이번에 리뷰할 논문은 2018 ACCV에 "Learning for Video Super-Resolution through HR Optical Flow Estimation" 이란 제목으로 처음 공개된 후 2년 뒤 2020 IEEE에 "Deep Video Super-Resolution using HR Optical Flow Estimation" 으로 보완되어 공개된 논문입니다. Video Super Resolution과 Optical Flow에 대한 개념이 모두 들어가있는 논문으로 원본 논문들과 공식 Github 링크는 아래에 첨부해두겠습니다.
✅ ACCV 2018
✅ IEEE 2020
✅ Github
Abstract
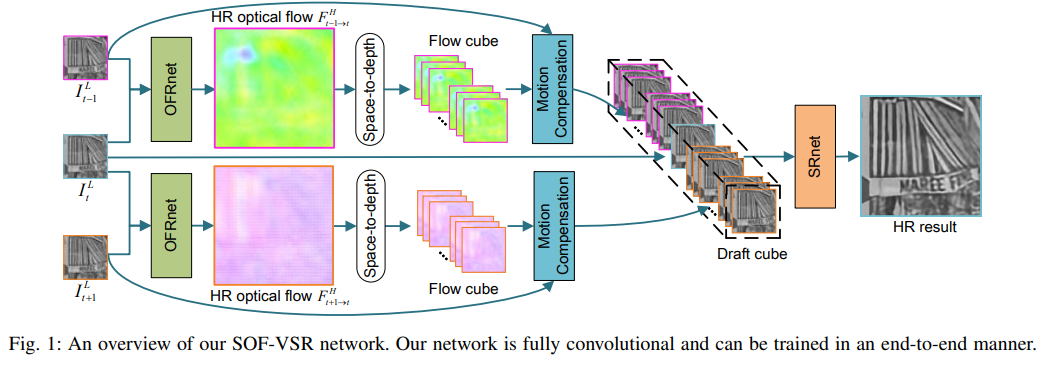
 Fig 1. Abstract
Fig 1. Abstract
본 초록에서는 기존 Video SR의 난관과 SOF-VSR에 대한 간략한 설명이 요약되어 있습니다.
"The key challenge for video SR lies in the effective exploitation of temporal dependency between consecutive frames"
Video-SR에서는 연속적인 프레임 사이에서 일시적인 연관성을 효과적으로 추출하는 것이 가장 key challenge입니다. 기존의 연구들의 경우 저해상도(LR) 프레임 간의 optical flow를 추론해서 이를 일시적인 연관성으로 사용했습니다. 하지만 이 방법은 고해상도(HR) 출력과 해상도 차이가 있었고, fine detail을 복원하는것을 방해(hinder)하였습니다. 따라서 본 연구에서는
Specifically, we first propose an optical flow reconstruction network (OFRnet) to infer HR optical flows in a coarse-to-fine manner. Then, motion compensation is performed using HR optical flows to encode temporal dependency. Finally, compensated LR inputs are fed to a super-resolution network(SRnet) to generate SR results.
의 방법을 소개하고 있습니다. 자세한 구조적인 측면은 추후 Network Architecture와 함께 살펴보도록 하겠습니다.
Introduction
Introduction에서는 Abstract에 서술된 부분을 보다 자세하게 정리해두었습니다. 원문은 첨부된 Fig.2~3을 참고해주세요. 자세한 내용은 아래 서술하였습니다.
 Fig 2. Introduction 1
Fig 2. Introduction 1
- Consecutive Frame 사이에서 Temporal Dependecy를 추출하는 것이 Video-SR에서 중요함
- 이를 수행하기 위해 Traditional Video SR이나 Multi-image SR에서는 patch similarities를 사용해 recurrent patches를 찾아냄
- 하지만 이러한 방법들은 오직 pixel-level dependency이며 computational cost가 아주 높음
- 그 이후 sub-pixel motion 정보를 optical flow estimation을 통해 사용하는 방법들이 제시됨
- 이 방법들의 제시 이후, Video SR은 Optimization Problem 의 영역으로 여겨짐
- 하지만 이 방법도 수렴단계까지 large number of iteration이 요구되어 high computational cost 문제에 봉착함
- 단일 이미지 SR의 성공 이후 video SR에서도 많은 연구가 나왔는데, LR frames에서 optical flow를 추정 한 후 이를 HR output에 direct matching하는 방법으로 학습을 해줌
- 하지만 LR optical flow에서 제공하는 temporal dependency는 video SR을 수행하기엔 아직 부족함
- Video SR에서는 temporal details & spatail detail 이 모두 중요함
- 현존하는 DL base의 Video SR 방식들이 spatial detail은 LR frame에서 성공적으로 복제할 수 있지만, temporal detail의 resoration은 아직 미지수임
 Fig 3. Introduction 2
Fig 3. Introduction 2
-
따라서 이 논문에서는 Super-resolve Optical Flow for Video SR(SOF-VSR)을 제시함
-
본 구조는 temporal detail을 optical flow SR을 통해서 복원함
-
우선 optical flow reconstruction net(OFRnet)을 통해 HR optical flow를 재구성함
-
이 optical flow눈 LR frame에서 motion compensation을 수행하기 위해 사용됨
a space to-depth transformation is used to bridge the resolution gap between HR optical flows and LR frames
-
결론적으로 compensated LR frame들이 SRnet(Super-Resolution Net)에 입력됨
본 논문의 기여(contribution)는 다음과 같이 주장하고 있습니다.
- incorporate SR both optical flows and images : Optical flow의 SR이 이미지의 SR에 궁극적으로 기여함 따라서 더 나은 performance를 얻을 수 있었음
- propose OFRnet to infer HR optical flows from LR frames
- SOF-VSR은 SOTA만큼의 성능을 제공함
앞서 서두에서 말했듯, 본 논문은 2018년에 ACCV에 올라오고, 2020년에 IEEE에 다시 보완하여 제출되었는데, 2년간의 보완에 대한 설명도 첨부되어 있습니다.(Fig.4)
 Fig 4. Introduction 3
Fig 4. Introduction 3
- Introduce a more lightweight and compact architecture
- additional analyses on the design of network
- conducted additional experiments on different upscaling factors
- additional experiments have been provided
Related Work
Single Image SR
 Fig 5. Single Image SR 1
Fig 5. Single Image SR 1
 Fig 6. Single Image SR 2
Fig 6. Single Image SR 2
- 기존의 방식들은 high-frequency detail을 복원할 수 없었음
- 그 후 제시된 방식은 large-number의 반복을 요구하여 연산이 굉장히 비쌈(expensive)
- 그 이후 DL을 접목하기 시작하면서 SRCNN, VDSR, DRRN, EXPCN, RDN 등의 model이 등장
Video SR
 Fig 7. Traditional Video SR
Fig 7. Traditional Video SR
- 전통적인 Video SR에도 여러 방법이 제시되었지만 over-smoothed 과 time-consuming 이라는 문제점이 있음
 Fig 8. Deep Video SR with Separated Motion Compensation
Fig 8. Deep Video SR with Separated Motion Compensation
- SRCNN의 성공 이후 2 단계로 framework를 나눠서 Video SR에 적용
- optical flow를 사용하고 이를 CNN에 넣는 형식
- 이러한 방법들은 최적의 결과를 얻기 힘들다는 단점이 있음
 Fig 9. Deep Video SR with Integrated Motion Compensation 1
Fig 9. Deep Video SR with Integrated Motion Compensation 1
 Fig 10. Deep Video SR with Integrated Motion Compensation 2
Fig 10. Deep Video SR with Integrated Motion Compensation 2
- end-to-end CNN이 접목되기 시작함 그리고 이 구조가 주를 이룸
- 그 이후 Encoder-Decoder와 LSTM이 사용됨
(진짜 요즘에 구조들은 Encoder-Decoder 없는게 있을까? 싶을 정도로 Transformer와 함께 정말 많이 보인다)
Methodology부터 본격적인 논문의 시작일 듯 하네요. 그건 Part 2에 상세히 기술하도록 하겠습니다. 이걸 보고 있으니 Optical Flow에 대한 개념 성립도 필요할 것 같아서 Flownet에 대한 Paper Review도 빨리 해야겠네요. 2번째 포스트로 바로 Methodology부터 업로드 하겠습니다. Intro 자세히 읽어주셔서 감사합니다!
