과대적합 문제
규칙이 매우 복잡하게 구성되어 훈련 데이터는 잘 맞추지만,
새로운 데이터는 잘 맞추지 못하는 모델을 과대적합 되었다고 한다.
반면 규칙이 너무 단순한 모델은 과소적합 되었다고 한다.
과소적합된 모델을 모든 데이터를 잘 맞추지 못한다.
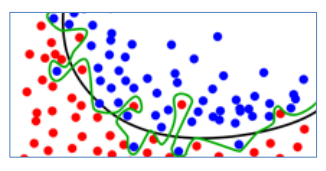
검정색 선은 잘 예측하고 있고, 초록색 선은 너무 복잡해 과대적합되었다.
일반화
머신러닝 모델의 중요한 부분은 새로운 데이터를 잘 맞추게 하는 것이다.
새로운 데이터를 잘 맞추는 상태를 일반화 되었다고 한다.
모델이 일반화 되려면 훈련 데이터셋이 다양성을 갖춰야한다.
기본적으로는 샘플이 많을수록 과대적합 없는 복잡한 모델 생성이 가능하다.
훈련데이터와 테스트데이터
모델의 일반화를 판단하기 위해 데이터셋을 훈련데이터와 테스트데이터로 구분
전체 데이터셋을 임의로 섞어 70~80%의 훈련데이터로 모델을 훈련시킨다.
그 후 20~30%의 테스트데이터로 예측을 진행해 모델을 평가한다.
사이킷런에서 이 기능을 하는 함수 train_test_split()가 있다.
데이터셋 관련 용어
Training set - 훈련데이터
모델 훈련에 사용하는 데이터셋
validation set - 검증데이터
모델 훈련에 적절한 지점을 찾기 위해 사용하는 데이터 셋으로
과적합 또는 과소적합을 방지하기 위한 훈련 중지 지점을 찾는다.
Test set - 테스트데이터
모델의 성능을 평가하기 위해 사용하는 데이터셋
테스트데이터에 관한 주의점
데스트데이터는 어떠한 정보도 제공해서는 안된다.
그 이유는
테스트데이터를 사용해 평가를 하고 파라미터를 조정한다면,
테스트데이터에 맞춘 모델을 생성하는 것이기 때문이다.
검증 관련 용어
Holdout
데이터셋을 train set과 test set으로 나눈다.
train set이 작으면 모델의 정확도가 떨어진다.
test set이 작으면 측정한 예측값의 신뢰도가 떨어진다.
K-fold Cross Validation
데이터셋을 K개의 fold로 나누어 사용한다.
총 K번의 실험을 진행하며, K-1 개의 fold는 training set,
1개의 fold는 test et으로 사용한다.
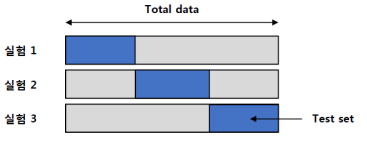
중복을 허용하지 않는다.
최종 성능 평가는 각 실험 성능의 평균으로 도출한다.
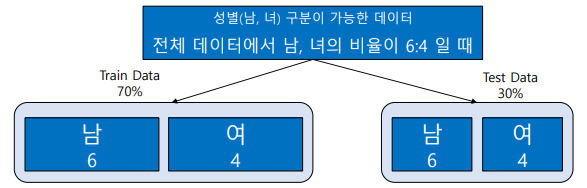
Stratified sampling
층화추출이라고 불린다.
데이터를 훈련데이터와 테스트데이터로 구분할 때
훈련데이터와 테스트데이터의 종속변수 범주가 동일하게 추출하는 방법이다.
Bootstrap
복원 추출이라고 불린다.
샘플 추출시 각 데이터의 중복 추출을 허용하는 것을 말한다.
적은 양의 데이터로 성능평가의 오차를 줄이기 위한 방법이다.
