이전 글에서 인공지능 기업에 가장 많이 필요한 인력이
데이터 수집해서 정리하는 막노동자라고 했다.
모델은 이미 만들어져있다.
대기업에서 데이터 수학자를 고용해서 만든다.
side talk:
한국 기업은
말도 안되게
모델링을 다루는
데이터 과학자를
대거 고용하고 있다...
똑똑한,
수학 박사 한명을 고용하는게 더 효율적 일 것 이다.
뭐 근데 사실...
한국 대기업의 선택은 당연했다.
그 나라의 금융가 인력을 둘러보면,
그 나라가 훤히 보일수 밖에 없다.
뉴욕에서는 문과생 찾아보기가 힘든데
아직도 여의도 금융센터는
엔지니어 보다
군대식 문화를 좋아하고
말 잘 듣는 문과가 다 수 이다.
긴말이 또 뭐 필요 있겠냐
영상을 봐라
https://www.youtube.com/watch?v=PWfdu4k0n2A
영상을 보면 아래와 같은 인공지능 production 모델이 나온다.
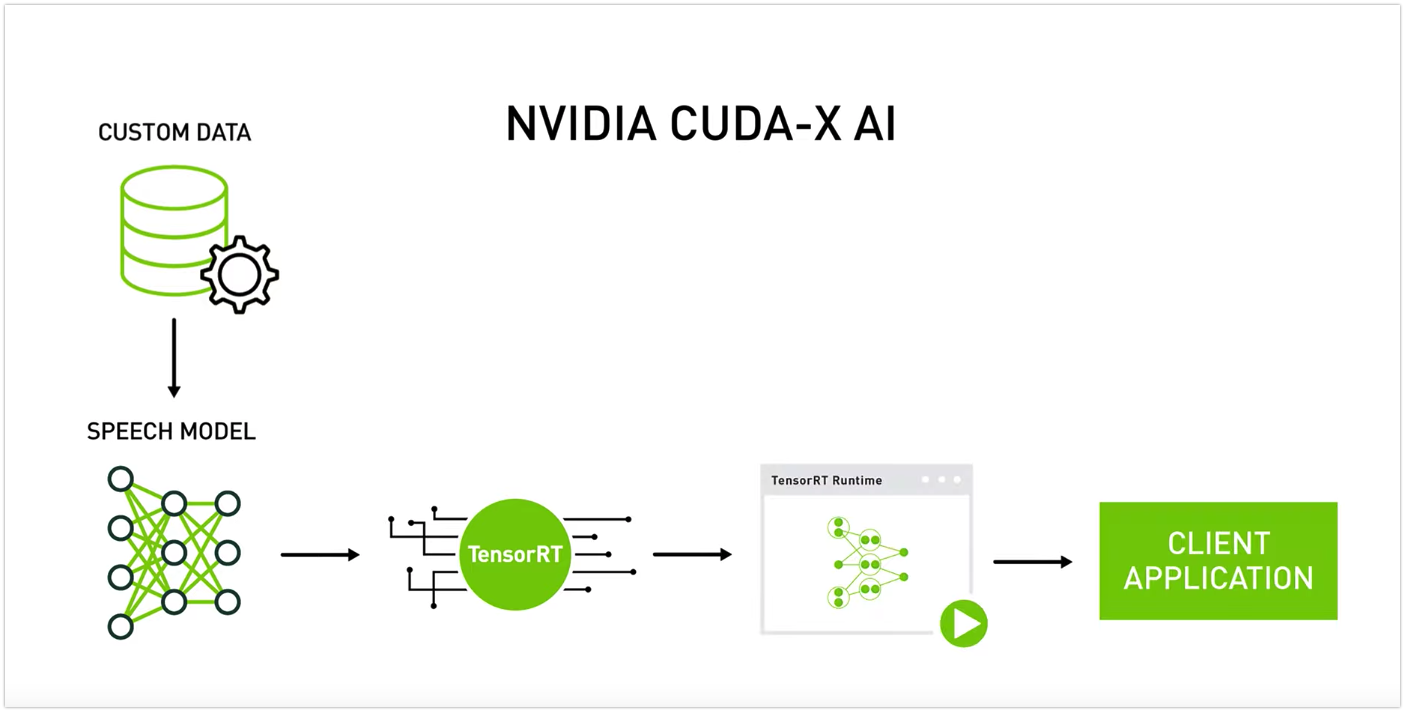
여기에서 일반 인공지능 기업이 할 수 있는 건
custom data를 수집하고 정리하는 것과
마지막에 client application 밖에 없다.
client application도
결국에는 대기업 포맷에 맞춰서 다시 만드는게 될 것 이다.
왜냐하면, 데이터를 지속적으로 다시 모델에 주입해야 하기 때문에
nvidia가 만들어 놓은 api에 양방으로 순조롭게 연결 하려면
기존 api를 변경과 서버를 nvidia로 옴기는게 효율적이다.
근데 여기서 중요한 것은 결국에 데이터는 누가 가질까?
nvidia가 비영리 단체처럼,
데이터 저장을 다른 서버에 할 수 있게 할까?
모델에 정확도를 높힌다고 데이터를 가져갈 것 이다.
