
🤖인공지능
특정한 기술보다는,
하나의 거대한 목표라고 할 수 있다.
인공지능은 시대에 따라 정의가 바뀌며, 다양한 관점에서 정의를 설명한다.
- 인간처럼 생각하는 Thinking Humanly
- 인간처럼 행동하는 Acting Humanly
- 이성적으로 생각하는 Thinking Rationally
- 이성적으로 행동하는 Acting Rationally
그래서 인공지능은 무엇인가.
인공지능은 사람의 지능을 기계로 구현하고자 하는 것이다. 특정한 기술보다는 '하나의 거대한 목표'라고 할 수 있다.
이러한 인공지능은 인간의 지능을 어떻게 구현하고 발현하는가에 대한 생각의 차이에 따라 아래와 같이 세 가지로 나뉠 수 있다.
- 규칙기반 인공지능 Rule Based AI
계산을 수행하며, 계산 과정을 정의하는 기호(Symbol)와 기호 간 연산에 대한 규칙(Rule)을 정의가 필요하다.- 실세계의 사물과 사상을 어떻게
기호화할 것인가 - 표현된 기호들과 규칙을 활용해 어떻게 지능적 추론을 할 수 있을 것인가
- 실세계의 사물과 사상을 어떻게
- 연결주의 인공지능 Connectionism
뇌 구조를 낮은 수준에서 모델링한 후, 외부 자극(학습 데이터)을 통해 인공두뇌의 구조와 가중치 값을 변형시키는 방식으로 학습을 시도한다.- 신경망 기반 AI, Perceptron, MLP(Multi-Layered Perceptron), 딥러닝(Deep Learning)
- 신경망 기반 AI, Perceptron, MLP(Multi-Layered Perceptron), 딥러닝(Deep Learning)
- 통계기반 인공지능
인간의 지능과 두뇌 구조에 대한 고찰보다, 문제를 어떻게 통계적으로 풀어내는가에 더 관심을 가진다.- 특징 설계(Feature Design)
- 통계적 모델에 기반해 문제를 푼 후 정답과 비교해 보는 평가 과정(Evaluation)
- 정답과의 차이를 반영해 통계 모델을 계속 갱신해 나가는 최적화 과정(Optimization/Parameter Update)
- 음성인식, 영상처리, 자연어 처리 등
오늘날 인공지능 연구는 규칙기반, 연결주의, 통계기반을 포함한 다양한 분야의 기법들이 융합되어 이용되고 있다.
- 자연어 처리(NLP)
- 음성인식(Speech recognition)
- 전문가 시스템(Expert System)
- 로봇
- 컴퓨터 비전(vision) 등
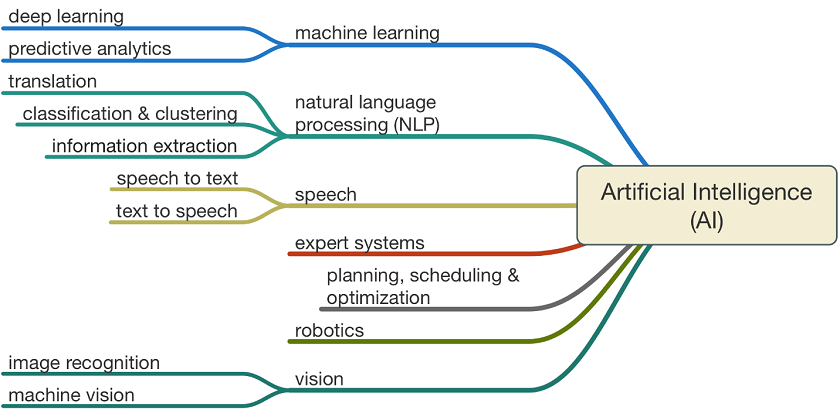
자 그럼 천천히, 하나하나 살펴보자.
1) 규칙 기반(rule-based) 접근법
: 인공지능이라는 목표를 이루기 위한 하나의 방법론.
사람이 프로그램에게 일일이 어떻게 하라고 지정해주는 것이다.
ex.부산대 맞춤법 검사기
하지만,
- 너무 큰 노력이 필요
- 변화에 적응하기 힘듦
이러한 문제점이 있다.
2) 머신러닝
: 인공지능이라는 목표를 이루기 위한 하나의 방법론.
'컴퓨터가 명시적으로 프로그램되지 않고도 학습할 수 있도록 연구하는 분야'
프로그램의 학습 :
'만약 어떤 작업 T에서, 경험 E를 통해, 성능 측정 방법인 P로 측정했을 때 성능이 향상된다면,
이런 컴퓨터 프로그램은 학습을 한다고 말한다.'
ex. 필기체 문자 인식 : T 필기체 문자 인식, P 필기체 인식의 정확도, E 정답이 표시된 필기체 문자의 입력, P가 E를 통해 향상된다면 이 프로그램은 학습된 것이다.
머신러닝은 어떤 방식으로 '학습'하는가에 따라 다음과 같이 세가지로 분류된다.
- 지도학습 Supervised learning
- 입력, 결과값(label)
- 분류classification, 회귀regression
- SVM, Decision tree, KNN, 선형/로지스틱 회귀
- 비지도학습 Unsupervised learning
- 입력
- 군집화clustering, 압축compression
- K-means 클러스터링
- 강화학습 Reinforcement Learning
- 결과값 대신 reward
- Action Selection, Policy Learning
- MDP(Markov Decision Process)
즉, 머신러닝은 입력값에 대응하는 결과값이 제대로 나오도록하는 최적의 매개변수 값을 찾는 과정이며, 학습(learning)의 결과물은 매개변수(가중치)의 값이다.
ex. 영어 알파벳 인식하는 프로그램
문자에 있는 사선, 수직선, 수평선, 곡선의 개수를 파악하여 문자 인식
ex. 손으로 쓴 숫자 인식하는 프로그램
로지스틱 회귀 Logistic Regression Model 사용
딥러닝
: 머신러닝의 한 분야.
특정한 하나의 모델이라기 보다는 머신러닝에 속하는 대표적인 방법론으로써 지도학습, 비지도학습, 강화학습 모두에 이용될 수 있다.
- 모델의 성능(정확도)이 뛰어나다.
- feature engineering이 필요 없다.
사람이 필수적으로 개입하여 모델에 입력할 변수를 생각해내는 기존 머신러닝 기법들과 달리, 딥러닝은 모델과 모델에 입력할 변수까지 스스로 학습한다. :representation learning - transfer learning이 용이하다.
하나의 문제를 잘 푸는 모델이 종종 다른 문제 역시 잘 푼다.
그럼에도 기존 머신 러닝 기법을 사용하는 경우
- 모델이 '왜' 그렇게 작동하는지 알아야 할 때
딥러닝을 쓰면 많은 경우 결과는 잘 나오지만, 모델이 어떻게 그 결과를 내는지 알기 어렵다 :block box모델
ex.환자의 데이터를 보고, 이 환자에게 어떤 처방이 필요한지 예측했더라도 왜 그렇게 내렸는지 설명하지 못한다면, 의사와 환자는 받아들이기 어렵다. - 딥러닝은 수많은 데이터가 필요하다. 데이터가 너무 적은 경우
- 딥러닝은 느리다. 가벼운 모델이 필요한 경우
엄청난 계산량이 필요한 딥러닝을 학습시키기 위해 대부분 GPU(Graphical Processing Unit)를 사용한다. - 기존에 충분히 검증된 모델이 있는 경우, 문제가 쉬워서 기존 머신 러닝 기법으로 충분한 성능을 낼 수 있는 경우 등
참고
CPU(Central Processing Unit)는 데이터를 처리하는 중앙처리장치이다. 명령어가 입력된 순서대로 데이터를 처리하는 직렬 방식으로 연산한다. 내부에 캐시 메모리를 두고 있다.
GPU(Graphics Processing Unit)는 3D 그래픽을 처리하는데 특화된 장치로, 병렬 연산 방식을 사용한다. 캐시메모리가 상당한 비중을 차지하는 CPU와 달리 산출연산처리장치(ALU)를 늘린 구조이다.
그리고 구글은 자사의 AI 학습 소프트웨어 'Tensorflow'에 최적화된 반도체를 만들어냈다. TPU(Tensor Processing Unit)는 GPU, CPU보다 수십 배의 전력 효율과 성능 향상을 나타낸다.
또한 IPU(Intelligence Processing Unit)는 연산 장치에서 가장 밀접한 곳에 메모리를 배치해 지연시간을 최소화한, 영국의 그래프코어에서 만들어낸 장치이다.
한국경제 기사
블로그
딥러닝은 인공신경망(ANN, Artificial Neural Network)이 발전한 개념이다.
-인공신경망
두뇌의 신경세포, 뉴런이 연결된 형태를 모방한 모델
생물학적인 뉴런이 다른 여러 개의 뉴런으로부터 입력값을 받아 세포체에 저장하다, 자신의 용량을 넘어서면 외부로 출력값을 보내는 것처럼,
인공신경망 뉴런은 여러 입력값을 받아 일정 수준을 넘어서면 활성화되어 출력값을 보낸다.
입력을 통해 만들어진 출력값 함수 : 활성화 함수(Activation Fuction)
ex.Sigmoid function : 모든 실수값을 0과 1사이의 값으로 바꾼다
인공신경망 뉴럴 네트워크는 뉴런을 여러 개 쌓아서 만들 수 있다.
- input layer
- hidden layer
- output layer

- Perceptron : 단순한 선형분류기 구조(0보다 크면 1, 작으면 -1)
- MLP, Multi-Layer Perceptron : hidden layer은닉 계층이라는 중간층 추가
여러 층으로 쌓을수록 학습하기 어려움
↓
Backpropagation Algorithm : 순방향Feed forward으로 연산 후 예측값과 정답 사이의 오차를 후방backward로 다시 보내주면서 학습시키는 방법
Perceptron으로는 AND, OR은 구현이 가능하지만, XOR은 'AND,OR,NOT'에 해당하는 Perceptron을 여러 층으로 쌓아서 만들어야 한다. 즉, MLP로 만들 수 있다.
ex.자율주행차
와! 정말 신기하게도 1989년에 이미 자율주행차를 연구했다!
-다시 딥러닝
인공지능 ⊃ 머신러닝 ⊃ 인공신경망 ⊃ 딥러닝
MLP의 문제점
- 깊은 층을 쌓을수록 역전파(Backpropagation) 학습과정에서 데이터가 사라져 학습이 잘 되지 않는,
사라지는 경사도(Vanishing Gradient)현상 - 학습한 내용은 잘 처리하지만 새로운 사실을 추론하는 것, 새로운 데이터를 처리하는 것을 잘 하지 못함
그래서 90년대에 인공신경망 분야는 몰락했다가, 사전 학습(Pretraining)을 통해 Vanishing Gradient 문제를 해결할 수 있으며(2006년), 학습 도중에 고의로 데이터를 누락시키는 방법(dropout)을 사용하여 새로운 데이터 처리에 대한 문제를 해결(2012년)할 수 있음을 알 수 있게 되며, 딥러닝이 탄생했다.
그리고, 이러한 알고리즘 개발과, 오랜 정보화의 결과로 축적된 막대한 데이터(Big data), 신경망 학습과 계산에 적합한 GPU 등의 하드웨어 발전으로 인하여 딥러닝이 유행하게 된다.
딥러닝은 데이터가 많아지더라도 일정 시점 이후에는 성능이 오르지 않는 머신러닝 알고리즘과 달리 데이터가 많아지면 많아질수록 성능이 더 좋아진다.
하지만 환경 변화에 따라 지속적인 재학습이 필요하다.
새로운 것을 학습시키려면, 전체 모델이 재학습을 진행해야 한다.(Batch Learning)
예를 들어 이미지 인식에서 고양이라는 결과값을 추가할 경우, 고양이의 사진에 대해서 다른 노드들은 관계가 없다는 것도 함께 학습시켜 주어야 하는 것이다.
새로 생긴 데이터만 따로 학습시키는 방법도 있다. (Incremental Learning)
머신러닝과 통계학
머신러닝과 통계학은 서로 영향을 주고 받는 관계이다.
같은 개념을 다른 각도로 바라보는 차이.
- 머신러닝은 정확한 예측에 집중을 하고,
- 통계학은 사람들이 왜 그러한 선택을 하는지 분석한다.
머신러닝의 predictive modeling Workflow

- 1. Data Collection 데이터 수집
- web crawling
- database, data file
Exploartory Data Analysis탐색적 데이터 분석과 Data Preprocessing데이터 전처리, 모델 선택Model Selection은 순차적 관계가 아닌 반복적 관계
- 2. Data Preprocessing 데이터 전처리
- data cleaning : 더러운 (데이터에 빠진 값, 결측값이나 중복값, 이상한 값이 있는 경우) 데이터를 정제하여 입력에 적합한 형태로 바꿔주는 단계
- feature engineering : 데이터의 기존 속성(feature)을 조합해서 새로운 속성을 만들어내기 위한 전처리
ex.집의 크기에 대한 가격 예측하는 모델 : 가로, 세로 길이를 이용하여 면적이라는 새로운 속성을 만들어내는 것 - feature scaling : 데이터의 스케일 맞추기
- dummification
- dimensionality reduction : 차원 줄이기
- 3. EDA : Exploratory Data Analysis 탐색적 데이터 분석
: 데이터의 특징을 찾고, 숨겨진 패턴을 발견하는 과정- 데이터의 히스토그램 그려보기, 두 변수 사이 산포도 그려보기, 변수들 상관관계 확인
- 데이터의 히스토그램 그려보기, 두 변수 사이 산포도 그려보기, 변수들 상관관계 확인
- 4. Model Selection 모델 선택
- Model : 새로운 입력 데이터를 받았을 때 예측값을 계산하는 방법
- 예측값을 계산하는 알고리즘을 선택한다 ; 로지스틱 회귀(logistic regression), KNN(K-Nearest Neighbors), SVM(Support Vector Machine), 딥러닝(deep learning)
- 모델이 사용할 속성들(features)을 선택한다
- 일종의 모델을 조절하는 적절한 하이퍼라미터(hyperparameter)를 선택한다.
- 5. Evaluation & Application 평가 및 적용
머신 러닝 모델의 성능을 평가하고, 모델을 활용하여 새로운 데이터에 대한 예측을 한다.- 평가용 데이터셋은 모델 선택과 모델 학습 과정에서 쓰이지 않아야 한다.
딥러닝의 모델
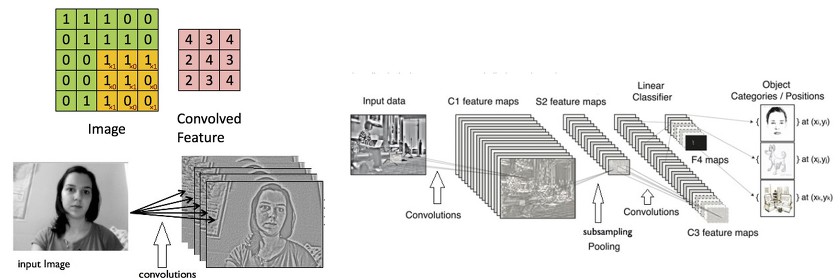
- CNN (Convolutional Neural Network)
이미지의 위치 변화나 방향 변화, 왜곡 등의 다양한 변화에 관계없이 인식하기 위해 Convolution과 Pooling과정을 반복 적용하여, 이미지에서 추상화된 정보를 추출한다.- Convolution : 여러가지 filter를 사용하여 이미지의 특징을 도출한다.
이미지를 일정한 패턴으로 변환하기 위해 행렬 연산을 수행한다.
포토샵이나 사진 어플에서 흐리게 하거나, 선명하게 하거나 하는 등 각종 필터를 적용할 때
데이터의 크기를 줄이면서 이미지의 특징도 추출할 수 있다.
- Pooling : 이미지의 특징은 유지하며, 차원(dimension)을 줄이는 역할
- Convolution : 여러가지 filter를 사용하여 이미지의 특징을 도출한다.
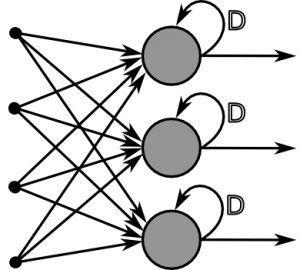
- RNN(Recurrent Neural Network)
음성과 같은 순차적인(Sequential) 정보를 인식하는데 주로 사용된다.
이전 상태의 값이 다음 계산의 입력으로 들어가서 결과에 영향을 미치는 구조- 기계 번역기 모델 : 두 개의 RNN 모델 사용
첫 번째 RNN(Encoder)에서는 영어 문장을 숫자로 인코딩,
두 번째 RNN(Decoder)에서는 숫자를 입력 받아 스페인어 문장을 출력 - 사진 속 상황 문장으로 설명하는 모델
- 사진 속 다양한 사물 인식하는 모델
- 기계 번역기 모델 : 두 개의 RNN 모델 사용
인공지능의 4가지 유형
- 단순한 제어 프로그램
세탁/청소 - 패턴이 다양한 고전적 인공지능
입력과 출력 관계를 맺는 방법의 수가 극단적으로 많고 세련된 경우
(탐색/추론, 지식베이스 활용) - 머신러닝을 받아들인 인공지능
데이터를 바탕으로 학습되는 기계학습 알고리즘 이용 - 딥러닝을 받아들인 인공지능
기계학습을 할 때 입력값의 특징(feature)을 사람이 입력하지 않고 기계가 직접 학습
