IRIS: LLM-Assisted Static Analysis for Detecting Security Vulnerabilities
https://arxiv.org/pdf/2405.17238
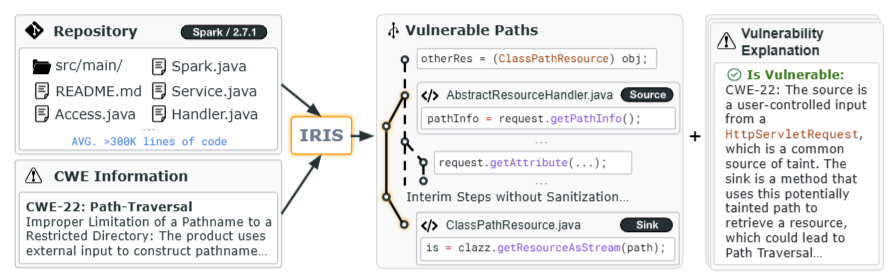
IRIS
논문에서 소개하고 있는 IRIS는 정적 분석툴과 LLM을 결합하여 취약점을 더 정확하고 넓은 범위를 커버할 수 있도록 한 방식이다. LLM을 이용하여 스펙을 자동 추론하고 이를 정적 분석과 결합해 취약점을 탐지한다.
- 대상 언어: JAVA
- 주로 사용한 LLM 모델: GPT-4
(연구에서는 여러 모델을 사용하였지만, 가장 성능이 좋아 많이 언급됨) - 주로 사용한 정적 분석툴: CodeQL(GitHub)
- 데이터셋: CWE-Bench-Java
- 탐지한 취약점 개수: 55(IRIS w GPT-4)
기존 방식의 문제점
- 기존 정적 분석 도구: 사람이 직접 정의한 source/sink/sanitizer 스펙에 의존
- 스펙이 누락되거나 부정확하면 취약점을 놓치거나 false positive가 많아짐
- context 이해가 부족해 오탐이 많음
IRIS 탐지 방식 제안
LLM(GPT-4 등): source/sink를 식별, context-aware하게 경로를 분류
탐지 단계
- 프로젝트 소스코드 전체 정적 분석
- CodeQL 사용해 프로그램의 데이터 흐름 그래프 생성
- 각 노드는 변수나 함수 호출 등으로 이루어짐
- Source, Sink Sanitizer 스펙 자동 추론
- 후보군 추출(Candidate Extraction)
- 외부 API 목록(java.io, javax.serverlet 등)
- 내부 공개 함수의 파라미터 목록
- LLM 프롬프트로 스펙 추론
- CWE 설명
- 예시 (few-shot 예제)
- 분석 대상 API 목록 (CSV 형태)
- 정적 분석으로 취약한 경로 찾음 (Taint Analysis)
LLM이 추론한 source/sink 정보 -> CodeQL
source → [tainted path] → sink
↘ (없으면 취약) sanitizer-
Contextual Filtering (LLM 기반 문맥 분석)
LLM에게 코드 스니펫 전달 후 맥락 고려하여 판단/분석
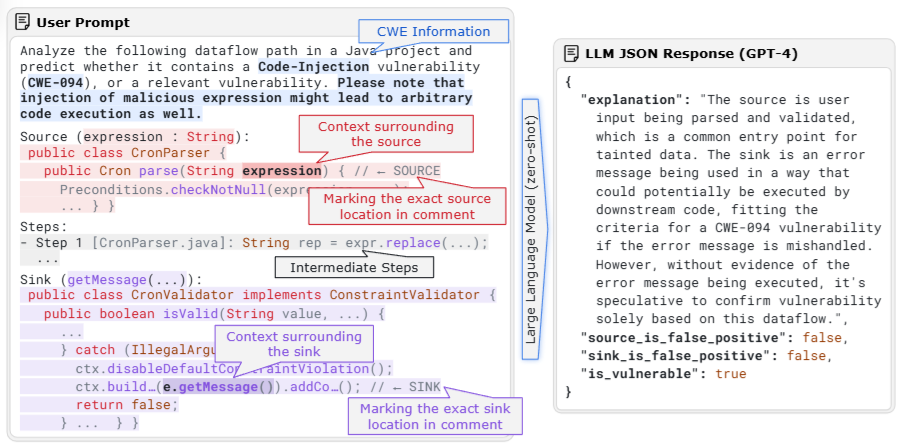
-
취약점 경로와 설명 생성
- 취약점이 발생하는 경로 (source → sink)
- CWE에 대한 설명
- LLM이 판단한 context 기반 설명
- false positive 필터링 결과
요약!
LLM에게 여러 문서를 제공해서 source/sink/sanitizer 판단하게 함
→ 위 결과를 CodeQL에 전달해서 데이터 흐름 그래프를 생성해 Path(source, sink)에 대해 중간에 sanitizer가 없는 경로가 있을 경우 취약한 경로일 가능성 높다고 판단
→ LLM이 해당 경로를 바탕으로 취약점 유무, source와 sink에 대한 false positive 여부와 설명 출력
→ source → sink 흐름 추적하며 오염된 데이터(taint) 영향 범위 분석
IRIS에서 LLM은
- 스펙 추론: 특정 함수의 source/sink/sanitizer 판단
- 경로 판단: sanitizer가 없었던 경로에 대해 코드 맥락을 참고하여 취약한지 판단
- 설명 제공: CWE에 대한 정보 제공
제언
- IRIS도 아직 탐지하지 못하는 CWE가 존재함
- 공통적인 취약점 탐지툴의 목표
- Specification Interference: Source/Sink/Sanitizer 구분의 자동화
- false positives
느낀점
지금하고 있는 프로젝트/연구와 비슷한 점이 많고, 우리도 hybrid 방식(정적 분석툴+LLM 결합)을 생각해봤던 만큼, 배울점이 많은 연구였다.
Java 언어에 한정해서 연구를 진행
처음부터 우리는 모든 언어를 모두 지원하는 툴을 우리가 만들기는 현실적으로 불가능하다고 생각해 타겟 언어를 지정했지만, 이 논문을 읽으며 한 언어에 특화되도록 설계하는게 정확도를 크게 늘리는 길일 수 있을 것이라는 생각이 들었다. 특히 생각지 못했던 API나 언어별 여러 특성들을 반영해야 실제로 개발자나 개발 환경에서 쓰일 수 있는 툴이 될 것이다. 그러려면 언어별 특성을 반영하는 것이 중요해지고, 모든 언어를 포괄하기는 더더욱 힘들어진다.
이 연구에서는 Java를 대상으로 했고, 데이터셋을 제작하거나 docs를 LLM에게 함께 제공하는 등을 통해 단일 언어 지원의 장점을 극대화했다고 생각한다. 물론 다른 언어에 대해 어느정도 취약점을 방어하는지 연구된 바 없지만, 언어의 특성을 반영하는 것에 대해 다시금 생각해보게 되었다.
LLM을 여러 단계에 걸쳐 배치
IRIS에서 LLM이 여러 판단 과정과 분석 단계에 자리하고 있다. 단계에 따라 필요한 역할을 부여하여 정적 분석툴을 돕는 동시에 취약점 여부를 판단하기도 하고, 결론적으로 사용자에게 취약점에 대한 정보를 제공하기까지 한다. 이렇듯 많은 양을 한꺼번에 처리할 필요 없이, 단계에 따라 필요한 부분을 수행하도록 할 수 있다는 점이 인상적이었다.
취약점이 발생하는 곳까지의 경로(Taint path)를 바탕으로 분석
교수님과 면담을 진행하면서 계속해서 했던 말이 '취약점이 단순히 코드 한 부분, 한 조각으로 발생하지 않을 것이다', '따라서 전반적인 코드의 구성과 맥락을 보아야 한다고 생각한다'는 것이었다. 충분히 누구나 할 수 있는 생각이었는데, 실제로 이 연구에서 그렇게 구현한 것이다. 사용자의 입력값부터 취약점이 직접적으로 발생하는 부분까지의 경로를 파악하여 이를 LLM에게 전달하고 이 경로에서 취약점이 발생할 가능성을 판단하게 한다. 이를 통해 전반적인 코드 context를 통해 판단할 수 있을 것이고, 이는 취약점 탐지의 정확도를 높일 것은 자명하다.
IRIS 모델은 특히 환경을 비슷하게 구성해서 실제로 사용해보고 싶은 생각이 든다. 꼭 써보고/같은 방식으로 진행해보고 글을 써보려 한다.
