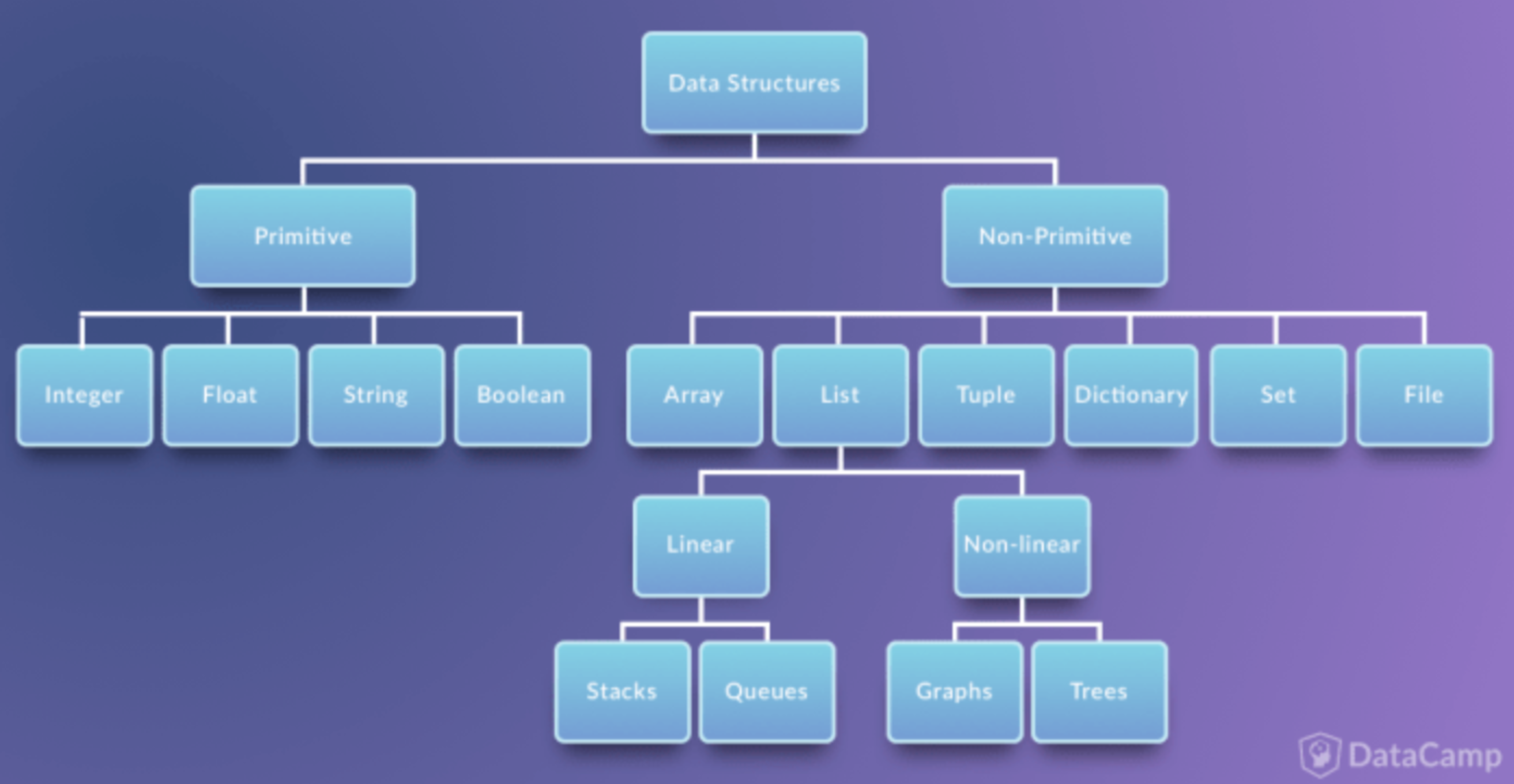
Data Structure
자료구조를 왜 써야 하는가?
토르발즈 왈 : 프로그램은 자료구조와 알고리즘
1. Primitive 단순구조
Number
String
Intager
Float
2. Non-Primitive 비단순구조
Array & List
- Big O(N)
- 순서가 있는 자료형
- 왜 순서가 있는가 ?
- 물리적(메모리에저장할때)으로 실제로 첫번째 데이터 바로 옆으로 순서 있게 저장이 되기 때문에
- 인덱싱이 가능
- 다차원적 사용 가능
- 사용처 : 댓글, 이미지 배열,
- 장점 : 순서가 있어 인덱싱이 가능. 인덱싱이 되기 때문에 자료를 빨리 불러들일 수 있다.
- 단점
- 물리적으로 바로 옆자리에 저장해야 하기 때문에 배열이 사용할 크기가 기본 값이 있다. 용량 초과 시 재할당(Array Resizing) 해야한다. 즉, 사이즈가 예측이 안되는 데이터는 배열과 안맞앙!
- 중간 인덱스를 삭제를 할 때 문제가 발생, 중간을 삭제하면 중간 빈 데이터가 생기기 때문에 삭제한 후 배열을 다시 붙여줘야 하는 귀찮음이 있다. 즉 삭제할 일이 많은 데이터는 배열로 하는 것은 비싼작업이다.
Stack
- First in Last out
- 함수를 호출할때 stack에다 저장되어 나중에 호출된 함수 먼저 실행되도록 한다
- stack overFlow ? : 담을수 있는 stack의 공간 보다 함수의 양이 더 많을때. 즉, 무한루프
Queue
- 순서대로 진행 First in First out
- 줄선대로 밥먹는다 > 맛집 예약 시스템
Priority Queue
- 우선순위가 있는 큐!
- 긴급 상황 먼저 큐 최근 순위로 올라선다.
- OS 프로세스 스케쥴링 시스템
Tree
binary tree
- Big O(log N)
- 탐색 속도 빠르게 하기 위해 2진트리 사용한다.
- 정렬이된 숫자를 저장하면 의미가 없다(== 그냥 리스트로 출력된다) 정렬이 안된 상태에서 해야 한다.
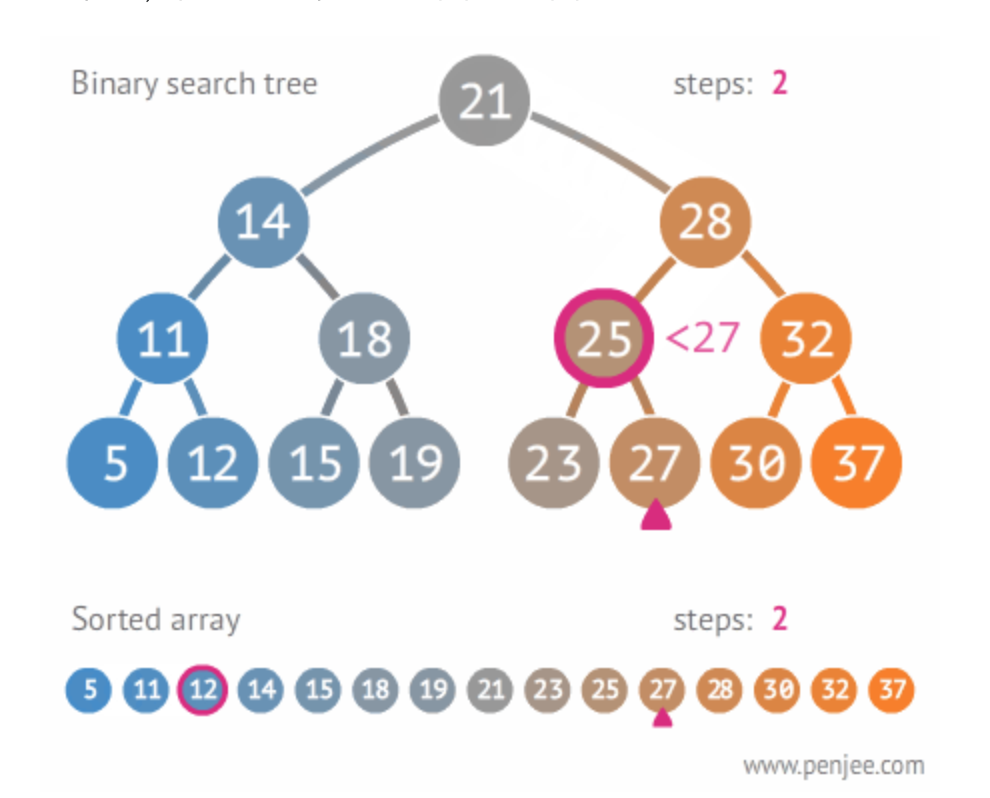
- 탐색 속도로만 따지면 set가 더 빠른대 2진 트리를 사용하는 이유는 뭘까 ? 트리에는 어느정도 순서가 있다.
- 작은 값은 왼쪽 큰 값은 오른쪽으로 정렬
Linked List
...
Tuple
- 간단한 데이터, 목적이 명확하지 않은 데이터이다.(e.g. 좌표 [(1,2),(3,4)]에서 X좌표가 뭔지 알수 없다)
- 배열구조와 비슷하지만 보통 2~5개 사이의 적은 요소를 저장 목적으로 사용한다.
- 수정이 불가능하며 이 때문에 속도가 아주 빠르다.
- 언어마다 없는 곳이 있는 대, 리스트나 클래스로 대체 가능 하기 때문에 없는 언어가 있다.
- 사용하는 대표 언어 : 파이썬
Set
- Big O(1)
- 순열자료구조? 리스트와 가장 큰 차이는 set는 순서가 없다.
- 하지만 set도 array의 한 종류...ㅋ
- 중복된 값을 허용하지 않음.
- 인덱스로 저장되지 않고 Hash에 저장된다. 같은 값으 해쉬는 동일 하기 때문에, 기존있던 자료를 치환해버린다(덮어쓰기)
- 해쉬로 저장될때 해쉬충돌이 발생하게 되는대 이는 해쉬를 정할때 나누기 나머지 값으로 하기 때문이대 이때문에 해쉬충돌을 없도록 하는 것이 좋은 알고리즘이다.
- 해취충돌이 없애기 위해서는 ? 메모리를 크게 잡으면된다! 그럼 어느정도 메모리가 탓을때 리사이징을 하는가 ? 대략 70% 찻을때 !
- e.g ) 중복전화번호를 제거해야 한다. array로 한담 2차 for loop 중복확인하고 다른 array에 담아야 한다. 하지만 set으로 하면 set에 담기만 해도 중복이 제거 된다.
Dictionary & Object
- 언제쓰죠? json 과 같이 자료에 대한 설명이 필요할때!
- 해쉬테이블
- 키 중복이 되지 않는다.
File
...
클래스생성자 & 기본메서드 변경하기가능
- 내가 만든 새로운 Object의 상송받는 기본 메서드 로직을 새로 작성하면 덮어쓰기, 나의 클래스 생성자로 나온 object에서 사용하는 변경된 기본 메서드는 내가 정의한 로직대로 값을 리턴한다.

TIL 기록 블로그 :: 문제가 있는 글엔 댓글 부탁드려요!