공부할 책 : Doit! 파이썬 웹 개발부터 배포까지! 점프 투 플라스크
플라스크
플라스크는 2004년 오스트리아의 오픈소스 개발자 아르민 로나허가 만든 웹 프레임워크이다. 플라스크는 아르민 로나허가 만우절에 장난삼아 던진 아이디어였는데 사람들의 관심이 높아져 서비스로 만들어졌다. 플라스크는 장고와 더불어 파이썬 웹 프레임워크의 양대 산맥으로 자리매김하고 있다.
플라스크는 마이크로 웹 프레임워크이다.
플라스크는 많은 사람이 '마이크로 웹 프레임워크'라고 부른다. 마이크로 웹 프레임워크는 프레임워크를 간결하게 유지하고 확장할 수 있도록 만들었다는 뜻이다. 플라스크 프레임워크의 간결함은 구체적으로 무엇인지 다음 코드를 살펴보자. 이 코드는 완벽하게 동작하는 플라스크 웹 프로그램이다.
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World"
if __name__ == "__main__":
app.run()이 코드를 실행한 다음 웹 브라우저로 접속하면 화면에 "Hello World"가 출력된다. 이처럼 플라스크를 이용하면 파일 하나로 구성된 짧은 코드만으로도 완벽하게 동작하는 웹 프로그램을 만들 수 있다.
확장성 있는 설계란?
플라스크에는 폼, 데이터베이스를 처리하는 기능이 없다. 예를 들어 장고라는 웹 프레임워크는 프레임워크 자체에 폼과 데이터베이스를 처리하는 기능이 포함되어 있다. 장고는 쉽게 말해 덩치가 큰 프레임워크다. 그러며 플라스크는 이런 기능을 어떻게 보완할까? 플라스크는 확장 모듈이라는 것을 사용하여 이를 보완한다. 이 말은 플라스크로 만든 프로젝트의 무게가 가볍다는 것을 의미한다. 왜냐하면 플라스크는 처음부터 모든 기능을 포함하고 있지 않기 때문이다. 그때그때 개발자가 필요한 확장 모듈을 포함해 가며 개발하면 된다. 실제로 플라스크 프로젝트는 가벼운 편이다.
플라스크는 자유로운 프레임워크다
플라스크는 한마디로 자유도가 높은 프레임워크다. 프레임워크는 대부분 규칙이 복잡하고 개발자는 그 규칙을 반드시 따라야 한다. 규칙을 따라야 하는 건 플라스크도 마찬가지다. 하지만 플라스크에는 최소한의 규칙만 있으므로 개발의 자유도는 다른 프레임워크보다 높다.
파이썬 가상 환경
플라스크를 파이썬 가상 환경에 설치해 보자.
명령 프롬프트에 다음과 같이 실행한다.
cd \
mkdir vens
cd vens
python -m venv myproject // 가상환경 만들기
cd C:\vens\myproject\Scripts
active // 가상 환경에 진입
(가상 환경에서 벗어나려면 deactive라는 명령을 실행해주자.)
가상환경에서 pip install Flask 명령을 입력하자.
플라스크 서버 실행
myproject 디렉터리에 pybo.py 파일을 생성하고 다음과 같이 코드를 작성한다.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_pybo():
return 'Hello, Pybo!'app = Flask(__name__) 은 플라스크 애플리케이션을 생성하는 코드다. 이 코드에서__name__ 이라는 변수에는 모듈명이 담긴다. 즉 이 파일이 실행되면 pybo.py 라는 모듈이 실행되는 것이므로 __name__ 변수에는 'pybo'라는 문자열이 담긴다.
@app.route 는 특정 주소에 접속하면 바로 다음 줄에 있는 함수를 호출하는 플라스크의 데코레이터다.
플라스크 서버 실행하기
가상 환경에서 flask run 명령을 실행한다. 하지만 플라스크 애플리케이션을 찾을 수 없다는 오류 메세지가 발생한다.
실행하려면 FLASK_APP이라는 환경 변수에 플라스크 애플리케이션을 지정해 주어야 한다.
가상환경에서 환경 변수 FLASK_APP 에 pybo 애플리케이션을 지정한다.
set FLASK_APP=pybo
플라스크 서버 실행 환경을 개발 환경으로 바꾸려면 다음과 같이 입력한다.
set FLASK_ENV=development플라스크 애플리케이션 팩토리
플라스크 앱은 다음 코드에서 보듯 Flask 클래스로 만든 객체를 말한다.
app = Flask(__name__)
플라스크는 app 객체를 사용해 여러 가지 설정을 진행한다. 그런데 app 객체를 전역으로 사용하면 프로젝트 규모가 커질수록 문제가 발생할 확률이 높아진다. 순환 참조 오류가 대표적이다.
애플리케이션 팩토리 사용하기
객체를 전역으로 사용할 때 발생하는 문제를 예방하려면 애플리케이션 팩토리를 사용하자고 권한다.
from flask import Flask
def create_app():
app=Flask(__name__)
@app.route('/')
def hello_pybo():
return 'Hello, Pyno!'
return appcreate_app 함수가 app 객체를 생성해 반환하도록 코드를 수정한다. 여기서 사용된 create_app 함수가 애플리케이션 팩토리다.
블루프린트
hello_pybo 함수는 URL에서 /에 매핑되는 함수인데, 그 매핑을 @app.route('/')라는 애너테이션이 만들어 준다. 이때 @app.route와 같은 애너테이션으로 매핑되는 함수를 라우트 함수라고 한다. 그런데 하나 생각해 볼 점이 있다. 지금까지 작성한 대로라면 새로운 URL이 생길 때 라우트 함수를 create_app 함수 안에 계속 추가해야 하는 불편함이 있다. 이때 사용할 수 있는 클래스가 블루프린트다.
views/main_views.py
from flask import Blueprint
bp=Blueprint('main',__name__, url_prefix='/')
@bp.route('/hello')
def hello_pybo():
return 'Hello, Pybo!'
@bp.route('/')
def index():
return 'Pybo index'애너테이션이 @app.route에서 @bp.route로 변경되었다. 이 변화에 주목하자. @bp.route에서 bp는 Blueprint 클래스로 생성한 객체를 의미한다. 코드에서 보듯 Blueprint 클래스로 객체를 생성할 때는 이름, 모듈명, URL, 프리픽스 값을 전달해야 한다.
블루프린트 파일을 적용하기 위해 다음과 같이 수정한다.
__init__.py
from flask import Flask
def create_app():
app=Flask(__name__)
from .views import main_views
app.register_blueprint(main_views.bp)
return appcreate_app 함수에 등록되었던 hello_pybo 함수 대신 블루프린트를 사용하도록 변경했다. 블루프린트를 사용하려면 main_views.py 파일에서 설정한 블루프린트 객체인 bp를 등록하면 된다.
플라스크를 실행시키고 localhost:5000, localhost:5000/hello 에 접속해 보자.
모델로 데이터 처리하기
웹 서비스는 데이터를 처리할 때 대부분 데이터베이스를 사용한다.
그런데 데이터베이스를 사용하려면 SQL 쿼리라는 구조화된 질의를 작성하고 실행하는 등 복잡한 과정이 필요하다. 이때 ORM(Object relational maping)을 이용하면 파이썬 문법만으로도 데이터베이스를 다룰 수 있다. 즉 ORM 을 이용하면 개발자가 직접 쿼리를 작성하지 않아도 데이터베이스의 데이터를 처리할 수 있다.
데이터베이스를 쉽게 사용할 수 있는 ORM
SQL쿼리와 ORM 을 비교해 보자.
question 테이블에 새로운 데이터를 삽입하는 쿼리는 보통 아래와 같다.
insert into question (subject, content) values ('안녕하세요', '가입 인사 드립니다. ^^')
insert into question (subject, content) valuse ('질문 있습니다.', 'ORM이 궁금합니다.')하지만 ORM 을 사용하면 쿼리 대신 파이썬 코드로 다음처럼 작성할 수 있다.
question1 = Question(subject='안녕하세요', content='가입 인사드립니다. ^^')
question2 = Question(subject='질문 있습니다.', content='ORM이 궁금합니다.')코드에서 Question은 파이썬 클래스이며, 이처럼 데이터를 관리하는 데 사용하는 ORM 클래스를 모델이라고 한다. 모델을 사용하면 내부에서 SQL 쿼리를 자동으로 생성해 주므로 직접 작성하지 않아도 된다. 즉, 파이썬만 알아도 데이터베이스에 질의할 수 있다.
플라스크 ORM 라이브러리 사용하기
파이썬 ORM 라이브러리 중 가장 많이 사용하는 SQLAlchemy,
파이썬 모델을 이용해 테이블을 생성하고 칼럼을 추가하는 등의 작업을 할 수 있게 해주는 Flask-Migrate 라이브러리도 사용해 보자.
-
Flask-Migrate 라이브러리를 설치하면 SQLAlchemy도 함께 설치된다.
가상환경에서pip install Flask-Migrate를 입력하자. -
파이보에 ORM을 적용하려면 config.py라는 설정 파일이 필요하다. 루트 디렉터리에 config.py 파일을 생성하고 다음과 같은 코드를 작성한다.
import os
# 프로젝트의 루트 디렉터리
BASE_DIR = os.path.dirname(__file__)
# SQLALCHEMY_DATABASE_URI는 데이터베이스 접속 주소이다.
SQLALCHEMY_DATABASE_URI = 'sqlite:///{}'.format(os.path.join(BASE_DIR, 'pybo.db'))
# SQLALCHEMY_TRACK_MODIFICATION는 SQLAlchemy의 이벤트를 처리하는 옵션이다.
SQLALCHEMY_TRACK_MODIFICATIONS = False- ORM 적용하기
__init__.py파일을 수정해 SQLAlchemy를 적용하자.
이때 db, migrate 와 같은 객체를 create_app 함수 밖에서 생성하고 실제 초기화는 create_app 함수에서 수행하는 패턴을 자주 사용한다.
from flask import Flask
from flask_migrate import Migrate
from flask_sqlalchemy import SQLAlchemy
import config
db=SQLAlchemy()
migrate=Migrate()
def create_app():
app=Flask(__name__)
#config.py 파일에 작성한 항목을 app.config 환경 변수로 부르기 위한 코드
app.config.from_object(config)
#ORM
#객체 초기화
db.init_app(app)
migrate.init_app(app,db)
#블루프린트
from .views import main_views
app.register_blueprint(main_views.bp)
return app- 데이터베이스 초기화하기
이제 ORM을 사용할 준비가 되었으므로 가상환경에서 flask db init 명령으로 데이터베이스를 초기화한다. 이 명령은 최초 한 번만 수행하면 된다.
이 명령을 수행하면 루트디렉터리 폴더 내에 migrations 폴더가 생성된다.
앞으로 모델을 추가하거나 변경할 때는 아래와 같은 명령을 사용한다. 데이터베이스 관리를 위해 기억해 두자.flask db migrate // 모델을 새로 생성하거나 변경할 때 사용
flask db upgrade // 모델의 변경 내용을 실제 데이터베이스에 적용할 때 사용
모델 만들기
-
모델 속성 구상
질문 모델 : id, subject, content, create_date
답변 모델 : id, question_id content create_date -
질문 모델 생성
pybo 디렉터리에 models.py 파일을 생성하고 Question 클래스를 정의한다.
from pybo import db
class Question(db.Model):
id=db.Column(db.Integer, primary_key=True)
subject=db.Column(db.String(200), nullable=False)
content=db.Column(db.Text(), nullable=False)
create_date=db.Column(db.DateTime(), nullable=False)Question 클래스는 모든 모델의 기본 클래스인 db.Model을 상속받았다. 이때 db는 __init__.py 파일에서 생성한 SQLAlchemy 객체다.
각 속성은 db.Column 클래스를 사용해 생성하고, 괄호 안의 첫번째 옵션은 필수 옵션으로, 데이터 타입을 의미한다.
primary_key 옵션은 속성을 기본 키로 지정한다. 데이터를 구분하는 유효한 값으로 중복되면 안 된다.
nullable 옵션을 지정하지 않으면 기본으로 빈값을 허용한다. 빈값을 허용하지 않으려면 nullable=False 옵션을 지정하자.
- 답변 모델 생성
Answer 클래스도 아래와 같이 작성한다.
이때 quesiton_id 속성은 질문 모델과 연결하기 위해 추가했다. 답변 모델은 어떤 질문에 대한 답변인지 표시해야 하므로 2단계에서 생성한 질문 모델과 연결된 속성을 포함해야 한다. 이처럼 어떤 속성을 기존 모델과 연결하려면 db.ForeignKey를 사용해야 한다.
그다음 question 속성은 답변 모델에서 질문 모델을 참조하려고 추가했다. 예를 들어 답변 모델 객체에서 질문 모델 객체의 제목을 참조(기존 모델을 참조)한다면 answer.question.subject처럼 할 수 있다. 이렇게 하려면 속성을 추가할 때 db.Column이 아닌 db.relationship을 사용해야 한다.
(...생략...)
class Answer(db.Model):
id=db.Column(db.Intiger, primary_key=True)
# db.ForeignKey 에 지정한 첫 번째 값은 연결할 모델의 속성명, 두번째 ondelete에 지정한 값은 삭제 연동 설정이다.
# ondelete='CASCADE' 에 의해 데이터베이스에서 쿼리를 이용해 질문을 삭제하면 해당 질문에 달린 답변도 함께 삭제된다.
question_id=db.Column(db.Integer, db.ForeignKey('question.id',ondelete='CASCADE'))
# db.relationship에 지정한 첫 번째 값은 참조할 모델이고, 두 번째 backref에 지정한 값은 역참조 설정이다.
# 역참조란 쉽게 말해 질문에서 답변을 참조하는 것을 의미한다. 한 질문에는 여러 답변이 달릴 수 있는데 역참조는 이 질문에 달린 답변을 참조할 수 있게 한다.
# 예를 들어 어떤 질문에 해당하는 객체가 a_question이라면 a_question.answer_set와 같은 코드로 해당 질문에 달린 답변을 참조할 수 있다.
question=db.relationship('Question', backref=db.backref('answer_set',))
content=db.Column(db.Text(),nullable=False)
create_date=db.Column(db.DateTime(),nullable=False)모델을 이용해 테이블 자동으로 생성하기
- 모델 가져오기
모델을 생성했으므로 플라스크의 Migrate 기능을 이용해 데이터베이스 테이블을 생성해 보자.
pybo/__init__.py
(...생략...)
#ORM
db.init_app(app)
migrate.init_app(app,db)
# migrate 객체가 models.py 파일 참조하게 함
from . import models
(...생략...)-
데이터베이스 변경을 위한 리비전 파일 생성
Question과 Answer 모델을 추가했으므로 데이터베이스가 변경되도록 가상환경에서 flask db migrate 명령을 수행한다.
이 명령을 수행하면 데이터베이스 변경을 처리할 리비전 파일이 생성된다. -
데이터베이스 갱신
이어서 flask db upgrade 명령으로 리비전 파일을 실행하자.
이 과정에서 데이터베이스에 모델 이름과 똑같은 question과 answer라는 이름의 테이블이 생성된다. 제대로 수행했다면 projects/myproject 디렉터리에 pybo.db 파일이 생성되는데, pybo.db가 바로 SQLite 데이터베이스의 데이터 파일이다.
생성된 테이블을 살펴보려면
1. DB Browser for SQLite 설치하기
2. DB 브라우저에서 pybo.db 열기
를 하면 된다.
모델 사용하기
프로젝트에서 모델을 본격적으로 사용하기 전에 '플라스크 셸'이라는 도구를 사용해 모델 사용법을 알아보자.
-
플라스크 셸 실행하기
가상환경에서 flask shell 명령으로 실행한다. -
질문 데이터 저장하기
다음 명령을 수행해 Question과 Answer 모델을 플라스크 셸에 불러오자. 그런 다음 Question 모델 객체를 하나 생성해 보자.
from pybo.models import Question, Answer
from datetime import datetime
q = Question(subject='pybo가 무엇인가요?', content='pybo에 대해서 알고 싶습니다.', create_date=datetime.now())여기서 객체 q를 만들었다고 해서 데이터베이스에 저장되는 것은 아니다. 데이터베이스에 저장하려면 다음처럼 SQLAlchemy의 db객체를 사용해야 한다.
from pybo import db
db.session.add(q)
db.session.commit()신규 데이터를 저장할 때는 add 함수를 사용한 다음 commit함수까지 실행해야 한다. db.session은 데이터베이스와 연결된 세션, 즉 접속된 상태를 의미한다. 데이터베이스를 처리하면 이 세션이 필요하다. 세션을 통해서 데이터를 저장, 수정, 삭제 작업을 한 다음에는 반드시 db.session.commit 함수로 커밋을 해 주어야 한다.
여기서 주의할 점은 커밋은 취소할 수 없다는 것이다. 커밋은 일종의 '결정인' 역할을 한다고 생각하면 이해하기 쉽다. 그래서 수행한 작업을 취소하려면 커밋 이전에 진행해야 한다. 이때 작업을 취소하고 싶으면 db.session.rollback 함수를 실행하자.
데이터를 생성할 때 속성값이 자동으로 1씩 증가한다. 두 번째 질문 데이터를 생성하고 id를 확인해 보면 2가 출력된다.
q = Question(subject='플라스크 모델 질문입니다.', content='id는 자동으로 생성되나요?', create_date=datetime.now())
db.session.add(q)
db.session.commit()
q.id #출력결과 2가 나온다.- 데이터 조회하기
저장된 데이터를 모두 조회해 보자.
Quesiton.query.all()
# '[<Question 1>, <Question 2>]' 가 출력된다.filter 함수를 이용해 첫 번째 질문 데이터만 조회하자.
Question.query.filter(Question.id==1).all()
# '[<Question 1>]' 가 출력된다.filter 대신 get 함수를 이용해 조회할 수도 있다.
Question.query.get(1)
# '<Question 1>' 가 출력된다.다만 get 함수로 조회하면 리스트가 아닌 Question 객체 1개만 반환된다. filter와 like 함수로 subject 속성에 '플라스크'라는 문자열이 포함된 데이터를 조회해 보자.
Question.query.filter(Question.subject.like('%플라스크%')).all()
# '[<Question 2>]' 가 출력된다.이때 like 함수에 전달한 % 표기는 다른 문자열을 포함하는지를 나타낸다.
- 데이터 수정하기
데이터를 수정해 보자. 데이터를 수정할 때는 단순히 대입연산자를 사용하면 된다.
q = Quesiton.query.get(2)
q.subject = 'Flask Model Question'
db.session.commit()데이터를 변경한 후에는 반드시 커밋을 수행해야 데이터베이스에 반영되는 걸 잊지 말자.
- 데이터 삭제하기
q = Question.query.get(1)
db.session.delete(q)
db.session.commit()- 데이터 생성 후 저장하기
from datetime from datetime
from pybo.models import Question,Answer
from pybo import db
q = Question.query.get(2)
a = Answer(question=q, content='네 자동으로 생성됩니다.', create_date=datetime.now())
db.session.add(a)
db.session.commit()답변 데이터를 생성하려면 질문 데이터가 필요하므로 우선 질문 데이터를 구해야 한다. id가 2인 질문 데이터를 가져온 다음 q에 저장했다. 그런 다음 Answer 모델의 question 속성에 방금 가져온 q를 대입해 답변 데이터를 생성했다.
- 답변에 연결된 질문 찾기 / 질문에 달린 답변 찾기
앞에서 구성한 Answer모델의 question 속성을 이용하면 답변에 연결된 질문을 조회할 수 있다.
a.question
# '<Question 2>' 가 출력된다.질문에서 답변을 찾는 경우는, question 속성에 역참조 설정 backref=db.backref('answer_set')을 적용했다. 그러므로 이를 사용하면 질문과 연결된 답변을 쉽게 가져올 수 있다.
q.answer_set
# '<Answer 1>' 가 출력된다.질문 목록 조회와 질문 상세 조회 기능 만들기
질문 목록 조회 기능 만들기
- 게시판 질문 목록 출력하기
pybo/views/main_views.py를 다음과 같이 수정해 보자.
from flask import Blueprint,render_template
from pybo.models import Question
bp=Blueprint('main',__name__, url_prefix='/')
@bp.route('/hello')
def hello_pybo():
return 'Hello, Pybo!'
@bp.route('/')
def index():
question_list = Question.query.order_by(Question.create_date.desc())
return render_template('question/question_list.html', question_list=question_list)
- 질문 목록 템플릿 파일 작성하기
이제 render_template 함수에서 사용할 question/question_list.html 템플릿 파일을 작성해야 한다. 그런데 이 파일은 어디에 저장할까? 바로 플라스크가 앱으로 지정한 모듈 아래에 templates 라는 디렉터리에 저장하면 된다. 가상환경에서 templates 디렉터리를 생성하자.
(템플릿 파일이란? - 쉽게 말해 파이썬 문법을 사용할 수 있는 HTML 파일이다. 템플릿 파일은 HTML 파일과 비슷하지만 플라스크의 특별한 태그를 사용할 수 있다.)
cd pybo
mkdir templatesrender_template 함수에 지정한 템플릿 파일명은 question/question_list.html 이므로 이 이름으로 템플릿 파일을 생성하고 다음과 같이 코드를 작성하자.
pybo/templates/question/question_list.html
{% if question_list %}
<ul>
{% for question in quesiton_list %}
<li><a href="/detail/{{question.id}}/">{{question.subject}}</a></li>
{% endfor %}
</ul>
{% else %}
<p>질문이 없습니다.</p>
{% endif %}템플릿 파일에 입력된 {% 와 %} 로 둘러싸인 문장을 템플릿 태그라고 한다. 이 태그가 파이썬 코드와 연결된다.
{% if question_list %} 이 코드는 함수에서 전달받은 질문 목록 데이터 question_list가 있는지 검사한다.
{% for question in question_list %} 이 코드는 question_list에 저장된 데이터를 하나씩 꺼내 question객체에 대입한다.
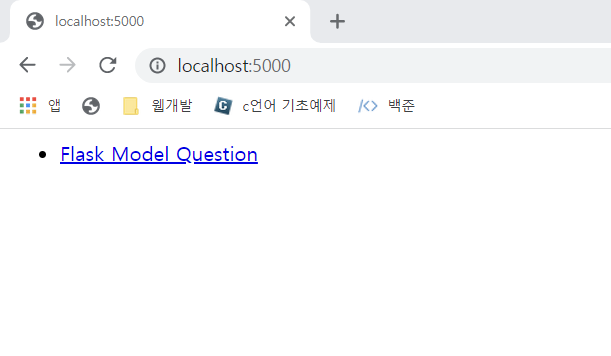
localhost:5000 에 접속시 다음과 같은 화면을 볼 수 있다.
게시판 상세 조회 기능 만들기
앞선 실습에서 만든 질문 목록 조회 페이지에서 질문 링크를 눌러 보면 다음과 같은 오류 메시지가 표시된다.
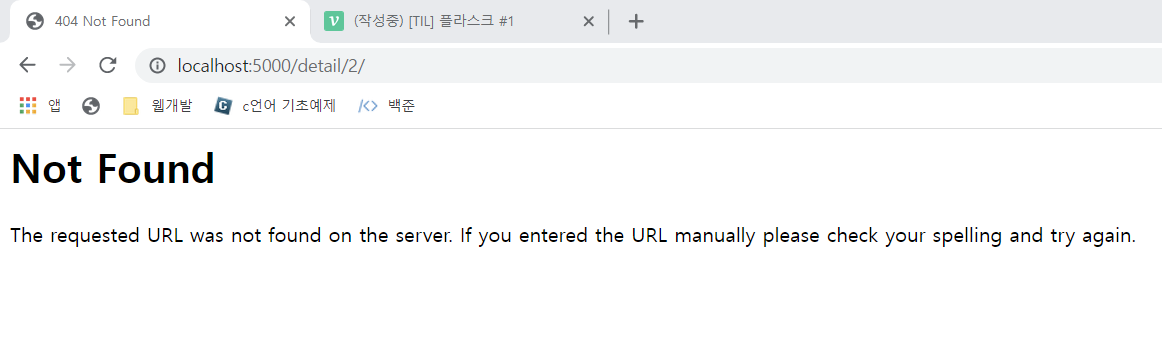
이 오류는 주소 표시줄에 보이는 localhost:5000/detail/2/ 페이지의 URL을 정의하지 않아 발생한 것이다. 이 문제를 해결해 질문 제목과 내용이 표시되도록 해보자.
- 라우트 함수 구현하기
질문 목록에서 링크를 누르면 localhost:5000/detail/2/ 과 같은 질문 상세 조회 URL을 요청한다. 이 URL은 'Question 모델 데이터 중 id값이 2인 데이터를 조회하라'는 의미다. 이와 같은 요청 URL에 대응할 수 있도록 main_views.py 파일에 @bp.route와 함께 detail 함수를 추가하자.
pybo/views/main_views.py
(...생략...)
@bp.route('/detail/<int:question_id>/')
def detail(question_id):
question = Question.query.get(question_id)
return render_template('question/question_detail.html',question=question)detail 함수의 매개변수 question_id에는 라우트 매핑 규칙에 사용한 <int:question_id> 가 전달된다. 즉, localhost:5000/detail/2/ 페이지를 요청하면 main_views.py 파일의 detail 함수가 실행되고, 매개변수 question_id에는 2라는 값이 전달된다.
- 질문 상세 템플릿 파일 작성하기
이어서 질문 상세 조회 화면에 해당하는 question/question_detail.html 템플릿 파일을 작성한다. templates/question 디렉터리에 question_detail.html 파일을 만들고 다음 코드를 작성한다.
pybo/templates/question/question_detail.html
<h1>{{question.subject}}</h1>
<div>
{{question.content}}
</div>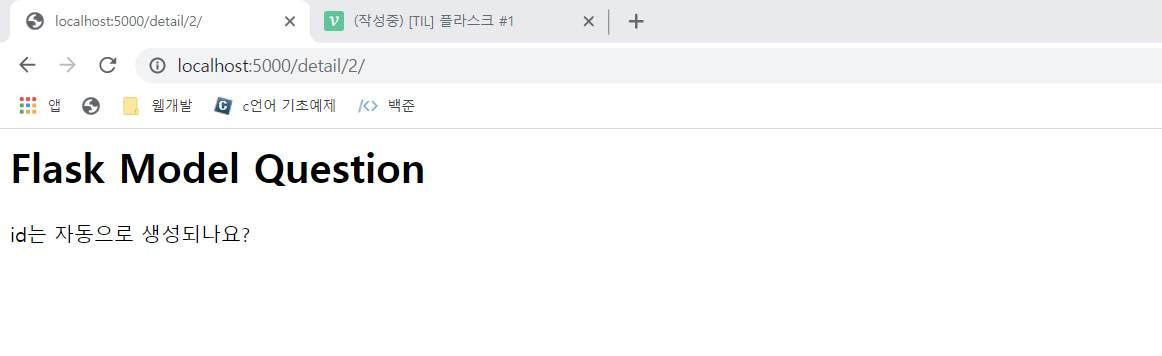
- 404 오류 페이지 표시하기
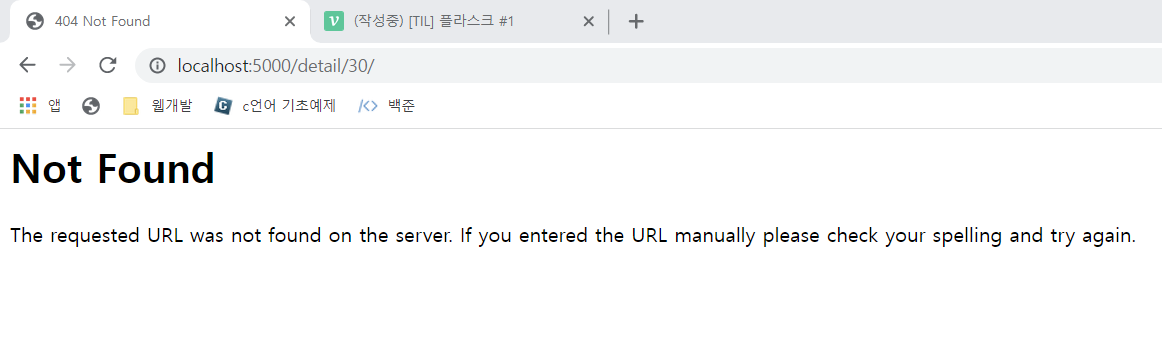
localhost:5000/detail/30/ 페이지를 요청하면 빈 페이지가 나타난다. 이처럼 잘못된 URL을 요청받을 때 단순히 빈 페이지를 표시하면 안 된다. 이때는 보통 'Not Found (404)'처럼 오류 페이지를 표시해야 한다. 다음처럼 detail 함수의 일부를 수정해 보자.
pybo/views/main_views.py
(...생략...)
@bp.route('/detail/<int:question_id>/')
def detail(question_id):
question = Question.query.get_or_404(question_id)
return render_template('question/question_detail.html',question=question)기존 get 함수 대신 get_or_404 함수를 사용했다. localhost:5000/detail/30 접속시 아래와 같이 빈화면이 아닌 Not Found 가 출력되는 걸 볼 수 있다.
블루프린트로 기능 분리하기
질문 목록 조회와 질문 상세 조회 기능을 main_views.py 파일에 구현했다. 모든 기능을 main_views.py 파일에 구현할 수도 있지만, 각 기능을 블루프린트 파일로 분리해서 관리하면 유지보수 하는 데 유리하다.
- 질문 목록 조회, 질문 상세 조회 기능 분리하기
pybo/views 디렉터리에 question_views.py 파일을 새로 만들고 질문 목록 조회와 질문 상세 조회 기능을 이동해보자.
pybo/views/question_views.py
from flask import Blueprint, render_template
from pybo.models import Question
bp = Blueprint('question',__name__,url_prefix='/question')
@bp.route('/list/')
def _list():
question_list = Question.query.order_by(Question.create_date.desc())
return render_template('question/question_list.html', question_list=question_list)
@bp.route('/detail/<int:question_id>/')
def detail(question_id):
question = Question.query.get_or_404(question_id)
return render_template('question/question_detail.html', question=question)블루프린트를 적용하기 위해 아래 파일도 수정하자.
pybo/__init__.py
(...생략...)
#블루프린트
from .views import main_views,question_views
app.register_blueprint(main_views.bp)
app.register_blueprint(question_views.bp)
(...생략...)2.url_for로 리다이렉트 기능 추가하기
question_views.py 파일에 질문 목록과 질문 상세 조회 기능을 구현했으므로 main_veiws.py 파일에서는 해당 기능을 제거하자.
from flask import Blueprint,url_for
from werkzeug.utils import redirect
from pybo.models import Question
bp=Blueprint('main',__name__, url_prefix='/')
@bp.route('/hello')
def hello_pybo():
return 'Hello, Pybo!'
@bp.route('/')
def index():
return redirect(url_for('question._list'))이때 redirect 함수는 입력받은 URL로 리다이렉트 해 주고, url_for 함수는 라우트가 설정된 함수명으로 URL을 역으로 찾아준다.
url_for 함수에 전달된 question._list 는 quesiton, _list 순서로 해석되어 함수명을 찾아준다. question은 등록된 블루프린트 이름, _list는 블루프린트에 등록된 함수명이라 생각하면 된다. 현재 _list 함수에 등록된 라우트는 @bp.route('/list/')이므로 url('question._list')는 bp의 접두어인 /question/과 /list/가 더해진 /question/list/URL 을 반환한다.
이제 localhost:5000 에 접속하면 리다이렉트 기능 덕분에 localhost:5000/question/list/ 페이지가 호출될 것이다.
- 하드 코딩된 URL에 url_for 함수 이용하기
앞서 url_for 함수를 이용하면 라우트가 설정된 함수명으로 URL을 찾아준다고 했다. 이 기능을 이용해 질문 목록 템플릿에서 질문 상세 조회를 호출하는 코드도 url_for를 이용해 수정하자.
pybo/templates/question/question_list.html
{% if question_list %}
<ul>
{% for question in question_list %}
<li><a href="{{url_for('question.detail', question_id=question.id)}}">{{question.subject}}</a></li>
{% endfor %}
</ul>
{% else %}
<p>질문이 없습니다.</p>
{% endif %}기존에 설정한 URL이 /detail/처럼 하드 코딩되어 있었다. 이 부분을 url_for 함수를 이용해 question.detail 라우트 함수로 URL을 찾도록 변경했다. 이때 question.detail 함수는 question_id 매개변수가 필요하므로 question_id 를 전달해야 한다.
