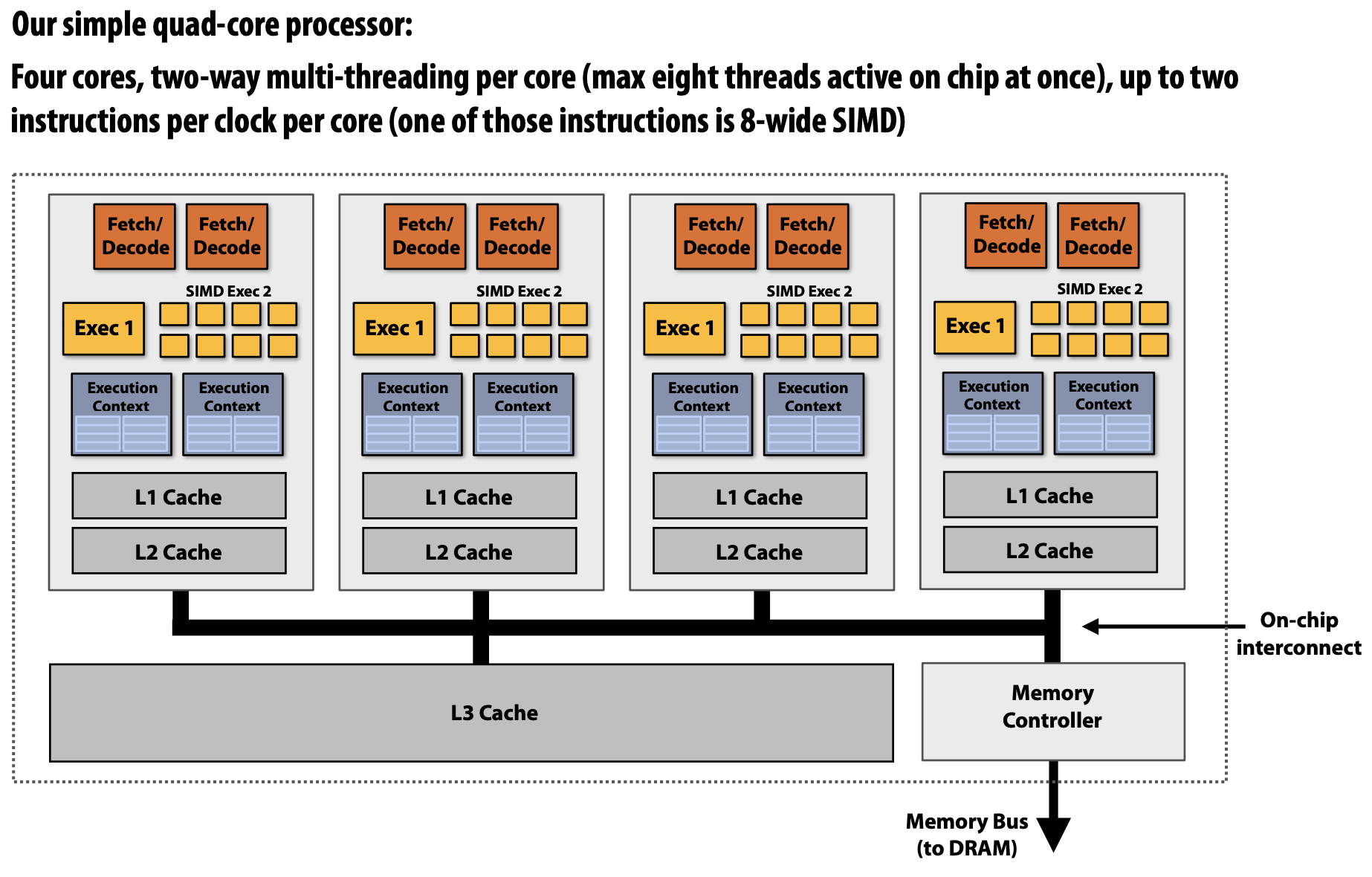
2. A Modern Multi-Core Processor
Parallel Computer Architecture and Programming: Lecture 2 - 1-19-18 - Carnegie Mellon University
Parallel Execution
Terminology
- Instruction Stream Coherence(Coherent Execution)
- 동시에 동작하는 모든 요소들에게 동일한 Instruction Sequence가 적용된다.
- Coherent Execution은 SIMD Processing Resoucess의 효율적인 사용에 필수적인 부분이다.
- Coherent Execution은 Core들 간의 효율적인 Parallelism 사용에 필수적인 부부은 아니다. 왜냐하면 각 Core는 다른 Instruction Stream을 Fetch/Decode 하기 위한 Capability를 가지고 있기 때문이다.
- Divergent Execution
- Instruction Stream Coherence의 부족
Instruction Stream Coherence를 Cache Coherence와 혼동 금지
Example Program
이번 파트에서는 일반적인 Computer Architecutre/Parallel Program에 대해서 알아보기 위해 다음과 같이 N개의 Floating-Point 배열의 모든 Sin 값을 구하는 예제를 사용하려고 한다. gcc로 컴파일 되는 아래 프로그램은 단순히 하나의 Processor에서 하나의 Thread로 실행될 것이다. (현재의 코드는 아무런 Parallelism이 표현되어 있지 않다.)
void sinx(int N, int terms, float* x, float* result){
for(int i=0; i<N; i++){
float value = x[i];
float numer = x[i] * x[i] * x[i];
int denom = 6; // 3!
int singn = -1;
for(int j=1; j<=terms; j++){
value += sign * numer / denom;
numer *= x[i] * x[i];
denom *= (2*j+2) * (2*j+3);
sign *= -1;
}
result[i] = value;
}
}일반적으로 간단한 Processor는 매 Clock마다 하나의 Instruction을 실행한다. 하지만 이전 파트에서 언급한 SuperScalar Processor는 Instruction-Level Parallelism(ILP)을 통해 매 Clock마다 두 개의 Instruction을 해독하고 실행이 가능하다.

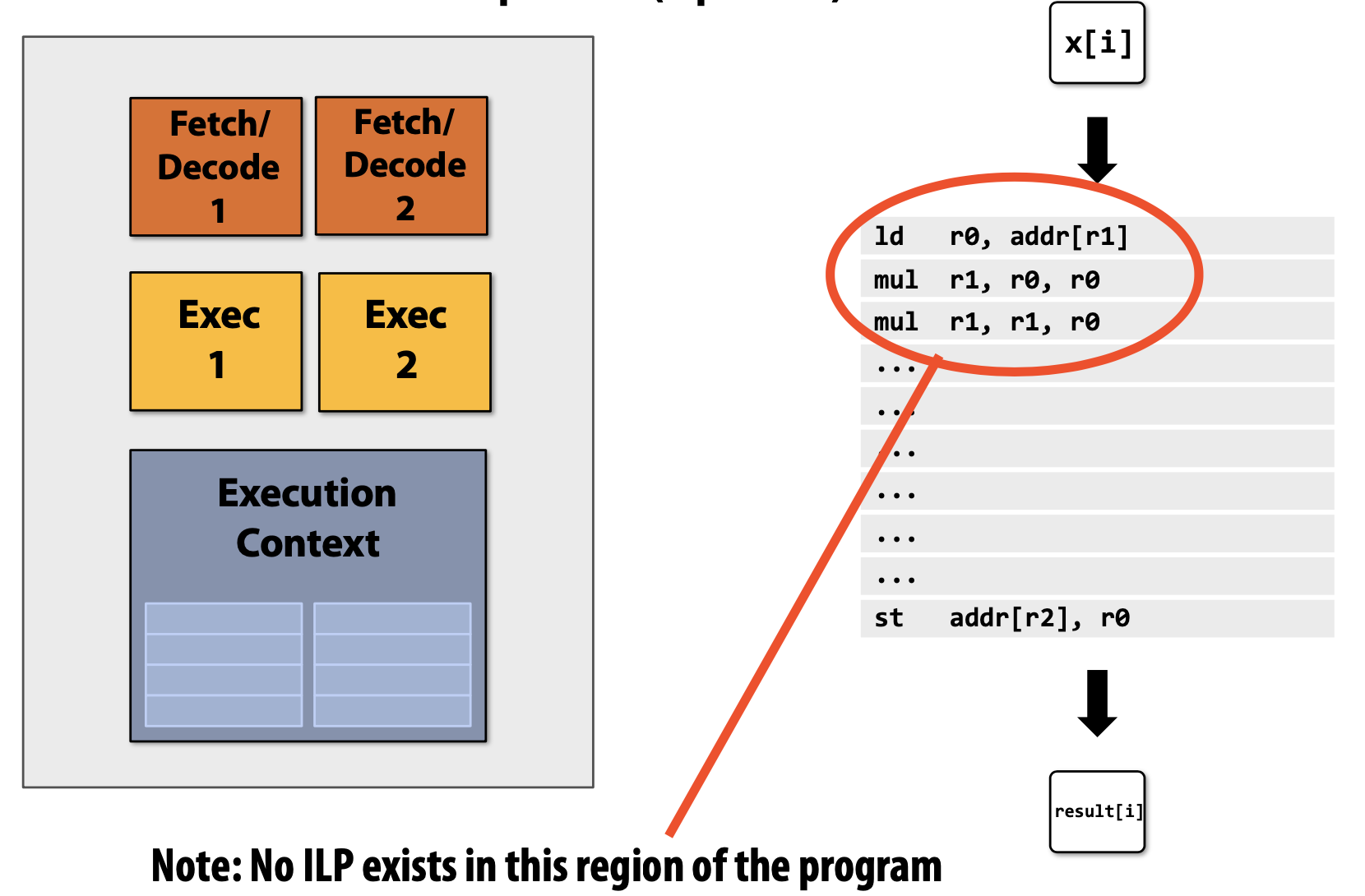
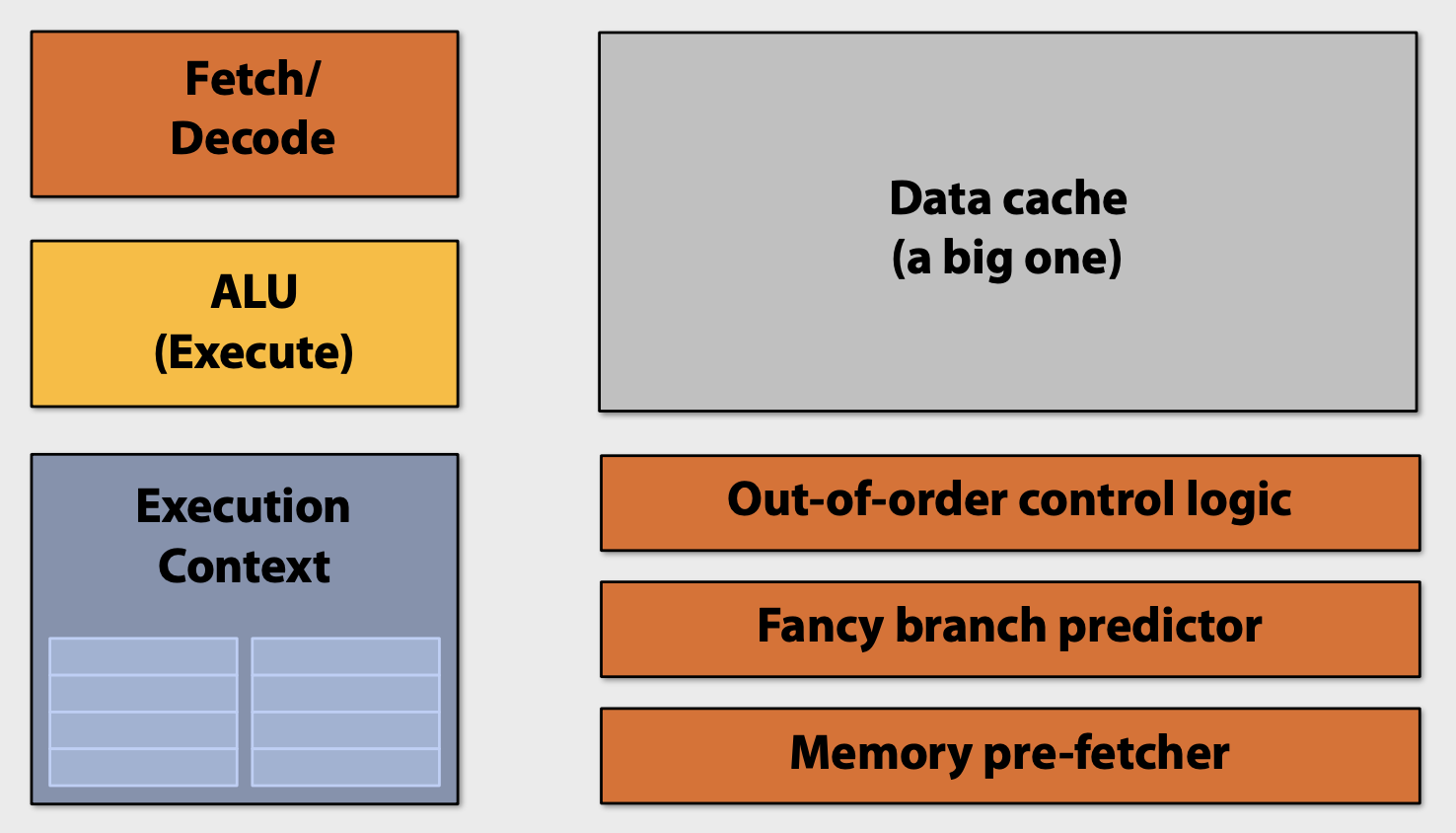
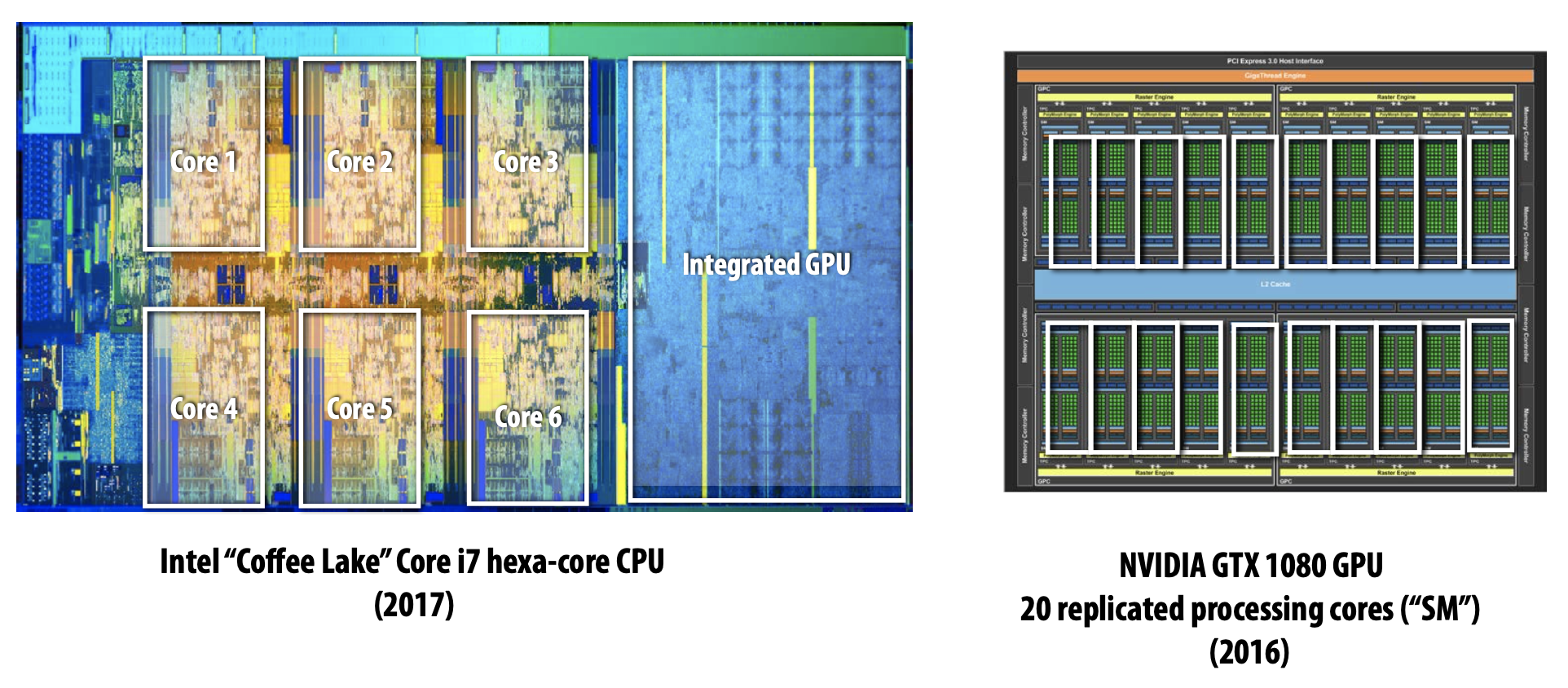
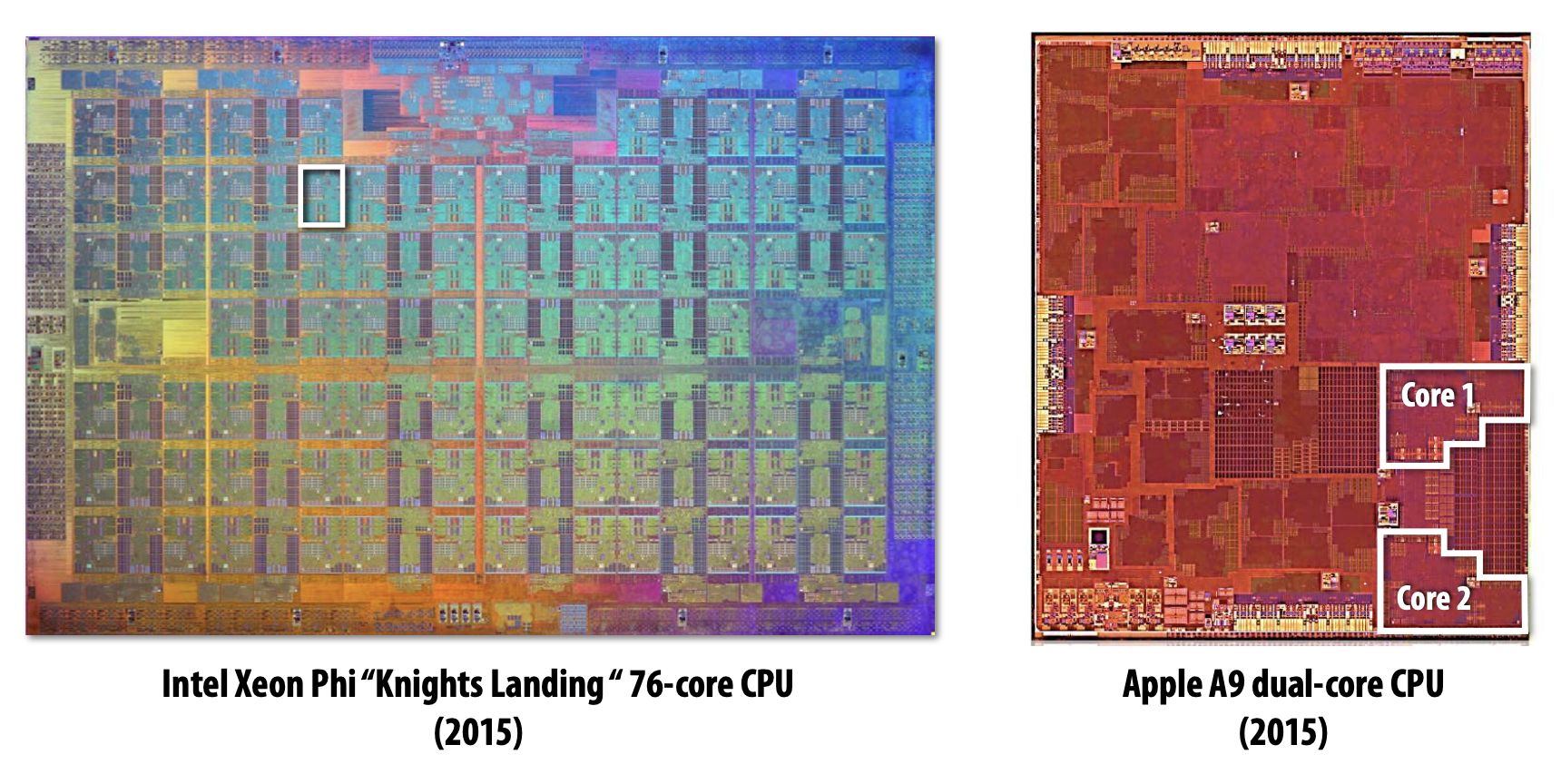
초기의 Multi-Core에서는 하나의 Instruction Stream을 빠르게 수행하도록 돕는 연산을 수행하기 위해 많은 Chip Transistor를 사용하곤 했다. Transistor가 많을수록 Larger Cache, Smarter Out-Of-Order Logic, Smarter Branch Predictor 등 특징을 가졌다.
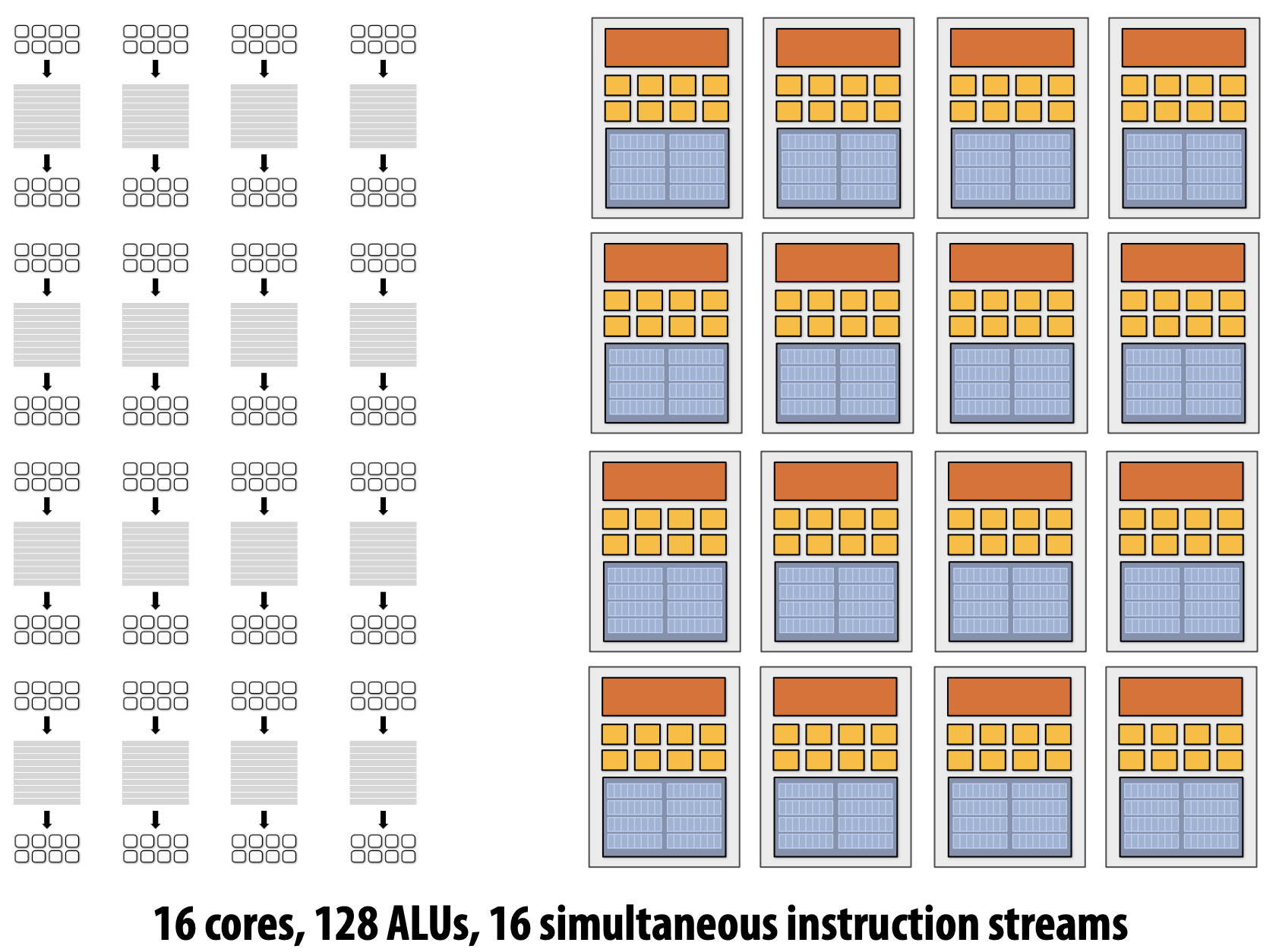
Idea#1 : Modern Multi-Core
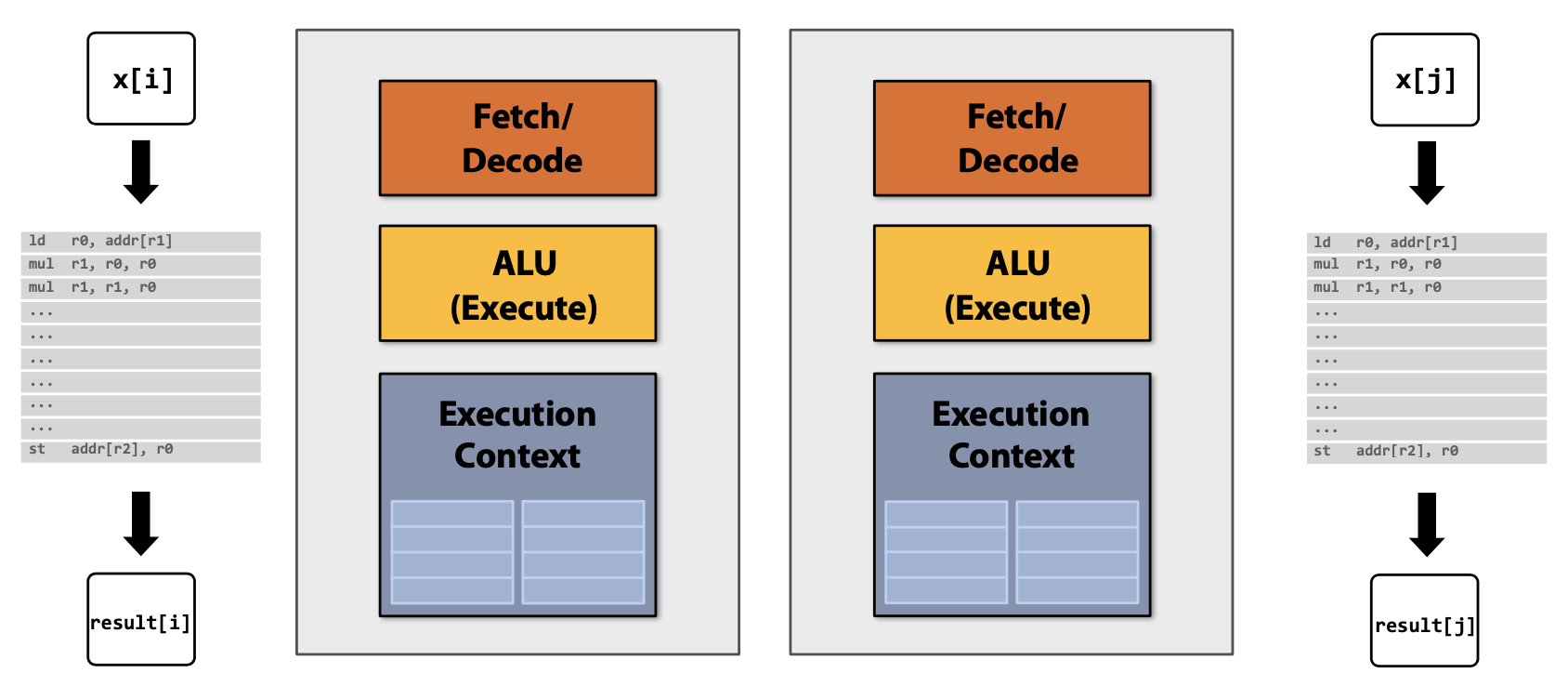
초기와는 다르게 최근에는 Single Instruction Stream을 가속화하는 Processor Logic의 정교함을 높이기 위해 Transisotr를 사용하기 보다 Processor에 더 많은 Core를 추가하기 위해서 더 많은 Transistor Count를 사용한다.
Parallelism(using pthreads) and Data-Parallel(using forall)
생각하기와는 다르게 초기의 좋은 Core보다 각각의 Core는 하나의 Single Instruction Stream을 실행할 때 더 느리다(e.g. 0.75 times as fast). 하지만 지금은 Multi-Core가 되면서 잠재적으로 속도가 향상된다고 볼 수 있다(P * 0.75).
아래에서 pthread는 프로그래머가 직접 Parallelism을 위해 Thread를 생성하는 반면, forall은 프로그래머에 의해 독립적으로 선언된 Loop Iterations의 정보를 통해 pthread와 다르게 어떻게 Compiler가 자동적으로 Parallel Thread Code를 생성한다.
typedef struct{
int N;
int terms;
float* x;
float* result;
}my_args;
void parallel_sinx(int N, int terms, float* x, float* result){
pthread_t thread_id;
my_args args;
args.N = N/2;
args.terms = terms;
args.x = x;
args.result = result;
pthread_create(&thread_id, NULL, my_thread_start, &args); // lanuch thread
six(N - args.N, terms, x + args.N, result + args.N); // do work
pthread_join(thread_id, NULL);
}
void my_thread_start(void* thread_arg){
my_args* thread_args = (my_args*)thread_arg;
sinx(args->N, args->terms, args->x, args->result); // do work
}void sinx(int N, int terms, float* x, float* result){
// declare independent loop iterations
forall(int i from 0 to N-1){
float value = x[i];
float numer = x[i] * x[i] * x[i];
int denom = 6; // 3!
int singn = -1;
for(int j=1; j<=terms; j++){
value += sign * numer / denom;
numer *= x[i] * x[i];
denom *= (2*j+2) * (2*j+3);
sign *= -1;
}
result[i] = value;
}
}
Idea#2 : More ALUs
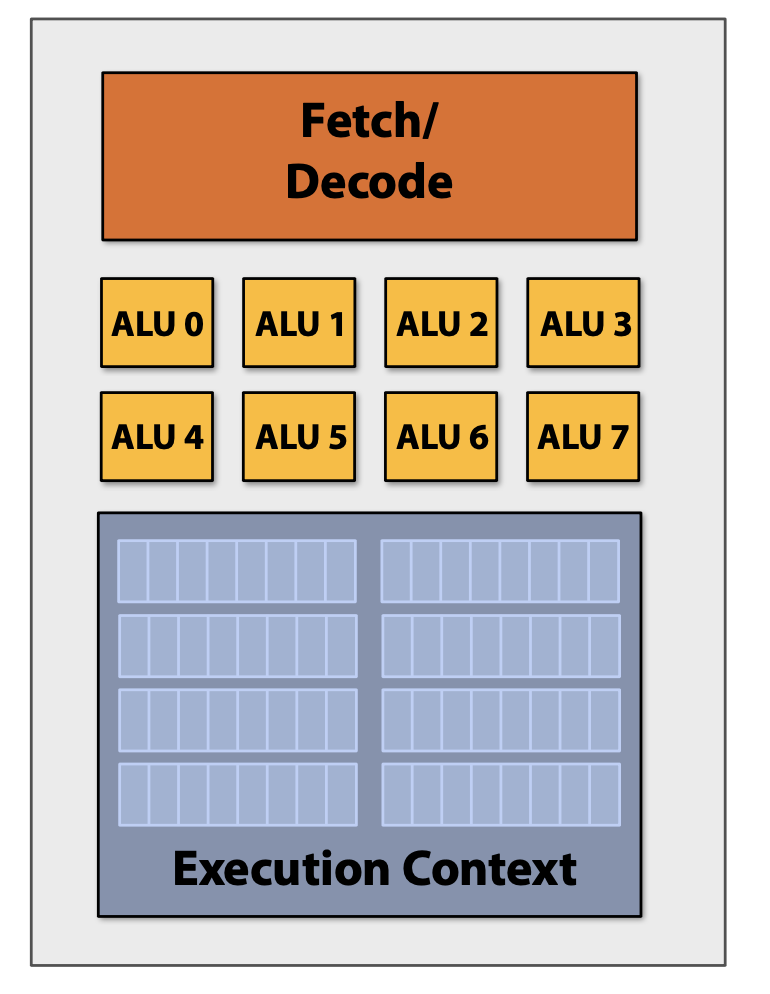
Processor에 존재하는 산술 논리 장치(Arithmetic Logic Unit, ALU)의 수를 증가시켜 Instruction Stream 관리의 Cost와 Complexity에 도움을 준다.
초기의 Compiler Program에서의 Instruction Stream은 Scalar Registers(e.g. 32bit floats)에서 Scalar Instructions을 사용하여 한 번에 하나의 배열 요소만 처리한다.
하지만 SIMD(Single Instruction, Multiple Data) 방법을 통해 Compute Capability를 증가시킬 수 있다. SIMD는 Parallel Processor의 한 종류로 하나의 명령어로 여러 개의 값을 동시에 계산하는 방식이다. 즉, 동일한 Instruction을 모든 ALU에게 Broadcast하고, 모든 ALU에서 병렬적으로 Instruction을 실행하는 것이다.
Vector Program(using AVX intrinsics) and Data-Parallel(using forall)
Intel의 AVX intrinsics를 이용하면 Vector Programming이 가능해진다. 즉, 256bit Vector Registers에서 N개의 배열 요소들을 Vector Instructions을 사용하여 동시에 처리할 수 있어진다.
Idea#1과 동일하게 Idea#2에서도 Data-Parallel을 표현할 수 있다. Compiler는 Loop Iterations이 독립적인 것으로 이해하고, 아래의 Loop Body는 많은 데이터에서 실행되어질 수 있다. 즉, Data-Parallel은 Multi-Core Parallel Code와 Core안에서의 SIMD Processing Capabilities을 사용하기 위한 Vector Instructions 모두를 자동 생성하여 활용할 수 있도록 한다.
#include <immintrin.h>
void sinx(int N, int terms, float* x, float* sinx)
{
float three_fact = 6; // 3!
for (int i=0; i<N; i+=8)
{
__m256 origx = _mm256_load_ps(&x[i]);
__m256 value = origx;
__m256 numer = _mm256_mul_ps(origx, _mm256_mul_ps(origx, origx));
__m256 denom = _mm256_broadcast_ss(&three_fact);
int sign = -1;
for (int j=1; j<=terms; j++)
{
// value += sign * numer / denom
__m256 tmp = _mm256_div_ps(_mm256_mul_ps(_mm256_broadcast_ss(sign),numer),denom);
value = _mm256_add_ps(value, tmp);
numer = _mm256_mul_ps(numer, _mm256_mul_ps(origx, origx));
denom = _mm256_mul_ps(denom, _mm256_broadcast_ss((2*j+2) * (2*j+3)));
sign *= -1;
}
_mm256_store_ps(&sinx[i], value);
}
}void sinx(int N, int terms, float* x, float* result){
// declare independent loop iterations
forall(int i from 0 to N-1){
float value = x[i];
float numer = x[i] * x[i] * x[i];
int denom = 6; // 3!
int singn = -1;
for(int j=1; j<=terms; j++){
value += sign * numer / denom;
numer *= x[i] * x[i];
denom *= (2*j+2) * (2*j+3);
sign *= -1;
}
result[i] = value;
}
}
하지만 만약 코드 내에 조건문이 존재한다면 어떻게 될까? 결과적으로 일부 ALU는 조건문에 의해서 제한되기 때문에 모든 ALU의 성능을 사용하지 못한다. 하지만 분기 부분을 지나게 되면 정상적으로 모든 ALU의 성능을 사용할 수 있다.

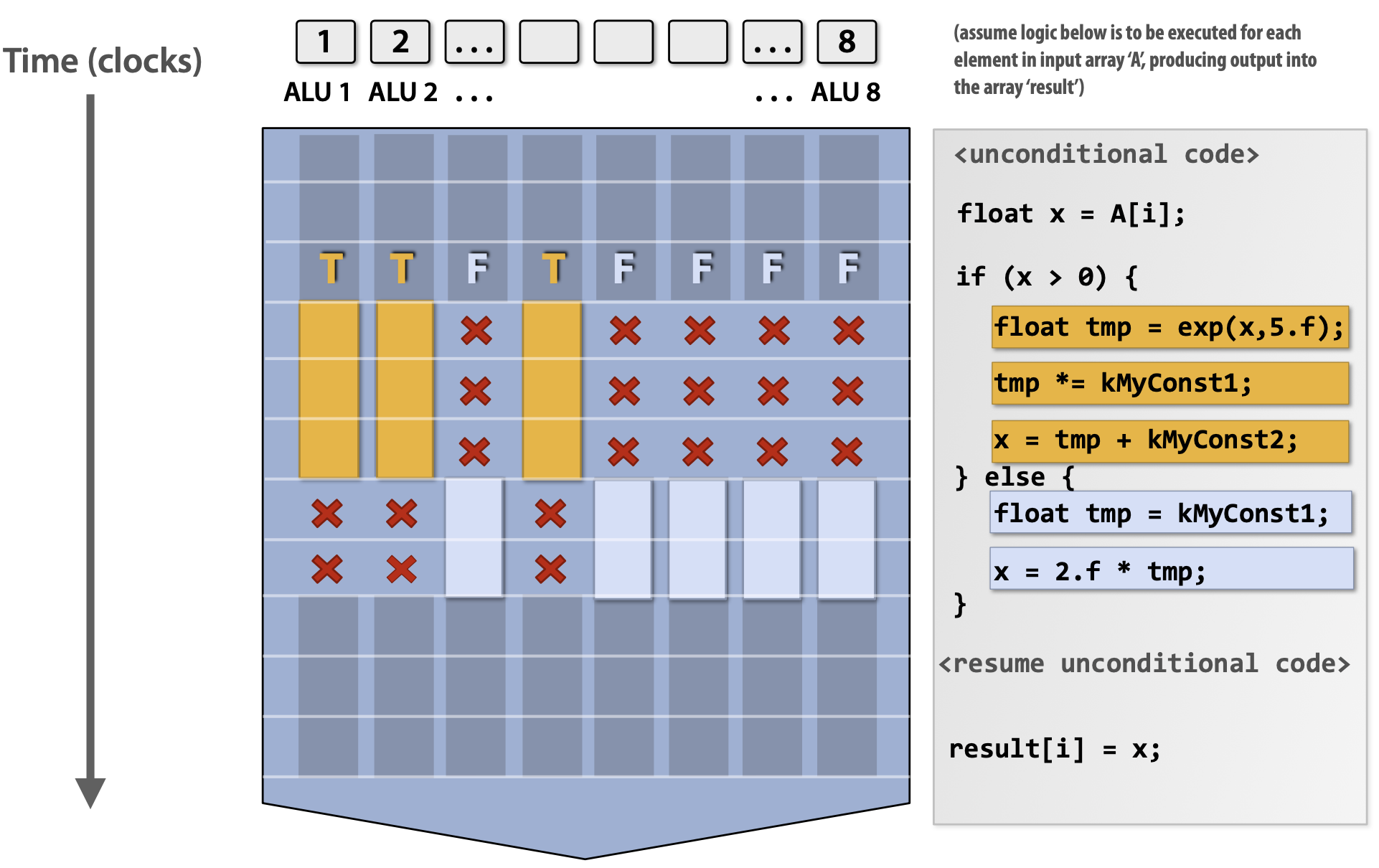
SIMD Execution on modern CPU
- SSE Instructions
- 128bit Opeartions : 4x32bits or 2x64bits (4-wide float vectors)
- AVX Instructions
- 256bit Operations : 8x32bits or 4x64bits (8-wide float vectors)
- Compiler에 의해 생성된 Instructions
- Intrinsics를 사용하여 개발자에 의해 명시적으로 요청된 Parallelism
- Parallel Language Semantics(e.g. forall)를 통해 전달된 Parallelism
- 반복문의 종속성 분석을 통해 예측된 Parallelism(Hard Problem)
- Explicit SIMD : Compile Time에 수행된 SIMD Parallelization
- Program Binary를 검사하고, Instructions을 볼 수 있음(vstoreps, vmulps, etc.)
SIMD Execution on modern GPU
- Implicit SIMD
- Compiler는 Scalar Binary(Scalar Instructions)을 생성함
- 하지만, Program의 N개의 Instance는 Processor에서 항상 함께 실행됨(즉, Hardware의 Interface는 Data-Parallel)
- Compiler가 아닌 Hardware는 여러 SIMD ALU에서 다른 데이터를 가진 여러 Instance의 동일한 Instruction을 동시에 실행하는 것에 책임이 있음
- 가장 일반적인 GPU의 SIMD Width는 8 - 32 Range를 가짐
- Divergence는 큰 문제가 될 수 있음
- 잘 못 짜여진 Code는 Machine의 최고 Capability의 1/32에서 실행될 수도 있음


Parallel Execution Summary
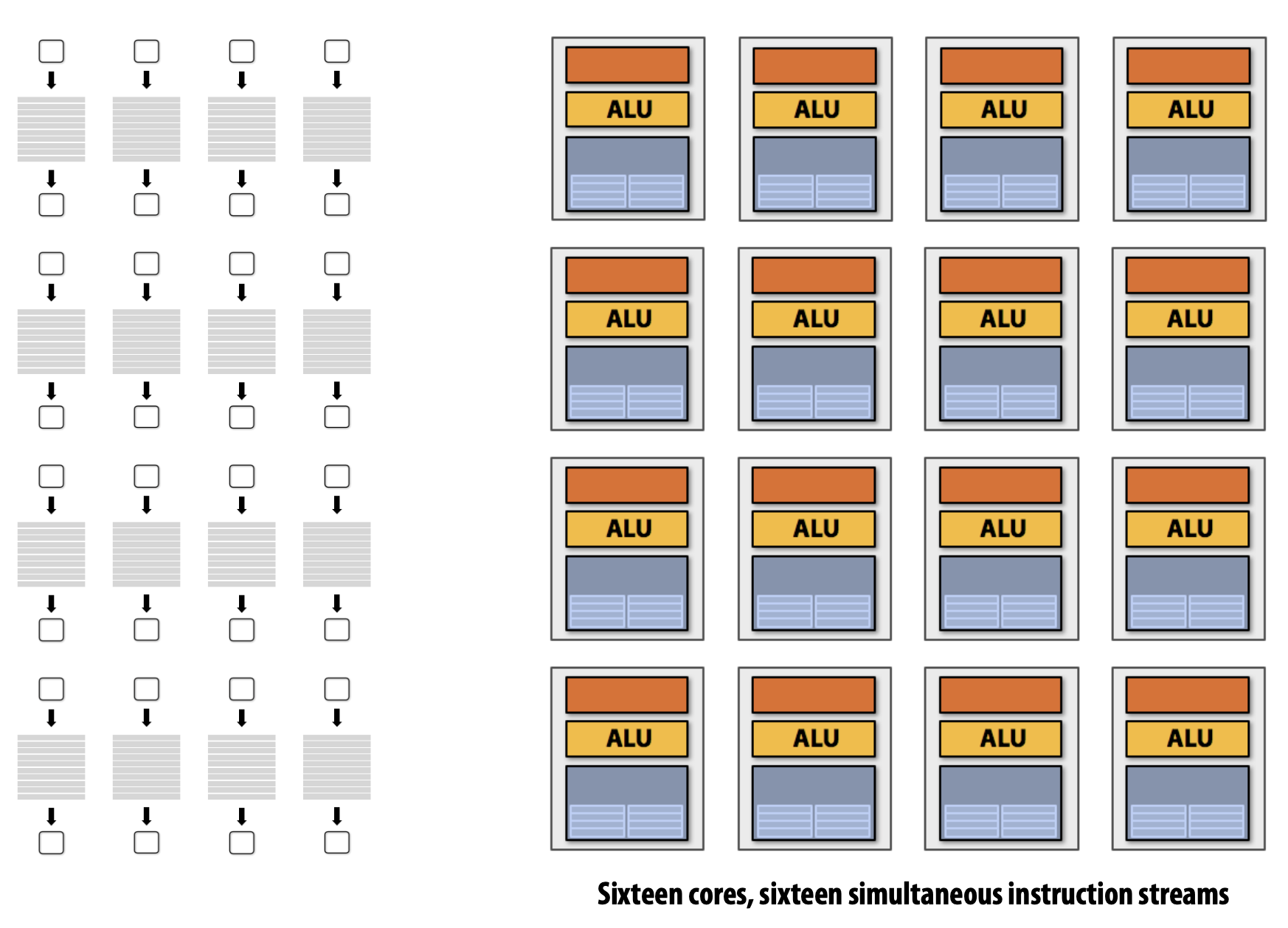
- Multi-Core
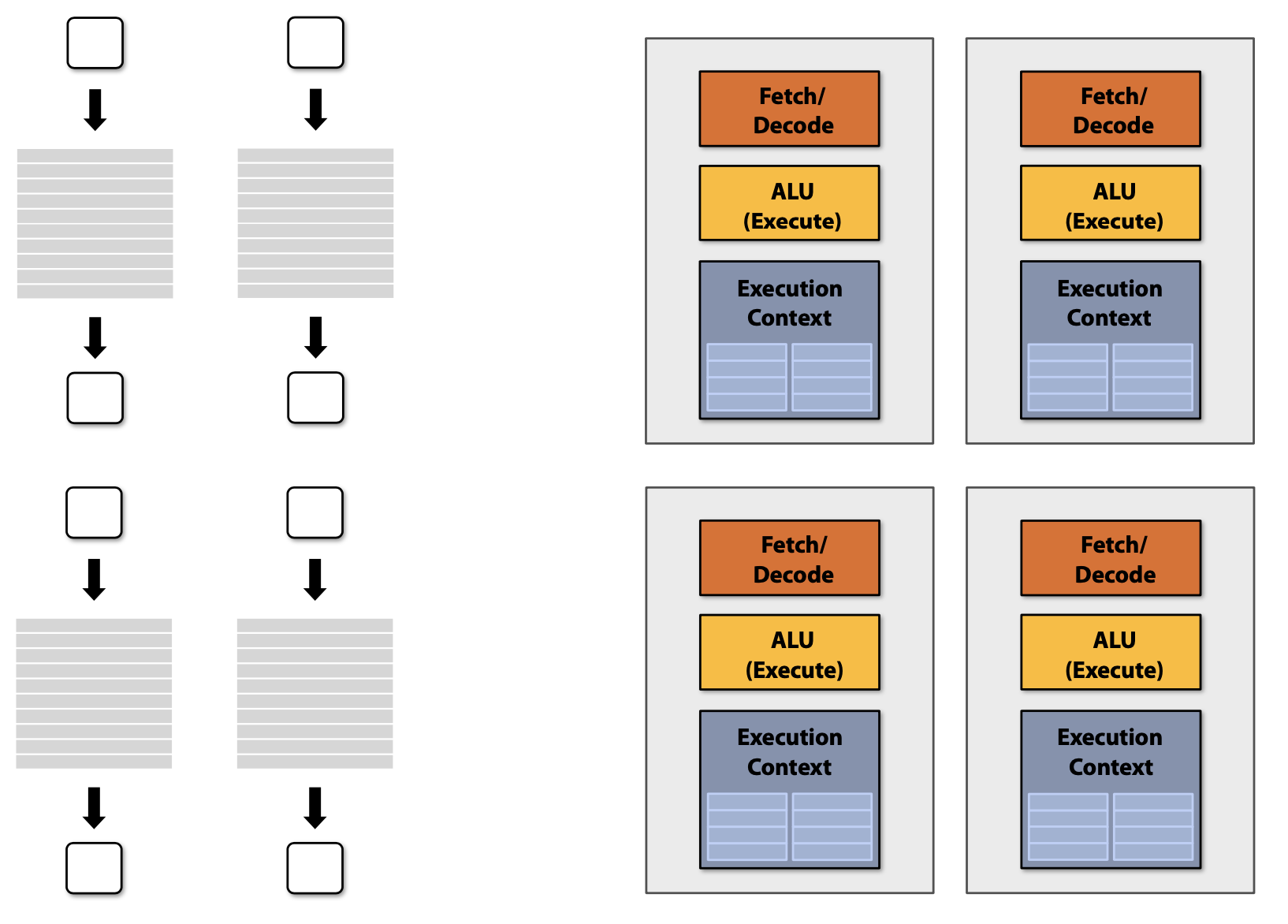
- Thread-Level Parallelism : 각 Core에서 완벽히 다른 Instruction stream을 동시에 수행
- Thread 생성 시기는 Software에 의해 결정(e.g. via pthreads API)
- SIMD
- Core 안에서 동일한 Instruction Stream으로 제어되는 여러 ALU 사용
- Data-Parallel Workload를 위한 효율적인 디자인
- Compiler(explicit SIMD) 또는 Run Time 때 Hardware로 Vectorization이 수행되어질 수 있음
- 종속성은 실행 전에 알려져 있음 : 보통 개발자에 의해 선언되어지지만 Advanced Compiler에서 반복문 분석으로 예측되어질 수 있음
- SuperScalar
- Core 안에서 병렬적으로 동일한 Instruction Stream으로부터 다른 Instructions을 수행(Instruction Stream 안에서 ILP 활용)
- 프로그래머가 볼 수는 없지만 실행 동안 Hardware에 의해 자동으로 동적으로 조사되어지는 Parallelism
Accessing Memory
Terminology
- Memory Latency
- Processor에 의한 Memory Request(e.g. load, store)가 Memory System에 의해 서비스되어지는 총 시간(e.g. 100cycles, 100nsec)
- Memory Bandwidth
- Memory System이 Processor에게 데이터를 제공할 수 있는 속도 및 비율(e.g. 20GB/s)
- Process Stalls
- 이전의 Instruction의 종속성에 의해 Instruction Stream에서 다음 Instruction을 실행할 수 없는 상황
- Memory에 접근하는 것은 Stalls의 주요 원인
Cache/Prefetching/Multi-Threading
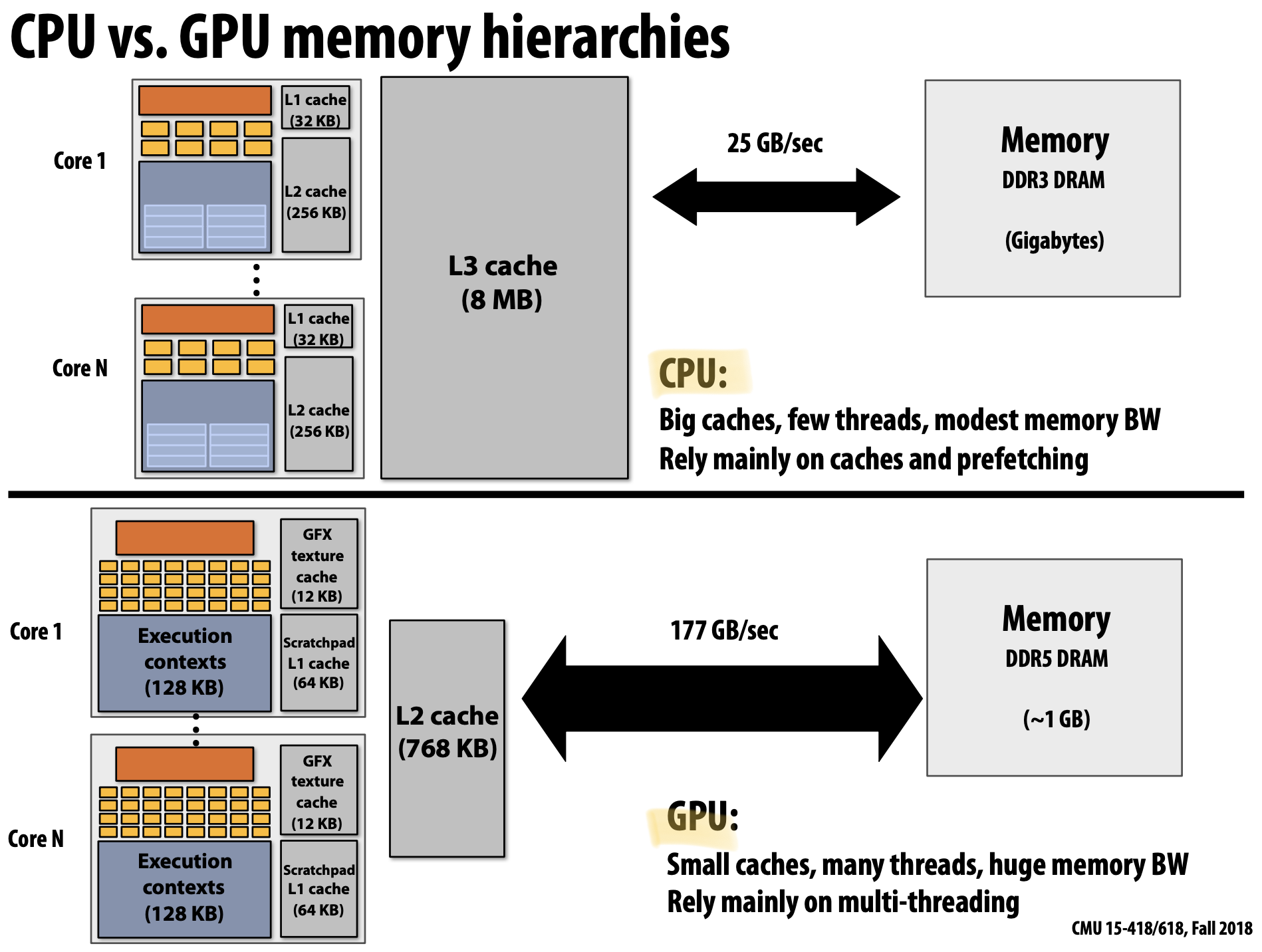
왜 일반적인 Processor에는 여러 Cache를 가지고 있을까? 그 이유는 Latency를 줄이는 것(Reducing)에 목적을 두고 있다. Processor는 Memory와의 상호작용보다 Cache에 존재하는 데이터를 효율적으로 실행시킬 수 있다. 또한 Cache는 CPU에 데이터를 전달하기에 높은 Bandwidth를 가지고 있어 결과적으로 Latency를 줄일 수 있다.
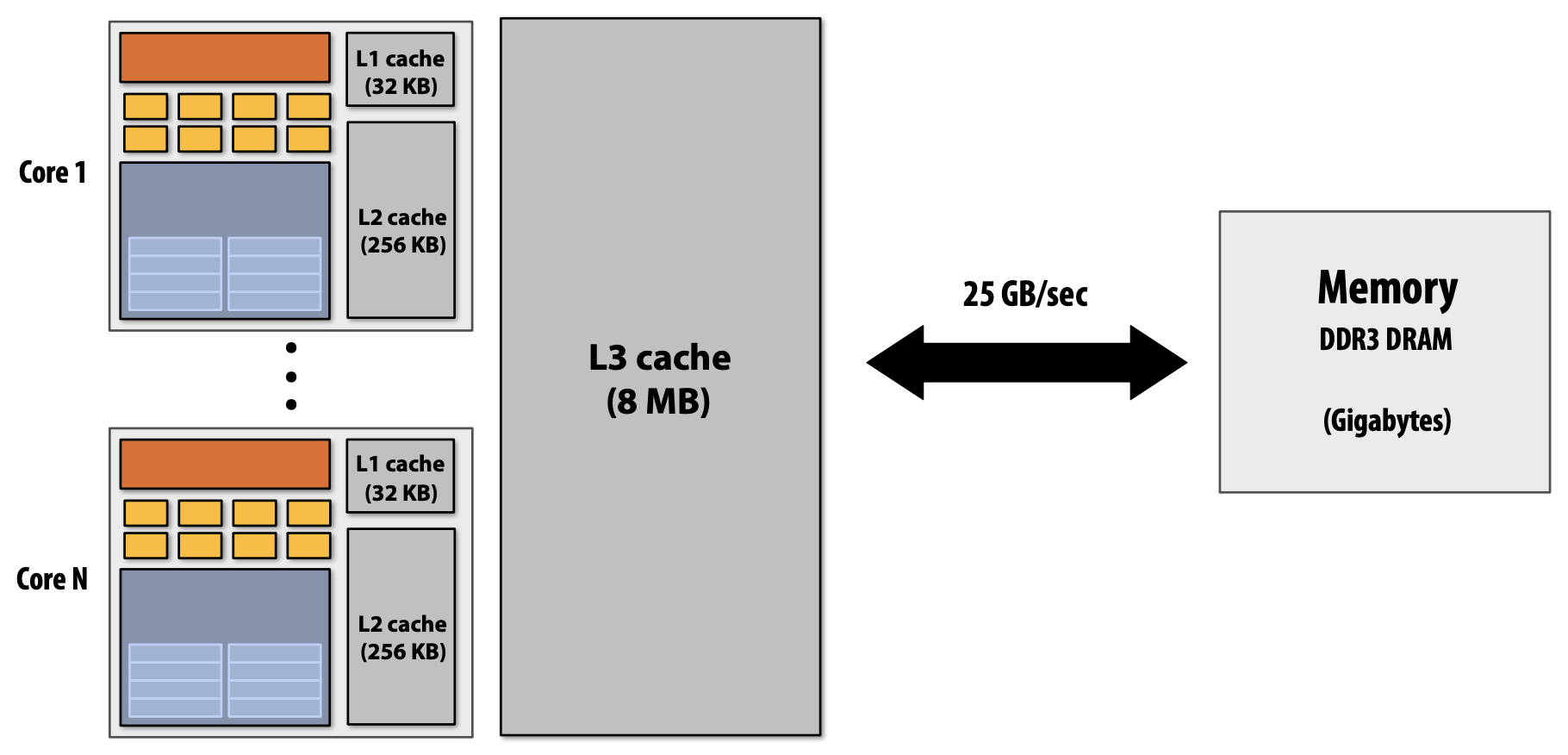
모든 일반적인 CPU는 Cache에서 데이터를 Prefetch하기 위한 Logic을 가지고 있다. 동적으로 프로그램 접근 패턴을 분석하여 다음에 어떠한 데이터가 접근할 것인지를 예측하는 것이다. 이것은 위의 Cache와는 다르게 직접적으로 Latency를 줄이는 것보다 줄여지는 것(Hiding)처럼 보이게 한다. 또한 만약 접근하려는 데이터가 Cache에 존재한다면 Stalls 현상을 줄일 수도 있다. 다만, 예측을 Logic에 의한 예측이 잘못된 경우 오히려 성능을 떨어뜨릴 수 있다. 즉, Bandwidth를 낭비하거나 Cache를 불필요한 데이터로 채울 수 있는 문제가 발생한다.
Multi-Threading은 Stalls 상황을 줄이기 위해 동일한 Core에서 여러 Thread의 Interleave Processing을 수행한다. 또한 Prefetching과 마찬가지로 Latency를 줄이는게 아니라 줄이는 것처럼 보이게 하기도 한다. Throughput-Oriented System의 핵심적인 요소는 여러 Thread를 실행할 때 전체적인 System Throughput을 늘리기 위해 하나의 Thread에서 하나의 작업을 완료하는데 걸리는 시간을 잠재적으로 늘린다.
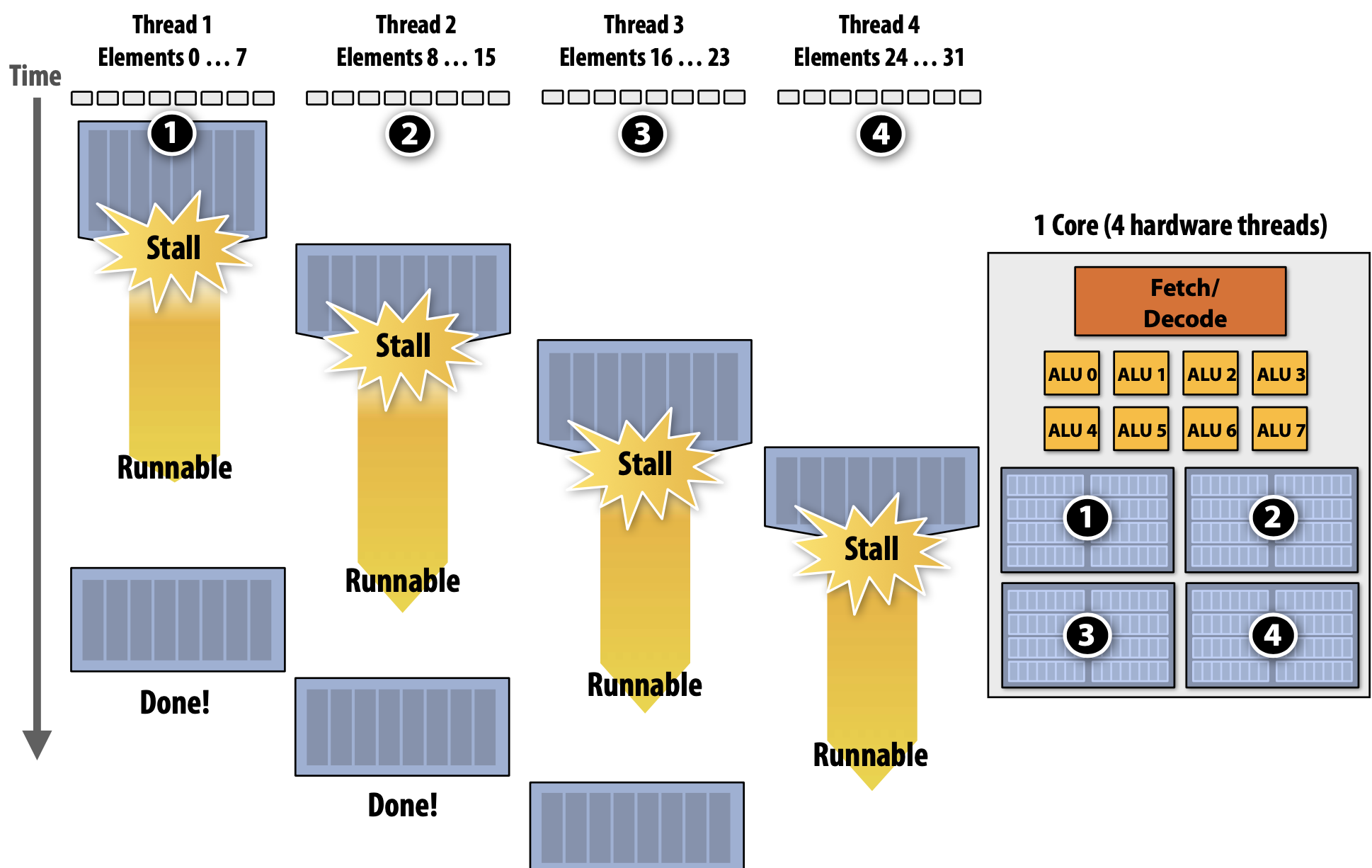
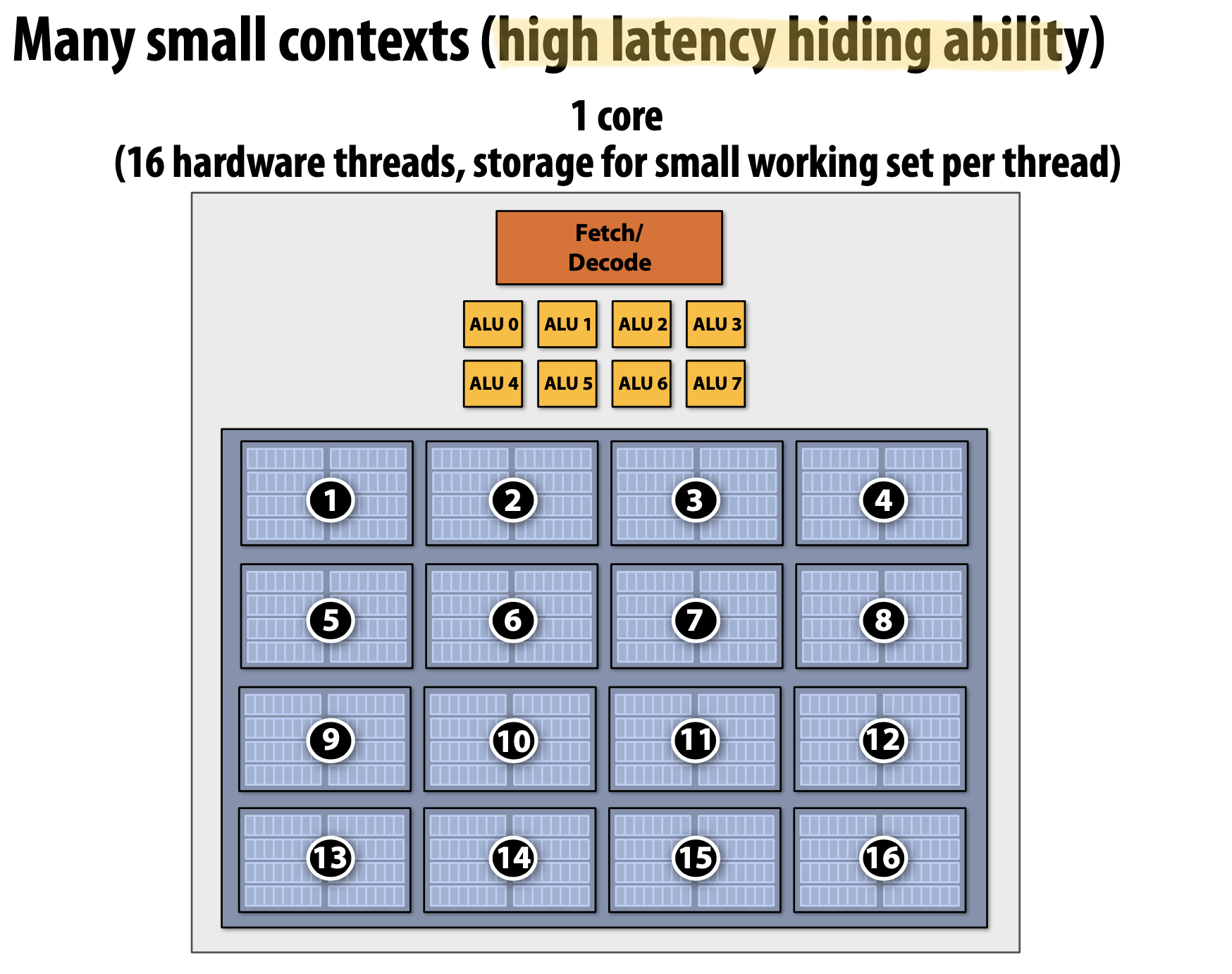
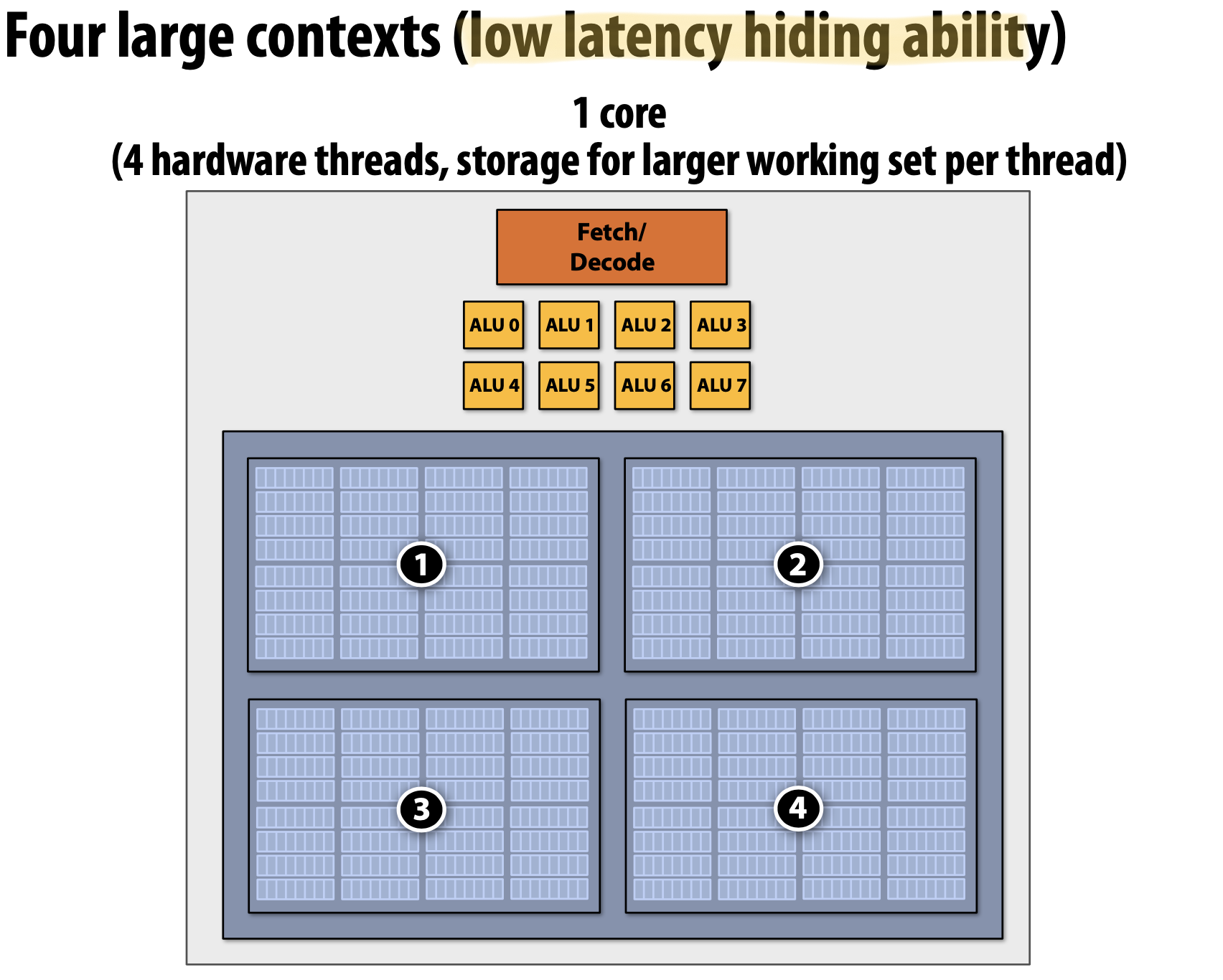
Hardware-Supported Multi-Threading은 여러 Thread를 Core가 Execution Context를 관리한다. 즉, OS가 Thread를 관리하는 것이 아니라 매 Clock마다 어떠한 Thread를 실행시킬지를 Processor가 결정한다는 것이다. 또한 Core는 여전히 동일한 개수의 ALU를 가지고 있어 Multi-Threading은 Memoery Access처럼 High-Latecny Operation에서 효율적으로 사용할 수 있도록 돕는다. Temporal Multi-Threading이라고 불리는 Interleaved Multi-Threading은 매 Clock마다 Core에 의해 선택된 하나의 Thread는 여러 ALU에서 Instruction을 실행하게 된다. Simultaneous Multi-Threading(SMT)는 매 Clock마다 Core가 여러 ALU에서 여러 Thread의 Instructions을 선택한다. 이것은 SuperScalar CPU 디자인의 확장으로 볼 수 있다.
Multi-Threading Summary
- Benefit : Core의 ALU Resources를 효율적으로 사용
- Memory Latency를 줄이는 것처럼 보일 수 있음
- 하나의 Thread가 부족한 ILP를 가질 때 SuperSclalar Architecture의 여러 기능적인 부분을 채울 수 있음
- Costs
- Thread Contexts를 위한 추가적인 저장 공간 필요
- Single Thread의 실행 시간 증가(자주 일어나는 문제는 아니지만 병렬 처리에서는 처리량을 신경써야함)
- Program에서 추가적인 독립된 Work가 필요함(ALU보다 많은 독릭적인 Work)
- Memory Bandwidth에 크게 의존적(More Threads → Larger Working Set → Less Cache Space per Thread)
Bandwidth Limited
만약 Processor가 상당히 높은 Bandwith으로 데이터를 요구하게 된다면 어떻게 될까? Memory System은 이를 따라갈 수 없게 된다. 즉, 더이상 Latency Hiding은 이러한 상황을 도와줄 수 없게 된다. 이러한 Bandwidth Limit을 해결하려는 문제는 Throughput-Optimized System에서 Application 개발자에게 상당히 흔한 것이다.
Bandwidth는 상당히 중요한 자원이기 때문에 우리는 조금이나마 문제를 해결하기 위해 두 가지 방법을 지키는 것이 좋다. 첫 번째, 고성능의 병렬 Program은 Memory에서 데이터를 덜 자주 가져오도록 연산을 구성하는게 좋다. 즉, 동일한 Thread에서 불러진 이전의 데이터를 재사용하거나 Thread 간에 데이터를 공유하는 것이다. 두 번째, 데이터를 덜 자주 요청하는 것이 좋다. 즉, 데이터를 요청하는 것보다 산술적인 수학 연산의 비중을 높이는 것이다. 왜냐하면 산술적인 연산은 Bandwidth에 제약이 없기 때문이다.
Summary
- 모든 최신 Processor가 다양한 수준으로 사용하는 세 가지 아이디어
- Multiple Proecessing Cores
- Many ALUs(SIMD) : 작은 추가 비용으로 연산 Capability를 늘일 수 있음
- Multi-Threading : Processing 자원을 효율적으로 사용 가능(Latency Hiding, etc.)
- 최신 Chip에 높은 산술 Capability 때문에 CPU와 GPU 모두에서 많은 병렬 Application은 대역폭 제한이 존재함
- GPU Architecture는 CPU와 동일한 Throughput Computing 방법을 사용하지만, 개념을 보다 극단적인 모로 확장시킴