
머신러닝의 학습 분류를 더 자세히 살펴보자.
참고
1. 지도학습 Supervised Learning
입력과 결과, 문제와 답을 주고 학습시키는 방법이다.
학습하도록 주는 데이터를 Train Set이라고 하며,
Train Set에 답이 무엇인지 달아주는 것을 Labeling이라고 한다.
레이블링한 Train Set으로 학습 및 훈련한 알고리즘은 Model이다.
이 모델의 정확도를 측정할 때는, 레이블링되지 않은 Test Set을 이용한다.
레이블링한 답이 어떤 형태인지에 따라 모델은 분류와 회귀로 나누어진다.
- 분류 Classification
데이터의 값이 딱딱 떨어지게 구분되는 경우, 이러한 데이터를 범주형 데이터라고 하며,
레이블링된 출력값이 범주형 데이터인 경우, 학습한 모델은 분류를 수행한 것이다. - 회귀 Regression
데이터의 값이 연속적인 수치 형태로 나타나는 경우, 이러한 데이터를 연속형 데이터라고 하며,
레이블링된 출력값이 연속형 데이터인 경우, 학습한 모델은 회귀를 수행한 것이다.
왼쪽은 분류를 수행한 것이며, 오른쪽은 회귀를 수행한 것이다.

1) 회귀 Regression
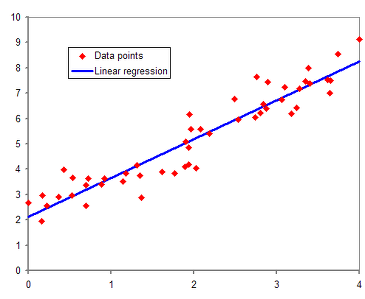
Linear Regression
- 임의로 분포한 데이터들을 하나의 직선으로 일반화시키는 것이다.
- 많은 자연현상이나 사회현상이 어떠한 요인에 대해 1차 함수 형태로 정비례하는 경우가 많다.
- 데이터가 극단적으로 튀는 방향이 아니라 평균적인 수치로 '회귀'한다는 데에서 용어가 탄생했다.
- Linear Regression 시, 각 데이터별 값과 직선까지의 거리 분산을 최소화하도록 직선의 모양을 결정한다. : 최소제곱법(OLS Ordinary Least Square)
- 출력값이 연속형일 경우에만 적용이 가능하다.
Locally Weighted Linear
Ridge
Lasso
2) 분류 Classification
Logistic Regression
- 로지스틱 함수를 회귀식으로 사용하여 붙여진 명칭
- 최소값과 최대값이 특정한 값으로 수렴한다.
- 범주형으로 완전히 분리된 값을 구분하기 좋다.
Decision Tree
- 어렸을 때 많이 했던 Akinator
- 그렇다면 아무리 복잡한 데이터라도 선을 많이 그어 100% 분류할 수 있지 않을까? 아니다. 지나치게 촘촘하게 분류할 경우, 훈련시킨 데이터가 아닌 실제 분류 데이터에 대해 정확도가 떨어진다. : 과대적합
Over fitting - 지나치게 복잡한 가지들을 쳐내는 가지치기(
Pruning)작업을 통해 적절한 수준으로 Decision tree를 만들 수 있다.
SVM Support Vector Machine
- 출력값을 구분할 수 있는 평면/선을 긋되 가장 큰 폭으로 차이나게 긋는 것
- 이때 경계 :
Hyperplane초평면 - 복잡한 곡선을 동원할 수 있어, 회귀 모델이나 Decision tree 모델이 학습하기 어려운 복잡한 데이터도 학습할 수 있다.

kNN
Naive Bayes
2. 비지도학습 Unsupervised Learning
- 답을 주어주지 않기 때문에, 어떤 데이터들이 서로 비슷한지 그룹짓거나 어떤 성질이 데이터를 잘 정의하는지 판단하는 등 문제에 대한 나름대로의 유용한 정보를 제공해주는 역할을 한다.
- 최종적으로 답을 알려주는 용도로 사용할 수는 없지만, 데이터의 특성을 파악할 수 있는 유용한 정보를 주어 사람이 의사결정하는데 도움이 된다.
1) Clustering 군집
비슷한 것끼리 묶는 것
-
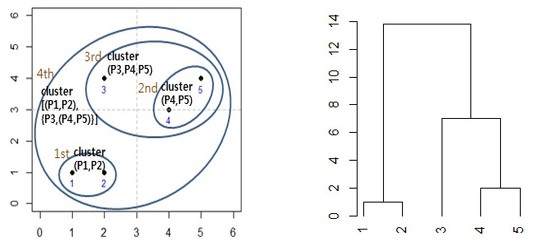
계층적 군집분석
한 군집이 다른 군집을 포함할 수 있는 구조
오른쪽과 같은 가지 형태를 'Dendrogram'이라고 한다. -
비계층적 군집분석
군집끼리 포함관계를 이루지 않고 서로 독립적인 한 군집으로 만드는 기법
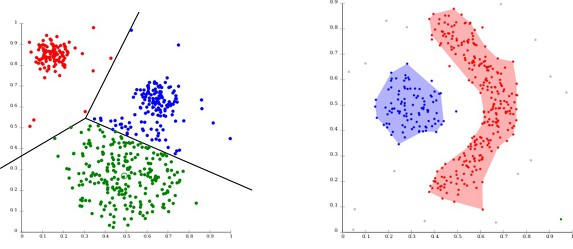
K-Means
거리 기반
DB-SCAN
밀도 기반
HCA Hierarchical Cluster Analysis
Exception Maximization
2) Visualization 시각화, Dimensionality Reduction 차원 축소
Visualization Alogrithm은 레이블이 없는 대규모의 고차원 데이터를 넣으면 도식화가 가능한 2D나 3D표현을 만들어준다.
Dimensionality Reduction은 너무 많은 정보를 잃지 않으면서 데이터를 간소화하는데 사용된다. : Feature Extraction(특성 추출)
PCA Principal Component Analysis
데이터 입력값의 특성을 분석해 출력값을 잘 설명해주는 새로운 입력 특성을 추출하는 방법
위와 같은 데이터는 xy축으로 설명하는 것보다 wz축을 새로 그어 데이터 특성을 표현하는 것이 더 낫다.
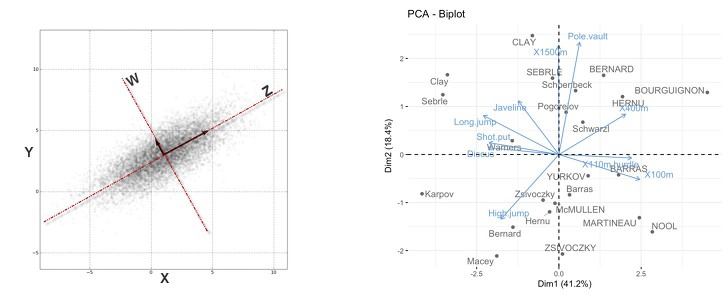
데이터를 잘 설명하는 특성을 찾는 것 뿐만 아니라
입력 특성의 개수를 적절하게 줄이는 효과가 있다. : 성능 개선의 효과
Kernel PCA
LLE Locally-Linear Embedding
t-SNE (t-distributed Stochastic Neighbor Embedding)
3) Association Rule Learning연관 규칙 학습
대량의 데이터에서 특성 간의 흥미로운 관계를 찾는다.
Apriori
Eclat
3. 강화학습 Reinforcement Learning
분류할 수 있는 데이터가 존재하지 않고, 데이터가 있어도 정답이 없다.
자신의 행동에 대한 보상을 받으며 학습하는 것이다.
- Agent
- Environment
- State
- Action
- Reward
이전에 존재했던 학습법이지만, 딥러닝 등장 이전에는 좋은 결과를 내지 못했다.
강화학습에 신경망을 적용하면서 복잡한 문제에 적용할 수 있게 되었다.
- 정의된 agent가 주어진 environment의 현재 state를 observation하여, 이를 기반으로 action을 취한다.
- 이때 환경의 상태가 변화하면서 정의된 agent는 reward를 받게 된다.
- reward를 기반으로 한 정의된 agent는 더 많은 reward를 받을 수 있는 방향(best action)으로 행동을 학습하게 된다.
최단 시간에 주어진 환경의 모든 상태 관찰과 보상 최대화를 할 수 있는 행동을 수행하기 위해서는 이용과 탐험 사이의 균형을 적절히 맞춰야 한다.
- 이용(exploitation)
현재까지 경험 중 현 상태에서 가장 최대의 보상을 얻을 수 있는 행동을 수행하는 것 - 탐험(exploration)
다양한 경험을 쌓기 위한 새로운 시도
마르코프 결정 프로세스 Markov Decision Process, MDP
Value Iteration, VI
Policy Iteration, PI
Q-Learning
