Forensic Analysis in Access Control: Foundations and a Case-Study from Practice
Reading Papers
평가
무려 ACM CCS 2020에 실린 포렌식 논문이다. 이론적 기반이 탄탄하지 않아 숨이 턱턱 막히는 듯 하였으나,, 내가 모자란 것이라고 생각하고 참으면서 읽었다. 너무 어렵다..
주제가 참 좋다. 접근 통제 시스템에서 포렌식 수행을 논의하는데, 3가지의 scheme의 예시를 들어서 각각 설명하였다. 크게 2가지의 갈래로 나뉘는데 1) 계산적 복잡도 측정 2) 목적-지향형 로깅이다. 1)은 사실 왜 필요한지 깊게 이해하지는 못했다. safety 분석의 관점에서 포렌식 분석을 설명하는데, safety 분석의 계산적 복잡도 클래스와 포렌식 분석에서의 계산적 복잡도 클래스가 3개의 접근 통제 scheme에서 모두 일치했다고 한다. 그리고 그 과정에서 safety 분석의 분석 방법을 통해 포렌식 사건을 인스턴스화하는 접근도 새로웠다. ⟨𝛾,𝜓,𝑘,𝑞,𝜋,𝐿⟩(각각 current state, state-change rule, known past, query, actual or possible, Log). 수사관이 원하는 조사 방향(무죄를 주는 것 or 유죄를 증명하는 것)에 따라서 𝜋를 possible이나 actual 중에 선택할 수 있고, 보다 적은 로그를 사용하더라도 효율적인 조사가 가능했다.
한편, 2)의 목적-지향형 로깅은 정말 가치있다고 본다. 대부분의 시스템에서 대용량 로깅을 하지만 포렌식에서 어떻게 사용할 것인지, 미리 계산하거나 예측하려는 시도를 하는 경우는 보지 못한 것 같다. 로깅을 할 때에도 나중에 어떻게 사용될 것인지 미리 고려해서 충분하면서도 최소화된 로그를 남기는 것이 중요할 것이다.
마지막으로,, 글을 쓰는 방식이 너무 어렵고 장황하다. 설명하는 방식이 추상화되고 매우 어려운 표현을 우선 쓴 다음에 항상 예시를 드는 방식이었는데, 예시는 이해할만 했지만 추상화된 표현이 문장도 다소 길고 와닿지 않는, 붕 떠있는 듯한 표현을 쓰는 경우가 많았다. 다만 모든 전개에서 앞으로 ~~를 설명하겠다를 명시해주는 것은 이해에 큰 도움이 되었다.
0. Abstract
[목표-지향적인 로깅을 위한 연구. 접근 통제의 3가지 scheme에 대한 포렌식 분석을 하기 위해 충분하면서도 소규모의 로깅 방법을 제시함.]
(오.. 주제 진짜 좋다..)
접근 통제 시스템의 맥락에서의 포렌식을 이전 연구에서 수행하지 않은 방식으로 수행하였다. 포렌식은 시스템의 과거 상태에 대한 질문에 대한 대답을 추구하고, 그렇기 때문에 보안 이벤트의 중요한 흔적과 증거들을 제공한다. 접근 통제는 누가 자원에 어떤 액션을 취할 수 있는지를 다루고, 중요한 보안적 기능이다. 우리의 초점은 잠재적으로 신뢰할 수 없는 사용자에게 권한 부여 상태의 변경을 위임할 수 있는 액세스 제어 시스템입니다. 접근 제어의 맥락이 포렌식 분석을 고려해야할 중요한 것이고, 그것이 안전성 조사의 자연스러운 보충 역할을 한다(?). 우리는 이러한 접근제어 시스템에서의 포렌식 문제를 추상적으로 제시하고, 3개의 scheme으로 예를 들어 설명한다 : a well-known access matrix scheme, a role-based scheme, and a discretionary scheme. 우리는 포렌식적 분석의 계산적 복잡성을 식별하고, 각 scheme의 safety 분석의 (복잡성)과 비교하였다(??). 우리는 로그의 의미들도 고려했는데, 포렌식 분석을 돕기 위해서 시간을 걸쳐 수집되는 그런 로그들. 우리는 3가지 scheme을 위한 포렌식 분석에 효율성을 제공하는 충분하면서도 소규모된 로그에 대한 결과를 발표했다. 이것이 목표-지향적인 로깅에 대한 논의를 하게 하였고, 포렌식 분석을 돕는다는 명확한 의도와 함께. 서버 없는 클라우드 애플리케이션의 현실적인 세팅에서 케이스-스터디를 진행하였고, 목표-지향적인 로깅이 고도의 효율성을 띄는 것을 발견하였다.
1. Introduction
[접근 통제와 포렌식, 서로 연관되어 있음.]
정보보안의 큰 2가지의 주제를 결합한다, 포렌식 분석과 접근 통제, 이전 연구가 하지 않았던 방식으로. 포렌식은 과거 시스템에 대한 질문을 대답하기를 추구한다. 넓게 collection, preservation, analysis, presentation으로 나눌 수 있다. 정보보안의 관점에서 포렌식은 수사관이 범죄 현장에서 직면하는 문제와 유사합니다.
접근 통제는 보안 주체가 자원에 대해 실행할 수 있는 행동을 다룬다. 시스템 보안의 중요한 측면으로 여겨진다. 운영체제의 프로세스와 같은 보안 주체가, 디지털 파일과 같은 자원에, 읽기나 쓰기와 같은 행위를 실행하려고 할 때, 접근 통제는 시도가 가능하도록 보장한다. mediator가 사용하는 권한 정책은 시도가 허락되어야 하는지 결정하기 위해 사용된다. 실제 시스템에서 이러한 권한 정책은 시간에 따라 변환될 수 있다.
접근 통제와 포렌식(감사와 같은)이 얽혀있을 수 있음을, 얽혀있음을 인정하는 정보보안의 긴 역사가 있다. Lampson이 회고를 제공한다. 예를 들어 그는 보안 사고의 이벤트에서 수사적 목적으로 로그를 유지하는 것에 대한 접근 통제의 중요성을 강조했다.
Forensics vs safety
[Forensics와 safety(safety 분석)과의 관계. safety 분석은 예방을 통한 보안의 한 분야인데, 권한 위임 정책을 사전 점검하여 바람직하지 않은 접근이 미래에 일어나지 않도록 예방하는 것임. 포렌식은 과거의 사건을 통해 침해가 있었는지를 나타낸다는 점에서, safety 분석의 예방적 메커니즘에 통찰력을 제공한다.]
(별거 아닌 말을 더럽게 어렵게 쓰네;;)
우리의 관심은 상태가 변화하는 시스템으로 여겨지는 접근통제 시스템에서의 포렌식이다. 예를 들면 권한의 상태가 시간에 따라 계속해서 변하는 시스템. 그러한 시스템에서 특정한 시점의 권한 정책은 순간의 상태로 여겨진다. 이것은 safety 분석에 내재된 마음가짐과 동일한데, 접근 통제에서 잘-연구된 문제이다. Section 6에서 얘기할 때에, 접근 통제를 위한 safety 분석에 대한 상당한 연구가 있다. safety 분석 뒤에 숨겨진 의도는 바람직하지 않은 접근이 미래에 어떤 시점에 권한 정책을 바꾸는 어떤 일련의 행동들로 인해 권한을 가지게 되지는 않는지 결정하는 것이다.
safety 분석은 위임에 의해 동기부여 된다: 완전히 신뢰되지 않는 유저가 권한을 바꿀 수 있는 권한. 위임은 따라서 접근 권한을 확장하려는 욕구에 의해 동기화 된다. - 권한을 변경하기 위해 몇몇의 전적으로 믿을 만한 유저에게 의지하는 것은 많은 숫자의 유저와 자원들에게 확장되지 않는다. 정말로 이러한 safety 분석이 바람직하지 않은 상태가 미래에 도달할 것이라고 밝혀낸다면, 우리는 현재의 권한 정책을 변경하기를 원하거나, 완전히 신뢰할 수 없는 유저가 권한을 바꾸도록 허락되는 변경의 속성을 변경하기를 원할 것이다. 그리하여 그러한 바람직하지 않은 상태에 도달할 수 있는 가능성이 배제될 수 있다.
safety 분석은 예방을 통한 보안의 한 분야이다, 그것은 우리의 시스템이 안전하지 않은 상태가 아니라고 확신하는 것이다. 불행하게도 예방이 시스템을 안전하게하는 전반적인 접근의 일부분임에도, 그것은 때때로 불충분하다고 여겨진다. 그것에는 2가지 이유가 있다. 첫 번째는 우리가 시스템이 도달하지 못하도록 배제하고 싶은 바람직하지 못한 상태의 집합을 특징짓는 것이 언제가 가능하지는 않기 때문이다. 다른 하나는 우리가 그러한 집합을 특징지을 수 있다고 하더라도, 내재하는 분석의 문제가 아주 다루기 힘들거나, 결정짓기 힘들지도 모른다는 것이다.
예방을 통한 보안의 상호 보완적인 접근은, 탐지를 통한 보안이다 - 침입이 일어났다는 탐지. 침입자를 찾거나 책임을 묻게 하는 등의 조치가 취해질 수 있다. 또한 이것은 미래의 비슷한 침입들을 배제할 수 있게 하기 위한 예방적 메커니즘에 통찰력을 줄 수도 있다. 포렌식은 탐지를 통한 보안의 일부분이다. 포렌식 분석의 맥락에서 우리가 제시하는 질문은 과거의 시스템이 위반을 나타내는지 아닌지와 연관된다, 우리의 현재 마음가짐에 연관하여, 사건이 있은 다음에. 따라서 접근 통제의 관점으로부터 포렌식 분석은 safety 분석의 자연스러운 보완물이다 : safety는 미래를 보고, 포렌식은 과거를 본다.
Forensics in Access Control
[접근 통제를 위한 포렌식을 다음과 같은 마음 가짐으로 본다, 완전히 신뢰받지 못하는 유저들이 상태 변화를 일으킬 수 있는 권한을 위임할 수 있는 환경, (권한의) 상태가 계속해서 변화하는 시스템. 따라서 유저가 권한을 가질 수 있는지, 실제로 가지고 있는지, 권한을 행사하였는지 3가지에 초점을 맞춘다. 이것은 침입에 대한 단서를 줄 수 있음은 물론이고, 특정인에 대한 면죄부를 줄 수도 있다.]
포렌식과 접근 통제는 운영체제 접근 통제의 가장 초창기의 구현부터 얽혀있었다. 접근 통제와 나란히 보안 감사 능력을 유지하기 위한 욕구가 Anderson의 1972년 ..에서 옹호되었다. Multics, ?nix의 전신, 또한 감사 추적 기능이 있었다, 보안 사고와 권한 외 접근에 대한 수사를 활발하게 하기 위해서. 그러나 우리가 알기로는, 어떠한 연구도 포렌식과 접근 통제의 교차점을 safety (분석)에 사용하는 것과 비슷한 마음가짐으로 고려하지 않았다. (그 마음가짐은) 접근 통제 시스템을 상태 변화하는 규칙과 함께 상태가 변화하는 시스템으로 본다. (상태 변화 규칙 안에서는) 완전히 신뢰받지 못하는 유저들이 상태 변화에 영향을 끼치는 권한을 위임받을지도 모른다. 이 연구에서는 이러한 방식으로 포렌식을 고려하는 것이 접근 제어에 유용하다고 우리는 주장한다. 그 이유는, 접근 제어가 시스템 보안의 중요한 일부분이기 때문이다. 그러므로 과거 권한 상태에 대한 질문에 답변하는 능력은 침입들에 대해서 중요한 단서와 증거를 제공할 수 있다. 바꿔말해서, 이는 면죄를 위한 증거를 제공할 수도 있다.
이러한 주제는 접근 통제를 위한 포렌식의 문제점을 제시하는 다음 섹터에서 다시 등장한다. 나중에 다시 이야기 하겠지만, 우리는 과거의 권한 상태에 대해서 누군가 질문할 수 있는 3가지 종류의 기본적인 질문을 생각해 보았다. 하나는 유저가 특별한 권한을 가질 수 있는지 여부이다. 예를 들어 파일에 쓸 수 있는 권한이 있는지 여부이다. 다른 하나는 그가 실제로 권한을 가지고 있는지이다. 마지막은, 그가 권한을 행사하였는지이다. 당연히, 마지막이 2번째를 포함하고, 그것이 첫 번재를 포함한다, 그가 권한을 행사하였으면 권한을 소유한 것이고, 소유할 수 있었던 것이다.
누군가는 왜 1~2 번째 질문에 대해서 우리가 관심을 갖냐고 물을 수 있다. 그것에 대한 답변은 우리의 의도 안에 숨어 있다. 위 질문의 가장 약한 부분을 동기화하기 위한 자연스러운 방법은 그것의 구현에 대해 고민하는 것이다. - 그가 권한을 가지는 것이 불가능했는지를 따지는 것. 이 보충적인 질문에 대한 "예"라는 대답은 그에게 범죄에 대해 면죄부를 줄 수 있다. 확정적 증거가 아닌, 보다 약한 질문이 수사관이 증거를 찾기에는 충분할지 모른다는 것이다.
Differences from safety
[safety와 포렌식의 차이점. 1) 포렌식은 과거의 상태를 조사하고, safety는 현재와 미래의 상태를 기술한다. 2) safety는 현재와 미래 "목표" 상태를 기술하고, "목표"에 도달할 수 있는지에 관심이 있다. 포렌식은 "목표"에서 얼마나 떨어져 있는지 범위를 정할 수 있는 '알려진 상태'에 대해서 명시하는 것에도 의미가 있다. 3) 포렌식은 과거 이벤트를 고려하는데, 이러한 이벤트들은 로그로 남을지도 모른다는 것이다.]
(너무 주저리주저리 길다.. 이게 꼭 다 필요한 얘기일까..?)
safety(분석)과 포렌식의 명백한 연관성에도 불구하고, 중요한 차이들이 있다. 특정한 설정에서 포렌식 분석을 위한 알고리즘을 직관적으로 이해하는 자연스러운 방법은, 상태-변경 규칙을 "역전"한 다음 특정 속성이 있는 과거의 상태가 존재했는지를 확인하는 것이다. 접근 통제에서, 사실은 컴퓨팅 관련 에서, 시스템의 현재 상태와 상태가 새로운 상태로 변화할 수 있는 방식를 명시함으로써 묘사하는 것은 관례적이다. 이것은 우리가 튜링 머신의 기술 문서에서 하는 것과 정확하게 같다.
포렌식과 safety의 다른 차이점은 우리는 관습적으로 2개의 상태를 명시한다 : 현재, 미래 "목표" 상태. 후자는 부분적으로만 기술될 지도 모른다, 예를 들면 특정한 주체가 특정 오브젝트의 특정 권한을 가지는지의 여부이다. 우리는 "목표" 상태가 현재의 상태로부터 도달 가능한지를 질문한다. 포렌식 분석에서는 현재의 상태와 과거 "목표" 상태로부터 떨어져서, 우리가 "목표" 상태로부터 얼마나 멀리 떨어져 있는지 범위를 정하는 '알려진 상태'에 대해서 명시하는 것도 의미가 있어 보인다. 그러한 상태는 Figure 1에서 겹쳐진 원으로 떨어져 있다. 그러한 이유는 우리가 과거를 보고 있기 때문이고, 포렌식 분석을 수행하는 슈퍼유저는 그러한 상태를 아마도 알 것이고, (그 상태를) 명시적으로 언급함으로 인해서, 분석을 조정할 수 있어, 분석가들이 그들의 포렌식 질문에 대한 답에 모든 관심을 집중할 수 있다. 예를 들어, 우리가 조사하는 보안 사고가 과거 2주 내에 일어났다고 했을 때에, 2주 전의 과거 상태를 아는 것은 조사의 범위를 정하기 위해서 의미가 있어 보인다. 게다가, 첫번째로 시스템을 처음 어떤 상태로 환경을 설정하는 것은 일반적으로 슈퍼유저이고, 딱 그 때에 잠재적으로 믿을만하지 않은 유저에게 권한 상태를 변경할 권한을 위임한다. 슈퍼유저는 그러한 상태로 포렌식 분석의 범위를 정하고 싶을 것이다. Section 2에서 있을 접근 통제에서의 포렌식 분석의 구체사항에서는, 우리는 그러한 상태의 명시적인 구체화를 한다. 그러나 우리는 그러한 상태가 접근 통제 시스템의 "시작 시간"을 의미하는 "비어있는" 상태임을 지적한다. 그것은, 우리가 이러한 추가적인 제약을 필요하다면 완전히 느슨하게 할 수도 있다는 것이다.
세 번째 차이는 포렌식은 과거 이벤트를 고려하고, 최소한 그러한 이벤트가 로그에 기록될지도 모른다는 것이다. 이러한 로그들은 결국 포렌식 분석에 있어 추가적인 input이 된다.
Logs
[로그를 의미있으면서도, 작게, 목표-지향형으로 수집하는 것을 Section 4에서 다룰 예정임.]
로그는 시스템의 과거 상태에 대해 우리가 기록하고 저장하는 데이터이다. 그것들은 사후 탐지에 기반한 보안에 유용하다. Section 4에서는 우리는 덩말로 신중하게 기록된 로그들의 결합이 포렌식 분석의 문제를 계산적으로 쉽게 한다는 것을 확인한다. 이것은 놀랄만한 것은 아니지만, 여기에 연관되는 문제는, 무분별한 로깅이 비정상적으로 큰 로그를 남기게 된다는 것이다. 이 연구의 이론은, Section 4에서 더 알아봄, 목표-지향형 로깅을 한다는 우리의 의도에 달려있다. 그것은, 미래의 포렌식 분석에 잠재적으로 유용한 것들만을 로깅한다는 것이다. 우리의 목표는 우리가 수집하는 로그의 양을 상당히 줄여줄 수 있다. 따라서 목표-지향형 로깅은 로그를 위한 semantic하고, lossy한 압축 방법이다. 이런 것은 Section 4에서 다루겠음.
충분한 (의미를 가진) 로그는 우리가 질문하기를 추구하는 포렌식 질문의 종류과 근접하게 연관되어 있다. 또한 이것은 safety와 포렌식 모두에게 중요한 기술적 도전과제와 연관되어 있다: 거의 무한적이게 많은 도달 가능한 상태. 우리는 이것을 Figure 2의 HRU scheme의 예시를 이용하여 설명한다. 상태를 encode하기 위해서 access matrix를 이용하고, 상태-변환 규칙으로서 명령어의 집합을 이용한다(Section 3.1에 자세히)
(예시..)
Foundations
[Contribution에 해당하는 내용. 1) 접근 통제를 위한 포렌식 분석법을 제시, 3가지의 접근 통제 모델을 제시하고 각각의 safety 관점에서의 계산 복잡도와 포렌식 관점에서의 계산 복잡도가 같은 클래스에 속한다는 것을 발견함. 2) 충분히 의미를 가지면서도 간략화된 로깅 방법 (목표-지향적인 로깅)에 대해 서술함.]
Section 2에서는 문제점을 정형화 하였다. 우리가 알기로는, 포렌식을 접근 통제에 우리의 방식으로 가져온 것이 처음이다. 그 이후에 우리는 2가지 셋의 contribution을 만들엇다. Section 3에서는 3개의 접근 통제 scheme을 가져왔다. 1) HRU scheme 2) RBAC scheme, ARBAC 3) Graham-Denning scheme. 우리는 3가지 scheme에서 포렌식 분석의 계산적 복잡성을 확인하였다. 이러한 scheme을 고려한 이유는 그들이 질적으로 다른 것들과 다르기 때문이다. HRU는 access-matrix, ARBAC는 RBAC, Graham-Denning은 discretionary scheme 기반이기 때문이다. 또한 safety 분석의 계산적 복잡도가 각각의 scheme에 대해 알려져 있고, 그들의 서로 다른 클래스에 속한다, HRU는 undeciable, ARBAC는 PSPACE-complete, Graham-Denning은 P이다. 이러한 각각의 scheme에 대해서 포렌식 분석은 safety 분석과 같은 클래스에 자리잡고 있고, 따라서 이러한 점에서도 safety와 포렌식 사이에 긴밀한 관련성이 확립된다. 다른 contribution은 충분하면서도 간략화된 로그이다. Section 4에서 자세히 설명한다.
Practice
Hello, Retail!이라는 실제 애플리케이션의 접근 통제 시스템에 대한 포렌식 분석을 통해 case-study를 실시함.(Section 5)
2. Problem
접근 통제 시스템은 상태-변화 시스템으로 여겨질 수 있다. 이러한 관점은 이전의 연구들과 일관되는데, 특히 safety 분석과 관련해서는 그렇다. 우리는 이러한 특징화를 Section 2.1에서 상기하고, 2.2에서는 포렌식 분석에서의 문제점을 접근 통제 scheme에서 의미있는 방법으로 제시한다.
2.1. Access Control Schemes and Systems
[표기에 대한 설명들. 뒤에를 이해하려면 알아야함.]
접근 통제 scheme은 pair ⟨Γ, Ψ⟩이다. Γ은 상태들의 집합이고, Ψ은 상태-변경 규칙의 집합이다. 전자는 무한하지만, 후자는 유한하다. 전자에 속하는 어떤 상태는 주체가 주어진 시간에 가지는 권한을 encode한다. 전자는 정해진 시간에 접근 통제 결정을 내리기 위한 모든 정보를 담고 있다. 주체의 예시는 유저와 권한이다. 접근 제어 요청은 query로 인코드된다. query의 문법은 특정한 scheme으로 맞춤되고, 다음 섹션에서 알아볼 것. query q가 true이면, 𝛾 ⊢ 𝑞처럼 표시하고, false이면, 𝛾 ⊬ 𝑞처럼 표시함.
상태 변화 규칙, 𝜓 ∈ Ψ은 상태가 다른 것으로 어떻게 변화할지에 대해 명시한다. 𝜓가 하나의 상태 변화 규칙을 나타낸다는 대충 주저리 긴 설명. 표시 방법은 아래와 같다고 함. 왼쪽에서 오른쪽으로 state-change 조건에서 변화가 가능하면 그냥 삼지창 화살표, 변화를 위해 여러개의 state-change가 필요하면 별표 삼지창 화살표.

Three assumptions
[기존의 safety 연구들로부터 가져온 전제들.]
1) 어떤 때라도 최대 1개의 state-change만이 실행 상태이다. 즉, state-change가 동시에 존재하는 것은 허가하지 않는다는 것이다.
2) 실행되는 state-change는 성공적으로 일어나거나, 아예 일어나지 않는다는 것이다. 부분적인 state-change에 대한 개념은 가지지 않는다.
3) state-change에 대한 순서를 고려할 때마다, 그것은 유한하다는 것이다. 이 모든 가정은 safety 분석에 관한 이전 연구의 맥락에서 가져온 것이다.
2.2 Forensic Analysis: Problem Formulation
[포렌식에서의 instance를 재정의하고, 각각의 요소에 대해 설명. 𝛾은 current state, 𝜓은 state-change rule, 𝑘는 알려진 과거, 𝑞는 state를 조회하는 query, 𝜋는 타입(possible or actual), 𝐿은 로그 // 마지막 semantic 부분은 중요해서 별도로 봐야함.]
⟨Γ,Ψ⟩라는 접근 통제 scheme이 있을 때, 포렌식 instance는⟨𝛾,𝜓,𝑘,𝑞,𝜋,𝐿⟩이다.⟨𝛾,𝜓⟩는 접근 통제 시스템이다. 전자는 현재 상태이고, 후자는 state-change 규칙이다.k는 우리가 고려하는 과거 시점에 대한 범위를 제한해주는 '알려진 과거 시점'이다.q는 우리가 찾고자하는 종류의 상태를 인코딩하는 query이다.𝜋 ∈ {possible, actual}은 q가 true인 상태가 일어날 가능성이 있는지, 혹은 일어났는지 여부를 인코딩한다.L은 로그.
Comparison to safety analysis
safety 분석에서의 인스턴스는 ⟨𝛾,𝜓,𝑞⟩와 같이 표현이 된다. 시스템 ⟨𝛾,𝜓⟩에서 q가 true가 되는 미래의 상태가 존재하느냐고 질문한다. 포렌식적 분석에서는 여기에 더해서 𝑘, 𝜋 and 𝐿을 고려한다. 아래에 자세한 설명을 덧붙였다.
The system, ⟨𝛾, 𝜓⟩
시스템의 현재 상태와 state-change 규칙을 나타낸다. 이 상태로부터 시작하여 뒤로 향하면서 과거의 상태를 탐색한다, 모든 "앞으로 향하는" state-change는 𝜓를 충족한다는 가정 하에(????)
알려진 과거, k
k 상태는 우리 조사의 state의 범위를 제한해 준다. 우리는 현재 상태와, k 사이의 상태들만 조사하면 된다. 이 요소를 formulation에 넣은 이유가 있다. 많은 실제 인스턴스들에서, 초기 상태는 "비어있는" 상태가 아니었다. 대신, 슈퍼유저가 접근 통제 시스템을 시작하기 전에 오브젝트들에 대해 특정한 권한을 부여하고 유저와 오브젝트를 생성하는 것이 보편적이다. 둘째로, 알려진 과거 상태는 우리의 분석이 얼마나 뒤로 가야할까를 제한하게 해준다.
쿼리, q
우리가 state의 범위 내에서 찾는 state의 종류를 구체화해준다. 쿼리의 정확한 문법은 특정한 접근 통제 scheme에 맞춰져 있지만, 이 연구에서는 query를 access request처럼 처리한다. 예를 들어, access matrix에서는 <subject, object, right⟩으로, RBAC 에서는 <user,role>으로.
Possible vs actual
접근 통제의 맥락에서 의미있어 보이는 3가지의 포렌식 질문에 대해서 알아보았다. 유저가 1) 권한을 가질 수 있는가 2) 권한을 가졌는가 3) 권한을 행사했는가. 상태-도달성의 관점에서 1)과 2)는 제시할 의미가 있다. 3)은 접근 시행에 적용된다, 접근에 대한 권한 보다는, 그리고 이것은 우리가 고려하는 포렌식 분석 종류의 범위를 넘어선다. 𝜋은 우리가 유형 1)을 의미하는지 유형 2)를 의미하는지 캡쳐하기 위함이다.
Log, L
로그는 과거 상태와 state-change에 대한 기록이다, 엔트리의 순서인데, 발생한 상태나 state-change의 일부분이다. 로그는 통합적이지 않을 수도 있는데, 어떤 엔트리는 state나 state change의 일부분만을 기록하고 있을 수도 있고, 모든 state나 state change에 대한 것이 로그에 등장하지 않을 수도 있다.
우리는 로그를 ground truth로 생각할 수 있다. 이러한 관점으로, 우리는 logical entailment를 이용하여 포렌식에서 우리의 관심 속성을 설정하려고 시도할 수 있다(????). (대충 로그를 통해서 특정 state의 sequence들이 일어났는지, 일어나지 않았는지에 대해 확실히 할 수 있다는 말임. 물론 불충분하여 일어났는지 안일어났는지에 대해 알 수 없는 경우도 있음.)
Semantics of an instace
주어진 포렌식 인스턴스에서, true false unknown 중 하나의 value를 할당할 수 있다. 𝜋가 possible일 때에, instance는 unknown일 수는 없고, true나 false여야 한다. true인 경우는, state 𝛾'가 1)𝛾' ⊢ 𝑞를 만족하고 (query가 true이다), 2) 𝑘 →∗𝜓 𝛾′ →∗𝜓𝛾 이러한 시퀀스가 일어나지 않았다고 확신할 수 없을 때 (알려진 과거 k로부터 주어진 state로의 변화, 그리고 주어진 state로부터 현재 state로의 변화가 모두 가능한 상황)일 때이다. 그렇지 않으면 false이다. 우리는 2)의 조건은 그러한 sequence가 정말 일어날지도 모르는지, 그 가능성을 배제할 수 없는지로 구체화 한다.
𝜋가 actual일 때에, 결과는 true, false, unknown일 수 있다. true인 경우는, 1)𝛾' ⊢ 𝑞를 만족하고, 2)𝑘 →∗𝜓 𝛾′ →∗𝜓𝛾과 같은 어떤 sequence가 실제로 일어났다고 확신할 수 있을 때이다. false인 경우는, 과거에 일어났던 sequence인 𝑘 →∗𝜓 𝛾′를 확신할 수 있는데, 𝛾′ ⊢ 𝑞과 같은 𝛾′이 존재하지 않을 때이다. 그렇지 않으면 unknown이다.
𝜋 = actual 이 true이면, 𝜋 = possible은 true이고, 𝜋 = possible이 false이면, 𝜋 = actual 역시 false이다.
수사관은 𝜋 을 그들의 의도에 맞게 possible 혹은 actual로 설정할 수 있다. 용의자에 대해서 면죄부를 주는게 목적이라면 possible이 보다 적절할 것이다. 그들의 의도가 유죄의 확증이라면, actual이 보다 적절할 것이다.
3. Computational Complexity
[앞에서 제시한 3개의 scheme에 대해 최악의 경우에 계산적 복잡성을 보겠다고 함.]
여기에서 우리는 앞에서 제시한 3개의 접근 통제 scheme을 위한 포렌식 분석 문제에서의 최악의 경우에 계산적 복합성을 계산할 것이다. 의도는 3개의 scheme에서 포렌식 분석을 위해 효율적인 알고리즘이 존재하는지 판단하기 위함이다. 또한 포렌식 분석이 safety 분석에 대해서 서로 다른 최악의 경우 계산적 복합성을 가지는지 여부도 관심을 가지고 있다.
Proof strategy
우리는 계산적 hardness를 위해서 lower-bound와 upper-bound를 확립하고자 통상적인 접근을 하였ㄷ. lower-bound를 확립하기 위해서는 (그것에 대해) 알려진 문제점을 감소했다. upper-bound를 확립하기 위해서는 construction을 하였다: 알고리즘을 제시했다. -> 그것에 대한 증명을 Section 3.1과 3.2에서 하기 위해서, 우리는 그 각자의 scheme을 위해 safety 분석 문제를 줄이기를 선택하였다.(??) 이것은 바람직한 lower-bound를 확립해줄 뿐만 아니라, 이러한 scheme에서 safety와 포렌식과의 관련성을 확립해주었다.
3.1. HRU
[HRU scheme에서 포렌식 분석의 복잡성은 undecidable이다.]
HRU scheme에 대해서 최악의 경우의 계산적 복합성을 계산할 것이다.
The HRU Scheme
access matrix란, 𝑀𝛾[𝑠,𝑜]처럼 표현하는데, subject와 object가 존재하고, subject가 object에 대해서 가지는 권한들의 집합을 의미한다. 그러한 access matrix를 전체적으로 표현하는 방법이 바로 𝑀𝛾[]이다.
HRU scheme에서의 state-change 규칙은 C𝜓라고 표기하는 명렁어(커맨드) 셋이다. state-change는 C𝜓 내부의 커맨드가 실행되는 것이다. 각각의 커맨드는 argument를 가지고, 그것 각각은 subject이거나, object이다. 각각의 커맨드는 선택적 조건을 가지는데, 그 조건은 argument인 subject와 object에 대해 셀 내부에서 권한이 있는지 확인하는 결합이다. 각 커맨드의 body는 기초적인 동작의 연속이다. HRU scheme은 6가지 기초적인 동작에 대해 명시한다. 1) subject의 생성, 새로운 행과 열을 access matrix에서 만드는 것. 2) object의 생성, 이것은 열을 생성함. 3) subject의 삭제, 해당하는 행과 열을 삭제함 4) object의 삭제, 해당하는 열을 삭제함. 5) 셀에게 권한의 추가, 6) 셀으로부터 권한을 삭제.
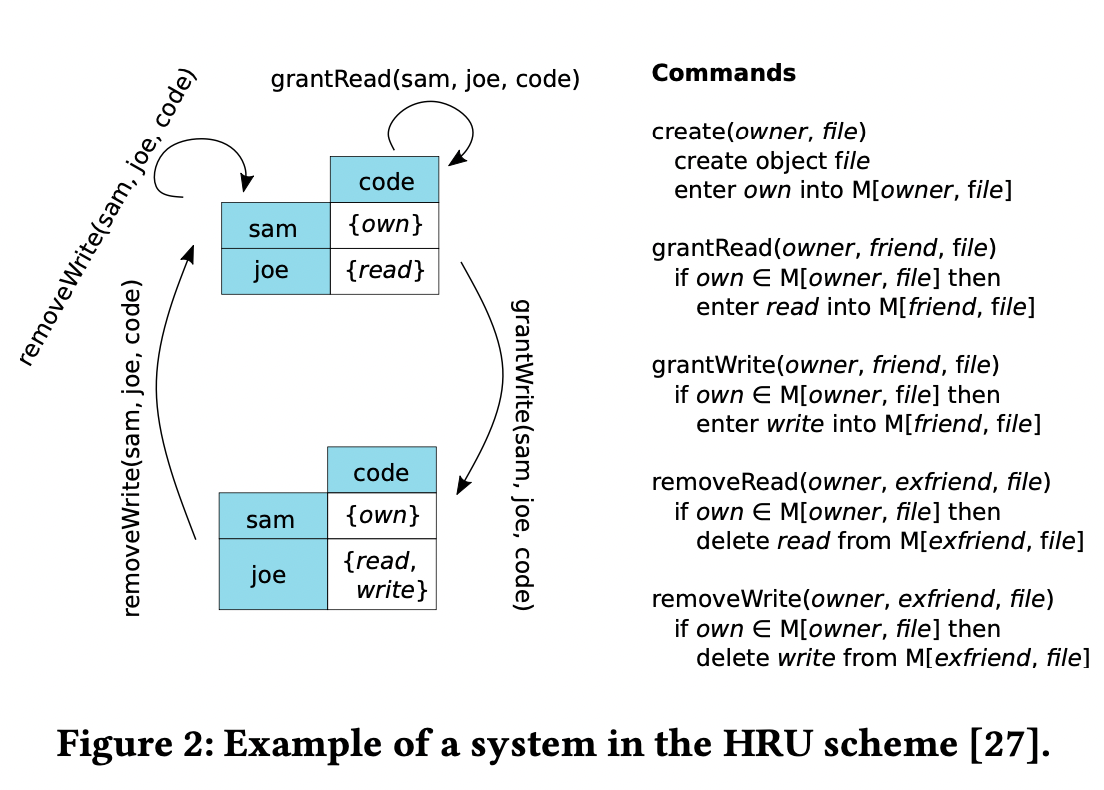
Figure2는 HRU 시스템의 예시이다. 여기에서 권한인 R은 {own, read, write}이고, C𝜓는 5개의 커맨드를 가진다. 여기에서 subject인 sam과 joe는 object로도 표시될 수 있다.
Forensic Analysis in HRU
포렌식 분석 인스턴스 ⟨𝛾,𝜓,𝑘,𝑞,𝜋,𝐿⟩에서, 𝛾, 𝑘는 access matrix가 된다. 𝜓는 커맨드들의 집합이다. L, 로그는 state와 state-change들의 부분으로 구성되어 있다. query 𝑞는 access request에 대응되는데, ⟨𝑠, 𝑜, 𝑟⟩(subject, object, right) 이다.
Example - possible access
Figure 2에서 sam이 read 권한을 가지는 것이 "possible" 하냐고 묻는다면, 우리는 초기 상태부터 현재 상태까지의 경로에 대한 지식을 가지고 있지 않다. 이러한 커맨드들의 나열이 가능하기 때문에, query는 true이다. grantRead(sam, sam, code), removeRead(sam, sam, code), grantWrite(sam, joe, code). 이제 다르게 가정해서, 우리가 모든 state-change들을 로그한다고 했을 때, 단 하나의 발생한 state-change가 grantWrite(sam, joe, code)이라고 한다면, query에 대한 대답은 false일 것이다.
Example - actual access
sam이 과거 상태에서 read 권한이 있었냐고 묻는다면, 우리는 시작 state 부터 현재 state까지 아무 정보가 없다. 인스턴스는 unknown이다. 왜냐하면, 그것은 가져온 경로에 따라 true일수도, false일 수도 있기 때문이다. 만약 우리가 우리의 로그 중에서 실행된 커맨드가 오직 "grantWrite(sam, joe, code)"임을 알고 있다면 인스턴스는 false가 될 것이다.
Computational complexity
HRU scheme에서 최악의 경우 계산적 복합성을 말해보자.
정리 1. HRU scheme에서의 포렌식 분석은 결정불가능한 복잡성을 최악의 경우에 가진다.
증명은 Appendix에 있다. 우리는 safety 분석의 버전으로부터 𝜋 = possible and 𝐿 = ∅인 특별한 경우들까지 축소해왔다. 포렌식 인스턴스가 다음의 2조건을 만족할 때에만 true임을 발견했다.
(조건 1과 2, 그리고 그에 대한 설명. 이해하지 못하여 생략.)
3.2. ARBAC
[ARBAC에서 포렌식 분석의 계산적 복합성은 PSPACE 내에 있다.]
role-based로 동작하는, ARBAC에 대해서 얘기해보자.
ARBAC Scheme
(이해하지 못하여 생략... 진짜 무슨말이야 ㅋㅋ ㅠㅠ)
Forensic analysis in ARBAC
상태 𝛾 and 𝑘는 R(role)의 부분 집합이고, 유저(u)들이 그러한 상태에 할당되어 있는 역할들이다. 로그 L은 state와 state-change의 부분으로 구성된다. 이전처럼 L은 비어있다. q는 역할이다. query의 의미는: 시스템에 관련되어 있는 유저인 u가 r의 멤버인지 여부이다.
Example - possible access
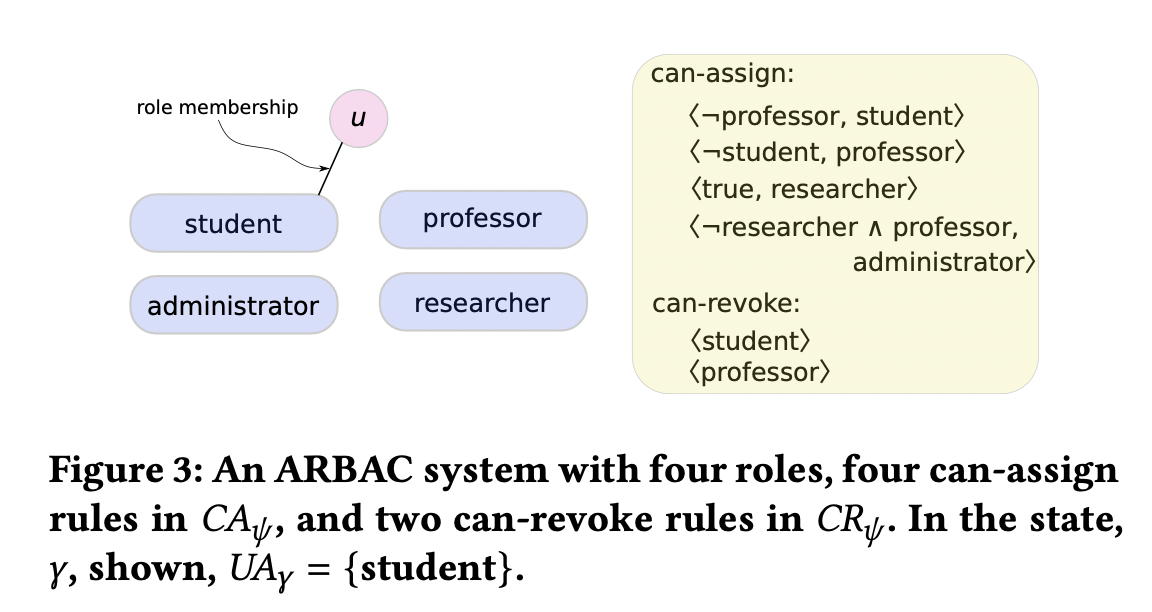
Figure 3의 예시. u는 오직 student 역할에만 할당되어 있다. 우리가 𝜋 = possible, 𝐿 = ∅인 상황이고, query q = ⟨professor⟩인 상황이라고 해보자. 그것은, 우리가 u가 과거 state에 professor의 역할을 하는 것이 possible한지를 물어보는 것이다. 이것은 "true"이다. 우리는 𝛾 로부터 시작해서 𝑘 까지 거꾸로 가보면서 이것을 직관적으로 이해할 수 있다. state-change의 possible한 순서는 다음과 같다 : assign-to(student), revoke-from(professor), assign-to(professor), revoke-from(student). 다시 가정해보자, L이 일어난 모든 state, 혹은 일어난 모든 state-change라고 가정해보자. L로부터 우리는 u가 student로부터 권한을 잃은 적이 없게 될 것이다. 그렇다면 instance는 false이다.
Example - actual access
Figure 3에서, 𝜋 = actual, 𝐿 = ∅ and 𝑞 = ⟨professor⟩이라고 가정해보자. 그러면 forensic 인스턴스는 u가 professor의 멤버였을 수도 있고, 아닐 수도 있기 때문에 unknown이다. 그러나, L이 모든 state-change를 기록하고 있다면, L에 따라, true or false가 나뉠 것이다.
Computational complexity
기타 증명은 Appendix B에 존재한다. PSPACE란, 인풋의 크기에 대해서 다항식의 공간을 차지하는 알고리즘이 결정할 문제마다 있는 클래스이다.
가정 2. ARBAC에 대한 포렌식 분석은 최악의 경우에 PSPACE-hard하다.
이 가정은 lower-bound를 제공해준다. 다음에 나오는 가정은 우리에게 upper-bound를 제공한다. 그러나 우리는 이렇게 한정하려고 한다. 1) 𝜋 = possible 2) 𝐿 = ∅ 3) 우리의 제한된 ARBAC 버전에만 적용. 1)의 이유는 그것이 true/false 만으로 결정할 수 있는 유일한 버전이기 때문이고, 2)의 이유는 얼마나 L이 존재하는지에 대한 정확한 규정 없이는 의미있게 분석할 수 없기 때문이고, 3)의 이유는 그 버전만이 가정 2의 규정 내에 우리를 스스로 한정할 수 있기 때문이다. 2)를 위해서 다음 섹션에서는, 충분하면서도 효율적인 로그에 대해서 언급하려고 한다. 3)을 위해서 우리의 upper-bound가 조금 더 일반적인 버전의 ARBAC를 적용하더라도 여전히 남아있음을 추측해본다. 이러한 추측의 기반은 safety와 포렌식의 강력한 일관성 때문이고, safety의 계산적 복잡도가 ARBAC의 일반화에 영향을 받지 않은 그동안의 연구결과 때문이다.
가정 3. 𝜋 = possible and 𝐿 = ∅ 일 때에 ARBAC scheme에서의 포렌식 분석은 PSPACE 내부의 계산적 복합성을 갖는다.
우리는 중단이 보장되어 있는 비결정적인 알고리즘을 제시하였고, 최악의 경우의 선형의, 그러므로 input의 크기에 대해서 다항식의 공간을 할당하였다. 그런 후에 Savitch’s theorem, NPSPACE = PSPACE에 관심을 가졌다. 비결정적인 알고리즘이 현재의 상태에서 시작하고 가능한 state-change들을 생각하면서 뒤로 간다.
귀결 3.1. 𝜋 = possible and 𝐿 = ∅ 일때의 ARBAC scheme에 대한 포렌식 분석은 PSPACE-complete 하다.
Observations
HRU scheme과 같이, ARBAC에서의 포렌식 인스턴스도 safety 분석과 동일한 복잡성의 클래스를 가졌다. 그러나, HRU scheme과는 다르게, 그것은 결정할 수 있었고, 가정 3 의 증명은 건설적이었다 : 비결정적인 것일지라도 알고리즘을 제공하였다(????). ~~~ 이러이러한 툴들이 있는데, 이것들은 PSPACE 내부에서는 종료된다. ARBAC에 대한 포렌식 분석이 upper-bound로 PSPACE인 점을 감안할 때, 이러한 도구들이 포렌식 분석에서 효율적으로 재사용될 수 있을 것이라고 기대한다.
3.3. Graham-Denning\
[P의 복잡도 안에 있다고 함. 3개 scheme 모두 safety 분석과 포렌식에서 복잡도 클래스가 동일함.]
Graham-Denning scheme. 선택한 이유는 1) HRU와 ARBAC scheme과는 질적으로 다르다. 자율적 scheme인데, subject가 object에 대한 소유 개념이 있고, subject의 자유에 따라 권한을 부여할 수 있다. HRU와 ARBAC와 유사한 점은 safety 분석이 연구되었다는 것이다. 공간을 고려해서 결과만 남긴다.
가정 4. Gramham-Denning scheme에서 𝜋 = possible, 𝐿 = ∅ 일 때에 포렌식 분석의 복잡도는 P 안에 있다.
Observations
클래스 P는 Graham-Denning scheme의 포렌식 분석 계싼 복잡도에서 upper-bound로 보인다. 따라서 우리의 증명 전략은 가정 3과 동일하다. 알고리즘을 제안한다. 따라서 우리가 고려한 모든 3개의 scheme에서 포렌식 분석은 safety 분석과 같은 클래스에 있었다.
4. Goal-Directed Logging
[로그가 너무 크면 저장하기도 어렵고, 분석에 시간이 오래 걸린다. 목적-지향형 로깅은 만약의 상황을 대비하여 '최소화'된 로그보다는 많은 정보를 저장한다. possible 분석을 위한 로그 사이즈 <= actual 분석을 위한 로그 사이즈.]
로그는 과거 상태에 대한 정보를 기록하고 포렌식을 돕는다. 여기에서 우리는 로그가 믿을만하다고 가정한다. 예를들어, 쓰기 전용 미디어에 기록한다고 가정하는 것이다. 로깅 메커니즘이 종합적이라면, 초기 상태부터 지금 상태까지 사이의 모든 과거 상태들에 대해 일어난 모든 state-change를 기록한다면, section 2에서 제시했던 포렌식 분석이 추적가능해질 것이다. 누군가는 log를 초기화 상태의 처음부터 쭉 살펴볼 수도 있다. 그러나 이러한 방식의 종합적인 로깅에는 중요한 단점 이있다. 1) 로그의 크기가 너무 크다. 2) quantity problem을 가져온다. 많은 양의 데이터가 분석되어야 한다는 것이다. 이 문제는 분석을 마쳐야 하는 시간과 관련된다. 3) 불필요한 데이터는 분석가를 관련있는 데이터로부터 관심을 잃게 함으로써 분석의 정확성을 가로막을 수 있다.
분석해야할 로그의 크기를 통제하기 위해서 데이터 감소 기술이 사용될 수 있다. 예를 들어, 분석가가 보기에 필요 없는 파일은 파일 필터를 이용해 제외할 수 있다. 접근 통제의 관점에서, 로그의 양을 줄이는 방법은 목적-지향형 로깅이다. 그것은 일어날 수 있는 포렌식 분석의 종류를 미리 알고 있거나 제한하는 방법이다. 그런 후에 필요한 데이터만 로깅하는 방법이다.
우리는 goal-directed loggin이 goal-oriented logging으로 제시되었던 것과는 다르다는 것을 지적한다. 후자는 로깅 요구사항이 공격자의 목표를 분석하는 데에서는 제외되어야 한다는 것이다. 이것은 보안 정책들이 제자리에 있음을 고려하고 공격자가 이것들을 위반하는 방법들을 분석함을 통해 해낼 수 있다. 이 연구에서는 로깅 요구사항을 보안 정책으로부터 추론하지는 않을 것이다, 그러한 정책들이 완벽한 보안을 가져온다는 보장이 없기 때문에. 대신에 보안 정책의 결핍이 공격을 가져오는 상황은 있을 것이다. 이러한 경우에 정책들로부터 로그가 단독으로 추출되었다면, 그들은 공격을 위해 필요한 정보들을 담고 있지 않을 것이다.
물론 포렌식 분석의 목적은 미리 알 수 없을지도 모른다. 이러한 경우에, 목표-지향형 로깅이 저장되는 로그의 사이즈를 줄이는 데에 사용될 수 없을 지라도, 분석에 input이 되는 로그의 사이즈는 줄이는 데에 사용될 수 있다. 왜나면 로그의 의미있는 부분을 필터링하는 것이 로그 전체를 분석하는 것보다는 쉽기 때문이다. 접근 통제의 관점에서 '최소한의' 로그는 특정한 포렌식 분석을 true or false로 대답하기 위해 필요한 딱 그정도를 포함하고 있다. 만약 '최소화'된 로그의 어떤 부분이 부족하다면, possible 분석을 위해서는 분석이 undecidable인 query가 존재할 것이다. actual 분석을 위해서는 정답이 unknown인 query가 존재할 것이다. '충분한' 로그는 '최소화'된 로그가 제공하는 모든 정보를 담고 있으면서도, 그것보다는 더 많은 정보를 포함한다. 다음 가정은 actual 분석을 위해 충분한 정보는 possible 분석에도 충분하다는 사실을 뒤따른다.
가정 5. 어떤 접근 통제 scheme에서, possible 분석을 위한 '최소한'의 로그 사이즈는 actual 분석을 위한 '최소한'의 로그 사이즈보다 적거나 같다.
(possible 로그 사이즈 <= acutal 로그 사이즈)
HRU, ARBAC, Graham-Denning
[3가지 각각의 scheme에 대해서, possible 분석과 actual 분석을 할 수 있게 해주는 Log의 사이즈를 제시함. 각각에 대한 가정과 증명을 첨부.]
(논문의 핵심 부분 중에 하나이지만, 관심분야가 아니라 대충 읽고 생략)
Observations
possible 분석을 위해 충분한 로그의 사이즈가 actual 분석을 위해 충분한 로그의 사이즈보다 작은 것은 놀랄만한 일이 아니다. 흥미로운 결과는 다음과 같다 : 우리가 목표가 possible 분석임을 알고 있다고 한다면, 더 작은 로그 사이즈를 만들 수도 있다는 것이다. 이러한 관찰 결과는, 로그 사이즈를 줄이고 싶은 누군가, 필요한 로그만을 남겨 분석을 쉽게 하고 싶은 누군가에게는, 목표-지향적인 마음가짐을 검증해주는 것이다.
5. Case Study
이전 연구로부터 우리의 분석적 통찰력을 검증하기 위해 실제 소프트웨어 시스템으로부터 케이스-스터디를 논의할 것이다. AWS 클라우드 플랫폼 내의 오픈소스 애플리케이션인 Hello, Retail!을 이용하자. 우리 연구의 범위는 AWS에 대한 다음의 질문들에 답하기 위함이다. 1) 어떤 종류의 포렌식 쿼리들을 지원하는가? 2) 목표-지향적 로깅이 로그 사이즈를 줄이는데 효과적인가? 섹션 5.1에서는 AWS의 접근 통제 모델에 대한 배경 지식을 설명하고, 우리가 관심갖는 그 시스템이 제공하는 로깅 서비스에 대해 설명한다.
Limitations
우리의 케이스 스터디는 AWS 로깅에 대한 종합적인 평가가 아니다. 우리는 특정 로깅 메커니즘과 클래스에 대해서만 이야기한 것이다, 소위 이벤트 관리라고 불리는 AWS ClouTrail. AWS는 다른 로깅 기능도 있다.
5.1. Background
[말 그대로 배경 지식. AWS, CloudTrail, Hello Retail!에 대한 설명.]
AWS 서비스가 제공하는 기능 중 하나는 serverless computing인데, 사용자가 일어날 이벤트와 관련된 call-back 함수를 쓰면, 그것을 소위 AWS Lambda라는 서비스를 이용하여 그 함수들을 이용하는 것이다. 사용자는 명시적으로 컴퓨팅 리소스를 할당할 필요가 없다.
AWS IAM
AWS는 역할-기반과 신원-기반의 인증을 결합한다. IAM 유저는 IAM 역할을 배정받고, IAM 역할은 IAM 정책에 배정된다. IAM 유저는 여러개의 역할에 배정될 수 있으며, IAM 역할은 여러개의 정책에 배정될 수 있다. IAM 유저가 역할을 맡고, 역할의 접근 권한을 행사할 수 있다. 또한 유저는 정책과 직접적으로 연관되기도 한다. Figure 4에서 정책의 예시를 보여준다. 서비스 역할이라는 개념도 있다. 이것은 특별한 IAM의 역할인데, EC2와 AWS Lambda와 같이 AWS가 관리하는 서비스들과 연관된다. 다른 AWS 서비스들을 위해 권한을 얻어오는 등의 역할을 한다.
CloudTrail
CloudTrail은 로그, 계속되는 모니터, AWS 설비 전반에 대한 계정 활동을 보존하는 역할을 한다. 이 로그들은 JSON 형식이고, S3 스토리지로 전달된다. CloudTrail은 이벤트를 데이터, 서비스, 매니지먼트 이벤트로 특징한다. 데이터 이벤트는 S3 내의 오브젝트의 읽기/쓰기 이벤트를 기록한다. 서비스 이벤트는는 AWS 서비스에 의해 만들어지는 것으로, 반드시 cloud application으로부터 만들어지는 것은 아니다. 매니지먼트 이벤트는 AWS 계정과 관련된 모든 control plain을 로깅한다. 예를 들어 DB 접근은 데이터 이벤트로 로깅되고, IAM 권한 생성은 매니지먼트 이벤트로 로깅될 것이다. IAM에서 만드는 접근 권한 변경은 CloudTrail에서 로깅된다. 이러한 로그들을 포렌식에 이용할 것이다.
Hello, Retail!
우리가 이것을 case-study를 위해 고른 3가지 이유가 있다. 1)서버리스 컴퓨팅 디자인 패턴이 최첨단이고, Hello Retail이 서버리스 아키텍쳐로 수상을 했기 때문 2) Hello Retail이 AWS에서 동작하도록 설계되었기 때문에 AWS IAM 내부의 풍부한 접근 통제 scheme과 AWS CloudTrail의 로깅 능력을 제공하기 때문이다. 3) Hello Retail이 보안 정책 설정이기 때문이다. 이것이 우리의 분석적 접근을 이용하게 해준다.
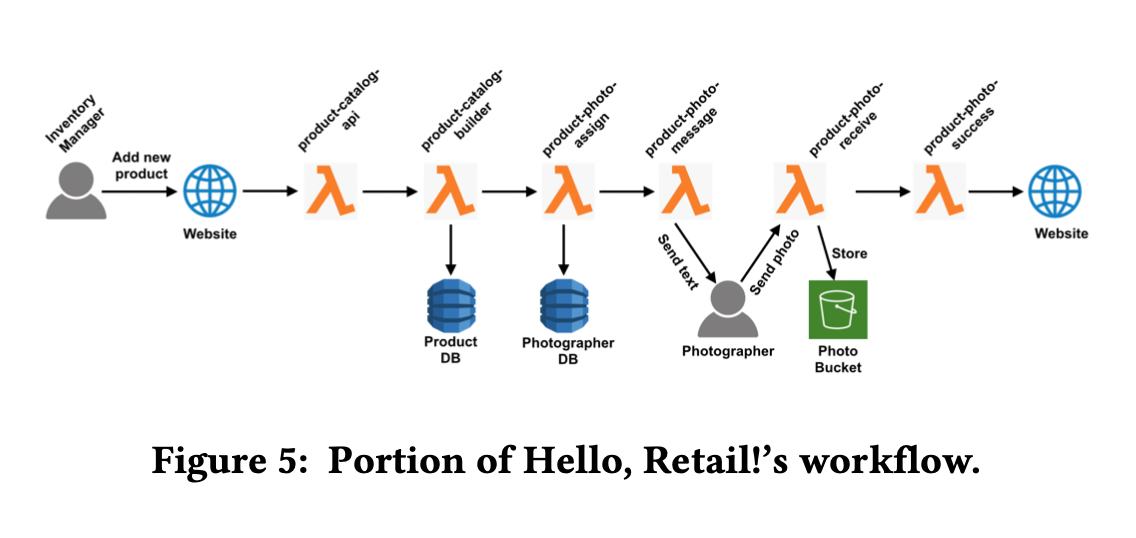
Hello Retail은 자영업자들을 위한 오픈소스인데, 판매자가 물건을 하나 판매하기 위해 글을 올리려고 하면, 상품 DB, 사진 DB 등등을 채워야 함. 여기에서 각자 권한 분배가 일어나고 접근 통제 정책이 사용됨.
5.2. Forensic Analysis
Incident
[사례에 앞서 예시로 들 사고의 개요를 설명.]
2가지 행위를 하였다. 1) 서비스 역할의 과도 권한 2) 제품과 연관되지 않는 사진을 올렸음. 2)부터 설명하면, 맥북과 아이폰을 홈페이지에 올렸는데, 두 상품 모두에서 아이폰 사진이 보이고 있음.
1)을 설명하면, 1)이 2)의 원인임. 악성 유저가 lambda 함수를 변경해서 부정확한 이미지가 저장된 것임. 근본적인 원인은 1) 과도한 권한이 공격자로 하여금 lambda 코드를 변경하게 만든 것임.
Analysis
[앞에서 설명한 방식에 맞춰 해당 사건을 포렌식 인스턴스로 변경함. 사건 해결하는 과정을 통해 접근 통제 기반의 포렌식의 예시를 들었음.]
보안 사고가 일어나는 일어나는 이유들이 있음. 진짜 이유도 그 중 하나임. 다른 이유는, 권한이 있는 사진까 잘못 사진을 보냈을 가능성도 있는 것임. Figure 5에서, 사고를 조사하기 위한 알고리즘은 다음과 같을 것임.
우선, 사진가가 보낸 사진이 맥북의 것이었는지를 확인하고, 만약 그렇다면 사진가는 무죄임이 판명나고, lambda의 2개의 함수가 변경되었는지 각각 확인될 것임. 사진가가 보낸 사진이 아이폰(잘못된 것)이었다면, 책임을 묻기 전에 정확한 사진가가 할당되었는지를 확인하고 정확한 문자 메시지가 사진가에게 전달되었는지를 확인해야 함. CloudTrail의 로그는 다소 불충분한데, 모든 전달된 문자메시지의 내용을 기록하지는 않음. 대신에 우리는 섹션 2에서부터 접근 통제 시스템과 그것의 state-change를 고려하여 조사를 할 것임.
Figure 5로부터 product-photo-receive 만이 S3 photobucket에 접근함을 관찰할 수 있음. 그러나 악성 유저가 다른 lambda 함수를 이용하여 S3에 접근했을지도 모르고, 함수를 바꾸었을 지도 모른다. 어떤 lambda 함수가 S3 리소스에 어떤 과거의 상태에 접근했는지를 알기 위해서, lambda 각각의 함수에 대해서 query를 날려야 한다. query는 ⟨𝛾,𝜓,𝑘,𝑞 = ⟨𝐹,𝐴𝑚𝑎𝑧𝑜𝑛𝑆3𝐴𝑐𝑐𝑒𝑠𝑠⟩,𝜋 = actual,𝐿⟩ 이와 같은 형태가 될 것이다. F는 lambda 함수이다.
우리의 프로그램에서 product-photo-receive 함수만이 S3에 접근하였다는 사실이 발견되었다. 그러나 S3에게 서비스 권한을 준 정책 중 하나는 PowerUserAccess 정책임을 발견하였다. 이러한 정책이 모든 S3에 읽기/쓰기 권한을 준 것이고, 서비스 권한이 과도 권한된 것이다. 따라서 우리는 product-photo-receive 함수가 악성 유저에 의해 변경되었다고 결론을 내리는 것이다. 우리의 포렌식 분석에서, AWS IAM의 로깅 능력은 주체가 과거에 권한을 가졌는지를 효율적으로 결정하게 해주는 것이었다.
Goal-Directed Logging
[목적-지향형 로깅의 적용 가능성을 2개의 시나리오를 통해 확인함.]
CloudTrail이 모든 매니지먼트 이벤트들을 로깅하는 것을 발견했다. 시스템의 사용자 수가 커지면서, 로그도 커진다. 1) 비용 증가 2) 너무 커서 분석을 어렵게 함. 우리는 목적-지향형 로깅을 통해 얼마나 줄일 수 있을까 고민하였다.
2개의 시나리오를 통해서 목적-지향형 로깅의 장점을 분석했다. 전체 로그 중에서 우리가 관심있는 포렌식 쿼리에 대한 로그가 2번째 열에 표시되었다. 거의 대부분(98~99%)는 우리가 관심있는 것에 대한 로그가 아니었으며, 목적-지향형 로깅을 통해 이를 줄일 수 있을 것으로 보인다.

6. Related Works
생략(힘들다..)
7. Conclusions
상태가-변화하는 시스템으로 여겨지는 접근 통제 시스템에서의 포렌식 분석을 제기하였고, 연구하였다. 또한 전통적 safety 분석 모델과 포렌식 분석과의 공통점과 차이점을 관찰하였다. 우리는 3개의 접근 통제 모델을 위한 포렌식 분석을 예를 들어 설명하였고, 최악의 경우에 포렌식 분석에서의 계산적 복잡성이 safety 분석과 같음을 확인하였다. 우리는 충분하면서도 최소화된 로깅을 통해 분석하는 방법에 대해 조사하였고, 그러한 맥락에서 목적-지향형 로깅이 논의되었다. 우리는 오픈소스 서버리스 클라우드 컴퓨팅 애플리케이션 케이스 스터디를 통해서 우리의 분석적 아이디어를 검증하였다.
Future work
생략..
