[논문 리뷰] LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
Paper Review

📌 LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
📖 ABSTRACT
Graph Convolution Network(GCN)은 협업 필터링에서 새로운 sota 기술이 되었지만, 본래 graph classification task를 위해 설계되었기 때문에 추천 작업에 적용하기 위해서는 몇가지 추가 작업이 필요함을 주장한다.
본 연구는 GCN의 디자인을 간소화하여 추천에 더 간결하고 적절한 모델인 LightGCN을 제시함으로써 기존 GCN 기반 sota 추천 모델인 NGCF의 성능을 개선했음을 보인다.
📖 INTRODUCTION
NGCF는 GCN에 영감을 받아 high-hop 이웃과의 서브그래프 구조를 보다 심층적으로 활용함으로써 협업 필터링에 대한 sota를 달생했다.
하지만 본 연구는 NGCF가 GCN의 모든 것을 정당성 없이 상속했음을 주장한다.
NGCN에 대한 내용은 해당 링크에서 참고할 수 있으며 뒤에서도 간단하게 다룬다.
기존 GCN은 feature graph에서 node classification을 위해 제안되었으며,
feature graph에서의 각 노드는 풍부한 속성의 input features를 갖는다.

예를들어 위 그림의 소셜 네트워크에서의 사용자 프로필을 고려해볼 때, 각 사용자는 feautres graph의 노드이며 각 노드에는 해당 사용자에 대한 여러 특징(나이, 성별, 지역, 취미)이 포함될 수 있다.
반면 CF의 사용자-아이템 상호 작용 그래프에서 각 노드는 ID embedding일 뿐이며, 기존 GCN의 input features와 달리 추가적으로 의미를 갖는 input features가 존재하지 않기 때문에 feature transformation 그리고 nonlinear activation이 필없음을 말한다.
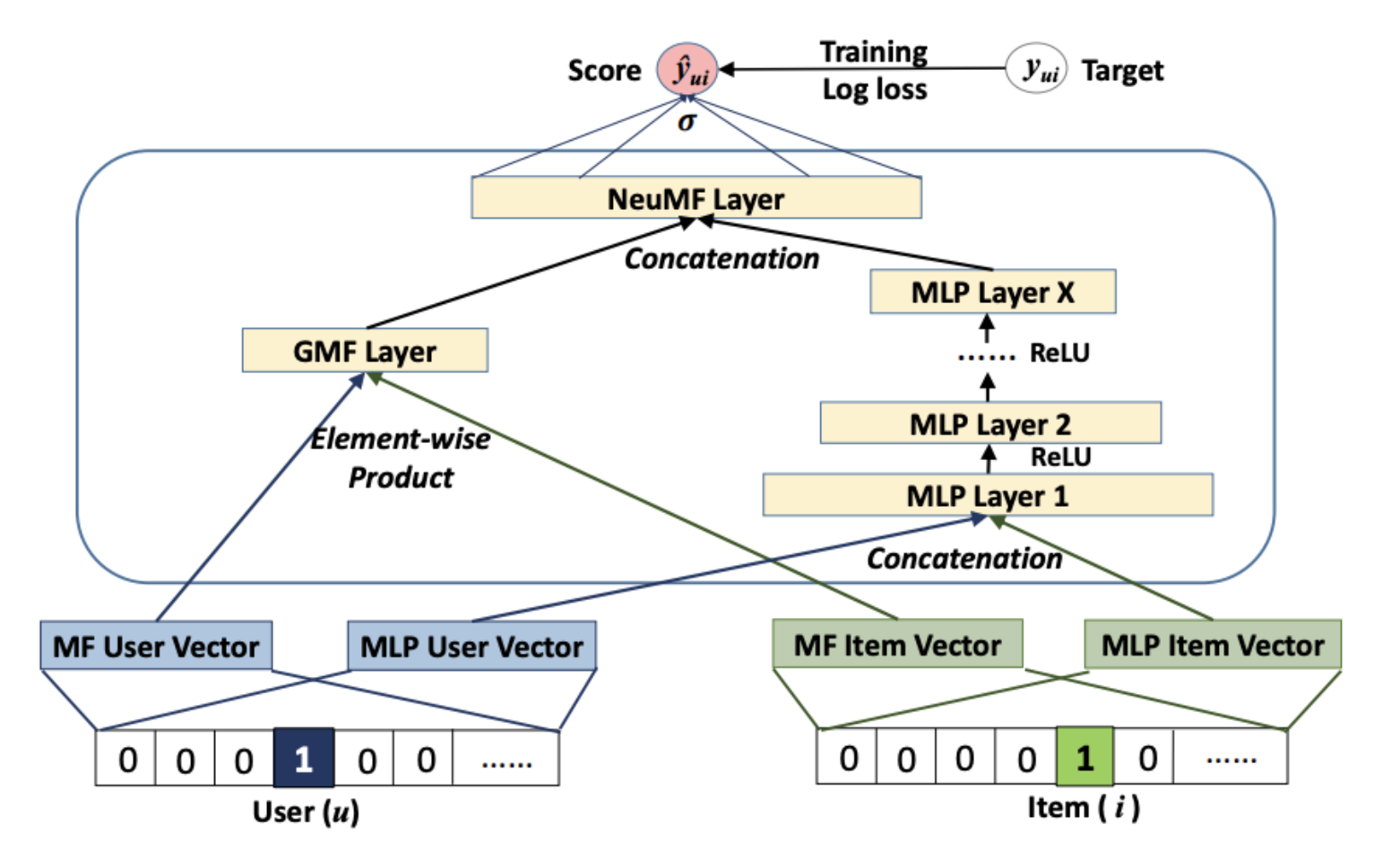
예를들어 위 그림의 NCF 모델 프레임워크의 node embedding은 단순히 one-hot embedding으로써 각 사용자와 아이템을 구별하는 용도 외의 의미는 지니지 않는다.
오히려 해당 연구는 실험을 통해 두 구성 요소가 추천 성능에 끼치는 부정적인 효과가 있음을 밝힘으로써 feature transformation와 nonlinear activation의 불필요함을 증명한다.
즉, GCN의 가장 기본적인 구성 요소 neighborhood aggregation만을 사용한 LightGCN이 NGCF의 성능을 개선했음을 입증한다.
계속해서 언급되는 feature transformation와 nonlinear activation이 명확히 어떤 과정을 나타내는지는 곧이어 수식을 통해 설명한다.
📖 PRELIMINARIES
NGCG Brief
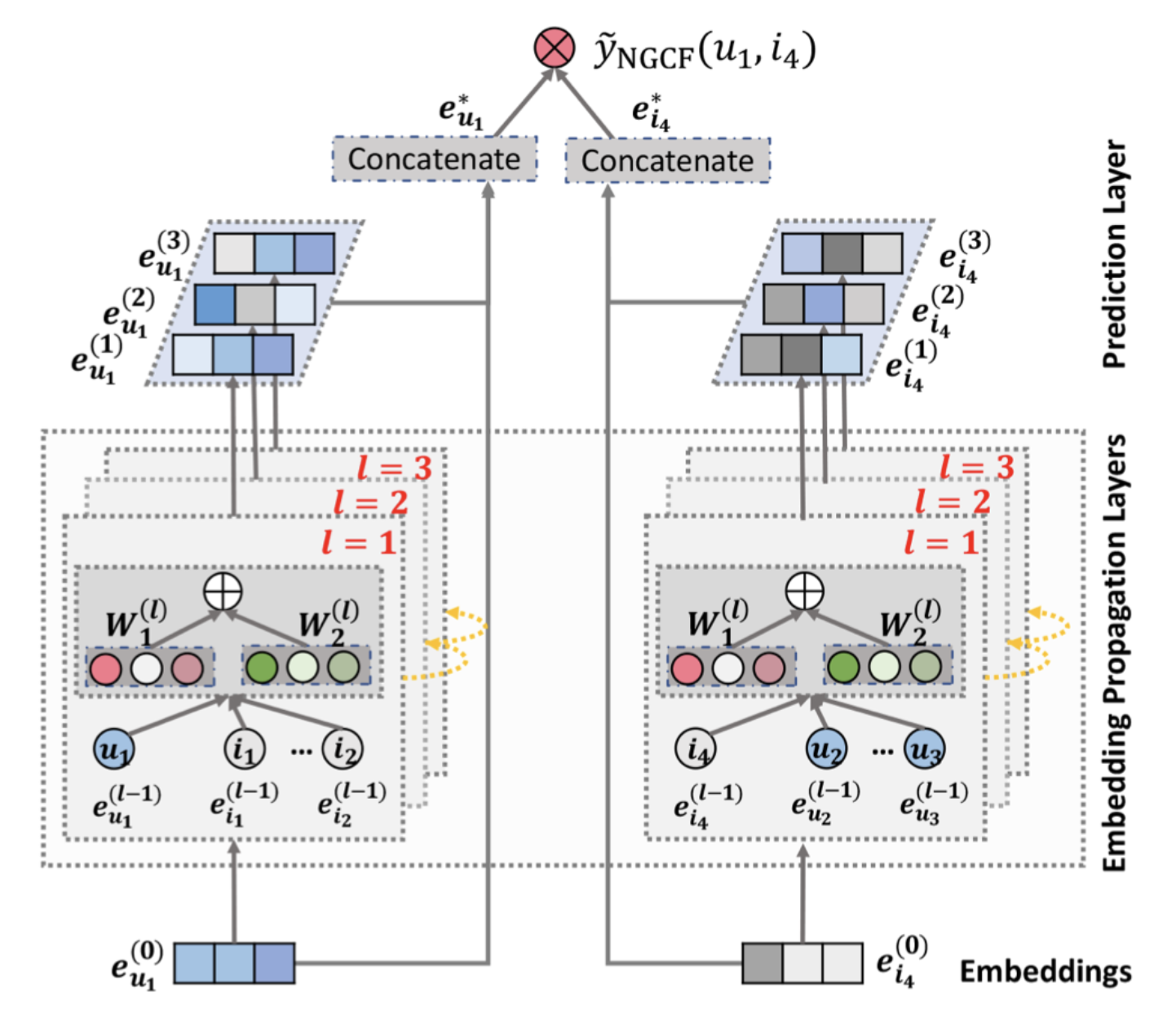
위 그림 각 층의 임베딩을 얻는 과정을 수식으로 표현하면 다음과 같다.
, : 각각 번째 레이어 전파 후 사용자 및 아이템 의 정제된 임베딩
: 비선형 활성화 함수
: 사용자 가 상호 작용하는 아이템의 집합
: 아이템 가 상호 작용하는 사용자의 집합
, : 각 레이어에서 특징 변환을 수행하기 위한 학습 가능한 가중치 행렬
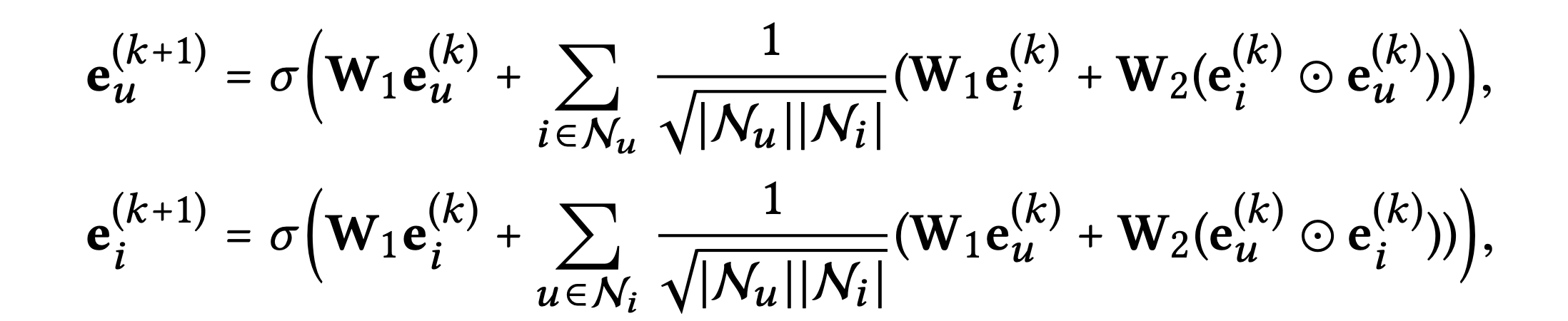
그림을 통해 알 수 있듯이 L 레이어를 전파함으로써 NGCF는
사용자 및 아이템 을 설명하는 + 1개의 임베딩을 얻는다.
그런 다음 + 1개의 임베딩을 연결하여 최종 사용자 임베딩 및 아이템 임베딩을 얻으며, 내적을 사용하여 예측 점수를 생성한다.
NGCF 수식에 포함된 nonlinear activation function 와 feature transformation matrix 와 가 위에서 언급한,
추천 작업을 위한 GCN에는 필요하지 않다고 주장하는 두 구성 요소이다.
Empirical Explorations on NGCF
해당 실험은 NGCF의 저자들이 공개한 코드를 사용하였으며, 동일한 데이터 분할 및 평가 프로토콜을 사용하여 진행했다.
추가로 GCN의 핵심은 전파를 통해 임베딩을 정제하는 것이기 때문에 기존의 최종 임베딩을 얻는 방식인 연결을 합계로 변경했으며, 이는 NGCF의 성능에 별다른 영향을 미치지 않음을 이야기한다.
저자는 NGCF의 세가지 변형을 구현했다.
- NGCF-f : 특징 변환 행렬 와 를 제거
- NGCF-n : 비선형 활성화 함수 를 제거
- NGCF-fn : 특징 변환 행렬과 비선형 활성화 함수 모두 제거
세가지 변형에 대해서는 모든 하이퍼파라미터(학습률, 정규화 계수, 드롭아웃 비율 등)을 NGCF의 최적 설정과 동일하게 유지했다고 한다.
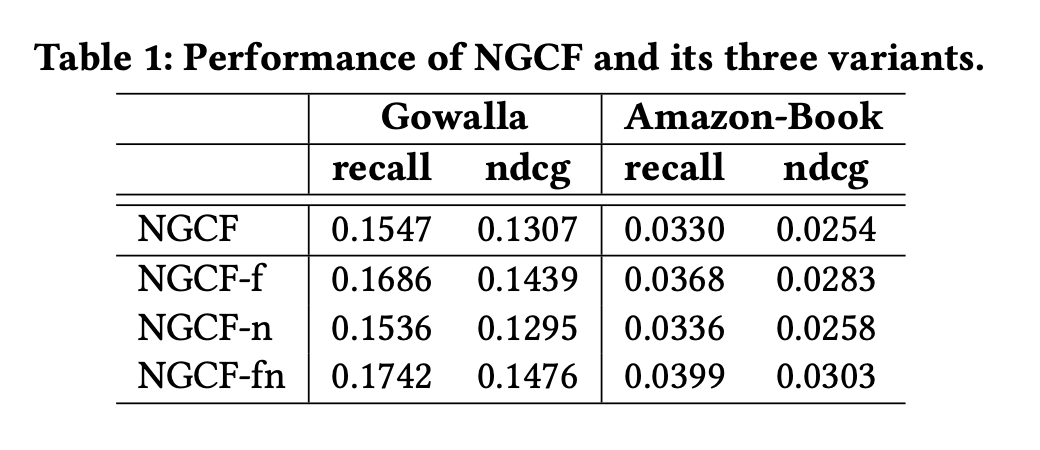
해당 표는 Gowalla 및 Amazon-Book 데이터셋에 대한 2-layer 설정의 결과를 나타내며 다음과 같은 결과를 보인다.
- 특징 변환을 제거하는 경우(NGCF-f) 모든 데이터셋에서 일관된 개선
- 비선형 활성화를 제거하는 경우(NGCF-n) 정확도에 그다지 큰 영향을 미치지 않음
- 모두를 제거하는 경우(NGCF-fn) 성능이 크게 향상
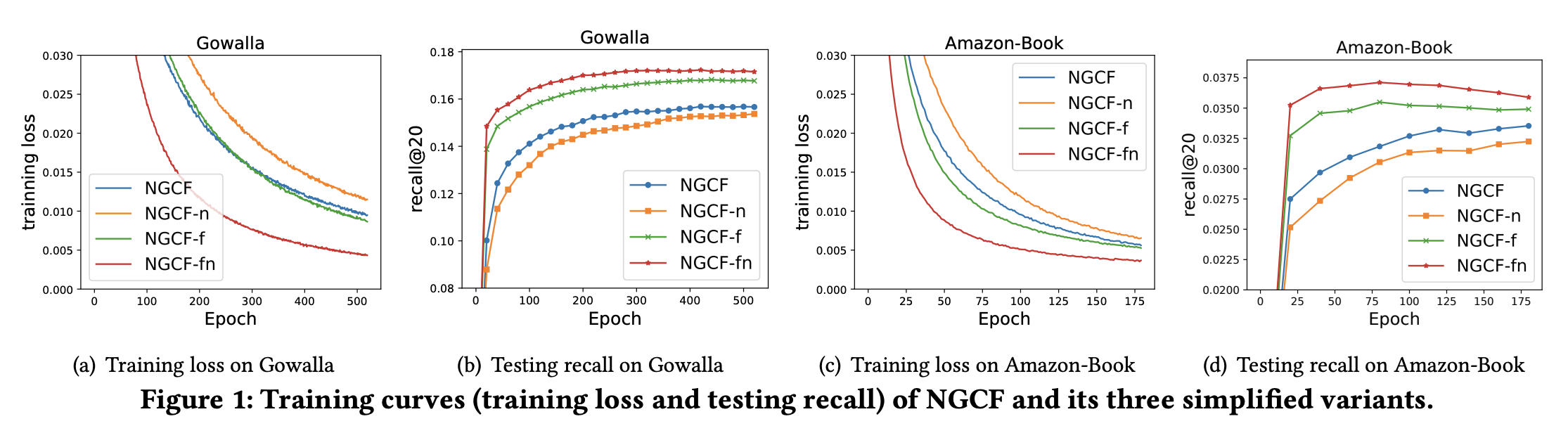
위 그림은 앞서 언급한 표에서의 훈련 손실과 테스트 recall의 기록이다.
그림을 통해 알 수 있듯이 NGCF-fn은 전체 훈련 과정 동안 다른 모델들보다 훨씬 낮은 훈련 손실을 달성했으며, recall 또한 가장 높은 수치를 기록함을 알 수 있다.
📖 Method
LightGCN
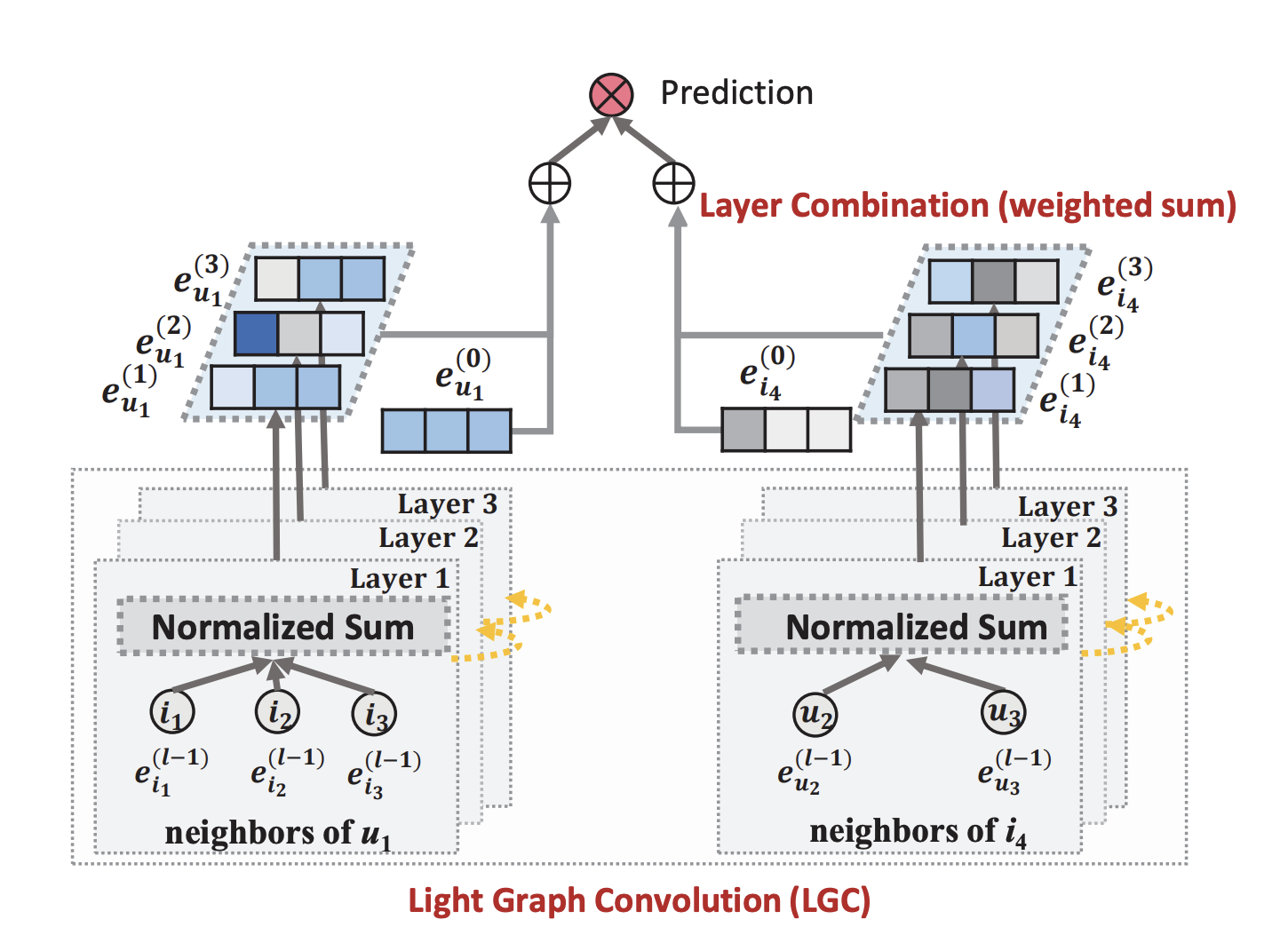
1. Light Graph Convolution (LGC)
LightGCN에서는 간단한 가중 합 집계 함수를 사용하며, 특징 변환과 비선형 활성화를 제거함으로써 다음과 같은 graph convolution 연산이 정의된다.
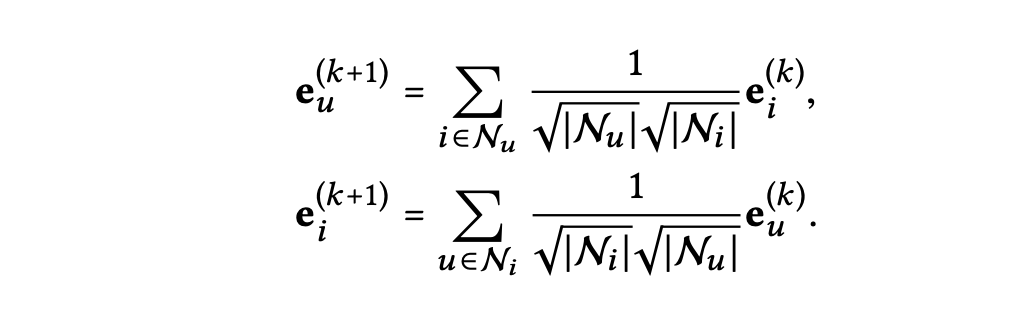
는 대칭 정규화로 임베딩의 스케일 증가를 방지한다.
기존 GCN과의 또 다른 차이점은 자기 자신은 집계시 포함하지 않고 연결된 이웃만으로 집계한다는 것이다.
이는 바로 다음에서 설명 할 레이어 결합 연산이 본질적으로 자기 연결과 동일한 효과를 가지고 있기 때문에 가능하다.
2. Layer Combination and Model Prediction
LighGCN에서 유일하게 학습 가능한 모델 파라미터는 0번째 레이어의 임베딩이다.
0번째 레이어의 임베딩은 모든 사용자에 대한 및 모든 아이템에 대한 이다.
해당 값을 통해 각 레이어의 임베딩 값이 계산될 수 있으며, 그 후 얻은 임베딩을 결합하여 사용자 혹은 아이템의 최종 표현을 형성하면 다음과 같다.
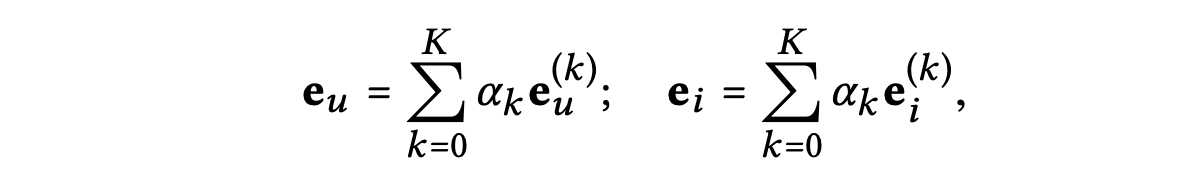
는 최종 임베딩을 형성하는 데 번째 레이어의 임베딩의 중요성을 나타낸다.
이 값은 수동으로 조정할 하이퍼파라미터로 취급하거나 자동으로 최적화할 모델 파라미터로 취급될 수 있다.
실험에서는 균일하게 설정하면 일반적으로 좋은 성능을 얻을 수 있음을 발견했다고 한다.
최종 표현을 얻기 위해 레이어를 결합하는 이유는 다음과 같다고 한다.
- 레이어 수가 증가함에 따라 임베딩이 과도하게 평활화될 수 있음
- 서로 다른 레이어의 임베딩은 다른 의미를 캡쳐
- 가중 합을 사용하여 다른 레이어에서의 임베딩을 결합하면 GCN의 중요한 트릭 중 하나인 자기 연결이 있는 graph convolution의 효과를 나타낸다.
모델 예측은 사용자 및 아이템 최종 표현의 내적으로 정의되며, 이는 추천 생성을 위한 순위 점수로 사용된다.
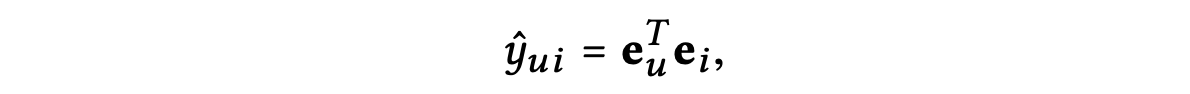
3. Matrix Form
본 섹션에서는 위에서 언급한 레이어 결합이 본질적으로 자기 연결과 동일한 효과를 갖는 이유를 설명한다.
1) 사용자-아이템 그래프의 인접행렬을 다음과 같이 얻을 수 있다.
: 사용자-아이템 상호 작용 행렬 사용자 수, 아이템 수)
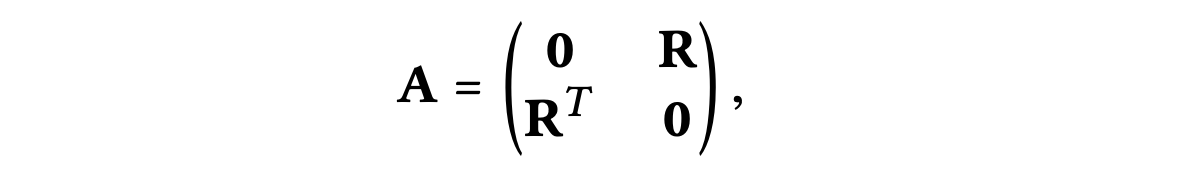
2) LGC와 동등한 행렬은 다음과 같이 얻을 수 있다.
: 0번째 레이어의 임베딩 행렬 임베딩 크기)
대각 성분 행렬이며,
각 항목 은 인접 행렬 의 번째 행 벡터에서 0이 아닌 항목의 수를 나타냄
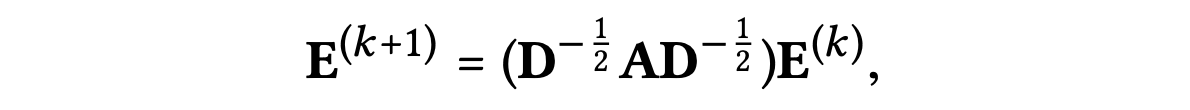
3) 마지막으로 모델 예측에 사용되는 최종 임베딩 행렬은 다음과 같다.
: 대칭 정규화 행렬
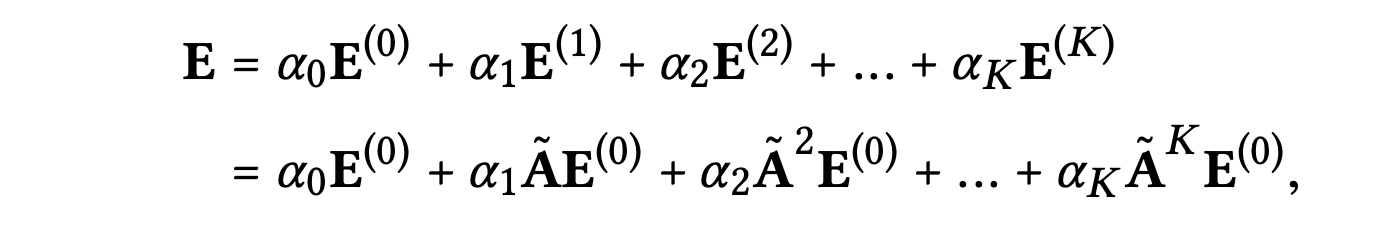
Model Analysis
1. Relation with SGCN
Simplifying Graph Convolutional Networks에서 저자들은 노드 분류를 위한 GCN의 불필요한 비선형성을 제거하고 가중치 행렬을 하나의 가중치 행렬로 축소함으로써 GCN을 간소화했다.
SGCN에서의 그래프 컨볼루션은 다음과 같이 정의된다.
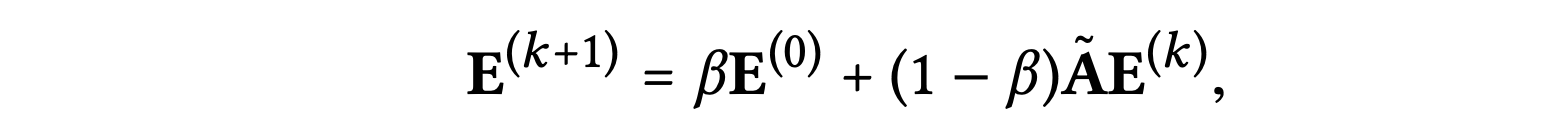
추가로 간결함을 위해 정규화 부분으로써 상수 값을 갖는 을 생략하고, 마지막 레이어에서 얻는 임베딩을 표현하면 다음과 같다.
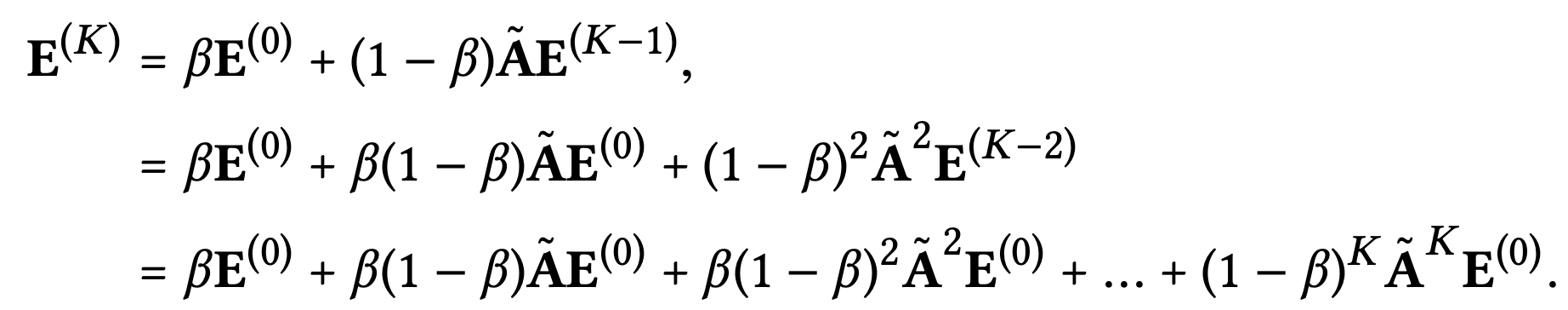
SGCN에서 보인 위의 수식적 유도는 앞서 설명한 LGC 레이어 결합이 본질적으로 자기 연결과 동일한 효과를 갖음을 보인다.
2. Relation with APPNP
저자는 Personalized PageRank에서 영감을 받아 GCN을 연결하며, 이를 바탕으로 Oversmoothing의 위험 없이 장거리 전파가 가능한 GCN 변형인 APPNP를 제안한다.
APPNP의 전파 레이어는 다음과 같이 정의된다.

는 전파에서 시작 기능을 보존하는 것을 제어하는 텔레포트 확률이다.
APPNP 마지막 레이어에서 얻는 임베딩을 표현하면 다음과 같다.
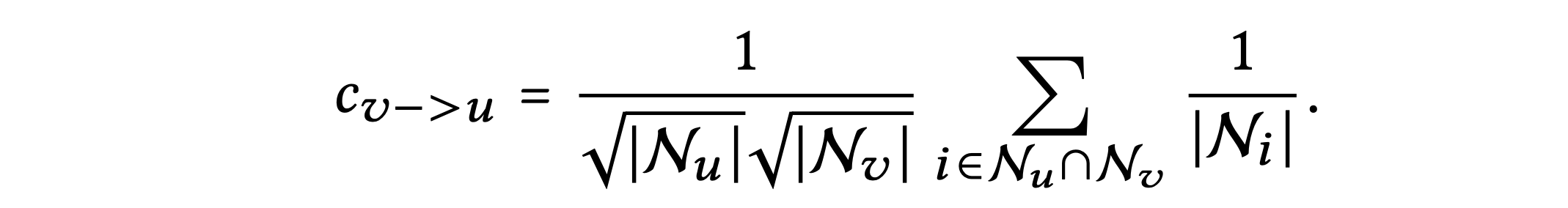
LightGCN은 를 적절히 설정함으로써 APPNP에서 사용된 예측 임베딩을 완전히 복구할 수 있으며, 이는 LightGCN이 Oversmoothing을 제어할 수 있음을 의미한다.
3. Second-Order Embedding Smoothness
이 섹션에서는 LightGCN이 선형성과 간결성을 위해 임베딩을 어떻게 더 smooth하게 만드는지 보인다.
사용자 측면을 예로 들어, 두 번째 레이어는 상호 작용하는 아이템이 겹치는 사용자를 다음과 같이 smooth하게 만든다.
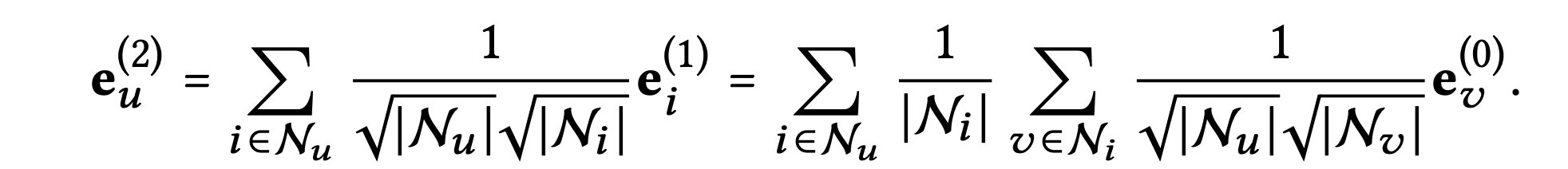
여기서 다른 사용자 가 대상 사용자 와 공동으로 상호 작용한 아이템이 있을 경우
의 에 대한 smoothness 강도는 계수에 의해 측정되며, 상호 작용 아이템이 없을 경우 값은 0이 된다.
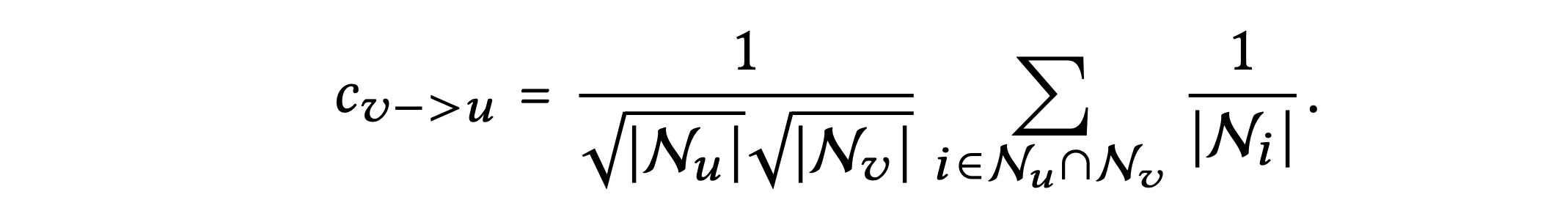
위의 계수로 의 2-hop에 있는 이웃 에 대한 영향을 해석하면 다음과 같다.
- 공동으로 상호 작용한 항목의 수에 따라 결정되며, 수가 많을수록 큰 값을 갖는다.
- 공동으로 상호 작용한 항목의 인기도에 따라 결정되며, 인기도가 적을수록 큰 값을 갖는다.
- 의 활동에 따라 결정되며, 활동이 적을수록 큰 값을 갖는다.
이러한 해석 가능성은 CF에서 사용자 유사성을 측정하는 가정을 잘 수용하며 LightGCN의 합리성을 입증한다.
즉, smoothness 강도가 1일 경우 두 사용자 임베딩은 동일한 사용자를 의미하며,
smoothness 강도가 0일 경우 두 사용자 임베딩은 전혀 다른 사용자임을 의미한다.
Model Training
LightGCN의 학습 가능한 매개변수는 0번째 레이어의 임베딩 뿐이며,
이는 모델 복잡도가 표준 행렬 인수분해와 동일함을 의미한다.
저자는 BPR loss를 사용한다.
이는 관찰된 항목의 예측이 관찰되지 않은 항목의 예측보다 높아지도록 유도하는 이진 손실 함수로 수식은 다음과 같다.
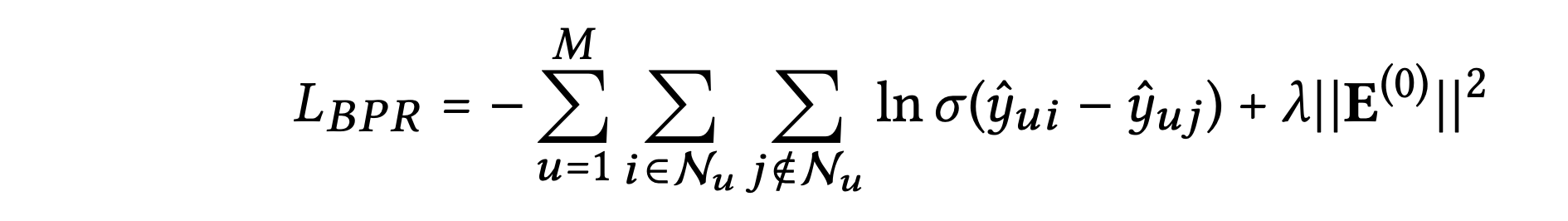
는 정규화 강도를 제어하며, Adam 옵티마이저를 사용하고 미니배치 방식을 적용했다고 한다.
📖 EXPERIMENTS
Performance Comparison with NGCF & State-of-the-Arts
-
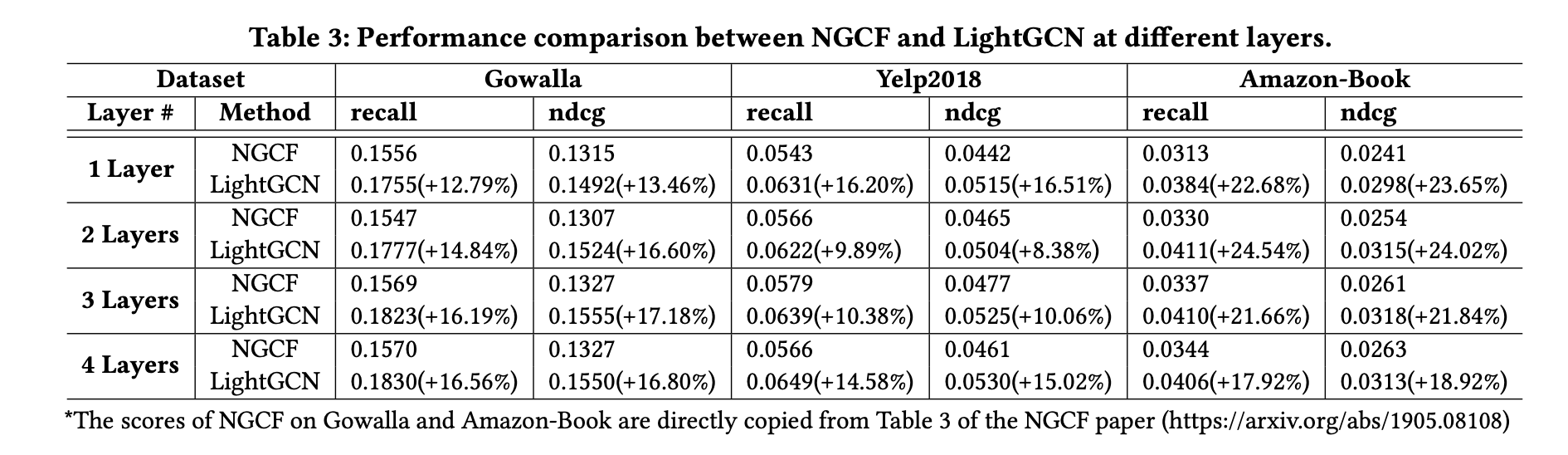
모든 경우에서 LightGCN이 NGCF를 크게 능가한다.
평균적으로 세 데이터셋에서 리콜 향상은 16.52%이며 ndcg 향상은 16.87%로 상당히 유의미하다. -
레이어의 수를 늘리면 성능이 향상되지만, 증가폭은 점점 줄어든다.
일반적으로 레이어 수를 0에서 1로 늘리면 가장 큰 향상이 나타나며, 레이어 수를 3으로 하는 것이 대부분의 경우에는 만족스러운 성능을 보인다고 한다.
- 위에서 언급한 NGCF-fn의 성능 표와 위의 LightGCN의 성능 표 비교를 통해 LightGCN이 NGCF-nf보다 우수한 성능을 보인다는 것을 알 수 있다.
- LightGCN이 세 데이터셋 모두에서 다른 방법들을 일관되게 능가하다.
LightGCN은 일관되게 더 낮은 traning loss를 보이며,
이는 LightGCN이 NGCF보다 훈련 데이터에 더 잘 맞는 것을 의미한다.
더 나아가 낮은 traning lossdl 더 나은 테스트 정확도로 이어지며 이는 LightGCN이 강력한 일반화 능력을 나타낸다.
Ablation and Effectiveness Analyses
Impact of Layer Combination
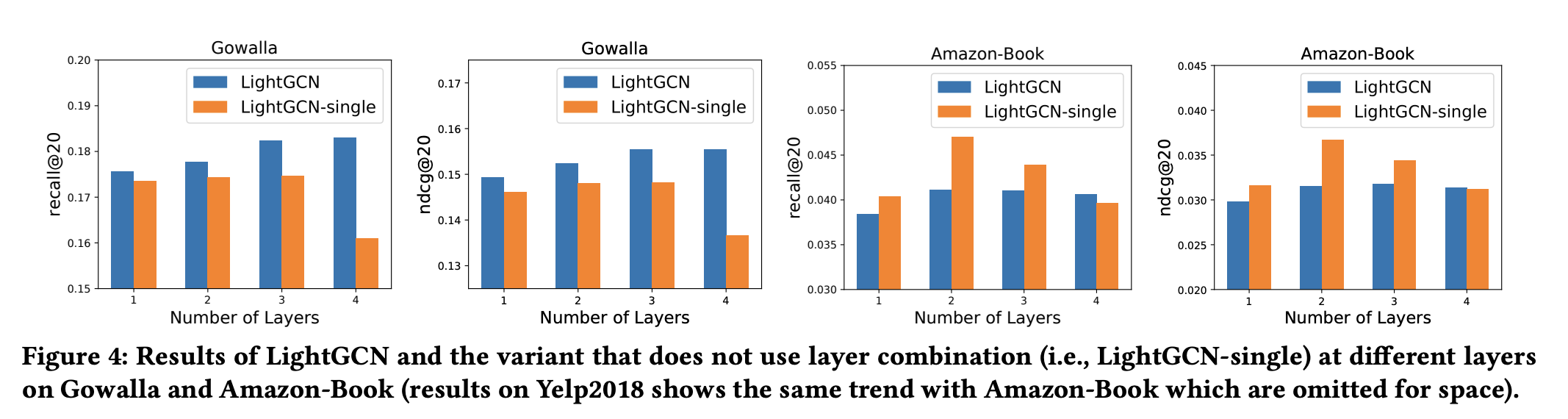
다음 그림에서 LightGCN-single은 마지막 레이어인 만을 최종 예측에 사용하는 모델로 LightGCN과 비교한다.
LightGCN은 일관되게 Gowalla에서 LightGCN-single을 능가하지만 Amazon-Book 및 Yepl2018에서는 그렇지 않음을 보인다.
저자는 레이어의 가중치를 튜닝함으로써 LightGCN의 성능을 더 향상시킬 수 있다고 말한다.
그래도 LightGCN-single은 성능이 레이어 2에서 최고점을 찍고 내려가는데 비해 LightGCN은 점진적으로 성능의 향상을 보이는 것을 통해 Oversmooothing을 해결하기 위한 레이어 조합의 효과를 정당화했다고 말한다.
Impact of Symmetric Sqrt Normalization
본 논문은 LightGCN에서 이웃 집계 수행시 각 이웃 임베딩에 대해 대칭 제곱근 정규화
() 사용에 대한 실험을 진행한다.
- 일반적으로 최선의 설정은 양쪽 모두에 제곱근 정규화를 사용하는 것이다.
- 두 번째로 좋은 설정은 왼쪽 side에만 L1 정규화를 사용하는 것이다.
- 두 side에 대해 대칭적으로 정규화하는 것은 제곱근 정규화에 도움이 되지만, L1 정규화의 성능을 저하시킨다.
Analysis of Embedding Smoothness
저자는 임베딩의 smoothing이 효과가 있는지 분석하기 위해 사용자 임베딩의 smoothness를 다음과 같이 정의한다.
실험 결과 2-layer LightGCN-single의 loss가 MF보다 훨씬 낮음을 알 수 있다.
이는 light graph convolution을 수행함으로써 임베딩이 smooth하고 추천에 더 적합해진다는 것을 나타낸다고 한다.
Hyper-parameter Studies
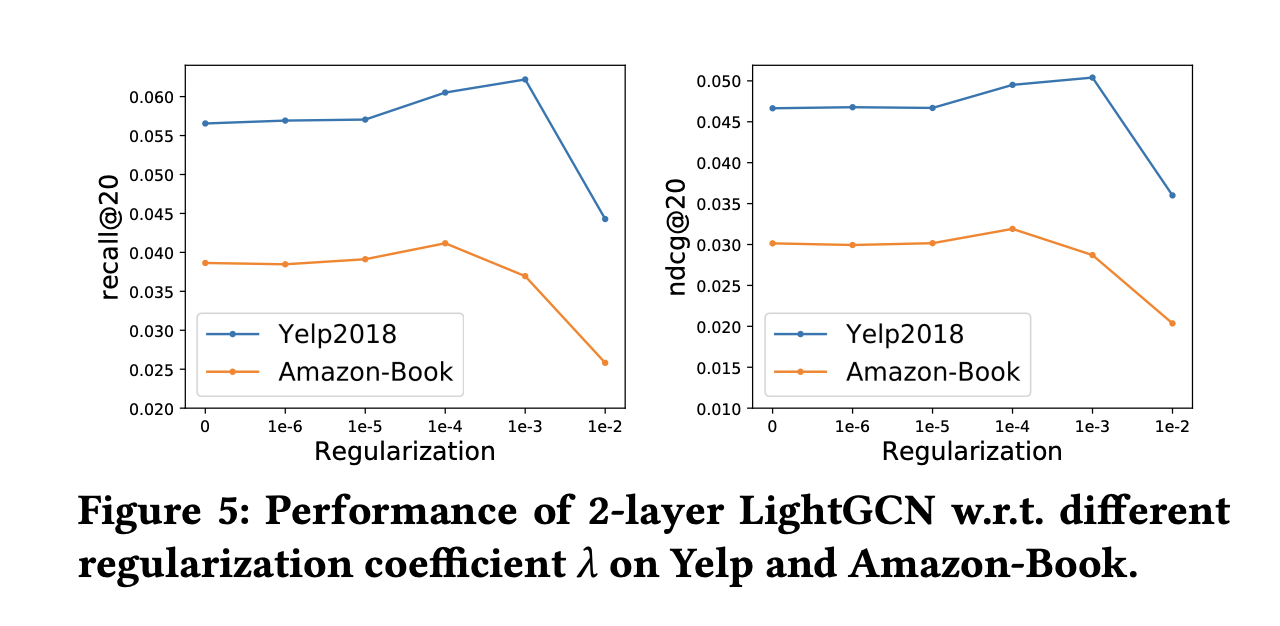
LightGCN을 새로운 데이터셋에 적용할 때, 표준 하이퍼파라미터인 학습률 외에 튜닝해야 할 가장 중요한 하이퍼파라미터는 L2 전규화 계수 이다.
위 그림을 통해 알 수 있듯이 LightGCN은 에 상대적으로 민감하지 않다.
를 0으로 설정해도 LightGCN은 추가로 드롭아웃을 사용하여 과적합을 방지하는 NGCF보다 더 나은 결과를 보인다고 한다.
📖 CONCLUSION
LightGCN은 light graph convolution과 layer combination으로 이루어졌다.
- light graph convolution은 기존 GCN에서의 표준 작업 중 feature transformation과 nonlinear activation을 제거했다.
- layer combination에서는 노드의 최종 임베딩을 모든 레이어에서의 임베딩의 가중합으로 구성하여 자체 연결 효과를 포괄하는 oversmoothing을 제어하도록 구성했다.
본 논문의 저자분이 작성한 논문을 읽을 때 마다 자신이 내세운 가정이 본질적으로 성능 향상에 도움이 되는지를 엄중한 잣대와 함께 실험하여 증명해내는 것을 매번 보임으로써 존경스러운 실험의 자세를 배울 수 있었다 생각한다.
추가로 모델의 성능 향상에 있어 불필요한 요소를 제거하는 것 또한 중요하다는 관점을 일깨워주어 나에게 의미있는 논문이 되었다고 생각한다.
Reference
LightGCN: Simplifying and Powering Graph Convolution
Network for Recommendation
[Paper Review] LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
