이 글은 공부한 내용을 기록용으로 남기는 글로, 학교에서 교양 수업으로 주피터 노트북(jupyter notebook)으로 엑셀 csv파일 분석 및 시각화 하는 수업을 수강했다. 이 글은 컴퓨터 포멧을 하기 전에 기록하는 게 좋을 것 같아서 쓰는 글이다.
그리고 벌써 대학생 2학년.. ㅎㄷㄷ
주제 1. 해양 쓰레기, 어디가 가장 많을까?
import csv
import matplotlib.pyplot as plt
# csv에 나온 지역명 추출
f=open("해양환경공단_해양쓰레기 모니터링 통계_2기조사방법_유형별.csv","r", encoding="cp949")
data = csv.reader(f, delimiter=",")
header=next(data)
지역=[]
for i in data :
if i[2] not in 지역: #지역 이름 추출
지역.append(i[2])
# 지역별로 해양쓰레기 수 추출
f=open("해양환경공단_해양쓰레기 모니터링 통계_2기조사방법_유형별.csv","r", encoding="cp949")
data = csv.reader(f, delimiter=",")
header=next(data)
쓰레기수 = [ 0 for i in range(len(지역))] #추출한 지역 수 만큼 쓰레기수 리스트 0으로 전부 초기화
for i in data :
쓰레기수[지역.index(i[2])] += int(i[7])
# 지역명 + 해양쓰레기 수
지역별_쓰레기수 = []
for i in range(len(지역)):
지역별_쓰레기수.append([지역[i],쓰레기수[i]])
지역별_쓰레기수.sort(key = lambda x : x[1]) #(지역, 쓰레기수)에서 쓰레기수만 비교해서 오름차순으로 정렬
#예시 : [[1,4],[2,3],[3,2]] → [[3,2],[2,3],[1,4]]
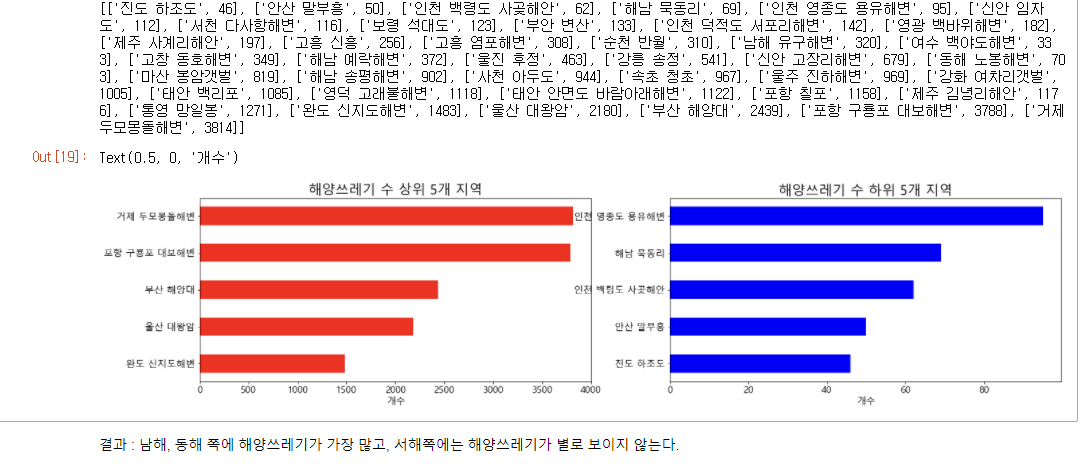
print(지역별_쓰레기수)
# 상위 5개 지역 / 하위 5개 지역
max5 = 지역별_쓰레기수[-5:] #해양쓰레기 상위 5개 지역+쓰레기수 를 max5 에 저장
max_name = [] #상위 지역 5개 리스트
max_cnt = [] #상위 해양쓰레기 5개 리스트
for i in range(5):
max_name.append(max5[i][0])
max_cnt.append(max5[i][1])
min5 = 지역별_쓰레기수[:5] #해양쓰레기 하위 5개 지역+쓰레기수 를 min5 에 저장
min_name = [] #하위 지역 5개 리스트
min_cnt = [] #하위 해양쓰레기 5개 리스트
for i in range(5):
min_name.append(min5[i][0])
min_cnt.append(min5[i][1])
# 가로23, 세로5인 큰 액자 안에, 1행 2열로 액자들을 그린다.
plt.rc('font', family='Malgun Gothic')
fig, ax = plt.subplots(1, 2, figsize=(23, 5))
# 각 액자들에 그래프를 그린다.
ax[0].barh(max_name,max_cnt, height=0.5,color='red')
ax[0].set_title('해양쓰레기 수 상위 5개 지역', size=20)
ax[0].set_xlabel('개수')
ax[1].barh(min_name,min_cnt, height=0.5,color='blue')
ax[1].set_title('해양쓰레기 수 하위 5개 지역',size=20)
ax[1].set_xlabel('개수')결과 :
주제 2. 해양 쓰레기의 대표 골칫거리, 플라스틱?
#플라스틱, 종이, 목재, 금속 등 개수를 리스트에 카운트한다.
f=open("해양환경공단_해양쓰레기 모니터링 통계_2기조사방법_유형별.csv","r", encoding="cp949")
data = csv.reader(f, delimiter=",")
header=next(data)
#쓰레기 종류 리스트 등록
종류 = ["플라스틱","종이","목재","금속","천연 섬유","유리","고무","외국기인","기타 재질"]
쓰레기수2=[0 for i in range(len(종류))] #쓰레기 종류 수만큼의 '쓰레기수2' 라는 리스트를 모두 0으로 초기화
for i in data :
쓰레기수2[종류.index(i[4])] += int(i[7]) #쓰레기 수를 종류별로 '쓰레기수2' 리스트에 담기
# 해양쓰레기 종류 + 종류별 쓰레기 수
종류별_쓰레기수 = []
for i in range(len(종류)):
종류별_쓰레기수.append([종류[i],쓰레기수2[i]])
종류별_쓰레기수.sort(key = lambda x : x[1]) #(종류, 쓰레기수)에서 쓰레기수만 비교해서 오름차순으로 정렬
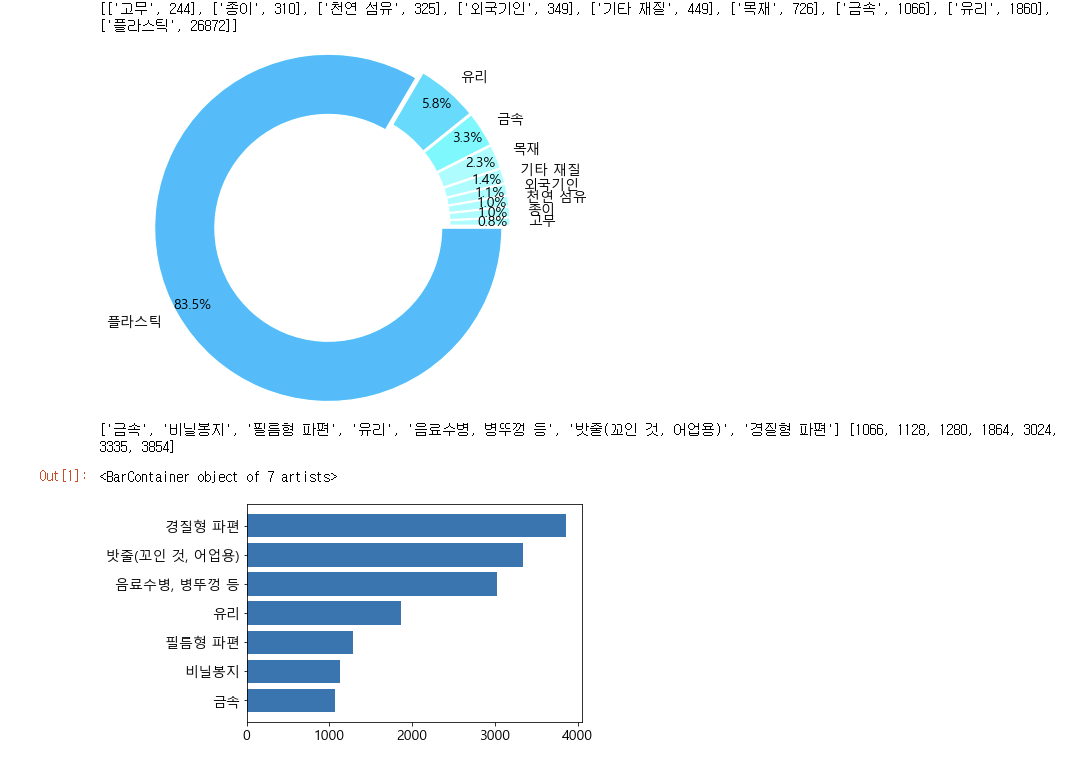
print(종류별_쓰레기수)
#오름차순 정렬된 [종류, 쓰레기수] 를 [종류],[쓰레기수] 로 분류
new종류=[]
new쓰레기수2=[]
for i in range(len(종류)):
new종류.append(종류별_쓰레기수[i][0])
new쓰레기수2.append(종류별_쓰레기수[i][1])
#파이 그래프 그리기
explode = [ 0.05 for i in range(len(종류))]
colorlist=[]
for i in range(len(종류)-3): #상위 3개 쓰레기수 제외하고 같은색으로 칠하기
colorlist.append('#96FFFF')
colorlist.append('#3CFBFF') #쓰레기수 3위 색
colorlist.append('#1EDDFF') #쓰레기수 2위 색
colorlist.append('#00BFFF') #쓰레기수 1위 색
plt.rc('font', family='malgun gothic', size=14)
plt.pie(new쓰레기수2,labels=new종류,explode=explode,autopct='%.1f%%',
pctdistance=0.9,labeldistance=1.1,radius=2,wedgeprops={'width': 0.7, 'edgecolor': 'w', 'linewidth': 2},
colors=colorlist)
plt.show()
#해양쓰레기 상세분류
f=open("해양환경공단_해양쓰레기 모니터링 통계_2기조사방법_유형별.csv","r", encoding="cp949")
data = csv.reader(f, delimiter=",")
header=next(data)
#상세분류 리스트 생성
상세분류=[]
for i in data :
if i[6] not in 상세분류 :
상세분류.append(i[6])
f=open("해양환경공단_해양쓰레기 모니터링 통계_2기조사방법_유형별.csv","r", encoding="cp949")
data = csv.reader(f, delimiter=",")
header=next(data)
#상세분류 쓰레기수 리스트 생성 후 해당 인덱스에 개수 카운트
상세분류cnt=[ 0 for i in range(len(상세분류))]
for i in data :
상세분류cnt[상세분류.index(i[6])] += int(i[7])
상세list = []
for i in range(len(상세분류)):
상세list.append([상세분류[i],상세분류cnt[i]])
상세list.sort(key = lambda x : x[1]) #[[상세분류, 상세분류 쓰레기 수]...] 에서 '상세분류 쓰레기 수'를 기준으로 정렬
상세top7 = [] #상위 7개 쓰레기 상세분류 리스트
상세수top7 = [] #상위 7개 쓰레기 상세분류 수 리스트
for i in range(-8,-1):
상세top7.append(상세list[i][0])
상세수top7.append(상세list[i][1])
print(상세top7,상세수top7)
#상세분류 그래프 그리기
plt.barh(상세top7,상세수top7)결과 :
주제 3. 해양 쓰레기, 갈수록 많아질까?
f=open("해양환경공단_해양쓰레기 모니터링 통계_2기조사방법_유형별.csv","r", encoding="cp949")
data = csv.reader(f, delimiter=",")
header=next(data)
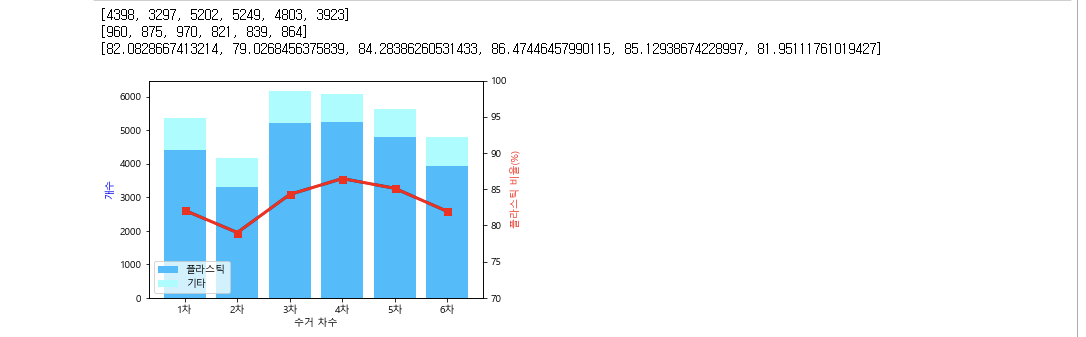
cntlist = ["1차","2차","3차","4차","5차","6차"] #쓰레기 수거 차수 리스트
cntPlastic = [ 0 for i in range(6) ] #1~6차 플라스틱 수 담을 리스트
cntEtc = [ 0 for i in range(6) ] #1~~6차 기타 쓰레기 수 담을 리스트
for i in data :
if i[4] == '플라스틱' :
cntPlastic[cntlist.index(i[3])] += int(i[7]) #플라스틱 수를 cntPlastic 리스트의 해당 차수에 누적
else :
cntEtc[cntlist.index(i[3])] += int(i[7]) #기타 쓰레기를 cntEtc 리스트의 해당 차수에 누적
print(cntPlastic)
print(cntEtc)
PerPla=[] #플라스틱 비율 리스트
for i in range(6):
PerPla.append(cntPlastic[i]/(cntPlastic[i]+cntEtc[i])*100) #플라스틱이 차지하는 비율을 해당 차수에 넣는다.
print(PerPla)
plt.rc('font', family='Malgun Gothic')
fig,ax1=plt.subplots()
#주 그래프 (쓰레기 개수)
ax1.bar(cntlist,cntPlastic,color='#00BFFF',label="플라스틱")
ax1.bar(cntlist,cntEtc,bottom=cntPlastic,color='#96FFFF',label="기타")
ax1.set_xlabel('수거 차수')
ax1.set_ylabel('개수', color='blue')
ax1.legend(loc=3)
#보조 그래프 (플라스틱이 차지하는 비율)
ax2=ax1.twinx()
ax2.plot(cntlist,PerPla,'r-s',markersize=7,linewidth=3)
ax2.set_ylabel('플라스틱 비율(%)', color='red')
ax2.set_ylim(70,100) #보조축 범위
plt.show()결과 :

흔한 컴공러 / 3학년