[논문 리뷰] RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
Paper Review
📌 RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
📖 ABSTRACT
-
협업 필터링의 희소성 및 콜드 스타트 문제를 해결하기 위해 지식 그래프를 부가 정보로 활용하여 추천 성능을 향상시킨다.
-
지식 그래프의 기존 path-based 방법과 embedding based 방법의 한계를 해결하기 위해 RippleNet이라는 end-to-end 프레임워크를 제안한다.
-
RippleNet이 영화, 책 및 뉴스 추천과 같은 다양한 시나리오에서 SOTA 모델 대비 우수한 성능을 달성했음을 보인다.
📖 INTRODUCTION
다음 그림과 같이 지식 그래프는 엔터티와 그들 간의 관계를 나타내는 그래프 구조로 추천에 대해 세 가지 측면에서 이점을 제공한다.
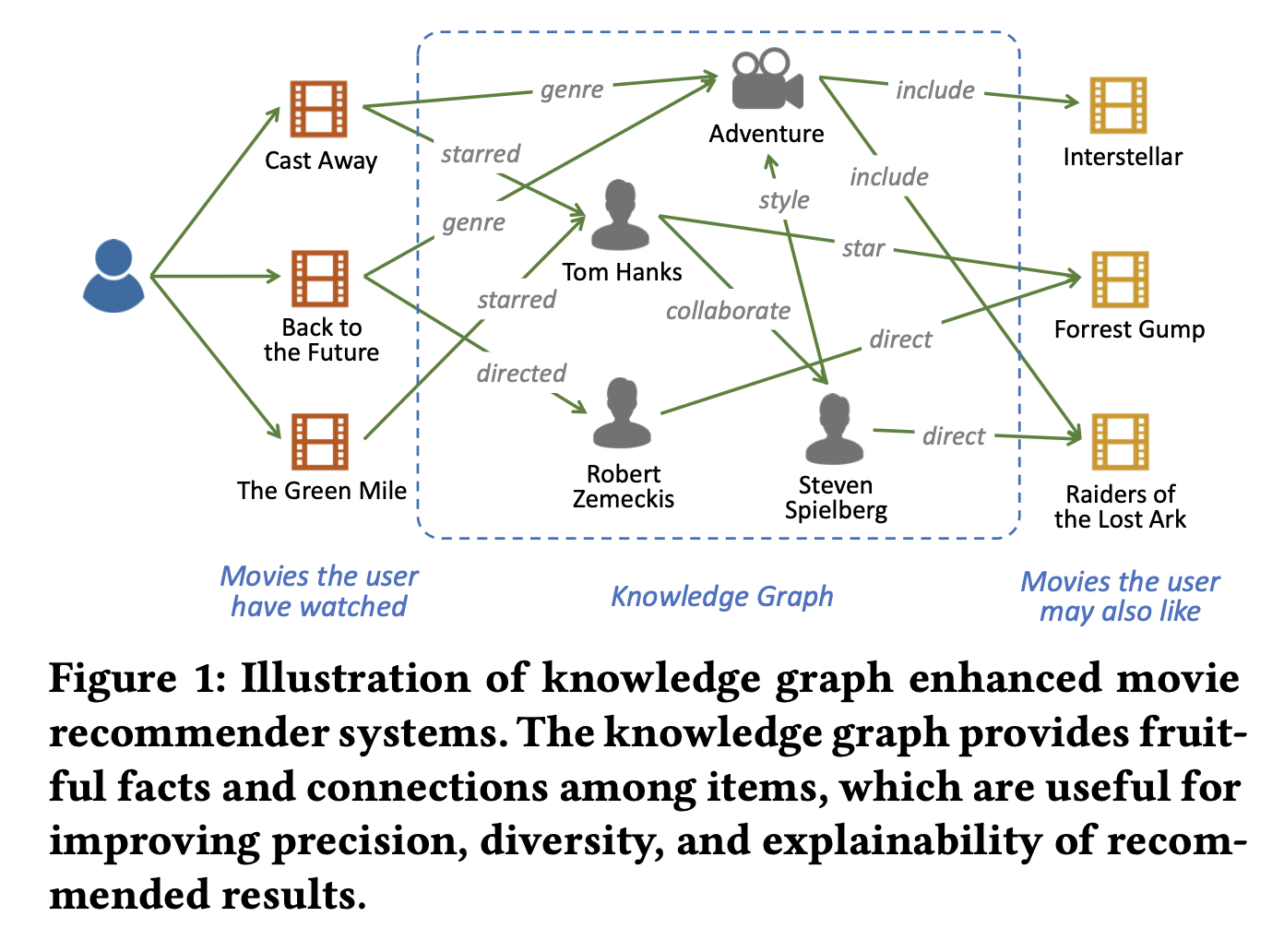
- 항목 간의 의미적 관련성을 도입하여 잠재적인 연결을 찾고 추천 항목의 정확도를 향상시킬 수 있다.
- 다양한 유형의 관계로 구성되어 있어 사용자의 관심을 합리적으로 확장하고 추천 항목의 다양성을 증가시키는 데 도움이 된다.
- 사용자의 과거 기록과 추천된 항목을 연결하여 추천 시스템에 설명 가능성을 제공한다.
[참고]
지식 그래프 내에는 사용자 노드가 존재하지 않는다.
사용자는 사용자-아이템 이분법 그래프에만 존재하며, 지식 그래프는 해당 아이템의 정보를 추가로 활용하기 위해 이용한다는 것을 명심하면 도움이 될 것 같다.
지식 그래프 두 가지 분류 및 한계점
기존 지식 그래프를 고려한 추천은 두 가지 범주로 분류될 수 있다.
1. Embedding-based methods: 지식 그래프 임베딩 알고리즘을 사용하여 지식 그래프를 전처리하고 학습된 엔터티 임베딩을 추천 프레임워크에 통합한다.
임베딩 기반 방법은 지식 그래프를 활용하여 추천 시스템을 지원하는 데 높은 유연성을 보여주지만, 학습된 엔터티 임베딩은 항목 간 관계를 특성화하는 데 덜 직관적이기 때문에 추천보다 링크 예측에 더 적합하다.
2. path-based methods: 지식 그래프 내 항목들 간의 다양한 연결 패턴을 탐색하여 추천에 대한 추가적인 지침을 제공한다.
경로 기반 방법은 지식 그래프를 더 자연스럽고 직관적인 방식으로 활용하지만, 수동으로 설계된 meta-path에 매우 의존하기 때문에 실제로 최적화하기 어려운 측면이 있다.
이에 대한 비교적 쉬운 설명은 [논문리뷰] KGAT: Knowledge Graph Attention Network for Recommendation의 <기존 협업 지식 그래프(CKG) 활용 한계점> 부분을 참고하면 도움이 될 것이다.
RippleNet 한계점 해결
기존 방법들의 한계점을 극복하기 위해 본 논문은 지식 그래프 기반 end-to-end 추천 프레임워크 RippleNet을 제안한다.
RippleNet은 해결책으로 앞서 언급한 두 유형의 장점을 결합한다.
RippleNet은 선호도 전파를 통해 KGE 방법을 추천에 통합하며, 어떠한 수동적인 디자인 없이 사용자의 기록에서 특정 항목으로의 가능한 경로를 자동으로 발견한다.
[참고] Unified Method
RippleNet은 처음으로 path-based method와 Embedding based method를 결합한 unified method 모델로 A Survey on Knowledge Graph-Based Recommender Systems에서 소개된다.
📖 RippleNet
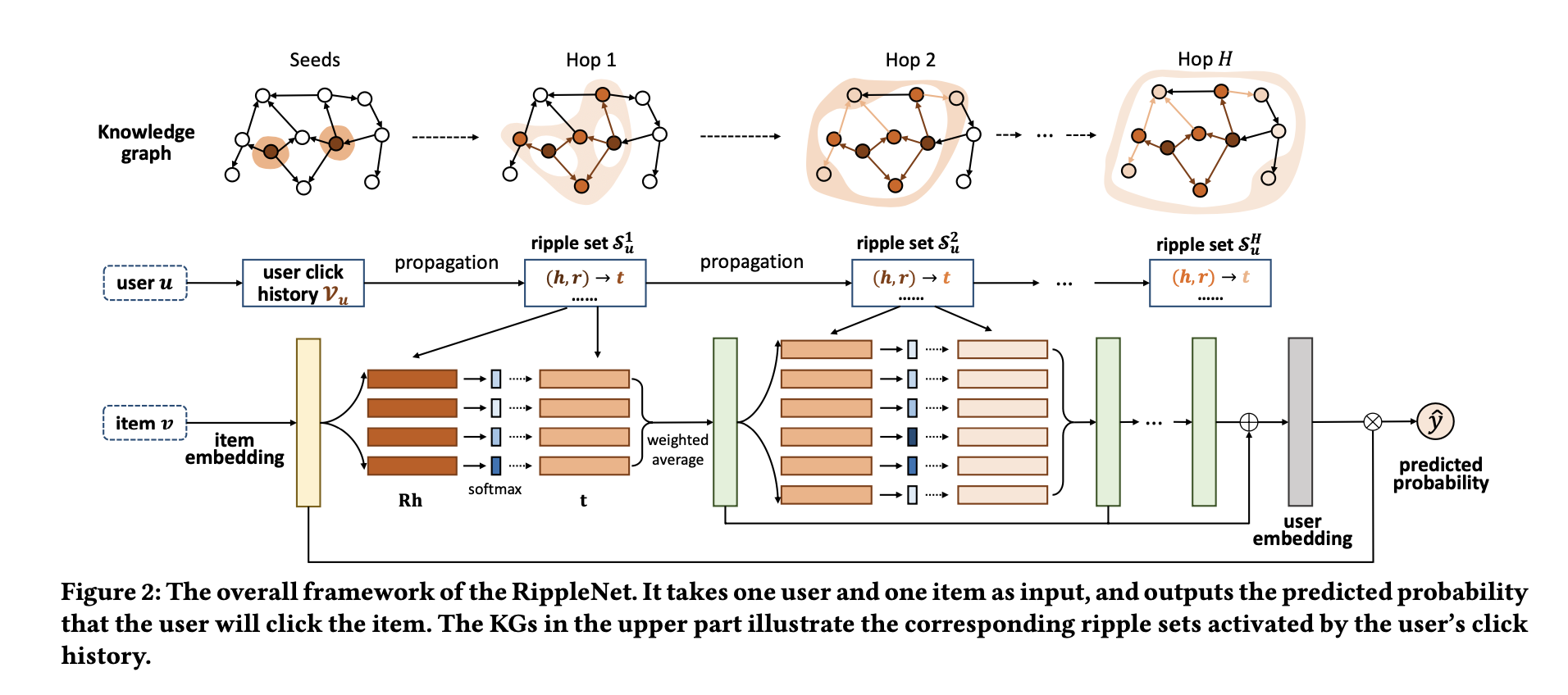
RippleNet은 CTR 예측을 위해 설계되었으며, 사용자-아이템 쌍을 입력으로 받아 사용자가 아이템을 클릭할 확률을 예측하여 출력한다.
다음 그림은 RippleNet의 프레임워크를 나타낸다.
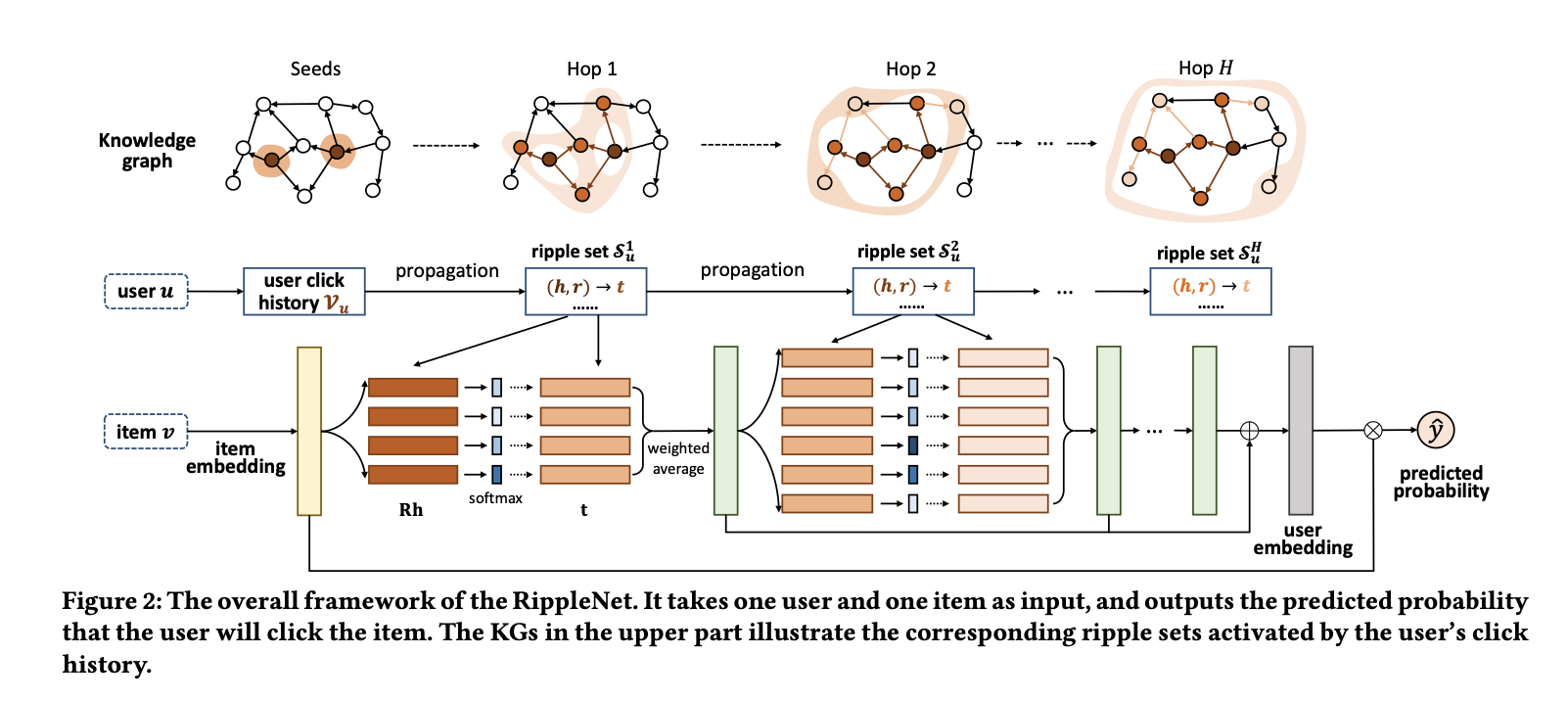
입력 사용자 에 대해, 그의 과거 관심사 집합 는 지식 그래프에서 Seeds로 정의한다.
이후 길이 만큼 떨어진 ripple set 를 형성하기 위해 확장된다.
즉, 는 seed set 로부터 -hop만큼 떨어진 knowledge triples sets이다.
이러한 ripple sets은 밑에서 언급할 식 4를 통해 아이템 embedding(노란 블록)과 계산되고 Seeds 아이템 에 대한 응답(초록 블록)을 얻는다.
이러한 응답은 최종적으로 사용자 에 대한 임베딩(회색 블록)을 형성하기 위해 결합되며, 마지막으로 사용자 와 항목 의 임베딩을 함께 사용하여 예측 확률 를 계산한다.
Ripple Set
지식 그래프의 각 엔터티들은 다음과 같이 다양한 관계로 연결되어있다.

위 그림의 "Forrest Gump"는 "Robert Zemeckis"(감독), "Tom Hanks"(주연), "U.S"(국가), "Drama"(장르)와 연결되어있다.
이와 같이 다양한 연결은 사용자의 선호도를 탐색하는 데에 깊고 잠재적인 관점을 제공한다는 이점을 지닌다.
예를 들어, 사용자가 "Forrest Gump"를 시청한 적이 있다면, 이 사용자는 "Tom Hanks"에 대한 팬이 되어 "The Terminal"이나 "Cast Away"와 같은 다른 작품에 관심을 가질 수 있다고 가정을 할 수 있기 때문이다.
지식 그래프의 관점에서 사용자의 계층적으로 확장된 선호도를 특성화하기 위해 RippleNet에서는 사용자 에 대한 -hop 관련 엔터티 집합을 다음과 같이 재귀적으로 정의한다.
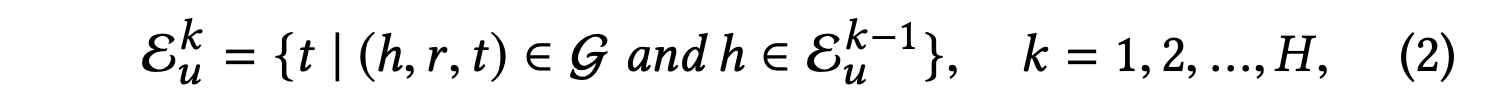
=={}은 사용자 가 과거에 클릭한 항목들의 집합으로, 앞서 말했듯이 지식 그래프에서 Seeds set으로 정의된다.
이와 관련된 엔터티는 사용자의 지식 그래프에 대한 과거 관심사의 자연스러운 확장으로 간주될 수 있다.
사용자 의 -hop ripple set은 다음과 같이 정의한다.
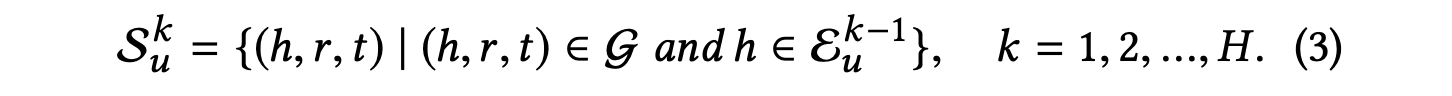
계속해서 언급되는 ripple은 본 논문에서 다음의 두 가지 의미를 지닌다고 한다.
- 여러 빗방울이 만들어내는 실제 물결과 유사하게, 사용자의 잠재적인 엔터티에 대한 관심은 그의 과거 선호도에 의해 활성화되어 지식 그래프의 링크를 따라 층층히 전파된다.
- 사용자의 잠재적인 선호도의 세기는 의 증가에 따라 약해지며, 이는 실제 물결의 점차적으로 약해지는 진폭과 유사하다.
이러한 ripple set은 의 증가에 따라 크기가 너무 커질 수 있다는 우려를 지니고 있으며, 이를 해결하기 위해 다음 사항들을 고려한다.
- 현실의 지식 그래프에서 많은 엔터티는 그림 3의 "2004"와 "PG-13"과 같이 들어오는 링크만 있고 나가는 링크가 없는 sink entities에 해당하기 때문에 ripple set이 너무 커질 일이 흔치 않다.
- 특정 추천 시나리오에서, 예를 들어 영화 시나리오에서는 이름에 "film"이 포함되어 있는 관계만을 고려하는 것으로 제한하여 ripple set의 크기를 줄이고 엔터티 간의 관련성을 향상시킬 수 있다.
- 사용자의 기록에서 너무 멀리 떨어진 엔터티는 긍정적인 신호보다 노이즈를 더 가져올 수 있기 때문에 의 선택에 대해서 실험적으로 논의한다.
- RippleNet에서는 계산 과부하를 줄이기 위해 전체 ripple set 대신 고정 크기의 이웃 집합을 샘플링할 수 있다.
📖 Preference Propagation
전통적인 CF 기반 방법들은 사용자와 아이템의 잠재적인 표현을 학습하고, 그들의 표현에 내적 곱과 같은 특정 함수를 적용하여 알려지지 않은 평가를 예측한다.
하지만 RippleNet에서는 사용자와 아이템 간의 상호 작용을 더 세밀하게 모델링하기 위해 사용자의 ripple set에서의 잠재적 관심을 탐색하기 위한 선호도 전파 기술을 제안한다.
각 아이템 의 임베딩과 사용자 의 -hop ripple set( 의 각 트리플 이 주어졌을 때, 다음과 같이 아이템 를 이 트리플의 헤드 및 관계 와 비교하여 관련성 확률을 할당한다.
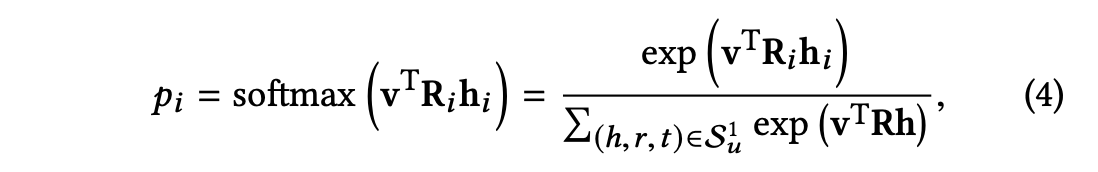
관련성 확률 는 관계 의 공간에서 아이템 와 엔터티 사이의 유사성을 나타낸다.
[참고] 헤드와 테일
지식 그래프에서 화살표를 내보내는 노드가 헤드이며, 화살표를 받는 노드는 테일이다.
관련성 확률을 얻은 후에는 해당 관련성 확률로 가중된 의 tails을 합산하고, 그 결과로 벡터 를 반환한다.
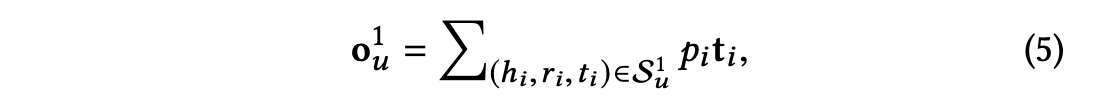
벡터 는 사용자 의 클릭 기록 에 대한 아이템 의 1차 응답으로 볼 수 있다.
위 두 수식의 연산을 통해 사용자의 관심사는 그의 기록 집합 에서 의 링크를 따라
-hop 관련 엔터티 집합 로 전달되며, 이를 RippleNet의 선호도 전파라고 한다.
수식 4에서 를 로 대체함으로써, 사용자 의 2차 응답 를 얻기 위해 선호도 전파 과정을 반복할 수 있다.
이 과정은 사용자 의 물결 집합 의 에 대해 반복적으로 수행될 수 있다.
이에 따라 사용자 의 여러 순서의 응답 를 관찰할 수 있으며, 사용자 에 대한 아이템 의 임베딩은 모든 순서의 응답을 결합하여 계산된다.
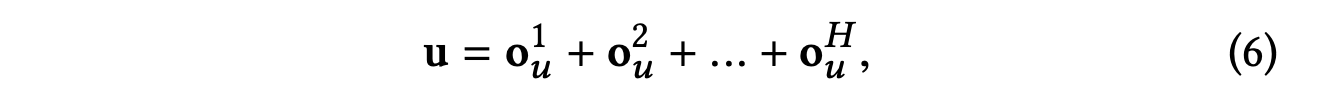
마지막 hop의 사용자 응답 가 이론적으로 이전 hop의 모든 정보를 포함하고 있지만, 희석될 수 있기 때문에 작은 hop의 를 결합하는 것은 필요하다.
마지막으로, 사용자 임베딩과 아이템 임베딩을 결합하여 예측된 클릭 확률을 출력한다.
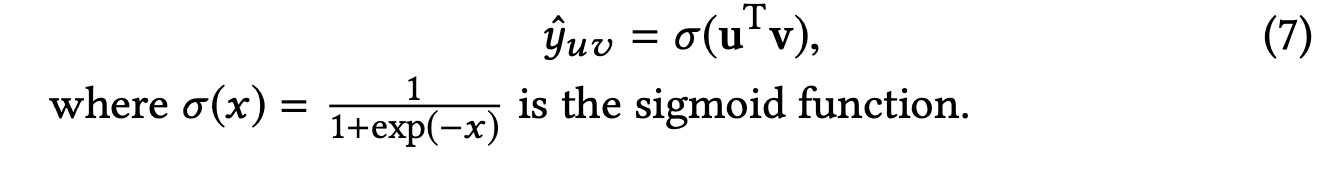
📖 Learning Algorithm
RippleNet은 지식 그래프 와 암시적 피드백 행렬 를 관측한 후에 모델 매개변수 의 다음 사후 확률을 최대화하려고 한다.
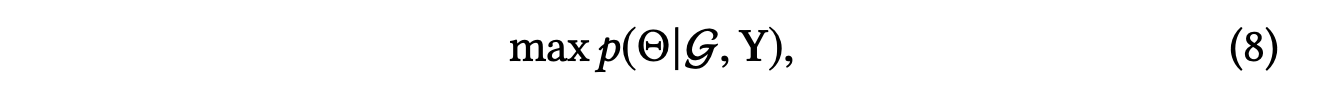
에는 엔터티, 관계 및 항목의 임베딩이 포함되며, 다음 식은 최대화와 같다.
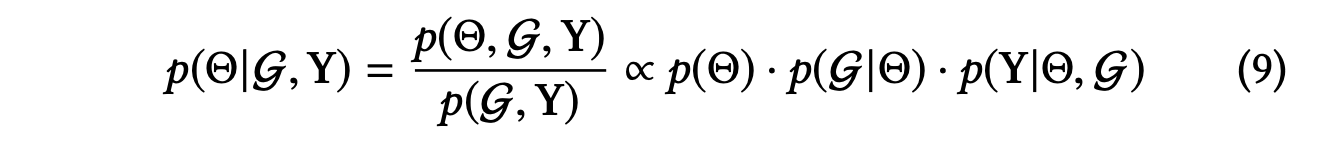
Bayes' 이론에 따르면, 위 식의 첫 번째 항인 는 모델 매개변수 ⊖의 사전 확률을 측정한다.
CKE 논문에 따르면 는 다음과 같이 평균이 0이고 대각 공분산 행렬을 갖는 가우시안 분포로 설정된다고 한다.
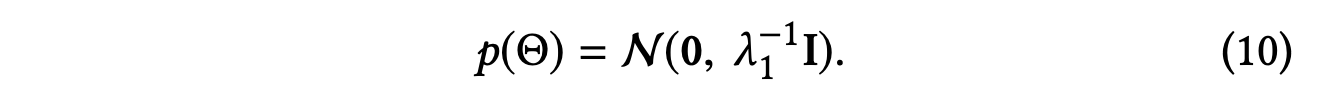
식 9의 두 번째 항은 모델 매개변수 가 주어졌을 때 관측된 지식 그래프 의 우도 함수이다.
RippleNet에서는 three-way tensor factorization method를 사용하여 다음과 같이 지식 그래프 임베딩에 대한 우도 함수를 정의한다.
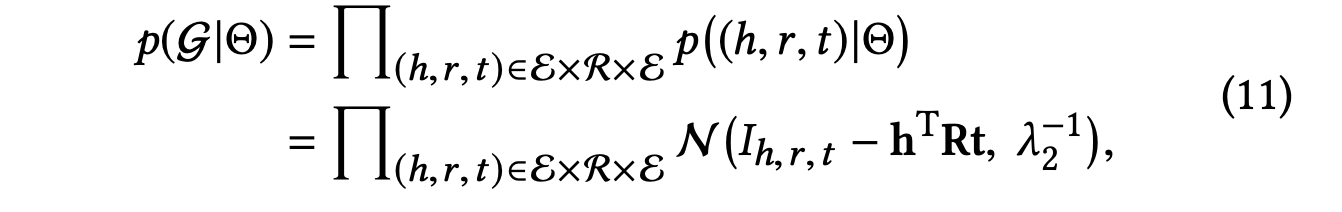
indicator 는 가 지식 그래프에 속하면 1이고 그렇지 않으면 0이 된다.
식 11에 따르면 지식 그래프 임베딩의 엔터티-엔터티 쌍 및 선호도 전파의 아이템-엔터티 쌍에 대한 점수 함수를 동일한 계산 모델 하에 통합할 수 있다.
식 9의 마지막 항은 와 지식 그래프가 주어졌을 때 관측된 암시적 피드백의 우도 함수로, 베르누이 분포의 곱으로 정의된다.
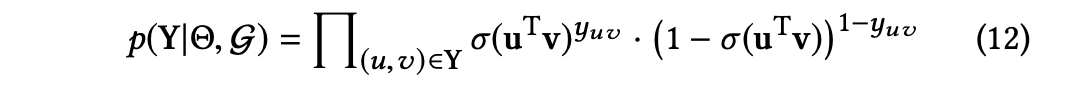
식 9에 대한 음의 로그를 취하면 RippleNet은 다음과 같은 손실 함수를 얻는다.
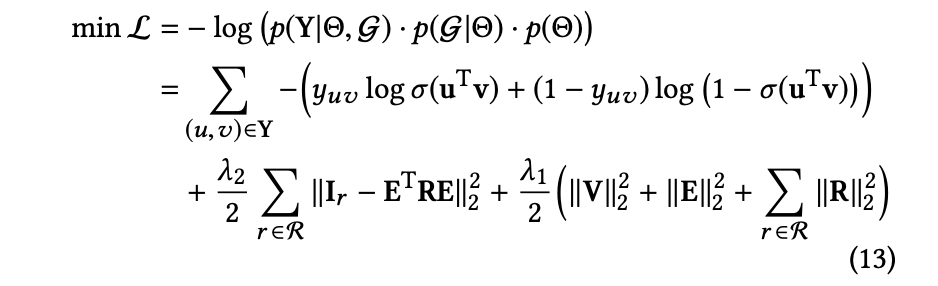
와 는 모든 아이템과 엔터티의 임베딩 행렬이고, 은 관계 에 대한 지식 그래프의 indicator tensor 의 slice이다.
그리고 은 관계 의 임베딩 행렬이다.
식 13의 첫 번째 항은 상호 작용 의 실제 값과 RippleNet에 의해 예측된 값 사이의 교차 엔트로피 손실을 측정하며, 두 번째 항은 지식 그래프의 의 실제 값과 재구성된 indicator tensor 간의 제곱 오차를 측정한다.
세 번째 항은 과적합을 방지하기 위한 정규화 항이다.
[참고] Indicator tensor
"Indocator tensor"는 한 엔터티와 다른 엔터티 간의 특정 관계가 있는지 여부를 나타내는 정보를 담고 있으며,
주어진 조건이 만족되면 1의 값을, 그렇지 않으면 0의 값을 갖는 텐서를 나타낸다.
이를 통해 모델은 사용자의 히스토리와 관련하여 특정 관계를 따라 확장될 수 있는 잠재적인 관심사를 학습할 수 있다.
위의 문제는 확률적 경사 하강법 알고리즘을 사용하여 손실 함수를 반복적으로 최적화한다.
RippleNet의 학습 알고리즘은 다음을 따른다.

각 훈련 반복에서 계산을 더 효율적으로 만들기 위해 에서 양성/음성 상호 작용의 미니배치 및 에서 참/거짓 트리플의 미니배치의 부정 샘플링 전략을 따라 무작위로 샘플링한다.
그런 다음 손실 에 대한 모델 매개변수 의 기울기를 계산하고 샘플링된 미니배치에 기초하여 역전파를 사용하여 모든 매개변수를 업데이트한다.
📖 EXPERIMENTS
Results
CTR 예측 및 상위- 추천의 모든 방법 결과는 다음 그림과 테이블에 제시되어있다.
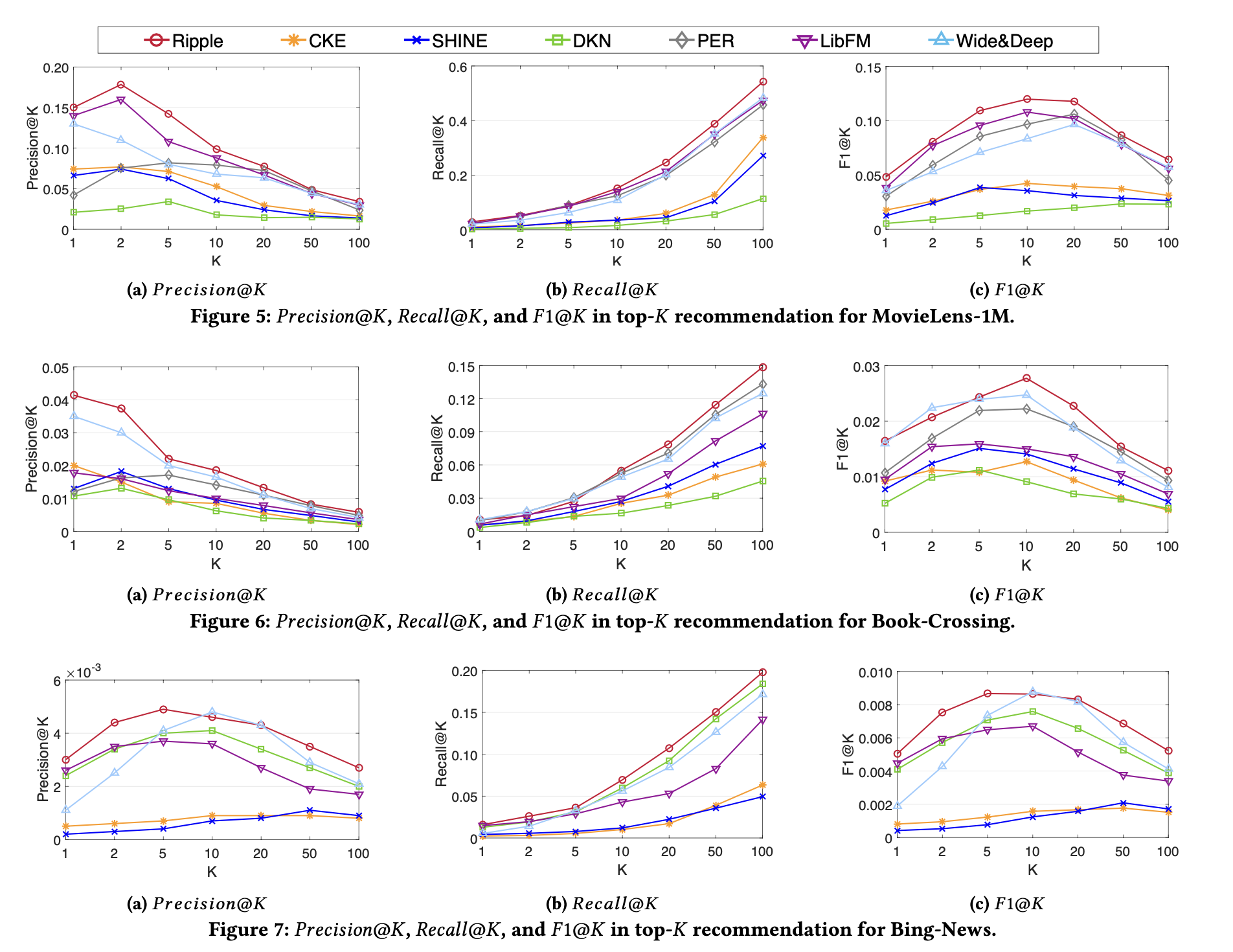
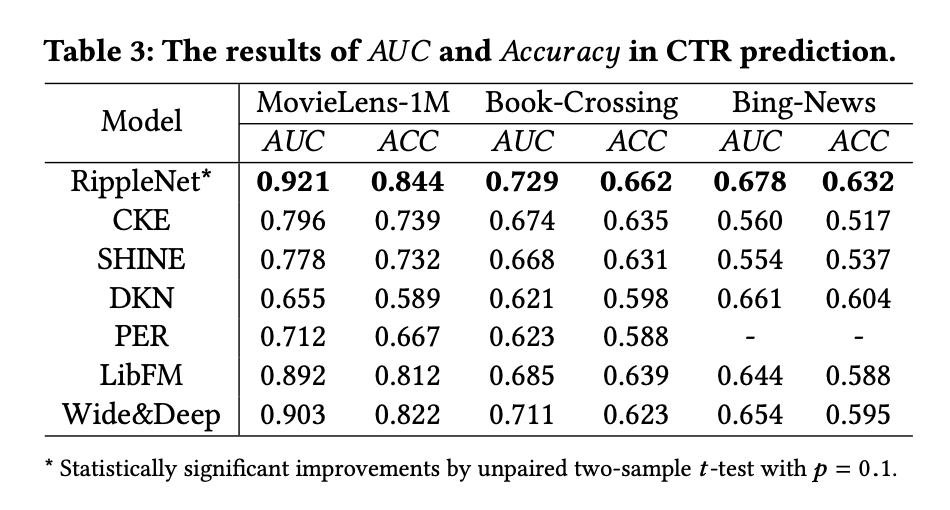
- CKE는 다른 기준에 비해 비교적 성능이 좋지 않다.
- SHINE은 뉴스 추천보다 영화 및 책 추천에서 더 좋은 성능을 보인다.
- LibFM 및 Wide&Deep은 지식 그래프에서 얻은 정보를 효과적으로 활용할 수 있어 만족스러운 성능을 달성한다.
- RippleNet은 세 데이터셋 모두에서 가장 우수한 성능을 발휘한다.
Size of ripple set in each hop
추가로 각 hop에서 사용자의 ripple set 크기를 변화시켜가며 RippleNet의 강건성을 조사했다.
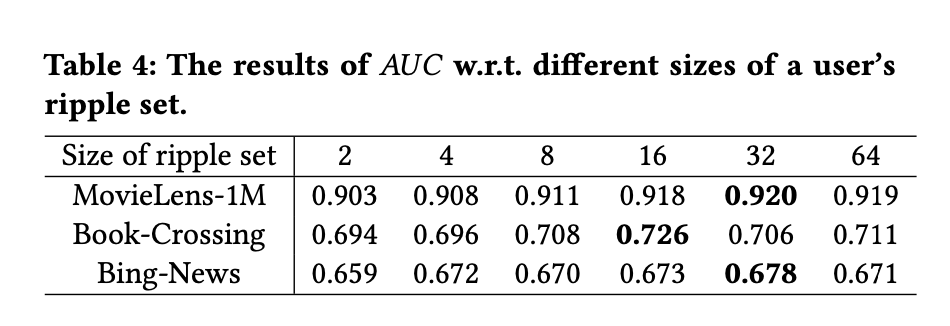
ripple set의 크기가 증가함에 따라 RippleNet의 성능이 처음에는 향상되었음을 보이며, 이는 지식 그래프에서 더 많은 지식을 인코딩할 수 있기 때문으로 보인다.
그러나 ripple set이 너무 큰 경우에는 성능이 감소한다.
일반적으로 실험 결과에 따르면 대부분의 데이터셋에 대해 크기 16 혹은 32가 충분해 보인다.
Hop number
또한 최대 Hop을 변화시킴에 따라 RippleNet의 성능이 어떻게 변하는지도 조사했다.
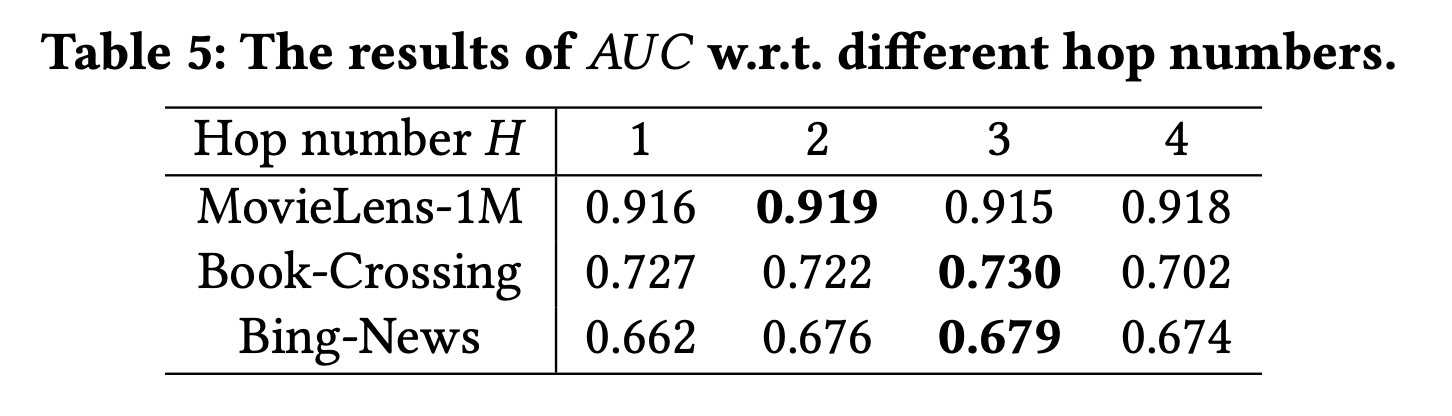
모델 최고의 성능은 H가 2 또는 3일때 달성되었다.
너무 작은 H는 상호 엔터티 간 관련성 및 장거리 종속성을 탐험하기 어렵게 만드는 반면,
너무 큰 H는 유용한 신호보다 더 많은 노이즈를 가져오는 것으로 보인다.
Case Study
RippleNet의 선호 전파를 직관적으로 시연하기 위해, 무작위로 4개의 클릭된 뉴스를 가진 사용자를 샘플링하고, 그의 테스트 세트에서 레이블 1을 가진 하나의 후보 뉴스를 선택했다.
추가로 사용자의 -hop 관련 엔터티 각각에 대해 해당 엔터티와 후보 뉴스 또는 그의
-순서 응답 사이의 관련 확률을 계산해 보인다.
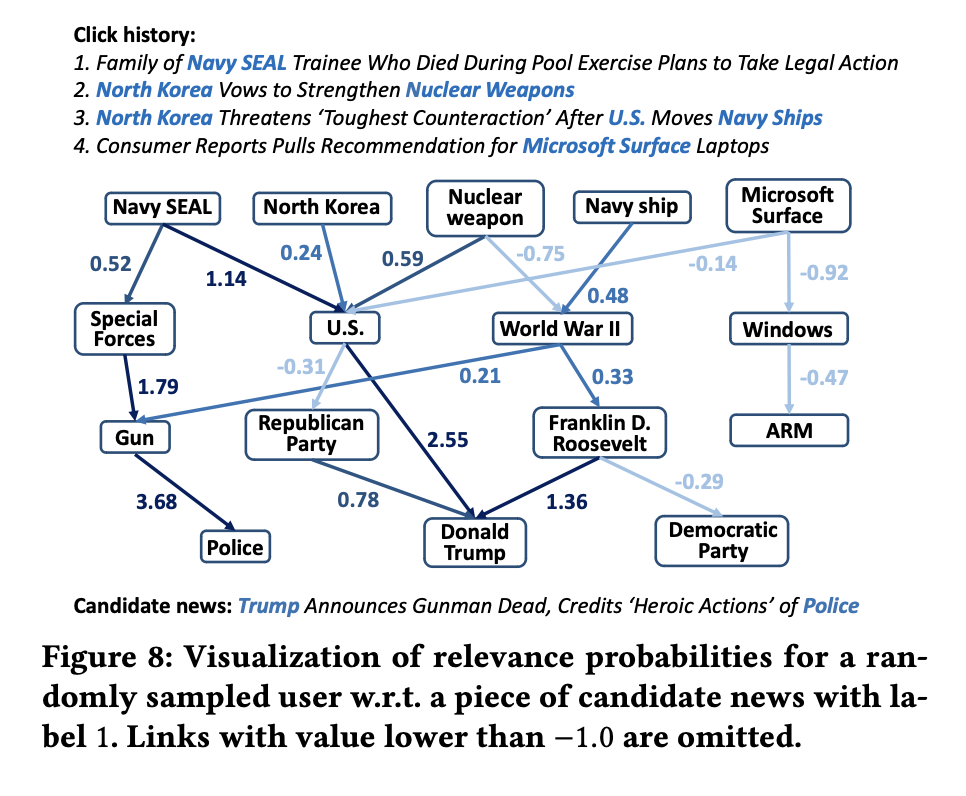
RippleNet이 후보 뉴스를 사용자의 관련 엔터티와 각기 다른 강도로 연관시킨다는 것을 볼 수 있다.
후보 뉴스는 "Navy SEAL" → "Special Forces" → "Gun" → "Police"와 같이 지식 그래프 내에서 사용자의 클릭 기록에 높은 가중치를 보이는 여러 경로를 통해 도달한다.
이러한 강조된 경로는 선호 전파에 의해 자동으로 발견된다.
추가로 주목할 만한 점은 "U.S.", "World War II", "Donald Trump"와 같은 몇몇 엔터티가 사용자의 기록에서 더 집중적인 관심을 받는다는 것이다.
이러한 중심 엔터티는 앞서 논의한 Ripple Superposition으로 인한 것이며, 향후 추천을 위한 사용자의 잠재적인 관심으로 기능할 수 있다고 한다.
Parameter Sensitivity
이 섹션에서는 RippleNet의 매개변수인 와 의 영향을 조사한다.
각각 를 2에서 64로, 를 0.0에서 1.0으로 변화시키면서 다른 매개변수를 고정하여 다음의 결과를 보인다.
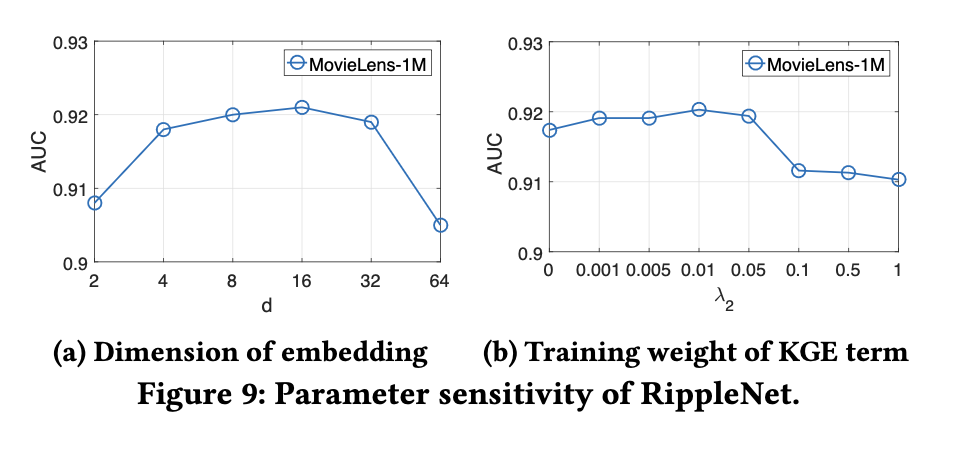
- 더 큰 차원의 임베딩은 더 유용한 정보를 인코딩할 수 있기 때문에 가 증가함에 따라 모델의 성능이 처음에는 향상된다. 하지만 = 16 이후에는 오버피팅으로 인해 성능이 감소한다.
- 가 작은 가중치로 설정될 때 RippleNet이 최고의 성능을 달성한다.
그럼에도 작은 가중치의 지식 그래프 임베딩 항은 충분한 정규화 제약을 제공하지 못할 수 있는 반면, 큰 가중치는 목적 함수를 오도할 수 있다.
📖 CONCLUSION
지식 그래프 관련 모델을 공부하는 데 있어 KGAT review를 기록했을 때 보다는 이해도가 높아진 것은 사실나 embedding-based method 및 path-based method에 대한 대표 모델들을 따로 공부할 필요성을 느낀다.
