이 글은 공부한 내용을 기록용으로 남기는 글로, 학교에서 교양 수업으로 주피터 노트북(jupyter notebook)으로 엑셀 csv파일 분석 및 시각화 하는 수업을 수강했다. 이 글은 컴퓨터 포멧을 하기 전에 기록하는 게 좋을 것 같아서 쓰는 글이다.
그리고 벌써 대학생 2학년.. ㅎㄷㄷ
전처리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
leftitemData = pd.read_csv("./서울특별시 대중교통 분실물 습득물 정보.csv")
backupFile = leftitemData.copy()
df1 = leftitemData.copy()
위의 코드를 입력하고 df1.shape 를 입력하면 저 두 숫자가 나온다.
14개의 필드와 약 270000개의 행을 가진 csv 파일을 분석 및 시각화 할 것이다.
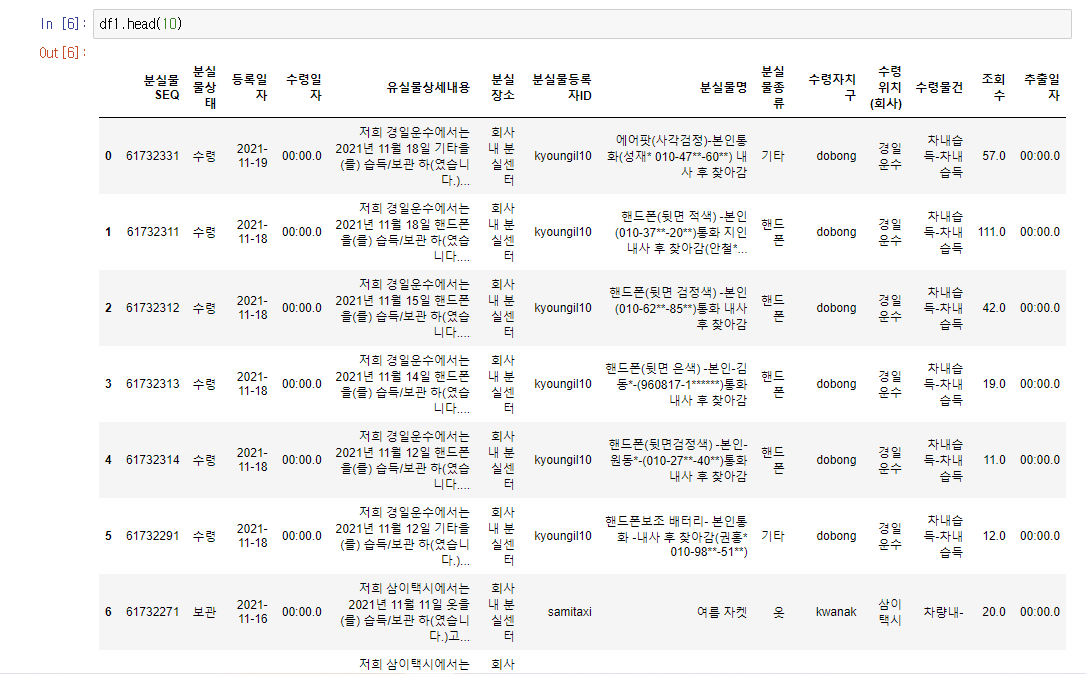
그리고 df.head(10) 을 입력하면 위 사진처럼 생긴 csv 파일을 분석한다는 걸 알 수 있다.
그전에 전처리 과정을 거쳐야 한다.
#필요없는 데이터 필드 제거
del df1['분실물SEQ']
del df1['수령일자']
del df1['분실물등록자ID']
del df1['조회수']
del df1['추출일자']
9개의 필드가 남는데, 그 중에서 비어있는 행을 출력하면 위의 사진처럼 나온다.
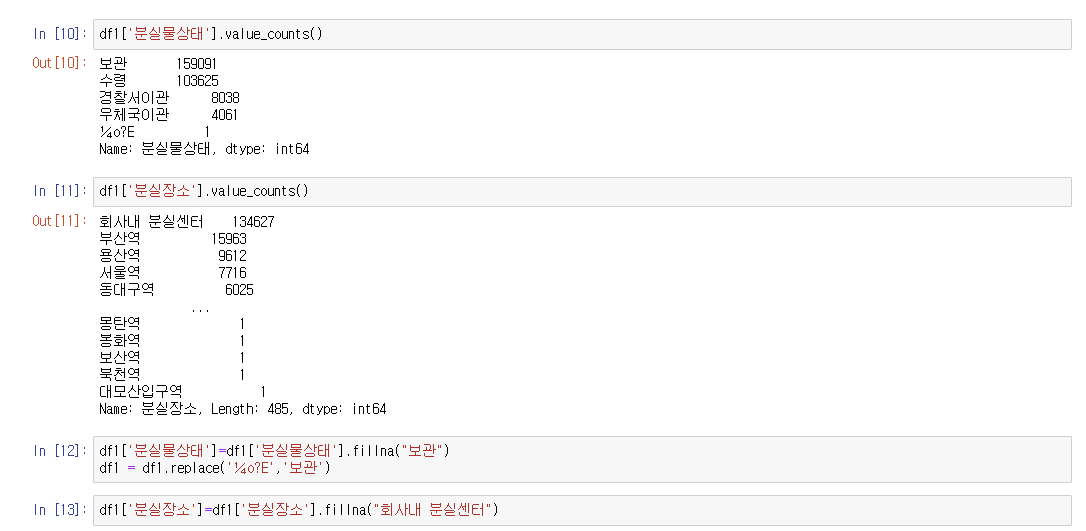
위의 사진처럼 '분실물상태' 와 '분실장소' 는 각각 최빈값인 '보관'과 '회사내 분실센터'로 채워넣었다.
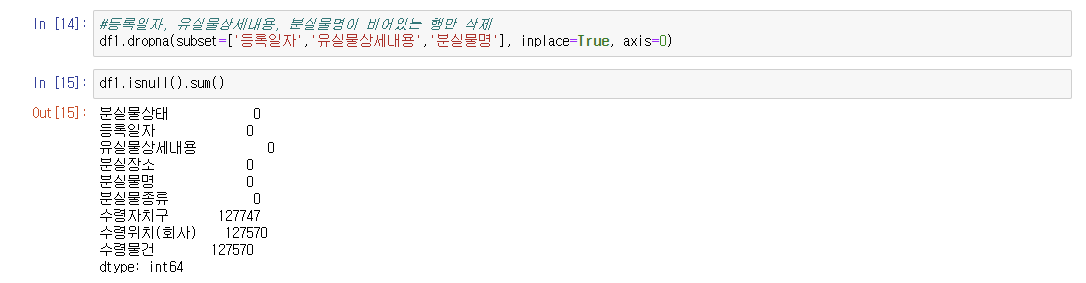
나머지 '등록일자', '유실물상세내용', '분실물명' 필드는 비어있는 행만 삭제했다.
수령 관련한 행이 약 12만개 비어져 있는 걸 확인할 수 있는데, 어떻게 전처리해야 할 지 몰라서 놔두었다.
그외엔 null값으로 된 필드가 없는 걸 확인할 수 있다.
이제 데이터 분석을 시작해 보자.
주제 1. 년도별로 보는 분실물! 수령했을까? 보관중일까?
#등록일자 타입을 문자로 변경
df1['등록일자'].astype(str)
#'등록일자_년도' 필드를 '등록일자'의 년도를 추출하여 새로 필드를 생성
df1['등록일자_년도']=df1['등록일자'].str[0:4].astype(int)
#'등록일자_년도', '분실물상태' 필드를 기준으로 수를 세는 집계함수로 '분실물상태' 필드의 행 갯수를 센다.
#['분실물상태'] 외에 등록일자, 유실물상세내용 등 다른 필드를 넣어도 무방하다.
aaa=df1.groupby(by=["등록일자_년도","분실물상태"])['분실물상태'].agg(["count"])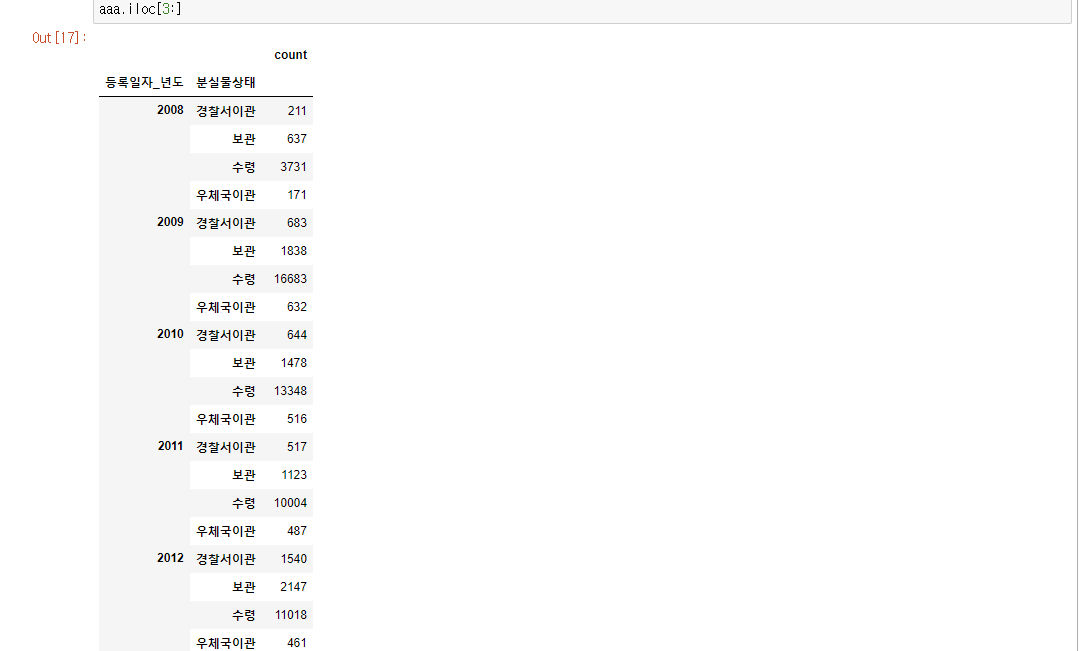
출력해 보면 위 사진과 같다.
# 2008년부터 2022년까지 리스트 생성
leftYear = list(range(2008,2022))
print(leftYear)
suryeong = [ 0 for i in range(len(leftYear)) ]
bogwan = [ 0 for i in range(len(leftYear)) ]
# tolist는 pandas에 있는 값을 (?) 리스트 형태로 변경해 준다.
# 그리고 sum([리스트명],[])은 2차원 배열을 1차원 배열로 바꿔준다.
for i in range(len(leftYear)):
bogwan[i] = aaa.iloc[3:].values.tolist()[i*4+1]
suryeong[i] = aaa.iloc[3:].values.tolist()[i*4+2]
bogwan = sum(bogwan,[])
suryeong = sum(suryeong,[])
# 데이터 시각화
plt.rcParams['figure.figsize'] = (12,8)
plt.rcParams['font.family']='Malgun Gothic'
plt.figure()
x=np.arange(len(leftYear))
plt.xlabel("연도")
plt.ylabel("분실물 수")
plt.title("년도별 분실물 수령/보관 수")
plt.bar(x-0.1,bogwan,width=0.2,color='orange',label='보관')
plt.bar(x+0.1,suryeong,width=0.2,color='cyan',label='수령')
plt.legend()
plt.xticks(x,leftYear)결과
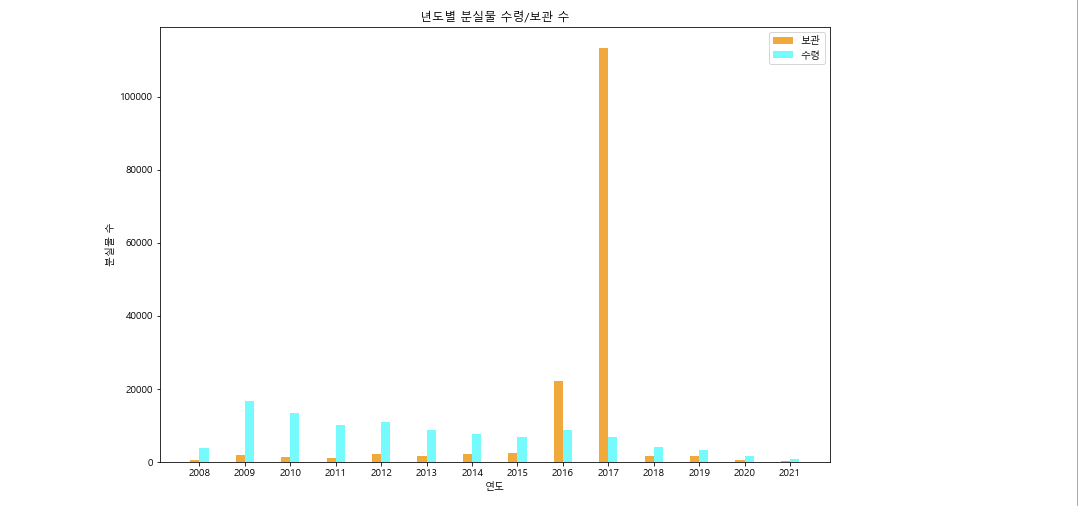
주제 2. 어디서 잃어버렸을까?
import folium as fm
leftPlace = df1.groupby(by=['분실장소'])['분실물상태'].agg(['count'])
leftPlace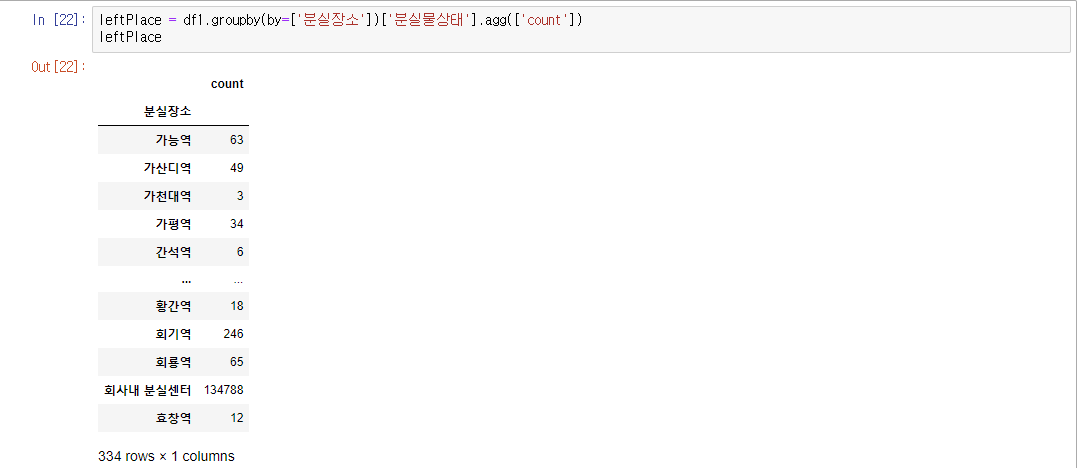
# 분실물 발생 역에 따른 분실물 수
leftVal = leftPlace.values
leftVal = leftVal.tolist()
leftVal = sum(leftVal,[])
# 분실물 발생 역 이름
leftPoint=df1['분실장소'].tolist()
leftPoint=list(set(leftPoint))
leftPoint.sort()
del leftPoint[leftPoint.index('회사내 분실센터')]
del leftPoint[leftPoint.index('우체국')]
del leftPoint[leftPoint.index('경찰서')]
leftPoint
#위의 두 리스트 합치기
leftMerge = [[i,j] for i,j in zip(leftVal,leftPoint) ]
leftMerge.sort(reverse=True)
hanguk_map = fm.Map(location=[36.5,127],zoom_start=7)
pointVal=[
[35.16406320755192, 129.06043834018325], #부전역
[37.728033514606395, 126.76859238475262],
[37.057157095766826, 127.05335837103293],
[37.92678246003923, 127.05493835385472],
[36.341715400552765, 126.5867134556729],
[36.2731263745939, 127.26532518450753],
[37.581627551088296, 127.0489258115193],
[34.94594727881839, 127.50331364215194],
[37.4478165404238, 126.45797300966365],
[37.653523347256176, 126.8428772519959],
[37.40172425527805, 126.70866054035136],
[37.81893796062869, 127.05668672686899],
[37.60348487890358, 127.1433464422088],
[37.623826465954885, 127.06179443638975],
[37.4028294679512, 126.92213542871266],
[35.165544507384745, 126.90920029797599],
[36.283280804757915, 128.094234],
[35.55151826933835, 129.138602557509],
[35.64026780356562, 128.74659055751087],
[37.91440394429525, 127.05719018454337],
[37.26205591153484, 127.03118537103741],
[34.93004367812572, 126.50320008262658],
[35.30727980080725, 128.9852768114706],
[37.49148564536503, 127.07286828638682],
[35.26580644842814, 129.23341118448639],
[37.29438628836124, 127.5708657440548],
[35.54318214686276, 127.32059457100043],
[37.28222495471059, 127.62862418452937],
[37.299168722418784, 127.10562915172702],
[35.37288920840899, 126.86027699798028],
[37.19581544773365, 127.05199519291983],
[37.46101672282579, 126.63806154003869],
[38.212932576417835, 127.1389904553961],
[37.46618518896929, 126.68069131146838],
[37.48418714248595, 126.78267425169417],
[36.44602413451919, 126.59087570720109],
[37.516332138141316, 127.39950391303098],
[37.691705185945885, 129.03280074373342],
[35.17485037495744, 128.25805391299727],
[37.52254496364785, 126.97377507130226] #이촌역
]
#상위 3개지역은 빨간색 마커
for i in range(0, 3):
marker = fm.Marker([pointVal[i][0],pointVal[i][1]],icon=fm.Icon(color='red'),popup=str(leftMerge[i][1])+":"+str(leftMerge[i][0]))
marker.add_to(hanguk_map)
#나머지는 파란색 마커
for i in range(3, 40):
marker = fm.Marker([pointVal[i][0],pointVal[i][1]],icon=fm.Icon(color='blue'),popup=str(leftMerge[i][1])+":"+str(leftMerge[i][0]))
marker.add_to(hanguk_map)
hanguk_map결과 :
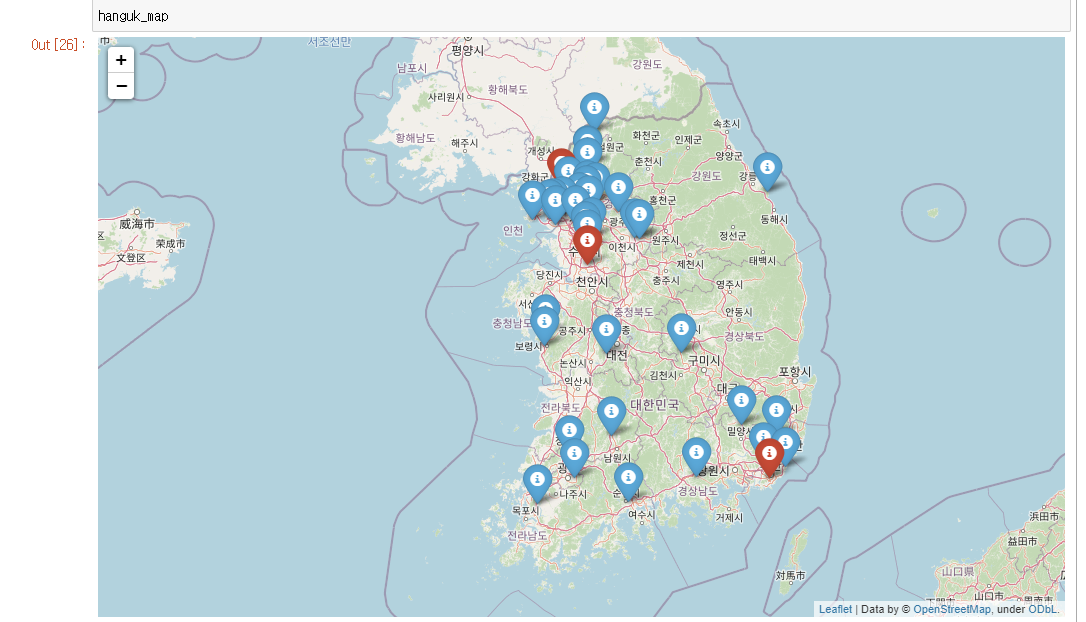
위도와 경도는 웹크롤링이란 기술로 불러올 수 있을 것 같은데...
나한텐 지금 어려운 기술이라 패스.. ㅠ
일일히 위도와 경도를 집어넣었다. 다음에 웹크롤링 기술을 배운다면 활용해 보고 싶다..!
주제 3. 어떤 분실물이 가장 많을까?
many = df1.groupby(by=['분실물종류'])['분실물상태'].agg(['count'])
manyasc=many.sort_values('count')
manyasc.plot.bar()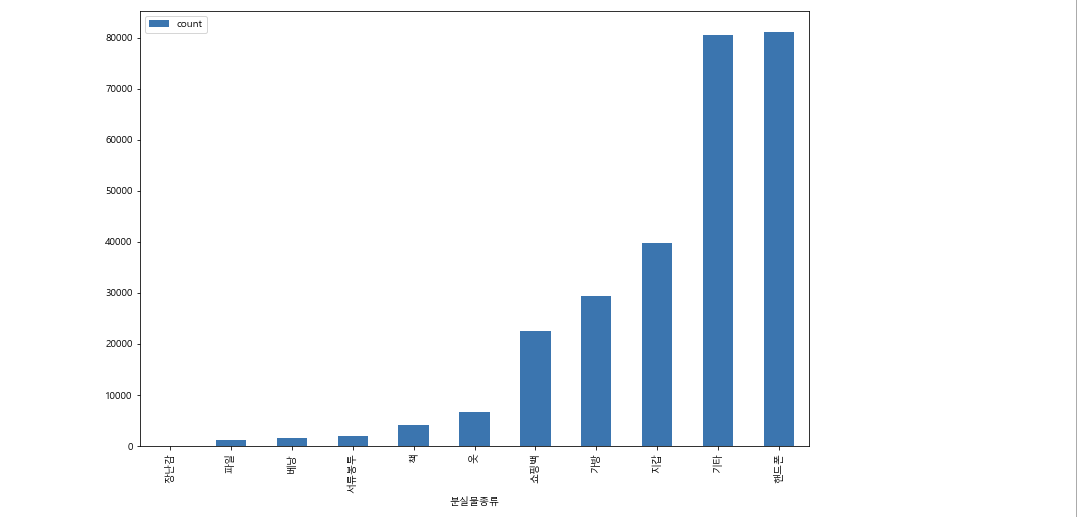
#특정 단어 검색
earphonedf = df1[df1['분실물명'].str.contains('이어폰|에어팟|버즈')]
a = len(earphonedf)
carddf = df1[df1['분실물명'].str.contains('카드')]
b = len(carddf)
umbdf = df1[df1['분실물명'].str.contains('우산')]
c = len(umbdf)
gladf = df1[df1['분실물명'].str.contains('안경')]
d = len(gladf)
keydf = df1[df1['분실물명'].str.contains('열쇠|차키')]
e = len(keydf)
winterdf = df1[df1['분실물명'].str.contains('장갑|목도리|털모자')]
f = len(winterdf)
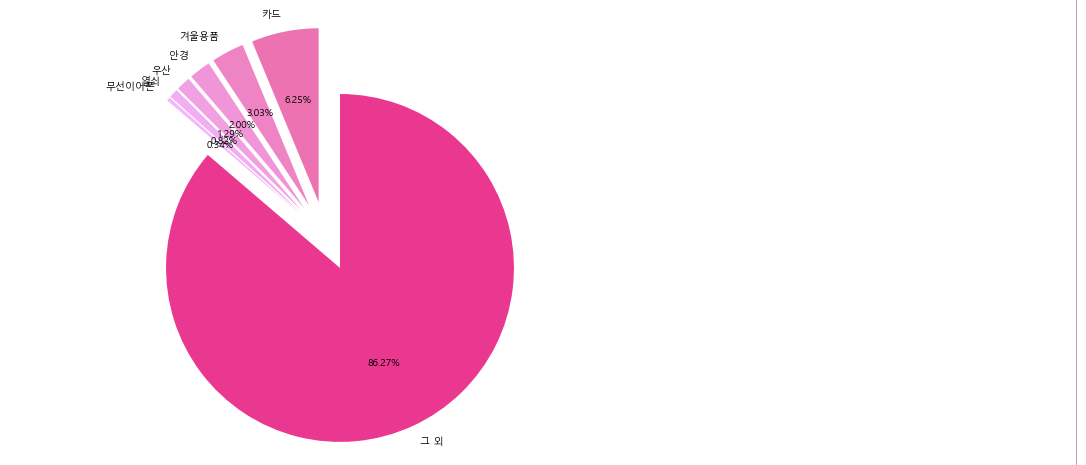
colorgroup = ['#FF69B4','#FF7DC8','#FF91DC','#FF9BE6','#FFAAF5','#FFB4FF','#FF1493']
g = len(df1['분실물종류'] == '기타') - a-b-c-d-e-f
explodelist = [ 0.2 for i in range(7)]
plt.pie([b,f,d,c,e,a,g],labels=["카드","겨울용품","안경","우산","열쇠","무선이어폰","그 외"],
startangle=90,autopct='%1.2f%%',colors=colorgroup,explode=explodelist)결과 :

흔한 컴공러 / 3학년