
0. 요약
GAN inversion은 이미지를 GAN의 latent code로 전환하는 것입니다.
이 논문에서는 현재까지 진행된 GAN inversion의 의 전체 과정을 정리하였습니다.
1. Introduction
이 논문은 특별한 실험을 한 논문이 아닌 GAN Inversion이라는 방법의 현 트렌드를 정리하는 논문입니다. GAN Inversion이 무엇인지, 어떤 방법으로 이루어 지는지, 현 문제점 및 향후 연구 과제 등을 제안합니다.
2. Problem Definition and Overview
Given an image, GAN inversion aims to recover the latent code in a latent space of a pretrained uncon- ditional GAN model, and thus enables numerous image editing applications by manipulating the latent code. In this case, the pretrained unconditional GAN model can be used without modifying the architecture.
GAN inversion은 이미지가 주어졌을 때, GAN모델의 latent space에서 latent code를 찾는 것입니다. 그리고 찾은 latent code를 수정하여 입력 이미지를 원하는 방향으로 수정하는 것이 목적입니다.
Ideally the found latent code of the given image should achieve two goals: 1) reconstructing the input image faithfully and photorealistically and 2) facilitating downstream tasks.
이미지로부터 latent code를 찾아내는 것은 최소한 두가지를 달성해야 합니다.
- 입력 이미지를 신뢰성있고 사실적으로 복원할 수 있어야 합니다.
- downstream tasks를 용이하게 해야 합니다.
2.1 reconstructing
이 과정에서 GAN 모델을 따로 학습하거나 구조변경을 하지 않고 latent code만 변경하여 원하는 이미지를 얻어낼 것입니다.
GAN inversion에 대해 이해하기 전에 몇가지 용어와 수식을 정리하겠습니다.
원하는 latent code(Z*)를 찾는 것은 다음과 같은 수식으로 나타낼 수 있습니다.
- G()함수는 latent code(z)가 들어왔을 때, 이미지(x)를 생성하는 함수로 uncondifional GAN의 Generator입니다.
- l()은 평가지표로 보통 MSE, perceptual나 LPIPS 등을 사용합니다.
- 이 수식으로 구해진 Z는 원본 이미지를 복원할 수 있는 latent code를 의미하며, 이 Z를 조작하여 수정된 이미지를 얻을 수 있습니다.
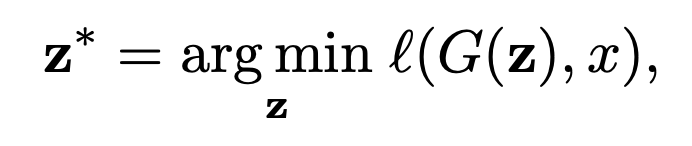
2.2 downstream tasks
downstream taks는 우선적으로 어떤 latent space를 사용할지 정해야 합니다(뒤에서 추가로 설명합니다). 그리고 어떻게 최적화 식을 푸는지에 따라 downstream task가 결정됩니다.
이 과정은 크게 3가지로 나뉩니다.
- learning-based: 이미지를 latent space로 변환하는 encoder를 학습하는 방법.
- optimization-based: back-propagation을 통해 최적화를 진행하는 방법.
- hybrid: 위 두 방식을 조합하여 이용하는 방법
일반적으로 learning-based로 생성된 latent code는 원본 이미지를 제대로 복원하지 못합니다. 반면에 optimization-based 방식은 원본을 유사하게 복원할 수 있는 latent code를 찾을 수 있지만, 계산해야 할 것이 많습니다. hybrid 방식은 learning-based로 초기 latent code를 구하고 optimization-based를 적용하는 방식입니다.
최근 연구에서 위에서 말한 단점을 보완하는 식으로 진행합니다. learning-based방식은 정확도를 향상시키는 방법에 대해 연구가 필요하고, optimization-based방식은 더 빠르게 계산하는 방법을 찾는 연구가 진행중입니다. 정확도와 시간은 trade-off 관계로 hybrid방식은 적절한 조합을 제공하지만, 여전히 연구가 필요합니다.
3. Preliminaries
3.1 GAN Models and Datasets
이미지를 생성하는 GAN에 대해서는 구조와 datasets, loss 등이 제안되었지만, 3D-aware GAN들은 아직 많은 연구가 필요합니다.
3.1.1 GAN Models
- DCGAN
Discriminator(D)와 Generator(G)에 conv를 적용한 GAN 입니다. - WGAN
생성된 데이터 분포와 실제 데이터 분포 사이의 Wasserstein distance를 최소화 하여 모델을 더 안정적이게 하고 training process를 더 쉽게 하였습니다. - BigGAN
모델 구조를 수정하여 상대적으로 큰 크기에 대해(256x256 이나 512x512) 학습이 가능하게 하였습니다. - PGGAN
점진적으로 GAN이 만들 수 있는 이미지를 크게 하여 1024x1024 크기의 이미지를 생성할 수 있게 하였습니다. - Style-based GAN
이미지 생성을 위한 계층적 잠재 스타일을 암시적으로 학습한다. 이 모델은 채널당 평균 및 분산을 조작하여 이미지의 스타일을 효과적으로 제어합니다.
3.1.2 Datasets
- ImageNet
14M 이상의 이미지, 20000개 이상의 category - CelebA
large-scale의 celebrity images with 40 attribute annotations. - Flickr-Faces-HQ (FFHQ)
Flickr에서 가져온 고퀄리티 얼굴 이미지 데이터셋(1024x1024) 약 7만장 - LSUN
10개 범주(침실, 교회 같은 장소) 20개 클래스(새, 고양이 등 물체)
이 외에도 DeepFashion, AnimeFaces, StreetScapes 등등 다양한 데이터셋을 사용하기도 한다.
3.2 Evaluation Metrics
photorealism, faithfulness of the recon- structed image, and editability of the inverted latent code.
3.2.1 photorealism
"얼마나 사실적으로 복원이 되었는가?"를 평가하는 지표로 사용됩니다.
- Inception score
GAN 모델에서 생성된 이미지의 품질과 다양성을 측정하기 위해 널리 사용되는 메트릭입니다. ImageNet에서 사전 훈련된 Inception-v3 네트워크를 사용하여 합성된 이미지의 통계를 계산합니다. 점수가 높을수록 좋습니다. - FID
실제 이미지와 Inception-v3 pool3 layer로 생성된 이미지의 feature vector간의 Frechet distance로 정의됩니다. FID가 낮을수록 지각 품질이 우수함을 나타냅니다. - Learned perceptual image patch similarity(LPIPS)
실제 이미지와 생성된 이미지를 VGG 모델을 사용 perceptual 품질을 계산합니다. 점수가 낮을수록 좋습니다.
3.2.2 faithfulness
faithfulness는 실제 이미지와 생성된 이미지의 유사도를 측정하는 방법입니다.
- MAE, MSE, RMSE
- Peak signal-to-noise ratio(PSNR)
이미지들의 최대 가능(possible) 픽셀 값과 이미지들 사이의 평균 제곱 오차로 정의됩니다. - Strucural similarity (SSIM)
휘도, 대비 및 구조 측면에서 독립적인 비교를 기반으로 이미지 간의 구조적 유사성을 측정합니다.
3.2.3 Editability
latent code를 수정하여 이미지의 어떤 속성을 수정할 수 있는지를 평가하는 항목입니다. 직접적으로 평가하는 것은 어렵고 보통 cosine, Euclidean distance나 분류 정확도를 사용합니다.
보통 얼굴과 관련된 속성들을 평가합니다.
3.2.4 Subjective Metric
위 평가지표와는 별개로 사람이 매기는 지표를 나타냅니다.
4. GAN Inversion Methods
여기서는
- GAN모델들의 다양한 latent space를 소개하고,
- 대표적인 GAN inversion 방법과 속성들을 소개합니다.
4.1 Which Space to Embed - From Z Space to P Space
GAN inversion 방법과 무관하게 latent space를 정하는 것도 중요합니다. 좋은 latent space는 disentangled되어 있고(각 특징들이 잘 구분되어 있는 상태를 말합니다.), embed하기 쉬워야 합니다.
latent code는 위에서 말했듯이
-
원본 이미지를 복원할 수 있어야 하며
-
downstream image editing taks를 할 수 있어야 합니다.
이 차이 때문에 적절한 latent space를 찾아야 합니다. -
Z space
분포로 부터 직접적으로 추출되는 latent sppace입니다.
Z space는 정규분포로 투영되었기 때문에 표현의 한계와 disentangle합니다. -
W and W+ space
최근 GAN inversion 방법은 대부분 StyleGAN에서 사용되는 latent code입니다. 이 latent code는 더 높은 자유도를 가지고 있고 Z space보다 표현력이 좋습니다.
StyleGAN은 native z를 mapping network f를 통해 style vector w로 매핑합니다. 이 style vector가 가지는 공간을 W space로 부릅니다.
W space가 z space 보다 더 disentangled되어 있지만, 이미지를 복원하기에 충분한 크기가 아닙니다. 이를 보완하기 위해 W+ latent space를 사용합니다. W+ 다른 중간 latent vector W가 AdaIN을 통해 각각의 generator의 레이어에 들어갑니다. -
S Space
S space는 채널별 스타일 매개 변수 s 에 의해 확장되며, 여기서 s는 생성기의 각 레이어에 대해 서로 다른 학습된 affine transformation을 사용하여 w ∈ W에서 변환됩니다. -
P Space
PULSE에 따르면 Generate가 latent space가 적당한 모양을 찾아갈 때 soap bubble(비누 거품) 효과를 발생한다는 것을 관측했습니다.
soap bublle이란 데이터의 분포가 가우시안 형태를 띄지만 고차원에서 거품의 표면처럼 분포의 표면에 밀집하는 현상을 뜻합니다. 이런 현상을 개선하기 위해 제안된 latent space가 P space입니다.
p = InverseLeakyReLU(w)로 p와 w의 관계를 표현할 수 있으며, StyleGAN의 z -> w 매핑 네트워크의 마지막 LeakyReLU를 0.2 기울기를 가지고 있어서, w -> p 매핑은 단순시 0.2의 LeakyReLU를 복원할 수 있는 5의 기울기를 가진 LeakyReLU를 사용합니다.
또한 그들은 latent code의 공동 분포가 대략 다변량 가우시안 분포라는 가장 간단한 가정을 하고 종속성을 제거하고 중복성을 제거하기 위해 P_N 공간을 추가로 제안합니다. P_N space는 P space에서 PCA whitening으로 얻어집니다.
4.2 GAN Inversion Methods
방법은 위에서 말한대로 크게 3가지로 분류됩니다.
- learning based
- optimization based
- hybird
4.2.1 Learning-based Inversion
encoding neural network E(x; Theta)를 구하는 방법입니다.
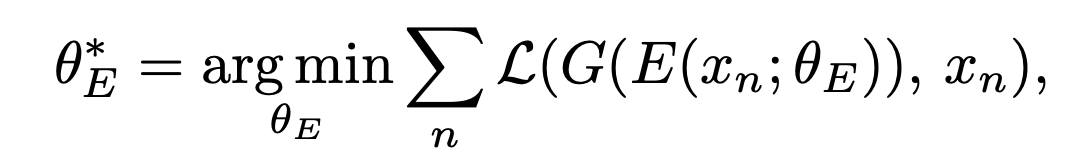
- x_n은 데이터셋에서 n번째 이미지를 의미합니다.
- E는 encoder(여기서 최적화하는 파라미터를 가진 모델), G는 decoder(보통 GAN의 Generator로 고정된 파라미터를 사용합니다.)를 의미합니다.
좋은 encoder는 다음과 같은 속성을 지닙니다.
- 가벼운 모델이다.
- 데이터 효과적이다.
- 고해상도 이미지 생성을 지원한다.
- 임의 이미지에 대한 일반화 가능성을 가져야 한다.
StyleGAN의 등장 이후, 대부분의 encoder는 StyleGAN을 위해 제작합니다.
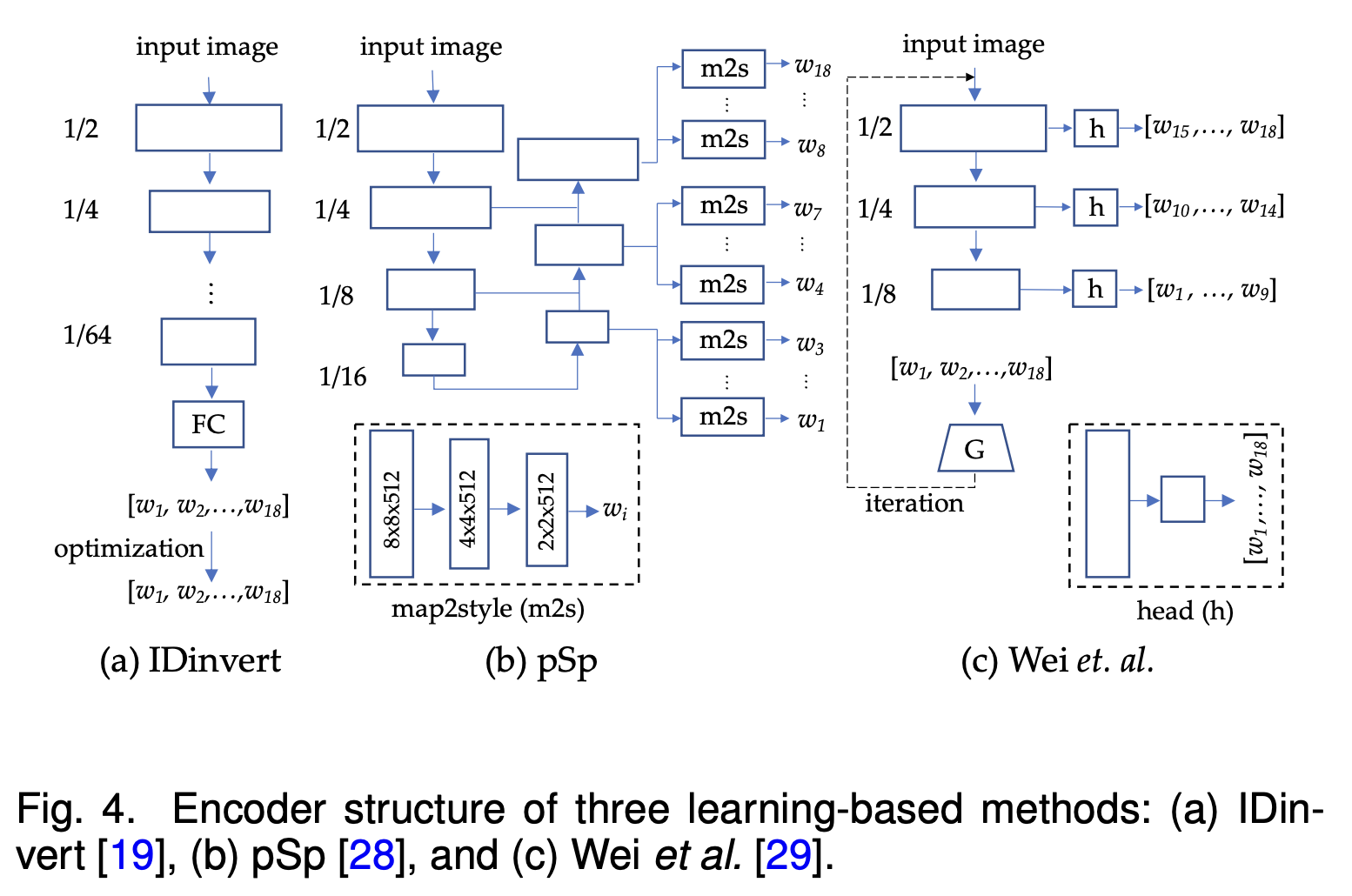
위 그림은 다양한 논문에서 제시한 encoder의 구조입니다.
4.2.2 Optimization-based Inversion
보통 latent vector를 다음과 같은 최적화 식을 사용하여 구해집니다.
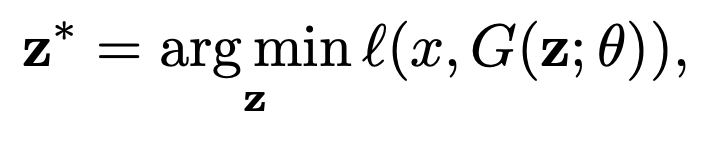
- x는 복원할려는 이미지입니다.
- G는 GAN의 Generator입니다.
최적화 기반에서는 크게 다음 항목들이 중요합니다.
- 국소최소해 문제때문에 옵티마이저를 선택하는게 중요합니다. 크게 두 가지 방식의 옵티마이저가 존재합니다.
- Gradient-based
- gradient-free
- 최적화 하려는 latent code의 초기값 문제(initialization)
위 방정식은 매우 nonconvex하기 때문에 이미지 복원 성능은 좋은 초기값을 선택하는 것이 중요합니다. 실험적으로도 다른 초기값이 상당한 perceptual 차이를 나타냈습니다.
랜덤으로 초기값을 설정하는 것은 언제 최적화될지 모르기 때문에 실시간 처리가 불가능합니다.
초기값으로 mean latent code로 시작하는 방법이 있습니다.
일반적으로 최적화 기반은 많은 시간과 자원(memory)이 필요합니다.
4.2.3 Hybrid GAN Inversion
말 그대로 하이브리드 방식은 위에서 말한 두 방식의 장점을 섞은 방법입니다. learning-based으로 초기값을 구한 뒤 gradient-based을 진행하는 방법입니다.
4.3 Properties of GAN Inversion Methods
GAN inversion은 다음과 같은 속성들을 가집니다.
4.3.1 Supported Resolution
고해상도 이미지를 지원해야 합니다.
GAN Inversion으로 생성하는 이미지의 해상도는 Generator의 능력으로 결되는 사항입니다.
4.3.2 Semantic Awareness
의미적 인식
이 속성은 GAN inversion은 픽셀 단위의 수정이 가능해야 하며 latent space위에서 latent code를 변경할 수 있어야 합니다.
이를 수식적으로 풀어쓰면 다음과 같습니다.

여기서 ||연산자는 l2 distance를, Theta_E는 encoder E()의 파라미터를 의미합니다.
이 과정을 통해 이미지를 수정합니다.
위 수식을 확장하여 픽셀 단위뿐만아니라 의미적 단계의 수정도 가능합니다. 위 수식을 다음과 같이 변형할 수 있습니다.
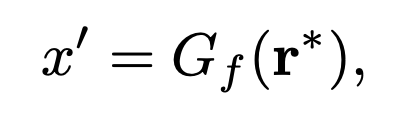
- F()는 VGG feature extraction을 의미합니다.
(이 항은 perceptual loss를 나타낸다고 볼 수 있겠습니다.) - E[D()]는 discriminator loss를 의미합니다.
위 수식을 이용하여도 픽셀 단위의 수정에서 보완이 필요합니다.(위 과정은 domain-guided encoder를 나타내며 learning-based방식입니다. learning-based의 장단점을 갖기 때문에 원하는 이미지로 복원해주는 정확한 latent code는 구하기 어렵다는 단점을 가지고 있습니다.)
위 과정을 두 단계로 나눌 수 있습니다.
1. 위 과정을 통해 local minimum 문제를 피할 수 있는 중간단계의 latent code를 구합니다.
2. 중간단계의 latent code를 optimization-based에 적용하고 위 수식들을 정규화 항으로 가져갑니다.
2번 단계를 수식으로 풀면 다음과 같습니다.
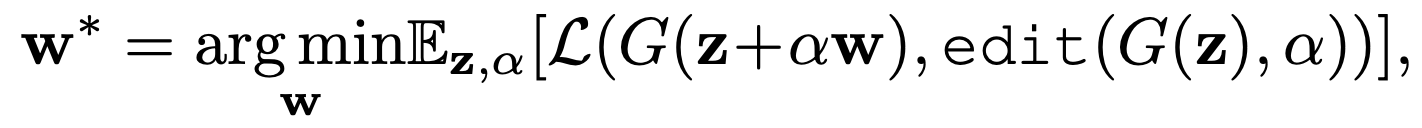
- x는 변환할 타겟 이미지입니다.
4.3.3 Layerwise
이미지 생성에 대한 문제에서, 생성자 함수를 역으로 계산하는 것은 매우 어렵습니다. 따라서 몇몇 최근 연구들은 Generator를 층(layer)으로 분해하여 계산하는 방법을 제안하고 있습니다. 예를 들어, 다음과 같이 하나의 층만 가지는 모델인 경우, 선형 프로그래밍을 사용하여 해결할 수 있습니다.
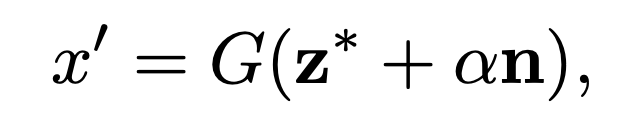
- g_n은 Generator에서 n번째 레이어를 의미합니다.
그러나 이 방법은 근사적인 해결책을 제공하며, 깊은 신경망의 경우 정확한 해결책을 제공하기 어렵습니다. 몇몇 연구들은 이를 보완하기 위해 추가적인 가정들을 사용하고 있지만, 이러한 가정들은 실제 상황에서 일반적으로 성립하지 않습니다.
Bau는 복잡한 최신 GAN을 역전시키는 방법으로, 생성자 함수의 마지막 층을 역전시키는 문제를 해결하는 것을 제안합니다. 먼저 전체 생성자 함수를 근사적으로 역전시키는 신경망 E를 만들고, 이를 사용하여 재구성된 이미지 Gf(r∗)을 생성하는 중간 표현 r∗를 식별하는 최적화 문제를 해결합니다.
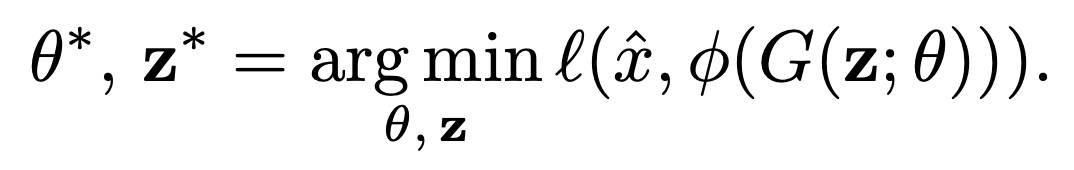
각 층 gi에 대해 작은 신경망 ei를 학습하여, gi의 출력을 잘 보존하는 ri를 근사적으로 계산합니다. 그 후, 모든 층을 역전시키면 G의 전체 역전시켜주는 신경망 E∗를 구성할 수 있습니다. 이 방법은 Sample z와 층 gi를 사용하여 ri−1과 ri의 샘플을 계산하여 생성자가 만드는 표현 manifold에 가까운 표현만 사용하여 학습합니다. StyleGAN의 경우 각 층에 대해 다른 중간 표현 w 또는 s를 사용하므로, 이미지를 W+ 또는 S 공간으로 역전시키는 것을 층별로 볼 수 있습니다.
4.3.4 Out-of-Distribution Generalizability
GAN inversion 기법은 특정 데이터셋에서 생성된 이미지 뿐만 아니라, 해당 데이터셋과 다른 이미지들을 역전시킬 수 있어야 합니다.
이 능력은 GAN inversion 기법이 더 넓은 범위의 이미지를 수정할 수 있도록 하는 전제 조건입니다.
그러나, 데이터셋에서 보지 못한 새로운 속성을 가진 이미지를 역전시키면 예상치 못한 결과가 발생할 수 있기 때문에 이러한 경우에는 GAN inversion이 한계가 있습니다.
이러한 문제를 완화하기 위해, 일부 연구들은 GAN을 다른 이미지 도메인으로 전이시키는 방법을 제안하고 있습니다. 이러한 전이 방법은 몇 가지 대상 이미지를 기반으로하는 few-shot/one-shot 방법, pretrained language-image 모델을 사용하는 zero-shot 방법, 그리고 양쪽 모두를 고려하는 방법 등이 있다. 최근 기술들은 이미지뿐만 아니라 스케치나 텍스트 등 다른 모달리티에서도 out-of-distribution generalizability를 보여주고 있다.
4.4 Latent Space Navigation
우리가 GAN Inversion을 하는 이유는 이미지의 특정 속성을 재배열 하기 위해서 잠재 공간에서 inverted된 code를 변화시킬 수 있기 때문입니다.
4.1에서는 다른 latent space를 소개했습니다. 여기서는 GAN의 latent space에서 해석 가능하고 disentangled 방향을 찾는 방법을 소개합니다.
4.4.1 Discovering Interpretable Directions
일부 방법은 잠재 공간에서 해석 가능한 방향을 발견하는 것을 지원합니다. 즉, 원하는 방향 n에서 잠재 코드 z를 변화시켜 생성 과정을 제어할 수 있도록하는 것입니다. 최근 몇몇 방법은 사전 훈련된 모델에서 어떤 종류의 훈련이나 최적화 없이도 해석 가능한 방향을 직접 계산하는 방법도 제안되었습니다.
지도 학습 기반 방법은 일반적으로 사전 훈련된 분류기(예: 얼굴 속성 또는 광원 방향 예측)를 도입하여 많은 양의 잠재 코드를 무작위로 샘플링하고 해당하는 이미지 모음을 합성하고 미리 정의된 레이블로 주석을 달아주는 것입니다. 이러한 방법은 새로운 데이터셋에 대한 속성을 얻기 어렵거나 수동 레이블링을 필요로 할 수 있기 때문에 제한적입니다.
비지도 학습 기반 방법은 일반적으로 페어링 된 데이터를 요구하지 않고 잠재 공간에서 해석 가능한 방향을 발견하려는 것입니다. Harkonene et al. 은 잠재 또는 특성 공간에서 적용된 PCA를 기반으로 중요한 잠재 방향을 식별하여 이미지 합성을 위한 해석 가능한 제어를 생성합니다. 얻은 주요 구성 요소는 특정 속성에 해당하며 주요 구성 요소의 선택적인 적용을 통해 많은 이미지 속성을 제어할 수 있습니다. 이 방법은 레이블을 사용하지 않고 PCA를 사용하여 방향을 발견할 수 있기 때문에 "비지도"로 간주됩니다. 그러나 이 방법은 주석을 위한 수동 개입과 지도를 필요로 합니다.
일부 방법은 자체 지도 방법으로 선형 및 비선형 경로를 최적화합니다. 비지도 방식에서 발견된 방향은 일반적으로 여러 가지 속성에 영향을 미치며, 영향을 미치는 방향을 명시적으로 주석 처리하고 어떤 레이어에 적용해야 하는지 지정해야 합니다.
w를 선형적인 방법으로 표현하자면 다음과 같습니다.
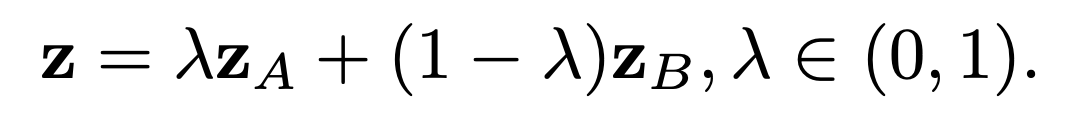
- 원본 이미지는 G(z)로 계산됩니다.
- L은 거리를 구하는 함수입니다.
- 이 방법은 G((z), a)가 G(z)에서 왔기 때문에 자기지도학습으로 분류됩니다.
4.4.2 Discovering Disentangled Directions
복수의 특성을 조작할 때는 서로 영향을 미칠 수 있기 때문에 다른 방법을 사용해야한다. 이를 위해 벡터를 직교시켜 복수의 특성을 제어할 수 있는 disentangled direction을 찾는 방법을 제안하였습니다. 또한 다른 방법으로 semantic space 대신 style space를 사용하여 local한 변형을 조절할 수 있다는 것을 실험으로 입증하였습니다.
5. Applications
5.1 Image Manipulation
이미지 x가 주어졌을 때, 특정 부분을 바꾸고 싶다면 x의 latent code z를 결과 이미지의 x' 의 latent code z'으로 선형적으로 바꾸면 됩니다. 식으로 나타내면 아래와 같습니다.
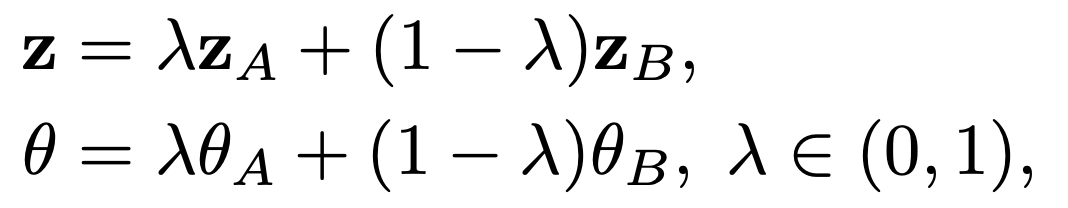
- n은 latent space에서의 의미적 방향을 나타냅니다.
- a는 조작 횟수입니다.
5.2 Image Generation
포토샵같이 의미적으로 원하는 이미지를 생성할 수 있습니다.
5.3 Image Restoration
φ()는 이미지를 손상시키는 함수라 정의할 때, 손상된 이미지 x_hat을
x_hat = φ(x)
라 표현할 수 있습니다.
위와 같은 방법으로 이미지를 복원할 수 있습니다.
5.4 Image Interpolation
두 이미지 x_A와 x_B가 있고 두 이미지의 latent code z_A와 z_B가 있으면 다음과 같은 방법으로 morphing을 진행할 수 있습니다.
모델 구조가 같고 파라미터가 다른 경우 다음과 같은 방식으로 morphing을 진행할 수 있습니다.
5.5 3D Reconstruction
Pan et al. 및 Zhang et al.은 GAN inversion에 기반한 단일 이미지에서의 3D 모양 재구성 및 포인트 클라우드 완성을 제안했습니다.
5.6 Image Understanding
몇 가지 방법은 훈련된 GAN 모델의 표현을 활용하고 이러한 표현을 의미론적 세분화 및 알파 매팅에 활용합니다.
5.7 Multimodal Learning
multi-modal 학습에서는 StyleGAN을 사용하여 언어 주도 이미지 생성 및 조작에 초점이 맞추어졌으며, 텍스트를 StyleGAN의 잠재 공간으로 매핑하는 인코더를 사용한 텍스트-이미지 생성 및 텍스트 안내 이미지 조작과 같은 방법이 사용되었습니다.
5.8 Medical Imaging
GAN inversion은 의료 영상에서 데이터 증강을 위해 사용되며, 원하는 속성을 가진 의료 영상을 합성함으로써 해석 가능성과 조절 가능성을 향상시킵니다.
6 CHALLENGES AND FUTURE DIRECTIONS
6.1 Theoretical Understanding.
GAN inversion을 통한 이미지 편집 응용에 중점이 두어졌으나, 더 나은 이론적 이해와 함께 비선형 통계 도구, 리만 매니폴드 및 지역 선형 방법을 활용하여 잠재 공간을 이해하는 방법에 대한 연구가 필요합니다.
6.2 Inversion Type
GAN inversion뿐만 아니라 인코더-디코더 아키텍처를 기반으로 생성 모델을 inverse시키기 위한 다양한 방법들이 개발되었으며, GAN inversion과 인코더-디코더 역함수를 결합하여 최상의 성능을 얻을 수 있는 방법을 탐구하는 것이 중요합니다.
6.3 Domain Generalization
GAN inversion은 style-transfer 및 이미지 복원과 같은 교차 도메인 응용에서 효과적이며, 사전 학습된 모델이 도메인에 구애받지 않는 특징을 학습했음을 나타내며, 중간 공유 표현을 반전하는 효과적이고 일관된 방법을 개발하는 것은 통합된 프레임워크에서 다양한 비전 작업을 처리하는 데 유용할 수 있다.
6.4 Implicit Representation
사전 학습된 GAN을 기반으로 한 몇 가지 방법은 기하학, 질감 및 색상을 조작할 수 있으며, 이는 대규모 데이터셋에서 사전 학습된 GAN 모델이 실세계 장면으로부터 물리적 정보를 학습했음을 나타내며, 암시적 신경 표현 학습은 3D 장면 속성의 제어를 가능하게 하고 다양한 응용에 사용되며, 사전 학습된 GAN의 암시적 표현을 반전하여 3D 재구성에 사용하는 흥미로운 연구 방향을 열었습니다.
6.5 Precise Control
GAN inversion은 이미지 조작을 위한 방향을 찾아줄 수 있지만, 시선 방향 전환 및 연속적인 시야 제어와 같은 정교한 제어가 필요한 작업에서는 더 많은 노력이 필요합니다.
6.6 Multimodal Inversion
GAN 역전법은 이미지 이외에도 언어 모델 및 음성 합성과 같은 멀티모달 표현에 적용될 수 있으며, 이는 언어 스타일 전이와 같은 작업에 대한 새로운 시각을 제공할 수 있으며, 멀티모달 표현으로 GAN 모델을 역전시켜 새로운 콘텐츠, 행동 및 상호작용을 생성하는 것이 가능합니다.
6.7 Evaluation Metrics.
GAN inversion에서는 더 나은 평가 지표 개발을 위한 노력이 필요하며, 예측 결과와 기대 결과 간의 차이를 측정하거나 역전된 잠재 코드를 더 직접적으로 평가하기 위한 효과적인 평가 도구가 부족한 문제점이 있습니다.
