MC vs TD(Monte Carlo Methods vs Temporal-Difference Learning )
참고: 원문 ebook
어렵게 생각하지 말자.
학문은 다 같다.
단지 발견한 사람이 다른 이름으로 만들었을 뿐이다.
어떤 사람은 어렵게 정리 해놓았고 (강화학습)
어떤 사람은 간단하게 정리 해놓았다.
나는 다른 학문에서 온 더 간단한 설명으로 비유 할 것 이다.
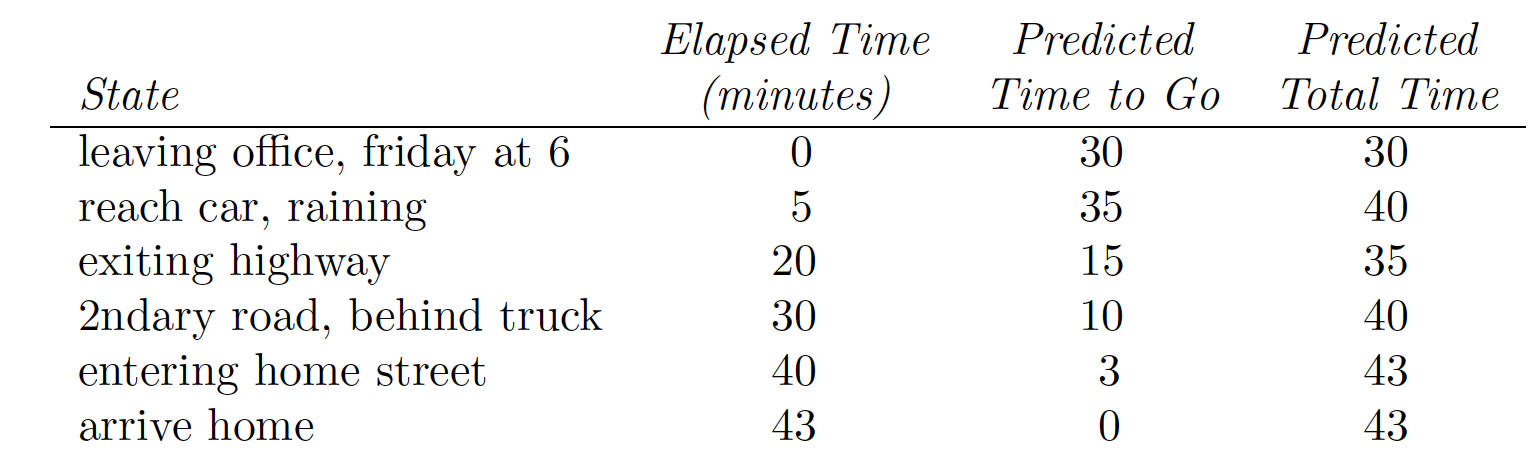
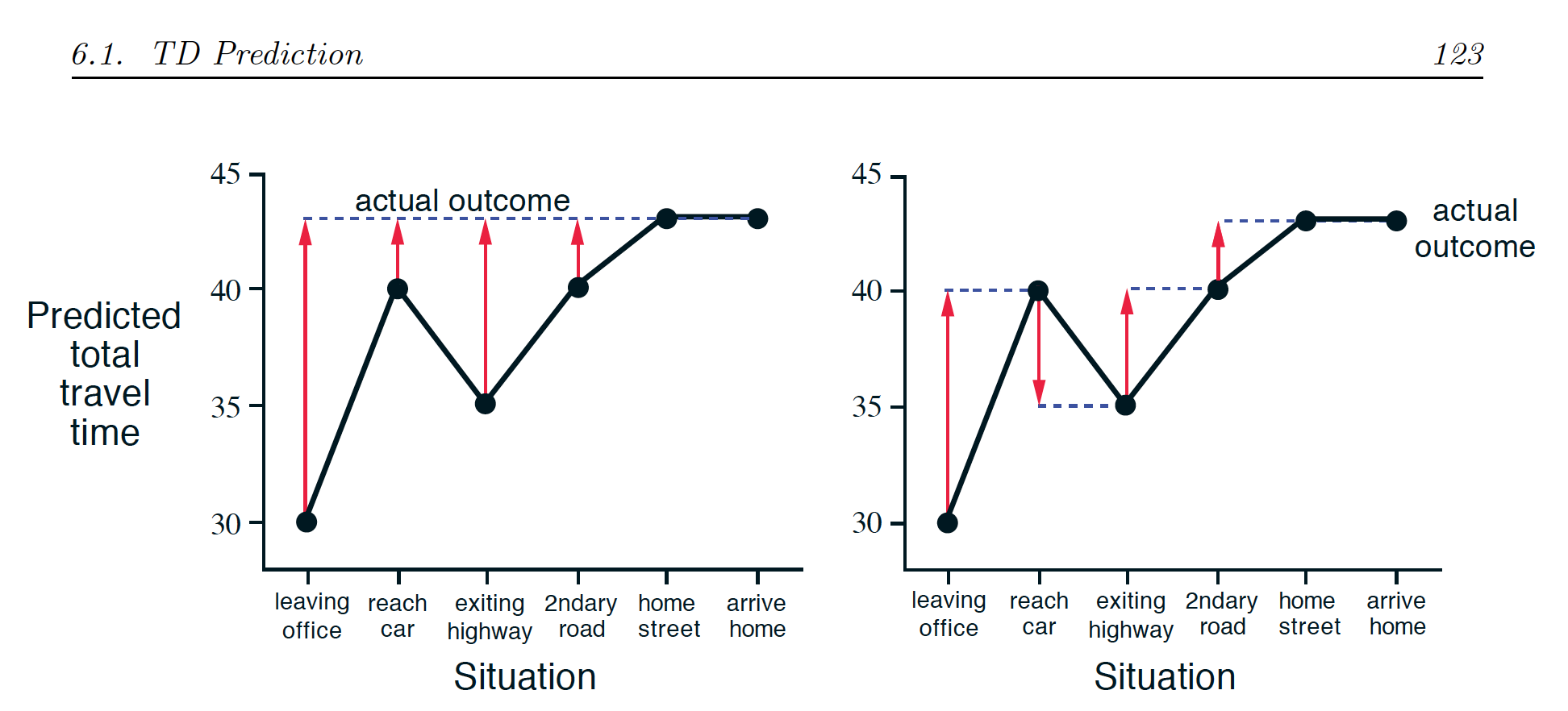
MC와 TD의 차이는 무엇을 답(true y)로 쓰냐 이다.
mc는 여러 t-step을 묶은 에피소드의 결과를 답으로 하는 것 이고
TD는 바로 다음 step에 예측치를 true y라고 생각하는 것 이다.
쉽게 말하면 mc는 이동평균을 답으로 보는 것 이고
td는 예측되는 이동평균을 답으로 보는 것 이다.
step-size표기는 보통 이렇게 한다.
TD(step-size)
ps.
당연히 이렇게 하면 평가지표인 MSE에서 td가 mc 보다 월등이 낮게 나온다. 왜냐하면 보통 step size가 td가 더 낮기 때문이다. 그러나 step size를 같게 하면 mc가 더 낮게 나온다.
이건 너무나도 당연하다. mc은 답을 보고 예측 하는 것이고, td는 답의 예측치를 가지고 예측하는 것 이기 때문이다.
그러나 딥러닝의 LSTM과 마찬가지로 강화학습에서 mc나 td는 time-lag가 발생한다.
결국 강화학습을 구성하는 근본이 이러기 때문에 강화학습도 예측을 잘 못한다는 이야기 이다.
다른말로 하면 강화학습 또한 실전 트레이딩에서 쓰일 수 없다.
그러나 예측치에 예측치를 높은 확률로 맞출수 있다면 실전 트레이딩에 사용 가능하다. 왜냐하면 예측치에 예측치를 알 수 있다는 것은 상대방의 수를 읽을 수 있다는 것 이다. 그러면 게임에서 이기기 훨씬 수월하다. 이런 경우가 있을까? 있다.
가령 미cpi를 예측 한다고 하자. 미cpi는 주가를 예측 하는데 하나의 feature으로 쓰일 수 있다. 그런데 미cpi를 발표 이전에 미리 계산할 수 있다면 어떻게 될까? 엄청나게 불공평 할 것 이다. 근데 이런게 현실이다. 어떤 지표가 나오기 전에 그 지표를 구성하는 데이터를 미리 구하면 된다. 가령 땡땡페이로 물가에 영향을 줄 수 있는 m2와 회전율을 정확히 구한다던가... 등등으로 할 수 있다.
결론은 손정의는 이런걸 미리 알고 있고 나라 정책도 바꿔가면서 최고의 투자회사를 완성 하고 있다. 바로 이미 도달한 '미래'의 데이터를 미리 볼 수 있는 투자 회사 이다. 이 계획이 완성이 된다면 아마 그가 고인이 되어도 소프트뱅크는 영생을 얻을 것 이다.
