
📌 Graph Convolutional Neural Networks for Web-Scale Recommender Systems
📖 ABSTRACT
본 논문은 Pinterest에서 개발 및 배포한 대규모 딥 추천 엔진을 설명한다.
PinSage의 저자는 GraphSAGE 저자와 같으며, 해당 모델은 GraphSAGE를 개선한다.
모델 PinSage는 Random walks와 graph convolution을 결합하여 그래프 구조와
노드 특징 정보를 모두 포함하는 노드의 임베딩을 생성한다.
저자는 해당 모델이 GCN을 기반으로 한 웹 규모 추천 시스템의 최대 규모 응용 사례라고 소개한다.
논문을 읽으면서 계속해서 언급되는 pin과 board를 직관적으로 이해하기 위해서는 pinterest 사이트를 방문해보길 권한다.
📖 INTRODUCTION
GCN 기반 방법이 다양한 추천 시스템 벤치마크에서 새로운 기준을 세웠지만,
실제 생산 환경에서의 성과로 진화되지 못하는 이유는 GCN 기반 노드 임베딩의 훈련 및 추론을 수십억 개의 노드와 수십 억 개의 엣지를 가진 그래프에 확장해야하기 때문이다.
이를 해결하기 위해 본 연구에서는 Pinterest에서 개발하고 운영 중인 고도로 확장 가능한 GCN 프레임워크를 제시한다.
PinSage라 부르는 해당 프레임워크는 Random Walks 기반 GCN으로,
30억 개의 노드와 180억 개의 엣지로 이루어진 거대한 그래프에서 작동한다.
PinSage는 GCN의 확장성을 향상시키기 위해 다음의 방법을 활용한다.
-
기존 GCN 알고리즘은 전체 그래프 Laplacian의 거듭제곱을 사용하여 그래프 컨볼루션을 수행한 반면, PinSage 알고리즘은 노드 주변의 이웃을 샘플링하고 이를 동적으로 구성하여 효율적이고 지역화된 컨볼루션을 수행한다.
- 기존 GCN 알고리즘의 Laplacian 거듭제곱은 Semi-Supervised Classification with Graph Convolutional Networks 리뷰를 통해 참고할 수 있다.
-
학습 중에 GPU를 최대한 활용하기 위해 큰 메모리를 사용하는 CPU-bound(Producer)가 노드의 네트워크 이웃을 샘플링과 필요한 특성을 가져오면 GPU-bound TensorFlow 모델(Condumer)이 확률적 경사 하강을 실행하게하는 Producer-Consumer minibatch 구조를 개발했다.
-
훈련된 GCN 모델을 사용하여 수십억 노드에 대한 임베딩을 생성하는 효율적인 MapReduce 파이프라인을 설계함으로써 반복 계산을 최소화한다.
PinSage는 학습한 표현의 품질을 향상시키 위해 다음의 방법을 활용한다.
- Random Walks를 통한 컨볼루션 구성 : 전체 노드 이웃에 컨볼루션을 수행하면 계산 그래프가 매우 커질 수 있기 때문에 랜덤 워크를 활용한 계산 그래프를 샘플링한다.
- 중요도/풀링 : Random Walks 유사성 측정에 기반한 노드 특성의 중요도를 가중치로 적용하는 방법을 사용한다.
- 커리큘럼 트레이닝 : 훈련 중에 더 어려운 예제를 알고리즘에 제공하는 커리큘럼 트레이닝 체계를 설계한다.
종합적인 오프라인 메트릭, 통제된 사용자 연구 및 A/B 테스트를 통해 해당 방식이 다른 확장 가능한 딥 콘텐츠 기반 추천 알고리즘과 비교하여 sota 성능을 보인다고 한다.
📖 METHOD
Problem Setup
Pinterest의 task는 추천 시스템에서 사용할 핀의 고품질 임베딩을 생성하는 것이다.
본래는 Pinterest 환경을 pin 및 board 두 가지 상호 배타적인 집합으로 구성된 이분 그래프로 모델링한다.
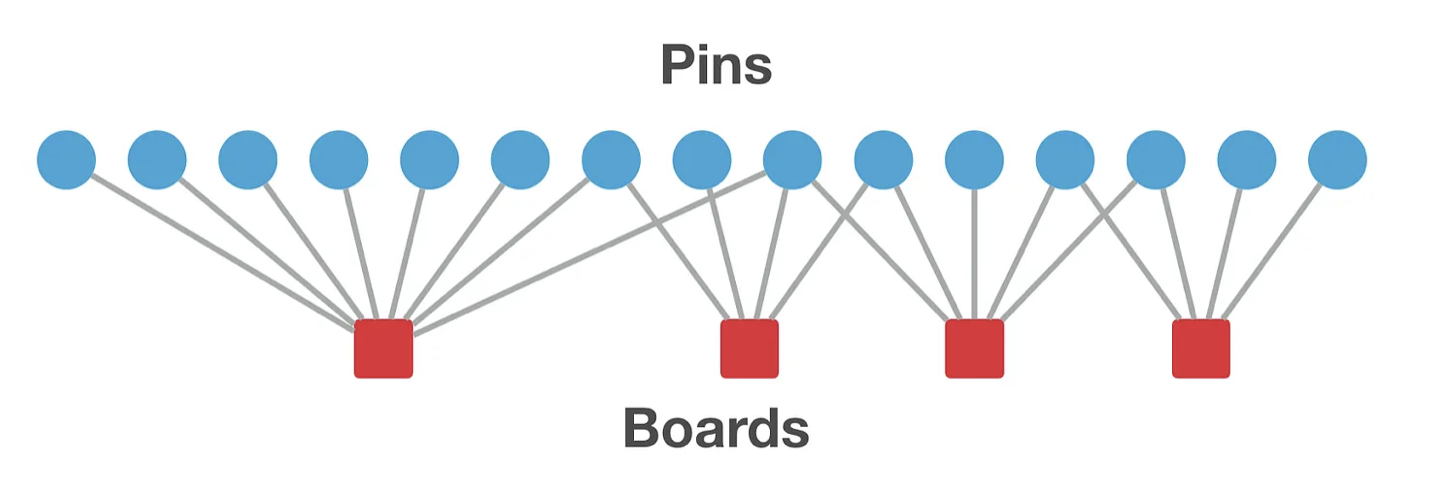
하지만 표기 편의 및 일반성을 위해 PinSage 알고리즘을 설명할 때 저자는 단순히 전체 그래프의 노드 집합을 pin과 board 각 집합을 합하여 참조하며, 필요한 경우를 제외하고는 둘을 명시적으로 구별하지 않는다.
📖 Model Architecture
이번 섹션에서는 위의 그래프를 기반으로 한 순전파와 mini-batch를 직관적으로 보이기 위해 그림을 함께 제공한다.
Forward propagation algorithm

위의 알고리즘을 한 줄씩 설명하면 다음과 같다.
- 노드 이웃의 임베딩 를 dense neural network를 통해 변환한 후 결과 벡터 집합에 대해 집계/풀링 함수(요소별 평균 또는 가중합으로 표시되는 )를 적용한다.
이를 통해 노드 의 지역 이웃 집합 의 벡터 표현 이 만들어진다. - 집계된 이웃 벡터 를 노드 의 현재 벡터 표현 와 연결하고, 연결된 벡터를 또 다른 dense neural network layer를 통해 변환한다.
*저자는 평균보다 연결이 성능 향상을 보였다 말한다. - 마지막으로 정규화를 통해 훈련을 더 안정적으로 만든다.
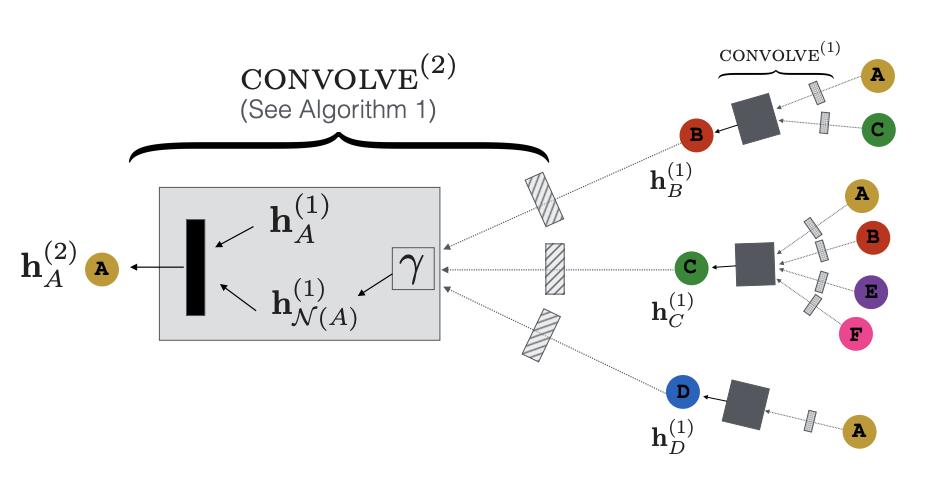
위의 그림은 순전파 알고리즘을 직관적으로 이해하는데 도움을 준다.
Importance-based neighborhoods
기존의 GCN은 단순히 k-hop 그래프 이웃을 검토했다면, Pinsage는 중요도 기반으로 이웃을 정의한다.
PinSage는 노드 의 이웃을 노드 에 가장 큰 영향을 미치는 개의 노드로 정의하며, 다음의 과정을 통해 이웃 노드가 결정된다.
- 노드 에서 시작하는 랜덤 워크를 시뮬레이션하고,
랜덤 워크에 의해 방문된 노드의 정규화된 방문 횟수를 계산한다. - 노드 의 이웃은 1번 과정을 통해 가장 높은 정규화된 방문 횟수를 가진 상위 개의 노드로 정의된다.
이를 통한 이점으로 저자는 두가지를 말한다.
- 일정 수의 노드를 선택하여 집계하는 것은 훈련 중 알고리즘의 메모리가 차지하는 공간을 제어할 수 있게 한다.
- 순전파 알고리즘에서 이웃의 벡터 표현을 집계할 때 이웃의 중요성을 고려할 수 있게 하며, 이때 가중치는 정규화된 방문 횟수로 정의된다.
Stacking convolutions
컨볼루션 연산을 적용할 때마다 노드에 대한 새로운 표현이 생성되며,
노드 의 더 많은 지역 그래프 구조 정보를 얻기 위해 컨볼루션을 여러 번 쌓을 수 있다.
주의할 점은 아래의 그림과 같이 순전파 알고리즘의 매개변수는 노드간에 공유되지만 레이어 간에는 다르다.


위의 알고리즘은 stacking convolutions을 사용하여 미니배치 노드 세트에 대한 임베딩을 생성하는 방법을 설명하며 요약하면 다음과 같다.
- 각 노드의 이웃을 계산한다.
- target node의 layer- 표현을 생성하기 위해 회의 컨볼루션을 적용한다.
- 최종 컨볼루션 레이어의 출력은 fully connected 신경망을 통과하여 각 노드의 최종 출력 임베딩을 생성한다.
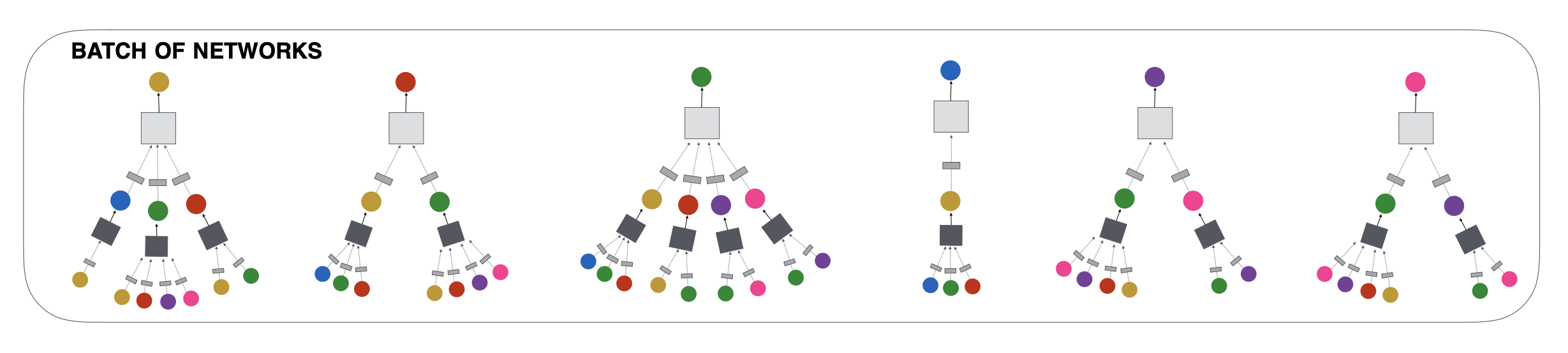
위의 그림은 미니배치에 해당하는 각각의 노드들이 위에서 소개한 알고리즘이 적용되어 최종 벡터 표현을 형성하는 과정을 직관적으로 보여준다.
Stacking convolution절의 초반에 언급했듯이 각 컨볼루션 레이어는 다음과 같은 별개의 매개변수를 갖는다.
추가로 최종 dense neural network layer는 매개변수 , 를 갖는다.
📖 Model Training
Loss function
모델의 매개변수를 훈련시키기 위해 사용되는 손실 함수는 최대 마진 기법이다.
기본 아이디어는 쿼리 아이템 임베딩과 관련 아이템 임베딩간의 내적을 최대화하는 것이며, 동시에 관련 없는 아이템 임베딩과의 내적은 미리 정의된 마진보다 작아지도록 한다.
단일 노드 임베딩 쌍()에 대한 손실 함수는 다음과 같다.
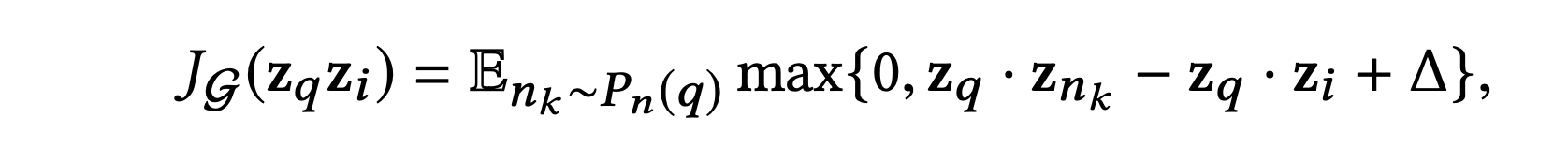
여기서 는 항목 q에 대한 negative examples의 분포를 나타내며, 는 마진 초모수이다.
Multi-GPU training with large minibatches
하나의 머신에서 여러 GPU를 최대한 활용하여 훈련하기 위해 순전파 및 역전파를 다중 타워 방식으로 실행한다.
여러 GPU를 사용할 경우, 각 미니배치를 동등한 크기의 부분으로 나눈다.
각 GPU는 미니배치의 한 부분을 가져와 동일한 매개변수 집합을 사용하여 계산을 수행한다.
역전파 이후에는 각 매개변수에 대한 경사를 모든 GPU에서 집계하고 동기화된 SGD의 단일 단계가 수행된다.
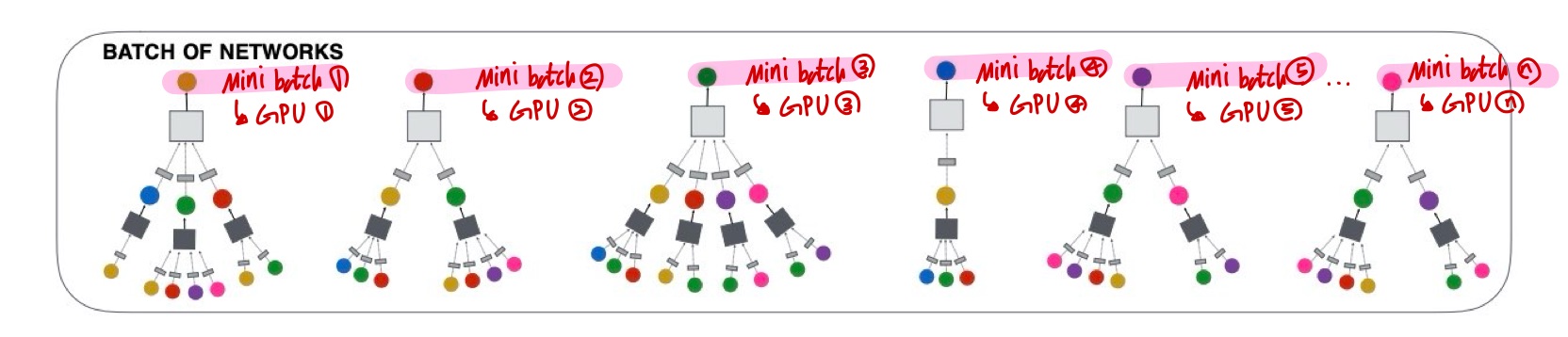
즉, 위의 그림에서 보이듯 타겟 노드 하나가 미니배치 하나를 의미하며, 각각의 GPU에 할당되어 순전파와 역전파가 계산된다.
수십억 단위의 매우 큰 예제 집합에서 훈련해야 하기 때문에 저자는 512에서 4096까지의 대형 배치 크기를 사용한다고 한다.
Producer-consumer minibatch construction
수십억 개 노드에 대한 adjacency list와 feature matrix의 크기가 크기 때문에 훈련 중에는 해당 정보가 CPU 메모리에 저장된다.
따라서 PinSage의 convolution 단계에서 각 GPU 프로세스는 이웃 노드 및 이웃의 특성 정보를 활용하기 위해 GPU에서 CPU 메모리로 데이터에 접근해야하지만, 이는 효율적이지 않다고 한다.
이 문제를 해결하기 위해 본 논문은 re-indexing 기술을 사용하여 현재 미니배치의 계산에 참여할 노드 및 이웃을 포함하는 하위 그래프 를 생성한다.
추가로 현재 미니배치의 계산과 관련된 노드 특성만을 포함하는 작은 feature matrix도 추출되며, 이는 의 노드 인덱스와 일관된 순서로 구성된다.
따라서 의 adjacency list와 작은 feature matrix은 각 미니배치 반복의 시작에서 GPU로 전송되므로 convolution 단계 중에 GPU와 CPU 간의 통신이 필요하지 않아 GPU 활용도가 크게 향상된다.
정리하면 순전파와 역전파는 GPU에서 이루어지며, 특성 추출, re-indexing 및 negative sampling은 CPU에서 계산된다.
Sampling negative items
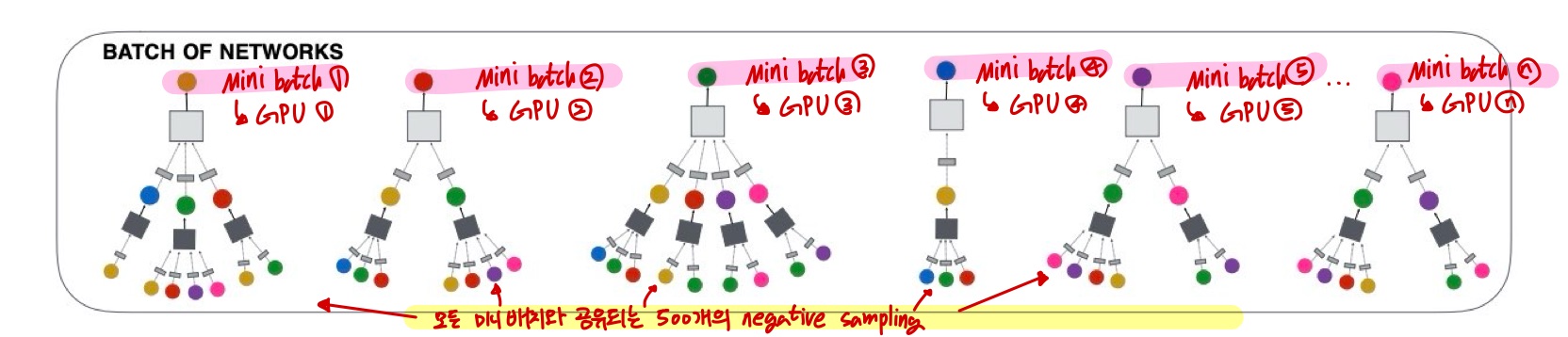
대규모 배치 크기로 훈련할 때 효율성을 향상시키기 위해 위의 그림과 같이 각 미니배치의 모든 훈련 예제에서 공유되는 500개의 negative samples 집합을 형성한다.
이렇게 함으로써 각 훈련 단계에서 계산해야 하는 임베딩의 수를 크게 줄일 수 있다.
해당 방법은 각 노드에 대해 독립적으로 부정 샘플링을 실행하는 것과 비교하여 계산량을 크게 절약한다고 한다.
하지만 neagtive sampling을 하더라도 모델의 성능을 높이는데에는 한계가 있다.
가장 간단한 경우를 살펴봤을 때 전체 항목 집합에서 negative samples를 균등하게 샘플링하면 positive samples의 내적이 500개의 negative samples의 내적 크기보다 크도록 나오게 하는 것은 너무 쉽다는 것이다.
즉, 2억개의 항목 중 500개의 무작위 negative samples은 쿼리 항목과 약간이라고 관련이 있을 확률이 낮기 때문에 높은 확률로 학습을 통해 좋은 매개변수 업데이트를 수행하지 못하게 된다.

이러한 문제를 해결하기 위해 각 positive samples마다 "hard" negative samples, 즉 쿼리 항목 q와 관련이 있지만 positive samples만큼 관련이 없는 항목을 추가한다.
hrad negative samples는 Personalized PageRank 점수에 따라 항목을 순위 매겨 생성한다.
2000~5000까지 순위가 매겨진 항목 중에서 무작위로 hard negative samples 집합을 형성한다.
정리하면 hard negative samples를 통해 모델이 순위를 매기는 데 어려움을 겪게 만들어 모델이 더 정밀한 단계에서 항목을 구별하도록 한다는 것이다.
다만 훈련 절차 전반에 걸쳐 hard negative samples를 사용하면 훈련이 수렴하기 위해 필요한 epoch 수가 두 배로 증가한다.
이를 해결하기 위해 처음 epoch에서는 hard negative samples을 사용하지 않고 다음 단계의 epoch를 진행할 때마다 하나씩의 hard negative samples를 추가해주는 방식으로 훈련을 진행한다.
Node Embeddings via MapReduce
위에서 소개한 알고리즘은 서로 다른 대상 노드에 대한 임베딩을 생성할 때 다양한 레이어에서 많은 노드가 반복적으로 계산된다.
효율적인 추론을 보장하기 위해 중복된 계산 없이 모델 추론을 실행하는 MapReduce 접근 방식을 개발했다.
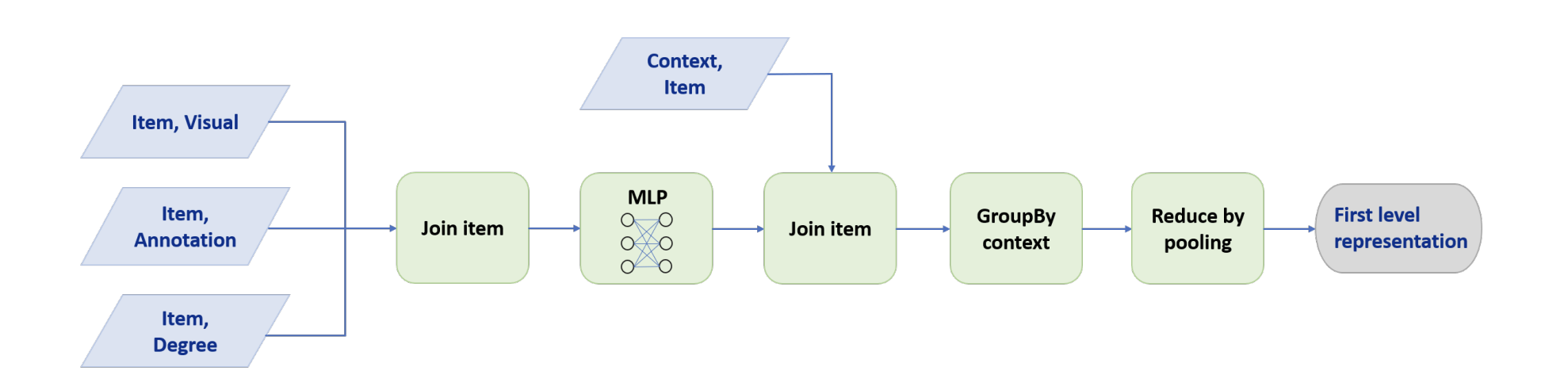
위의 그림은 pin-to-board Pinterest 그래프에서의 데이터 플로우를 자세히 나타낸다.
layer-0에서의 입력 노드는 pin/item이며, layer-1에서의 입력 노드는 board/context이다.
MapReduce 파이프라인은 두 가지 주요 부분으로 구성된다.
- 모든 pin을 낮은 차원의 잠재 공간으로 투영하고 집계 연산을 수행할 수 있는 임베딩을 생성하는 데 사용되는 MapReduce 작업이다.
처음 알고리즘에서 소개했던 대칭 벡터 함수 γ가 이에 해당한다. - 다른 MapReduce 작업은 결과 pin 표현을 해당 board의 ID와 결합하고, board의 임베딩은 이웃의 특성을 풀링하여 계산한다.
이를 통해 중복된 계산을 피하며 각 노드의 잠재 벡터는 한 번만 계산된다.
board의 임베딩이 얻어지면 두 개의 MapReduce 작업을 사용하여 pin의 두 번째 레이어의 임베딩을 계산하며, 이는 위에서 설명한 것과 유사하게 수행될 수 있다.
이 프로세스는 필요에 따라 반복될 수 있다.
📖 EXPERIMENTS
Experimental Setup
Features used for learning
Pinterest의 각 pin은 이미지와 텍스트 주석(제목, 설명) 세트와 관련되어 있다.
각 pin 에 대한 특징 표현 를 생성하기 위해 visual embedding(4,096 dimenstions), textual embedding(256 dimenstions), 그래프에서의 노드/pin의 log degree를 연결한다.
visual embedding은 VGG-16 아키텍처를 사용한 분류 네트워크의 6th fully connected layer에서 나온 것이다.
textual embedding은 Word2Vec 기반 모델을 사용하여 훈련되었으며, 주석의 맥락은 각 pin에 연결된 다른 주석으로 구성된다.
Offline Evaluation
Hit-ratio & MRR
-
Hit-ratio는 추천 시스템에서 모델이 생성한 추천 목록 중 실제로 사용자가 선호하는 아이템이 몇 개나 포함되어 있는지를 나타내는 지표이다.
일반적인 사용자의 상위 몇 개의 추천 아이템 중 실제로 선호하는 아이템이 몇 개나 있는지의 비율료 표현된다. -
MRR(Mean Reciprocal Rank)를 나타내는 지표로, 모델이 생성한 추천 목록에서 실제로 사용자가 선호하는 아이템이 얼마나 높은 순위에 있는지를 평균화한 값이다.
MRR은 고려된 아이템이 상위 몇 번째에 위치하는지에 역수를 취한 값들의 평균을 계산한다.
즉, Hit-ratio는 목록에 얼마나 많은 선호 아이템이 있는지의 비율을 나타내고, MRR은 상위 몇 번째에 첫 번째 아이템이 위치하는지의 평균을 나타낸다.

- importance-pooling 집계 및 hard negative sampleings 사용한 Pinsage가 Hit-rate 67%와 0.59의 MRR로 최상의 성능을 보인다.
- 시각적 및 텍스트 정보를 결합하는 것이 각각 하나를 사용하는 것보다 효과적임을 보인다.
Probability density of pairwise cosine similarity for embedding
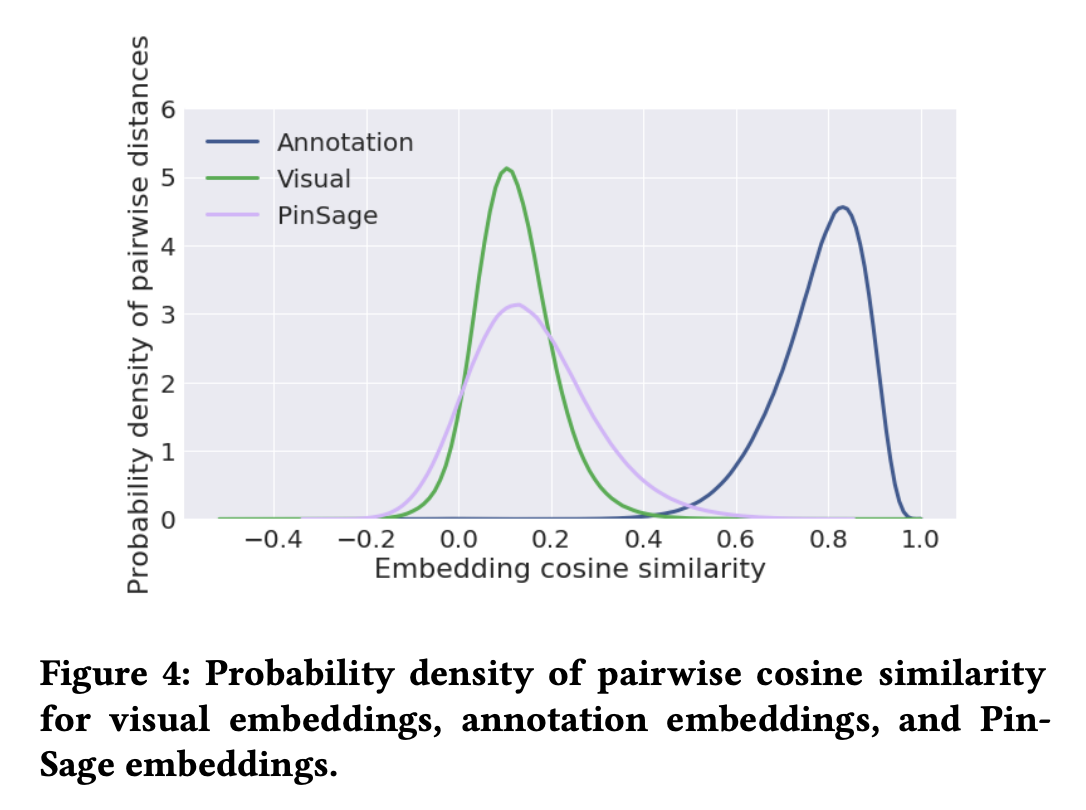
위의 그림은 각 임베딩의 항목 쌍 간의 코사인 유사도 분포를 그린것이다.
임의의 항목 임베딩 쌍 간의 거리가 넓게 분포되어 있는지의 여부를 통해 학습된 임베딩의 효과를 평가할 수 있다.
모든 항목이 거의 동일한 거리에 위치한다면 임베딩 공간은 서로 다른 중요도를 가진 항목을 구별하기에 충분한 해상도가 없음을 의미한다.
그림을 통해 PinSage embedding의 코사인 유사도가 가장 넓게 분포되어 있음을 알 수 있으며, 이는 가장 효과적인 방법임을 의미한다.
User Studies
사용자 연구에서는 사용자에게 쿼리 pin 이미지와 두 가지 다른 추천 알고리즘에 의해 검색된 두 pin이 제시된다.
사용자는 그 중 어느 알고리즘의 pin이 쿼리 pin과 더 관련이 있는지 선택하도록 요청을 받으며, 동등하다는 선택도 할 수 있는 상황에서 실험이 진행되었다.
다음의 표는 PinSage와 4가지 다른 방법론 간의 대조 결과를 나타낸다.

사용자가 더 관련이 있다고 생각하는 항목 중 약 60%가 PinSage에 의해 추천되었음을 알 수 있다.

위의 그림은 각각의 방법론을 통해 추천되는 pin 이미지의 예시를 보인다.
- visual embedding은 일반적으로 시각적 유사성을 잘 예측하지만 이미지 의미 측면에서 적절하지 않은 추천을 제시한다.
- Pixie 방법은 pin-board 관계의 그래프를 사용함으로써 쿼리의 범주가 "식물"임을 올바르게 이해하여 식물 범주 항목을 추천하지만 가장 관련 있는 항목을 찾지는 못한다.
- visual/textual and graph information를 결합한 PinSage는 시각적 및 주제적으로 쿼리 항목과 유사한 항목을 찾아냄을 보인다.

추가로 저자는 1000개의 항목을 무작위로 선택하여 PinSage 임베딩에서 2D t-SNE 좌표를 계산하여 임베딩 공간을 시각화한다.
위의 그림에서 표시된 것처럼 항목 임베딩의 근접성이 콘텐츠의 유사성과 잘 일치하며 동일한 범주의 항목이 동일한 부분에 임베딩됨을 관찰할 수 있다.
Training and Inference Runtime Analysis
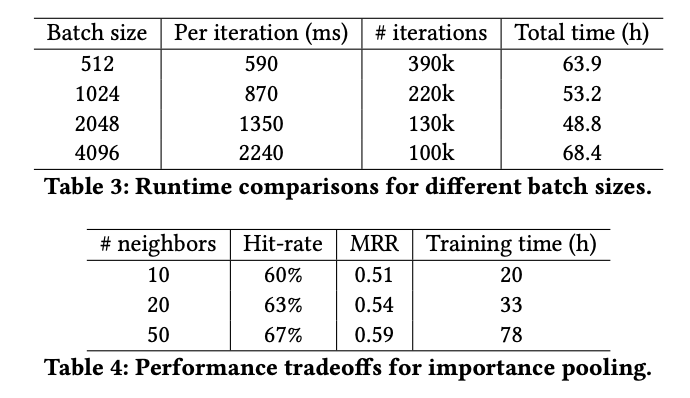
-
첫 번째 표는 PinSage 훈련 과정에서 미니배치 SGD의 배치 크기가 실행 시간에 미치는 영향을 보인다.
결과적으로배치 크기가 2048인 경우 훈련이 가장 효율적이라는 것을 알 수 있다. -
두 번째 표는 PinSage의 importance pooling으로 훈련할 때 이웃의 크기 와 훈련 시간간의 상충 관계를 보인다.
이웃 크기가 50인 두 층의 GCN이 노드의 이웃 정보를 가장 잘 캡쳐하면서 계산 효율적이라고 저자는 말한다.
📖 CONCLUSION
PinSage는 추천 도메인에서 딥러닝 모델을 사용하여 성공적인 성능을 보인 훌륭한 사례라고 생각한다.
논문으로 구현되는 모델들이 정제된 데이터셋에서 뿐만 아니라 실제 산업 환경에 적용될 수 있도록 이와 같은 다양한 시도들이 지속되면 좋겠다는 생각을 한다.
이후로도 실제 산업과 연관성이 짙은 논문들을 찾아보면서 적절하게 적용할 수 있도록 공부해야겠다.
Reference
Graph Convolutional Neural Networks for Web-Scale
Recommender Systems
[Paper Review] MulitSAGE part2 GraphSAGE
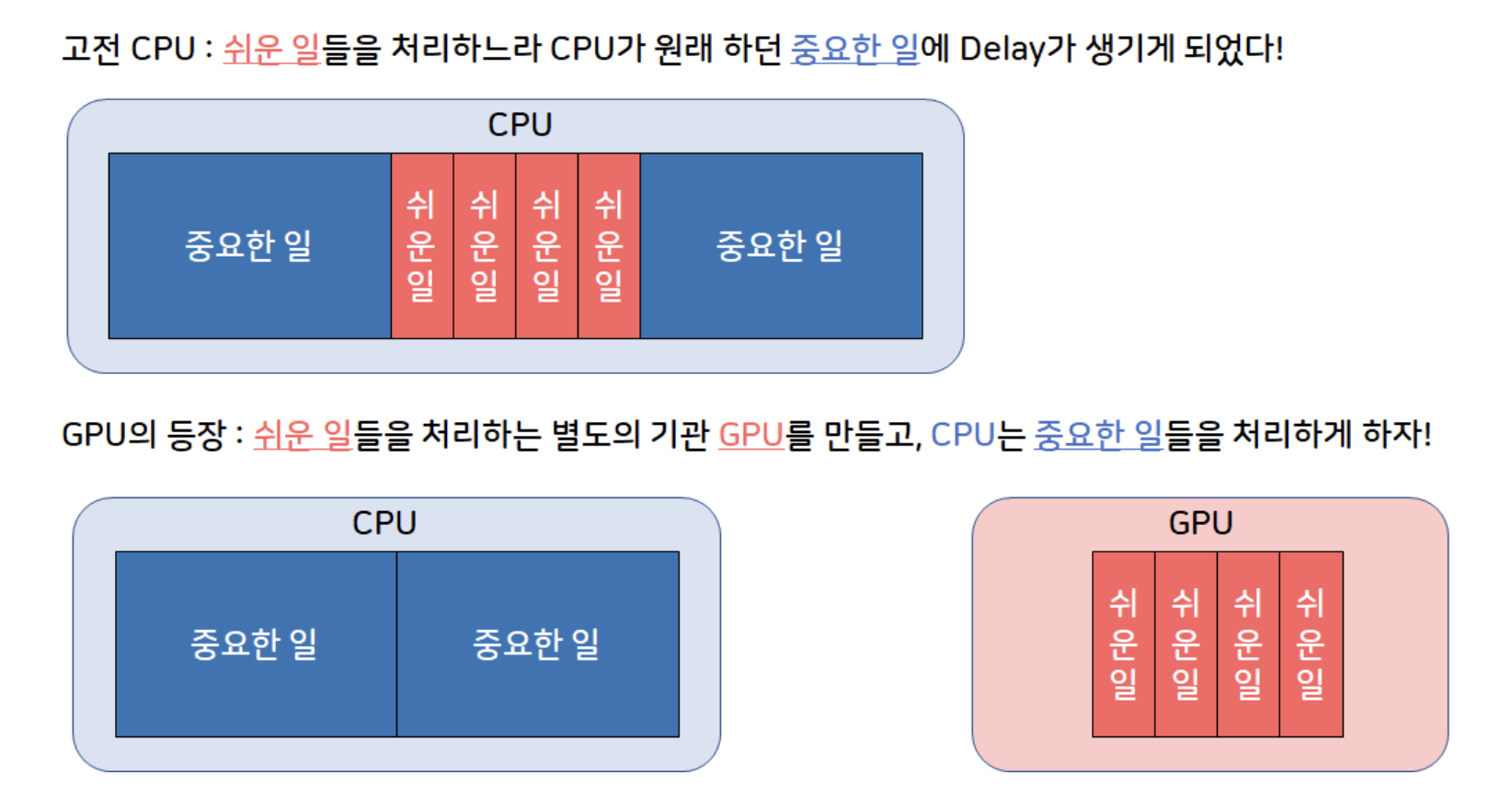
CPU와 GPU 차이
