머신러닝은 데이터 전처리, 모델 학습/예측, 평가의 과정으로 구성된다.
머신러닝 모델은 여러 가지 방법으로 성능을 평가할 수 있다. 성능 평가 지표는 분류 모델과 회귀 모델에 따라 여러 종류로 나뉜다.
회귀 모델의 경우, 대부분 실제값과 예측값의 오차 평균값을 사용한다. 예를 들어 오차에 절댓값을 씌우고 평균 오차를 구하거나 오차의 제곱값에 루트를 씌운 뒤 평균 오차를 구하는 방법과 같이 기본적으로 예측 오차를 가지고 성능 평가 지표를 작성한다.
분류 모델의 경우, 실제 데이터와 예측 결과가 얼마나 정확하고 오류가 적게 발생하는가에 기반한다. 단순히 정확도만 가지고 판단하게 된다면 잘못된 평가 결과를 도출할 수 있다.
정확도(Accuracy)
정확도는 직관적으로 모델 성능을 나타내는 지표다. 하지만 이진 분류의 경우 데이터의 구성에 따라 모델의 성능을 왜곡할 가능성이 존재하기 때문에 정확도 수치 하나만 가지고 성능을 평가하지 않는다.
그렇다면 정확도 지표는 어떻게 모델의 성능을 왜곡할까?
예를 들어, 타이타닉 데이터를 예로 들면, 성별이 남자인 경우보다 여자인 경우가 생존 확률이 높았기 때문에, 남자는 사망, 여자는 생존으로 예측해도 높은 정확도가 나올 수 있다. 이렇게 된다면 해당 모델은 성별 데이터로만 사망, 생존을 구분하는 모델이 되는 것이다.
정확도는 불균형한 레이블 분포를 갖는 데이터에서 머신러닝 모델의 성능을 평가할 경우, 적합한 평가 지표가 될 수 없다.
예를 들어 100개의 데이터가 존재하는데 90개 데이터 레이블이 1, 10개의 데이터 레이블이 0이라고 한다면, 모든 데이터를 1로만 예측해도 90%의 정확도를 갖는 모델이 된다.
이처럼 불균형 레이블을 갖는 데이터에서는 정확도를 성능 평가에 사용을 하지 않고 이를 해결하기 위해 오차행렬이 등장했다.
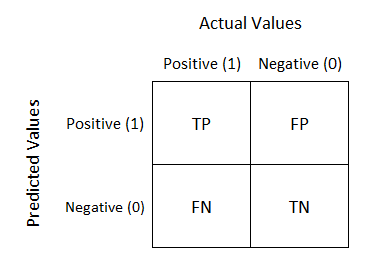
오차행렬(Confusion Matrix)
분류 모델이 예측을 수행하면 해당 모델이 얼마나 헷갈리고 있는지 함께 보여주는 지표다. 즉, 이진 분류의 예측 오류가 얼마인지, 어떤 유형의 오류가 발생하고 있는지 함께 나타낸다.
행렬의 열은 예측 클래스 값 기준으로 Negative, Positive로 구분하고, 행렬의 행은 실제 클래스 값 기준으로 Negative, Positive로 구분한다.
그렇게 유형에 따라 행렬의 4분면을 TP, FN, FP, TN로 구성한다.
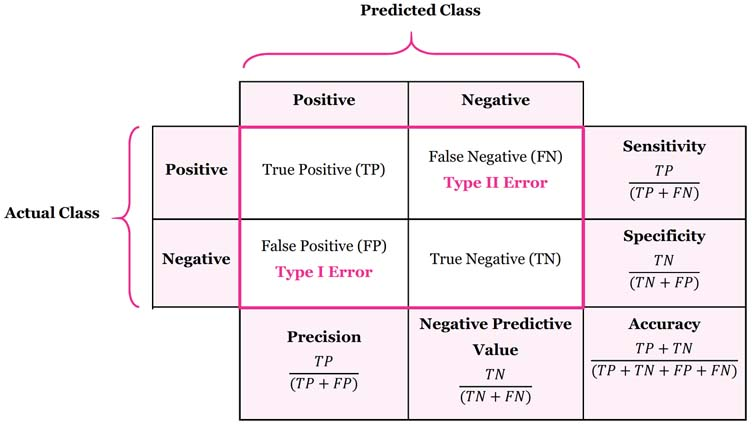
- TP : 예측 값을 positive로 예측, 실제 값 또한 positive
- FN : 예측 값을 negative로 예측, 실제 값은 positive
- FP : 예측 값을 positive로 예측, 실제 값은 negative
- TN : 예측 값을 negative로 예측, 실제 값 또한 negative
-> 뒤의 값으로 예측을 했는데 앞의 결과가 나옴
정밀도(Precision)와 재현율(Recall)
정밀도(Precision)는 positive로 예측한 데이터 중, 실제 값이 positive로 일치한 데이터의 비율이다. positive 예측 성능을 측정하기 위한 평가 지표로 양성 예측도라고도 불린다.
재현율(Recall)은 실제 값이 positive인 데이터 중, 예측 값이 positive로 일치한 데이터의 비율이다. 민감도(Sensitivity) 혹은 TPR(True Positive Rate)라고도 불린다.
재현율이 중요한 지표가 되는 경우는 실제 positive 데이터를 잘못 판단하게 되면 큰 문제가 발생하는 경우다. 예를 들어 암 환자를 음성으로 잘못 판단하게 되면 암을 알지 못한 채 살아갈 것이기 때문이다.
보통 재현율이 중요한 경우가 많지만, 정밀도가 중요한 지표가 되는 경우는 실제 negative 데이터를 잘못 판단하게 되면 큰 문제가 발생하는 경우다. 예를 들어 회사 중요 메일을 스팸 메일로 잘못 분류하게 되면 업무 상에 큰 차질이 생길 수 있다.
재현율과 정밀도는 서로 상호보완적이다. 그렇기에 재현율 혹은 정밀도가 어느 수준 이상 높아지게 되면 높아지면 다른 수치는 떨어진다. 가장 좋은 성능 평가는 재현율과 정밀도 모두 높은 수치를 얻는 것이다. 반면에 둘 중 하나의 평가 지표만 높고 다른 평가 지표는 매우 낮은 결과를 나타내는 경우를 바람직하지 않다.
F1-Score
정밀도와 재현율을 결합한 지표이다. F1-Score는 정밀도와 재현율 어느 한 쪽으로 값이 치우치지 않을 때 높은 값을 가진다.
ROC(Receiver Operation Characteristic) 곡선과 AUC
이진 분류의 성능 측정에서 중요하게 사용되는 지표다.
ROC 곡선은 수신자 판단 곡선으로 불리고, FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지 나타내는 곡선이다. TPR은 앞서 말한 것처럼 재현율을 의미한다. 그리고, 민감도에 대응하는 지표로 TNR(True Negative Rate)이라고 하는 특이성(Specificity)이 있다.
