이번에는 앞서 올린 포스트의 뒷부분을 리뷰하고, SOF-VSR에 대한 정리를 마치도록 하겠습니다. Methodology부터 하나씩 살펴보겠습니다.
Methodology
본 논문의 핵심인 SOF-VSR의 전체적인 구조는 Fig.1과 같습니다. 추후 상세한 단계별 구조들도 논문에 상세히 소개되어 있어서 도움이 많이 될 것 같습니다.
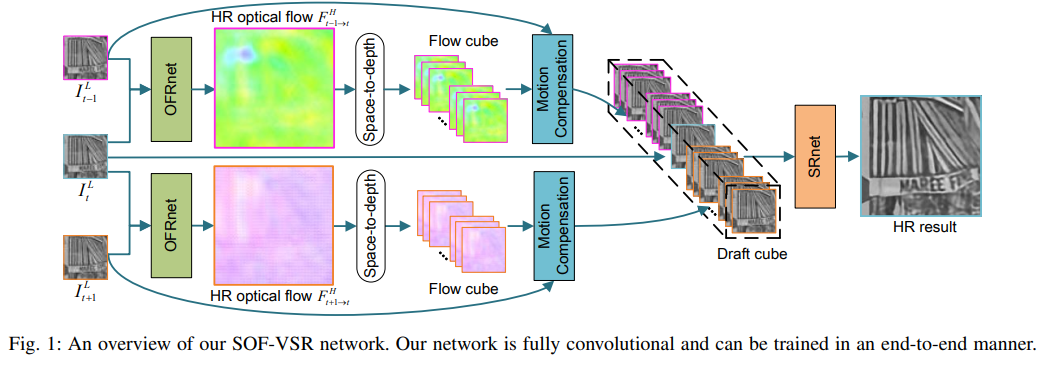 Fig 1. SOF-VSR Architecture
Fig 1. SOF-VSR Architecture
Overview
- T개의 연속적인 LR frames이 SOF-VSR의 입력으로 사용
- 으로 frame을 표기하여 임
- 그 이후 LR frames들을 YCbCr color space 로 변환하는데, 밝기에 관한 channel만을 얻고자 하였음.
(YCbCR은 첫 프로젝트에서 사용한 이미지의 색 채널 관련된 것인데, 참고사항으로 공부하면 도움이 많이 되었습니다. 이미지 및 영상 처리에서 중요하게 쓰였더라구요.)
✅참고자료 : YCbCr Wikipedia - LR Frame들은 OFRnet으로 먼저 들어가고, HR optical flow를 추론함
- ORFnet은 central LR frame 과 인접한 frame을 가지고 HR optical flow 를 생성함
- 그 후, space-to-depth transformation을 거쳐 HR optical flow를 LR flow cube로 생성
- Motion compensation이 flow cube를 사용하여 draft cube를 생성함
- 생성된 Draft cube가 SRnet으로 들어가 최종적인 HR frame을 만듬
- 본 예시에서는 을 예시로 설명되어 있음
Optical Flow Reconstruction Net(OFRnet)
시작하기 앞서 자꾸 optical flow라는 개념이 나오는데, 이에 대해 설명은 하지 않아둬서 이해에 어려움이 있으시면 아래의 두 자료를 확인해주시면 좋습니다. 저도 공부하는데 많이 도움이 된 두 곳입니다.
✅ Optical Flow(1)
✅ Optical Flow(2)
- 기존의 연구들로 CNN이 LR and HR image간의 non-linear mapping도 학습 가능하다는 것이 보여짐
- Optical Flow를 사용한 FlowNet과 같은 선행 연구들이 optical flow가 motion estimation에 사용될 수 있다는 잠재력을 보여줌
- 따라서 본 논문에서 OFRnet은 이를 융합하여 사용
- model size와 training difficulty를 줄이기 위해, parameter를 공유하는 scale-recurrent architecture가 SRN-DeblutNet에서 사용됨
- 이 개념에서 아이디어를 얻어 optical flow reconstruction에 scale-recurrent network를 사용
- 전체적인 OFRnet의 구조는 Fig.2 참고
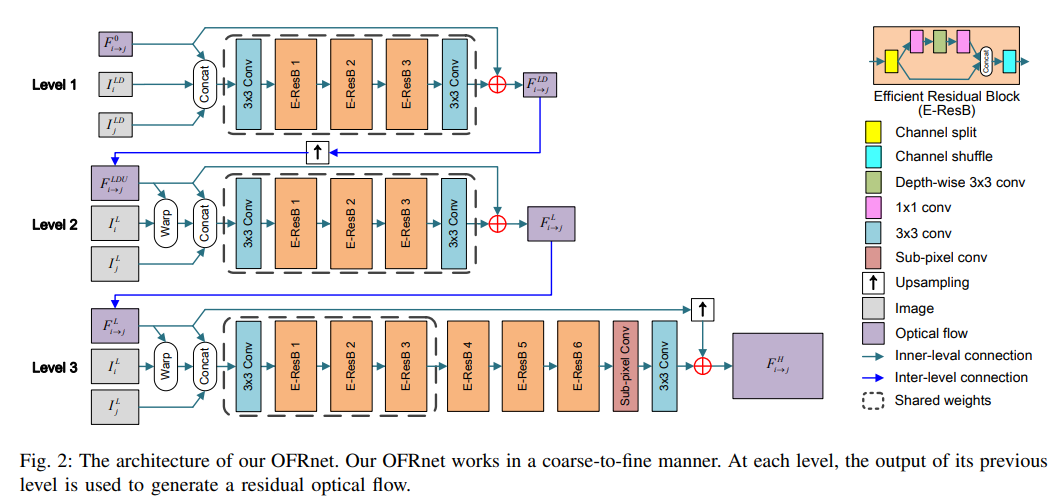 Fig 2. OFRnet Architecture
Fig 2. OFRnet Architecture
- 첫 두 level에서는 recurrent module을 서로 다른 scale의 input에서 optical flow를 추론하기 위해서 사용
- level 3에서는 먼저 recurrent structure를 deep representation을 생성하기 위해 사용하고, 그리고 SR module을 LR frame representation을 기반으로 HR optical flow를 복원하는데 사용
- 이러한 구조는 OFRnet이 complex motion pattern을 다룰 수 있게 하고, model 자체도 lightweight 및 compact 함
Fig.2의 각 level별 동작을 상세히 정리하면 아래와 같습니다. 입력과 출력이 서로 엮여있어 level 1부터 차례대로 타고 올라가면 전체적인 흐름을 파악할 수 있습니다.
Level 1.
- Input : pair of LR frame ,
- Input downsampled by a factor 2
- Generate : , & initial flow map
- Concatenated these generations fed to a feature extraction layer
- three efficient residual blocks used to generate deep features
- Channel split, Channel shuffle, Depth-wise convolution techniques are used to improve the efficiency
- these features fed to flow estimation layer generate : optical flow at level 1
- middle layer를 제외한 모든 convolution layer는 ReLU를 사용
- Output :
Level 2.
- Input :
- Upscaled by factor of 2 using bilinear interpolation
- Magnitude of optical flow is also doubled with the resolution
- Upscaled Flow : used to warp result
- , , : concatenated and fed to the recurrent model
- Output :
Level 3.
- Input :
- Input has same size as the LR input level 3 works as an SR module to reconstruct HR optical flows
- Similar to level 2 first concateneted and fed to recurrent model to extract features
- These features then fed to three additional residual blocks to generate deep representations
- Resulting feature representations are fed to a sub-pixel layer for resolution enhancement
- Output : final HR optical flow
Contribution of OFRnet
- First unified network to integrate SR and optical flow estimation
- Learns to infer HR optical flows between latent HR image from LR inputs
- Demonstrated the potential of CNN
Motion Compensation Module
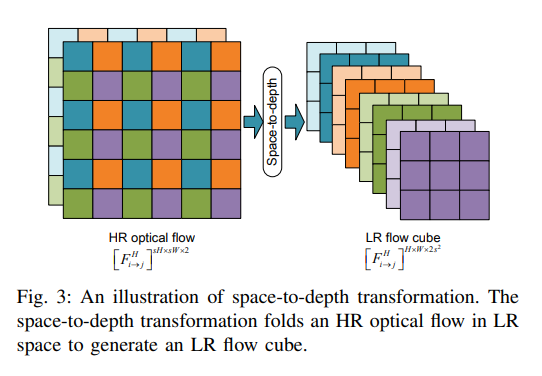 Fig 3. Space-to-depth transformation
Fig 3. Space-to-depth transformation
- space-to-depth transformation이 HR optical flow와 LR frame 사이의 resolution gap을 이어주기 위해 사용됨
- Fig.3에서 볼 수 있듯, regular LR grid가 HR flow에서 추출되고, channel dimension으로 배치되고 flow cube를 얻음
- and 는 LR frame의 크기, 는 upscaling factor를 의미
- Slices are extracted for LR flow cube to wap the LR frame, resulting in multiple warped drafts
- : warping operation using bilinear interpolation
- : represents the concatenation of multiple warped drafts
Super-Resolution Net (SRnet)
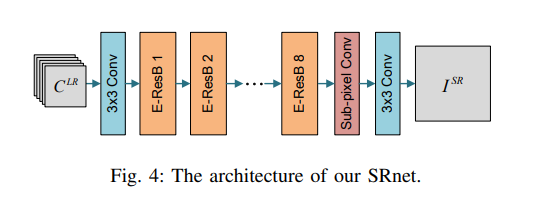 Fig 4. SRnet
Fig 4. SRnet
- Motion compensation이 끝나고, multiple drafts가 각 neighboring frame에 대해서 생성됨
- 모든 draft가 central LR frame로 concatenated fed to SRnet
Loss Function
- SRnet과 OFRnet에 대한 Loss 설정
- SRnet에 대해서는 MSE(Mean-Square-Error)를 사용
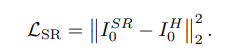
- OFRnet의 Loss-equation은 아래와 같음

- Total Loss :
Experiments
- Datasets : Vid4 , DAVIS-10
- 145 1080P HD video from CDVL database
- Basic Settings : Pytorch, Nvidia GTX 1080Ti GPU, Adam solver
- Iteration : 200k
Ablation Study
각 실험에 대한 결과는 Fig.5를 참고하면 됩니다.
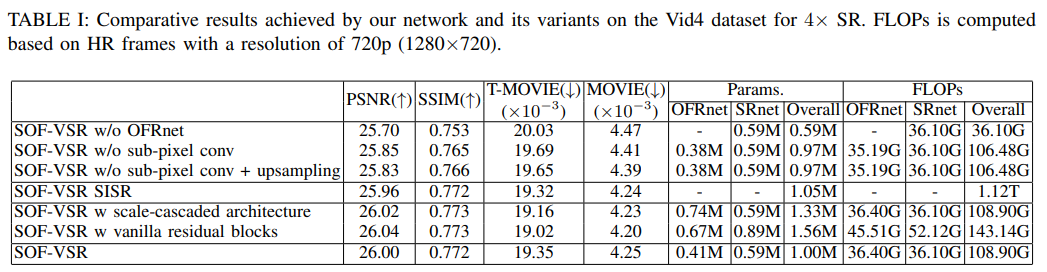 Fig 5. Results of ablation studies
Fig 5. Results of ablation studies
- Motion Compensation : removed OFRnet and fed LR frames directly to SRnet
- LR Flow vs HR Flow : HR optical flows provide more accurate temporal dependency for performance improvement
- Upsampled Flow vs Super-resolved Flow : optical flow SR can recover finer temporal details and facilitate SOF-VSR
- SISR before Optical Flow Estimation : network has a much lower computational cost and is more suitable for applications on mobile computing devices
- Scale-recurrent vs. Scale-cascaded Architectures : SOF-VSR is more lightweight and compact while achieving comparable performance
- Efficient Residual Block vs. Vanilla Residual Block : SOF-VSR network is more suitable for applications on mobile computing devices
그 외 시각적인 실험결과는 다음 Fig.6-8을 통해 확인할 수 있습니다.
 Fig 6. Results(1)
Fig 6. Results(1)
 Fig 7. Results(2)
Fig 7. Results(2)
 Fig 8. Results(3)
Fig 8. Results(3)
정량적인 수치에 대한 비교는 Fig.9-12에 첨부된 표를 통해 확인할 수 있습니다.
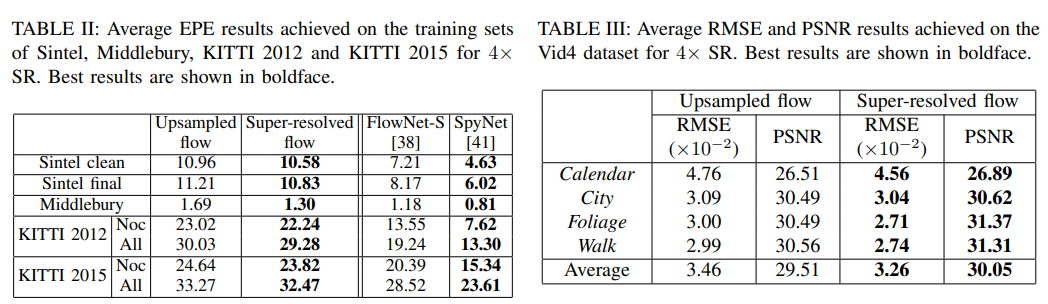 Fig 9. Result Tables(1)
Fig 9. Result Tables(1)
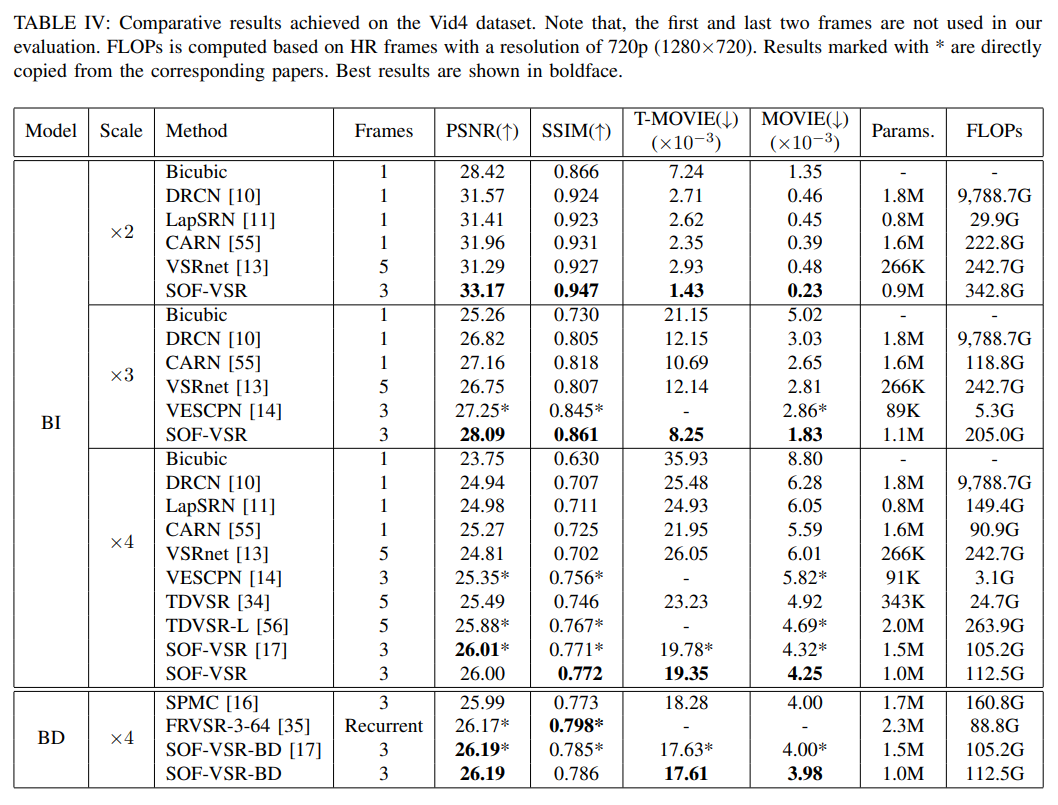 Fig 10. Result Tables(2)
Fig 10. Result Tables(2)
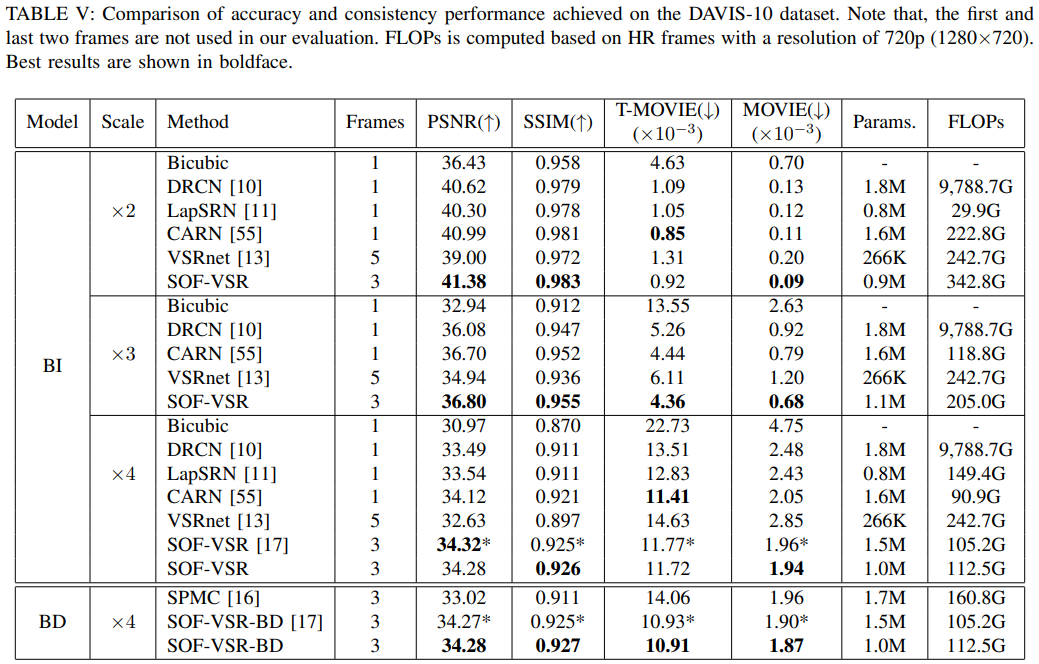 Fig 11. Result Tables(3)
Fig 11. Result Tables(3)
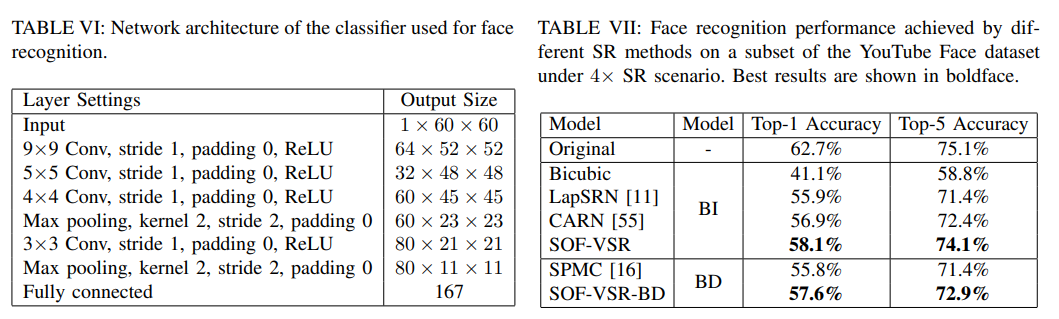 Fig 12. Result Tables(4)
Fig 12. Result Tables(4)
표의 내용을 깔끔하게 그래프로 정리해준 사진도 있습니다. Fig.13을 참고해주세요. 그래프에 대한 설명은 하이라이트 해두었습니다.
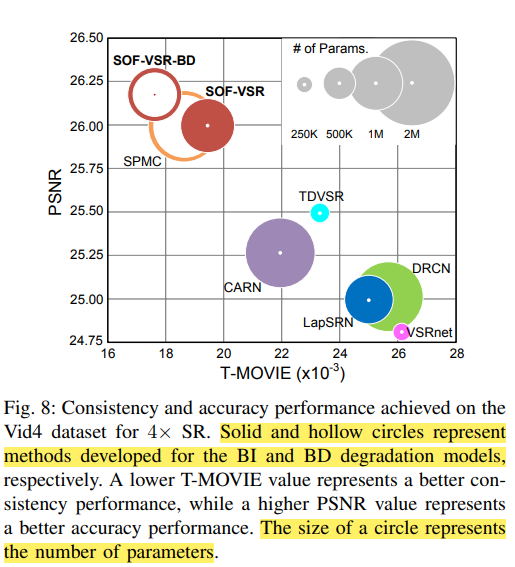 Fig 13. Table to Graph
Fig 13. Table to Graph
Conclusion
- Proposed end-to-end deep network for video SR
- First super-resolves optical flows to provide accurate temporal dependency
- Motion compensation is the performed based on HR optical flows
- SRnet used to infer SR results from these compensated LR frames
- Results show that SOF-VSR network can recover accurate temporal details for the improvement of both SR accuracy and consistency
SOF-VSR의 논문 리뷰를 이것으로 마치겠습니다. 직접 코딩도 해보고 실험도 해봐야할 Model이라 상세히 읽느라 시간이 좀 오래 걸렸던 것 같습니다. 다음은 OpticalFlow와 관련된 FlowNet으로 생각중입니다.
