만 수행하고, 문자열 연산에 대해서 보수적인 모델을 사용한다. 이러한 한계가 부정확한 intent를 만드는데, 따라서 IDFG가 정확하지 않을 수 있다. 3.3에서 언급했듯이, ICC의 매칭은 통신에 사용된 intent의 필드들과, 타겟 컴포넌트의 intent filter에 있는 필드들의 매치이다. 따라서 ICC를 추론하기 위해서는 intent와 intent filter에 있는 필드들에 대한 추론을 마무리해야 한다. IC3 도구를 이용하는데, intent와 intent filter의 필드값을 추론하는 도구임. IC3는 정확하지는 않은데, 우리는 probability model을 이용해서 IC3의 추론 결과를 기반으로 intent와 intent filter 간의 매칭 가능성을 계산하고자 하였다.
probability model은 이러한 가정 하에 만들어졌다. intent와 intent filter 사이에 더 많은 비슷한 필드가 있을수록, 매칭 확률이 더 높다. 아래 정의를 참고.
Definition 1 : 랜덤한 변수 I1 ... In 은 intent에 존재할 것이라고 I3가 추론한 변수. 랜덤한 변수 f1 ... fn 은 intent filter에 존재할 것이라고 I3가 추론한 변수.
Definition 2 : intent와 intent filter는 각각의 필드 값들의 집합으로 대표됨. intent I = (I1 .. In), intent filter f = f1 ... fn.
Definition 3 : I3 추론의 2가지 결과가 있는데, 결정된 값의 경우에는 "value"와 같이 표시되고, 정확히 추론하지 못한 경우에는 ""와 같이 표시된다.
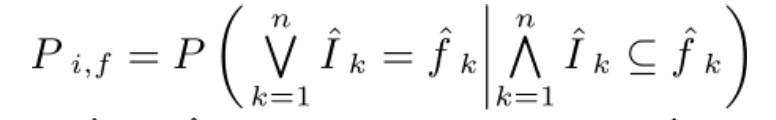
수식의 구체적인 내용은 잘 이해하지 못했음.
주차장 검색 애플리케이션을 통해 예시를 들고, 어떻게 어떻게 계산하여, 어떻게 어떻게 probability model을 한다는 예시 부분(생략).
intent가 각각의 intent filter와 매치될 수 있는 가능성을 계산하고, 그 결과가 정렬된다. 가장 높은 가능성을 가진 intent filter가 target component로 선택된다. 계산 결과는 calling sequence를 생성하는 데에 사용되고, Amandroid에서 ICC를 분석한 결과가 이 계산으로 대체된다. Amandroid가 각 컴포넌트의 DFG, CFG를 IDFG, ICFG로 생성하는 데에 이용된다.
4.3. Reverse Searching Algorithm of Encrypting Database Key Generation
[opendatabase()를 통한 Algorithm1 예시를 통해 데이터베이스 암호화 방법을 찾는 reverse search 알고리즘을 설명. DDG, IDFG, IR을 이용하여 패스워드가 들어가는 파라미터를 역추적함. Algorithm1을 보면 함수가 재귀적으로 구성되어서 끝(constant, 파라미터 없는 함수)에 도달하면 리포트에 추가하는 것을 볼 수 있다.]
데이터베이스 암호화는 1) 키를 통한 암호화 2) 내용 자체가 암호화, 두 가지 방법에 따라 이루어진다. 데이터베이스 암호화에서 서로 다른 패턴들이 사용되기 때문에 조사가 필요했다. 안드로이드 애플리케이션은 특정 명령어를 통해 데이터베이스 암호화를 수행하기 때문에, 관련된 명령어를 추적하고자 했다. ICFG를 target으로부터 거꾸로 검색하고 파라미터를 결정짓는 방법을 통해 목표를 달성할 수 있었다. 검색은 IDFG나 암호화를 가리키는 오브젝트의 끝에 도달하면 종료되었다.
1) 패스워드를 통한 암호화를 수행하는 경우에는, 패스워드와 패스워드의 생성 경로를 알고자 했다. Algorithm 1는 opendatabase라는 명령어를 이용하여 패스워드 생성 경로를 식별한다. 명령어(opendatabase)의 2번째 파라미터는 패스워드이다. 우리의 알고리즘은 애플리케이션의 DDG, IDFG, IR을 필요로 한다. DDG는 IDFG에서 커맨드의 위치를 찾아내기 위해 사용된다. 커맨드의 위치를 찾아내는 것은 어렵지 않은데, IR의 모든 커맨드가 unique number을 가지고, 이것이 IDFG의 노드와 대응하기 때문이다.
다음으로는 opendatabase를 호출한 함수를 찾아낸다. DDG의 패스워드가 그것의 source(dd)를 찾기 위해서 추적된다. dd가 constant인 경우에는 추적이 중단되고, output report에 추가된다. dd가 파라미터가 있는 함수인 경우에는, 함수가 report에 추가되고, DDG 내부에서 parameter들의 소스에 대한 추적이 계속 진행된다. dd가 파라미터가 없는 함수인 경우에는 함수가 report에 추가되고 추적이 중단된다. dd가 호출한 함수의 파라미터인 경우에는 dd의 값을 결정하기 위해서 IDFG 내부에서 추적한다. searchidfg는 dd를 호출자의 코드 위치에서 추적하기 위한 목적을 가진다. 이렇게 하여 패스워드의 소스와 생성 경로가 모두 결정되고, 리포트에 기록된다.

(패스워드가 아니라) 암호화된 데이터를 데이터베이스에 기록하는 경우에는, 암호화된 데이터의 생성 경로를 알아내야 한다. 알고리즘 1이 유사하게 이용될 수 있다. 안드로이드 애플리케이셔는 암호화된 데이터를 기록할 때에 insert()라는 명령어를 이용하는데, 여기에서 2번째 파라미터가 데이터이다. DDG, IDFG, IR을 이용하여 데이터의 소스와 생성 경로를 알아낼 수 있다.
5. Evaluation
100개의 안드로이드 애플리케이션과 20개의 직접 만든 애플리케이션을 이용하여 테스트
이러이러한 부분에 초점을 맞추었음.
(1) 데이터베이스 암호화 경로를 찾는데의 효과성에 대한 검증
(2) ICC 문제를 해결하는 데에 우리 연구의 해결책의 효과성에 대한 검증
(3) 우리 도구와 다른 도구 간의 시간 소요와 정확성의 비교
(4) 실패한 경우들에 대한 분석
5.2.1. (1)
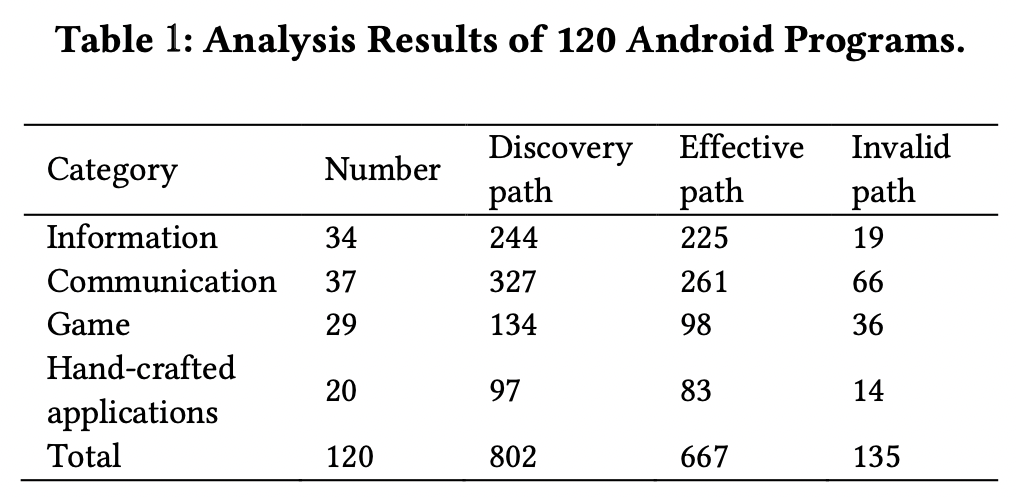
Invalid path는 직접 분석한 것에 비해서 도구가 경로를 제대로 찾지 못한 경우인데, 여러 개의 target intents를 가지는 경우에서 주로 일어났다. probability model의 한계라고 볼 수 있다.
5.2.2. (2)
ICCTA와 PRIMO와 비교하였다. 비교를 위해서는 Droid-Bench를 이용하였다. 벤치마크는 테스트를 위해 직접 만든 앱들로 진행되었고, 직접 만들었기 때문에 신뢰성은 조금 떨어질 수 있다.
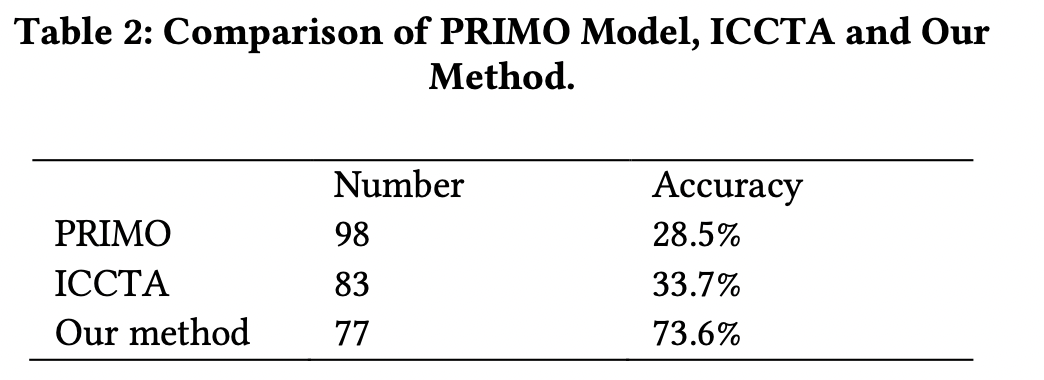
Accuracy는 TP/(TP + FP)로 계산되었는데, TP는 true positives, FP는 False positives이다. 우리의 도구가 다른 도구들보다 훨씬 높은 결과를 가져왔는데, 그 이유는 우리의 도구가 probability model을 사용하기 때문에 fake intent link를 줄여주기 때문이다.
(조작 냄새가 좀 나는데,,,)
5.2.3. (3)
Amandroid, Fordroid, Droidsafe, Droidrista와 비교하였다. 100개의 실제 애플리케이션에서 ICFG, IDFG를 추출하는데에 걸리는 시간을 비교하였다. 또한 ICFG와 IDFG를 교차로 참고하면서 암호화 프로그램의 경로를 구하였다. 마지막으로 우리는 직접 데이터베이스 암호화 방법을 생성하였다. 우리는 암호화 방법의 유효성으로 Accuracy를 측정하였다.
(ICFG, IDFG를 각 도구별로 생성하고, 4.3.에서 언급한 reverse search를 적용하여 암호화 방법을 추론함. 그 결과와 직접 매뉴얼하게 분석한 암호화 방법을 비교하여 Accuracy rate를 측정했다는 말인듯.)
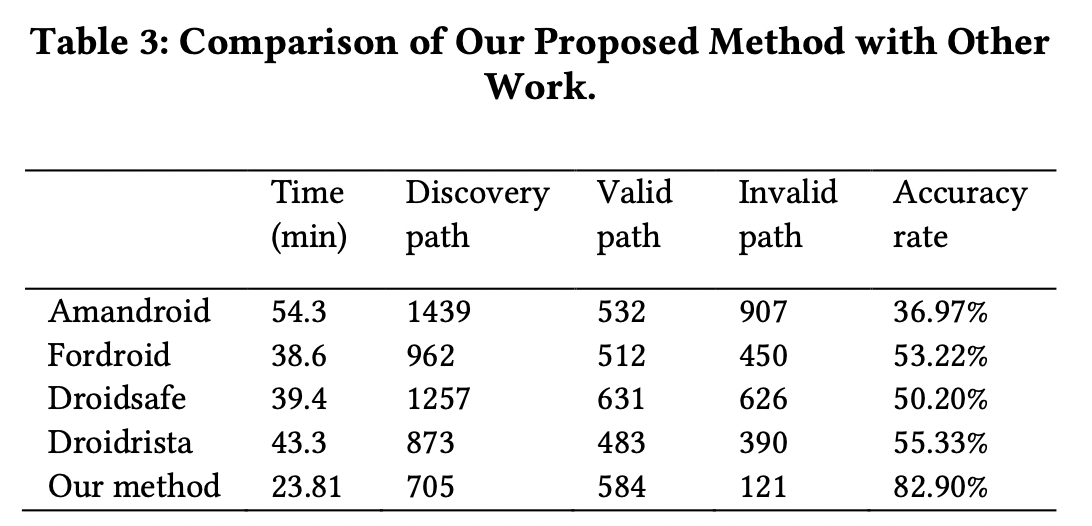
우리가 시간도 제일 조금 걸렸는데, 그 이유는 probability model을 이용한 것이 시간을 줄여주었기 때문이다. 정확도도 우리의 도구가 제일 높은데, 다른 도구들의 IDFG, ICFG는 실제 실현가능성이 부족하기 때문이다. 우리의 도구는 probability model을 이용하여 가장 가능성이 높은 IDFG, ICFG를 선택할 수 있다.
5.2.4. (4)
Table 1.에서 135개의 실패 케이스에 대하여, 그 이유는..
1) 분석 시간이 너무 길었고, 가능한 암호화 경로가 너무 많았다. 우리의 data flow 분석은 보수적인 입장을 취하였고, DFG의 조건 경로는 기본적으로 접근 가능했다(??) 이것이 가능한 암호화 경로를 빼먹을 가능성을 줄였으나, 출력되는 결과의 양을 늘렸다. -> 이게 실패케이스랑 무슨 상관이야.. ㅋㅋ
2) 안티-리버싱 기술의 존재가 실패의 또다른 이유였다. 실제 몇몇 애플리케이션들은 code obfuscation을 이용하기 때문에, 실패한 경우들이 있었다.
5.3. Result and Discussion
[한계, 알아낸 점.]
Table 1에서 검증 과정을 하다 보니, 어떤 경로들은 실제 상황과 벗어난 것으로 밝혀졌다. 실패 결과들을 분석해 보니, 여러개의 target intents를 가진 상황으로 밝혀졌다. ICC 문제를 해결하기 위한 probability model의 한계점으로 보인다. 가장 가능성이 높은 1개만 선택하다 보니, 실제 target components를 놓치게 되고, 결과로 출력하지 못한 것이다.
100개의 실제 애플리케이션을 분석해보니, 1) 75.6% 앱의 데이터베이스 암호화는 하나의 컴포넌트에서 이루어졌다. 따라서 컴포넌트 간 통신 문제는 암호화 분석 결과에 큰 영향을 미치지 않았다. 2) 데이터베이스로 암호화된 데이터의 소스(68.3%)는 휴대폰의 시그니처(IMEI)였다. 따라서 포렌식 수사에서 IMEI를 획득하는 것이 중요할 것이다. 3) 11.4%의 데이터베이스는 암호화되지 않은 경우가 있었고, 3.61%의 데이터베이스는 컨텐츠가 암호화되었다. 4) 대부분의 데이터베이스 암호화는 키, 데이터 암호화의 조합을 사용하였다(?) 5) 우리의 방법은 82.9% 정확도로 성공하였고, 데이터베이스 암호화 방법을 알 수 있었다.
그러나 분석 방법은 여전히 한계가 있다, 특히 reverse analysis 과정에서이다. 현재 앱들은 꽤나 성숙한 정도의 anti-reverse 방법을 가지고 있다. 또한 안드로이드 애플리케이션들은 종종 안드로이드 environment 내의 코드를 실행할 때가 있는데, 우리의 분석은 프로그램 내부의 코드에만 초점을 맞췄다. 안드로이드 environment 코드에서의 실행은 완벽한 분석을 지원하지 않을 것이다. 이 상황을 해결하기 위해 추후에는 안드로이드 environment에 대한 분석 라이브러리를 확장할 것이다.
6. Conclusions
안드로이드 애플리케이션에 대한 수동 분석은 시간을 많이 소비하고, 확장 가능성이 없다. 우리는 자동화된 정적 분석 프로그램을 개발하였다. 우리의 방법은 직접 만든 probability model을 이용하여 정적 분석의 한계를 극복하였고, CFG와 DFG로부터 데이터베이스 암호화 방법을 찾아내기 위해 특별히 검색 알고리즘을 개발하였다. 모든 애플리케이션에 대한 분석은 39.6 시간이 걸렸으며, 100개의 앱으로부터 총 705개의 ㅇ마호화된 데이터베이스를 발견하였다. 우리의 방법은 그 중에서 584개, 82.9%의 정확도로 데이터베이스의 암호화 방법을 찾아낼 수 있었다.
