데이터 분석 과정
데이터 사이언스는 데이터의 가치를 강조한 개념이다.
데이터 사이언스는 통찰력을 찾아 문제를 해결하는데 초점을 맞춘다.
데이터 사이언스는 크게 수집 - 분석 - 적용의 단계를 가진다.
1. 비지니스 이해하기 - Business Understanding
성공적인 데이터 분석을 위해서는
분석 대상 도메인에 대한 전문 지식이 필요하다.
해당 도메인의 전체 프로세스 또는 공정을 이해해야
전체 분석 과정의 흐름을 설계할 수 있다.
2. 데이터 수집하기 - Data Mining
데이터는 내부 데이터와 외부 데이터로 구분할 수 있다.
내부 데이터는 수집이 쉽고, 정제되어 있는 경우가 많아
1차 분석 대상이 된다.
외부 데이터는 추가 수집하는 것으로 많은 정제작업을 요구한다.
따라서 분석의 목적을 명확히 정의하고,
목적에 필요한 데이터를 요청하는 것이 바람직하다.
3. 데이터 전처리하기 - Data Cleaning
데이터 전처리 과정은 전체 분석 과정 중 가장 많은 시간을 필요로 한다.
최소 60% ~ 90% 정도의 시간이 든다.
수집한 데이터를 분석하기에 적합한 형태로 만드는 것으로,
기본적으로 행과 열로 포매팅하는 것을 말한다.
수집한 데이터에서 필요한 속성을 선택해 데이터를 재구성하고,
기술 통계 과정을 거쳐 결측값 및 이상치를 찾아 처리하며,
필요한 데이터는 정규화 및 파생변수 생성 등을 진행한다.
4. 탐색적 데이터 분석 - Data Exploration
탐색적 데이터 분석은 EDA라고도 불린다.
자료의 특징과 구조를 파악하는 작업으로서,
자료의 구조, 기본 통계, 간단한 시각화를 통해
데이터에 대해 깊이 이해하는 작업이다.
이 과정만으로 데이터 분석이 끝나는 경우도 있으며,
복잡한 설계를 위해서도 방향성을 갖게 해주는 역할을 한다.
5. 특성 공학 - Feature Engineering
모델링을 위한 전처리라고 할 수 있다.
특성 공학에는 4가지가 있다.
5-1. 정규화 - Scaling
비교되는 변수의 단위가 다를 경우 정규화 과정을 통해 단위를 맞출 수 있다.
대표적인 방법으로 표준화(Standatdization)을 통해
데이터는 평균이 0, 표준편차가 1이 되어 서로 비교가 가능해진다.
5-2. 구간화 - Binning
구간화는 관측치가 연속형이면서 범위가 너무 다양할 경우,
특정 구간으로 나누어 범주형 또는 순위형으로 변환시켜
데이터를 이해하는 것이다.
=> 연속형 변수를 범주형 또는 순위형으로
5-3. 변수 생성 - Creating Feature
새로운 변수를 만드는 것이다.
주어진 변수만으로는 의미있는 결과가 나오지 않을 때,
변수의 속성을 추가하는 것이다.
예시!
판매량 데이터에서 주말, 주중 판매량이 다를 경우,
요일 혹은 주말 여부를 추가하면 의미있는 분석 결과를 얻을 수 있다.
5-4. 원 핫 인코딩 - Creating Dummy
효율적인 데이터 처리를 위해
데이터의 값을 0과 1로만 나타내는 것을 말한다.
6. 모델링 - Predictive Modeling
모델을 개발하고 검증하여 개선해나가는 과정이다.
분석 방법을 선정하고, 모델에 사용하는 주요 인자를 파악한다.
만들어진 모델의 결과를 해석하고, 검증하는 과정을 반복해
보다 예측력 높은 모델을 만든다.
7. 데이터 시각화 - Data Visualization
분석 결과는 가능한 그래프로 설명하는 것이 좋다.
그래프는 데이터 및 결과의 전체 패턴을 쉽게 파악하게 한다.
분석 방법론
KDD 분석방법론
- 분석 대상 비지니스 도메인의 이해
- 분석대상 데이터 셋 선택과 생성
- 데이터에 있는 노이즈와 이상치 제거하는 정제작업이나 전처리
- 분석 목적에 맞는 변수를 찾고 데이터의 차원을 축소하는 데이터 변환
- 분석 목적에 맞는 데이터 마이닝 기법 선택
- 분석 목적에 맞는 데이터 마이닝 알고리즘 선택
- 데이터 마이닝 시행
- 데이터 마이닝에 대한 해석
- 데이터 마이닝에서 발견된 지식 활용
CRISP-DM 분석방법론
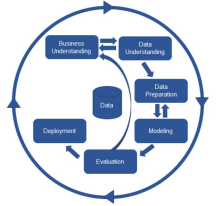
1단계: 업무 이해 - Business Understanding
- 비지니스 관점에서 프로젝트의 목적과 요구사항을 이해
- 도메인 지식을 데이터 분석을 위한 문제 정의로 변경
- 프로젝트 계획 수립
2단계: 데이터 이해 - Data Understanding
- 데이터 수집
- 데이터 탐색을 통해 통찰을 발견
- 데이터 품질 확인
3단계: 데이터 준비 - Data Preparation
- 데이터를 분석 기법에 적합한 형태로 변환
- 데이터 정제, 가공
4단계: 모델링 - Modeling
- 주요 변수 선택
- 모델링 기법 선택
- 테스트용 데이터셋을 분리하여 모델 평가
- 최적 모델을 만들기 위해 데이터 준비 절차를 반복할 수 있다.
5단계: 평가 - Evaluation
- 분석 결과 및 모델 평가
- 분석 모델이 비지니스 목적에 부합하는지 평가
- 데이터 마이닝 결과를 수용할 것인지 최종 판단
6단계: 전개 - Deployment
- 완성된 분석 모델을 업무에 적용하기 우한 계획 수립
- 적용된 모델이 고객 목표에 충족되었는지 확인
- 유지보수 계획 수립
SEMMA 분석방법론
- SEMMA (Sample, Example, Modify, Model and Assess)
- 기술과 통계 중심의 데이터 마이닝 프로세스
1. 추출 - Sample
- 분석할 데이터 추출
- 모델을 평가하기 위한 데이터 준비
2. 탐색 - Explore
- 그래프와 통계를 이용한 데이터 탐색
- 데이터 오류 확인
3. 수정 - Modify
- 변수 선택, 변형, 생성
- 분석용 데이터 변환
4. 모델링 - Model
- 분석 모델 구축
- 통계 기법 사용
5. 평가 - Assess
- 모델 평가 및 검증
- 여러 모델 동시 비교
