📌 Brute-force Algorithm
문자열 매칭 알고리즘을 가장 단순하게 구현한 것이다.
int BruteForceMatch(string text, string pattern)
{
for (int i = 0; i <= text.size() - pattern.size(); i++)
{
int j = 0;
while (j < pattern.size() && text[i + j] == pattern[j])
j++;
// match at i
if (j == pattern.size())
return i;
}
return -1;
}시간 복잡도는 Text의 길이와 Pattern의 길이의 곱이다.
단순 비교 알고리즘의 시간 복잡도 : O(NM)
📌 Knuth-Morris-Pratt Algorithm
KMP 알고리즘으로 불리는 문자열 매칭 알고리즘이다. KMP 알고리즘은 패턴을 문장안에서 좌에서 우로 비교하는 것인데, Brute-force 알고리즘과 다르게 패턴의 위치를 좀 더 효율적으로 이동시킨다. 패턴과 문장의 불일치가 발생했을 때 중복연산을 최대한 피하면서 패턴을 우측으로 이동시킨다. 이를 위해서는 문장의 불일치 발생 시, 얼만큼 건너 뛴 후에 비교연산을 할 것인가를 판단하여야 한다.
KMP 알고리즘 비교 예시
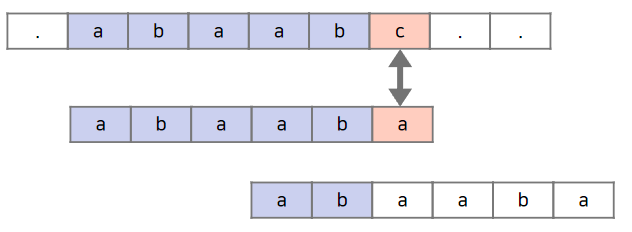
이를 판단하기 위해서는 탐색 문자열의 접두사와 접미사의 최대 일치 부분을 알아야 하고, 이를 위해서 다음과 같은 과정이 필요하다.
📌 Failure Function
KMP 알고리즘에서 탐색 문자열의 접두사와 접미사의 일치 부분을 계산하여 배열의 형태로 저장하는 함수이다. 다양한 이름으로 부르지만 본 글에서는 실패 함수(failure function)이라 한다. 실패 함수를 구하는 과정은 다음과 같다.
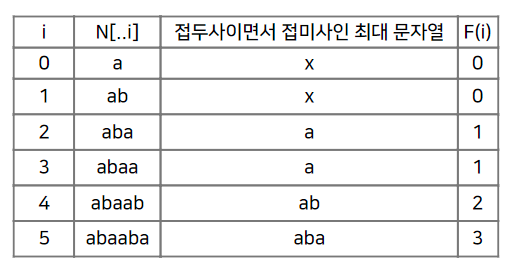
비교된 탐색 문자열의 부분 중, 접두사이면서 접미사인 최대 문자열을 구하여 배열의 형태로 저장한다.
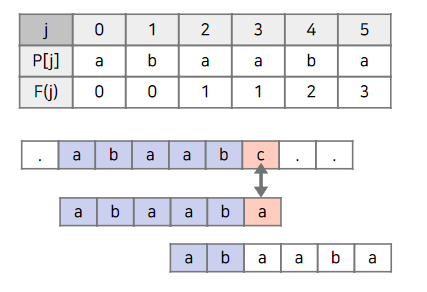
실패 함수를 통해 계산된 배열은 다음과 같다. 계산된 배열을 참고하여 탐색 문자열을 이동시킨다. 불일치가 발생한 index가 j라면, 다음 비교를 위해 탐색 문자열의 위치를 F(j-1) index에 위치한다.
Failure function 코드 예시
void FailureFunction(string pattern)
{
F[0] = 0;
int i = 1;
int j = 0;
while (i < pattern.size())
{
if (pattern[i] == pattern[j])
{
F[i] = j + 1;
i++;
j++;
}
else if (j > 0)
j = F[j - 1];
else
{
F[j] = 0;
i++;
}
}
}실패함수의 형태는 KMP 알고리즘의 형태와 크게 다르지 않다. 실패함수의 코드를 보면 반복문에서 i index가 1씩 증가하고, i - j의 값은 최소 1씩 증가한다. 따라서 반복이 최악의 경우에도 탐색 문자열의 크기의 두 배를 넘지 않기 때문에 실패함수의 수행시간은 O(M)에 수렴한다고 본다.
실패함수의 시간 복잡도 : O(M)
📌 KMP Algorithm 분석
KMP 알고리즘 코드 예시
int KMPmatch(string text, string pattern)
{
int n = text.size();
int m = pattern.size();
FailureFunction(pattern);
int i = 0;
int j = 0;
while (i < n)
{
if (text[i] == pattern[j])
if (j == m - 1)
return i - j;
else
{
i++;
j++;
}
else
{
if (j > 0)
j = f[j - 1];
else
i++;
}
}
return -1;
}KMP 알고리즘 코드 반복문에서 i는 1씩 증가하며, i - j 의 값은 최소 1씩 증가한다. 따라서 반복이 문자열의 크기의 두 배를 넘지 않기 때문에 KMP 알고리즘의 수행시간은 실패함수의 수행시간을 더한 O(N+M)에 수렴한다고 본다.
KMP 알고리즘의 시간 복잡도 : O(N+M)
📌 마무리
오늘은 문자열 탐색 알고리즘 중에서 성능이 우수한 KMP 알고리즘에 대해서 자세히 알아보았습니다. KMP 알고리즘은 문자열 탐색 부분에 있어서 거의 최고의 성능을 자랑하기 때문에 코딩테스트에서도 많이 등장하고, 다른 문자열 탐색 알고리즘을 공부하는 데 있어서도 중요한 부분입니다. KMP 알고리즘에 대해 처음 접하시는 분이라면 본 글이 도움이 되었으면 좋겠습니다.

KMP 알고리즘에 대해 잘 배워갑니다
-고리대금업자가 꿈인 대학생