📌 Self-Supervised Learning for Recommender Systems: A Survey
📖 Abstract
-
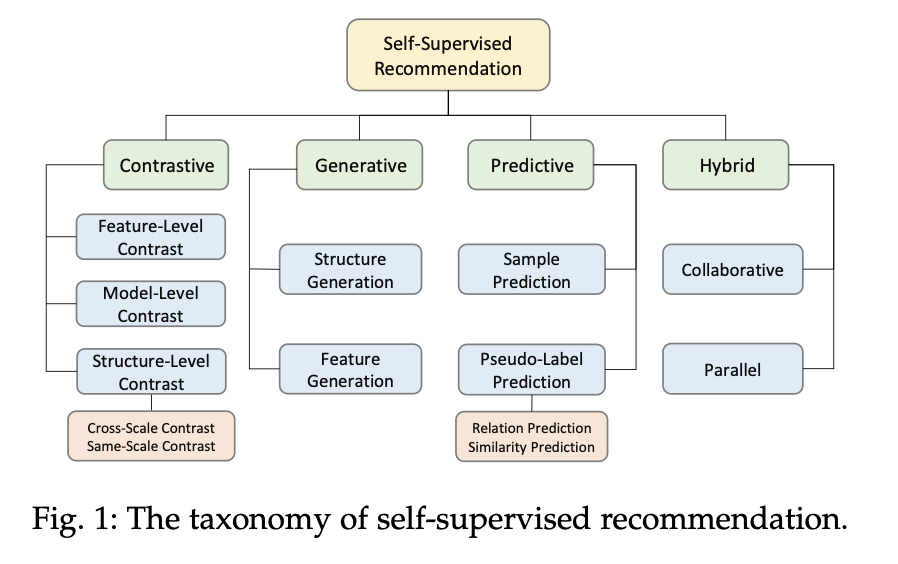
자기 지도 학습은 추천 시스템의 희소한 데이터를 처리하는 문제에 있어서 해결책으로 주목받고 있으며, 본 서베이 논문은 이러한 자기 지도 학습을 Contrastive, Generative, Predictive, Hybrid 네 가지 범주로 나누어 설명한다.
-
실험 비교를 용이하게 하기 위해 다양한 SSR 모델과 벤치마크 데이터셋이 포함되어 있는 SELERec이라는 오픈 소스 라이브러리를 공개한다.
📖 Introduction
본 서베이에서는 다음과 같이 SSR의 정의를 제안한다.
- SSR은 더 많은 데이터를 요청하는 대신 raw data 자체를 활용하여 희소한 명시적 피드백을 보완하기 위해 추가 감독 신호를 추출한다.
- 증강된 데이터를 사용하여 추천 모델을 학습시키기 위해 자기 지도 작업을 통합한다.
- 자기 지도 작업은 종착점이 아닌 추천 성능을 향상시키기 위해 설계되었다.
처음에는 PinSAGE에서 negative sample을 정의하여 학습하는 방식이 SSR의 Contarstive learning과 다른점이 있는지 의아했지만, 본 논문에서 이에 대해 설명한다.
기존 Contrastive learning 기반 추천은 지도 및 비지도 설정 모두에 적용되며, 데이터를 증강하지 않고 marginal loss를 최적화한다는 점에서 self-supervised learning으로 분류되지 않는다.
데이터를 증강하는 것이 둘의 핵심적인 차이라고 보여진다.
SSR 대부분의 모델들은 Encoder + Projection-Head 아키텍처를 따른다.
현재 SSR의 연구는 주로 graph와 sequential data를 활용한다.
- 인코더 는 사용자와 아이템을 위한 분산 표현 를 학습하며, 데이터에 따라 GNNs, Transformers 그리고 MLP와 같은 다양한 신경망이 사용된다.
- 프로젝션 헤드 는 를 추천 작업이나 특정 자기 지도 작업을 위해 적합하게 만들며, 일반적으로 선형 변환, 얕은 MLP 또는 비모수 매핑과 같은 가벼운 구조가 사용된다.
이 아키텍처를 기반으로 하여 SSR은 다음과 같이 정의될 수 있다.
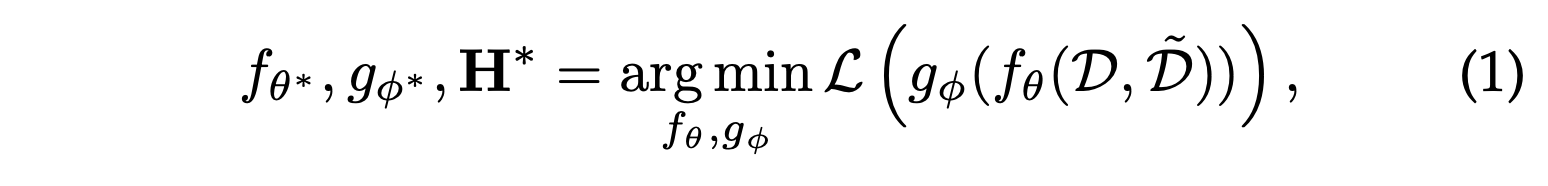
수식에서 는 원본 데이터이며, ~: 증강된 데이터이다.
SSR은 전형적인 세가지 훈련 방식을 지닌다.
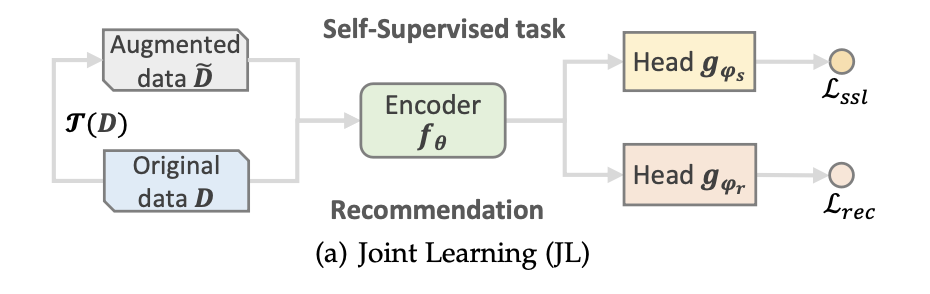
- Joint Learning: 일종의 다중 작업 학습으로 간주될 수 있지만, 전치 작업의 출력은 일반적으로 우선 순위가 높지 않고 추천 작업을 규제하는 데 도움이 되는 보조 작업으로 간주된다.
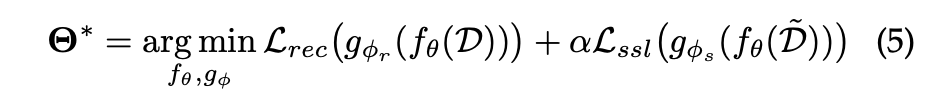
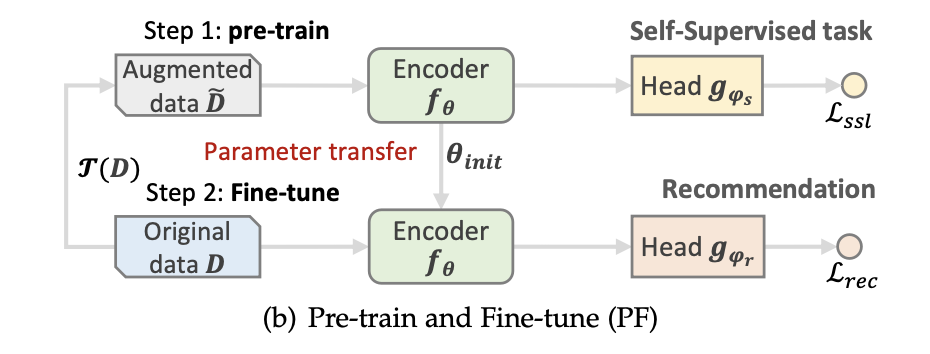
- Pre-training and Fine-tuning: 먼저 Pre-training 단계에서는 인코더가 증강된 데이터에서 self-supervised 작업으로 사전 훈련되어 파라미터의 유리한 초기화를 달성한 후 원본 데이터에서 fine-tuning되며, 추천 작업을 위한 프로젝션 헤드에 적용된다.
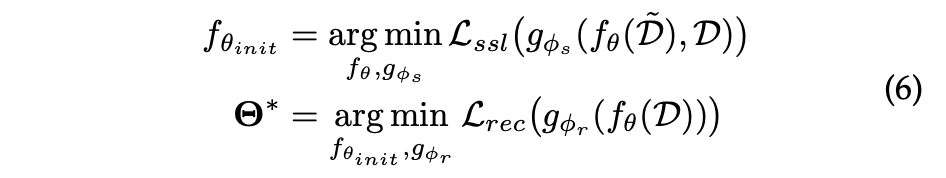
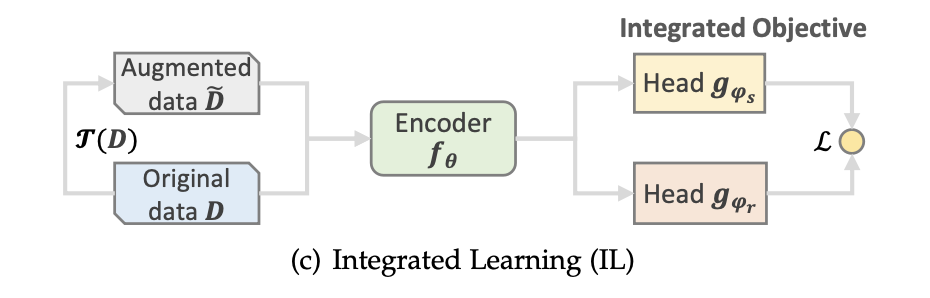
- Integreted learning: 이 방식에서는 pretext task와 recommendation task가 잘 맞물려 통합되어 통일된 목표로 적용된다.
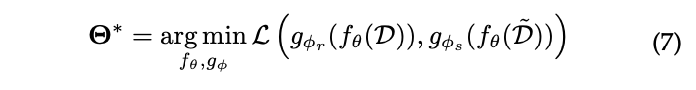
📖 DATA AUGMENTATION
SSR에서 일반적으로 사용되는 데이터 증강 기술은 시퀀스 기반, 그래프 기반, 그리고 특징 기반으로 분류된다.
Sequence-Based Augmentation
주어진 항목 시퀀스 가 있을 때, 일반적인 시퀀스 기반 증강 방법은 다음과 같다.
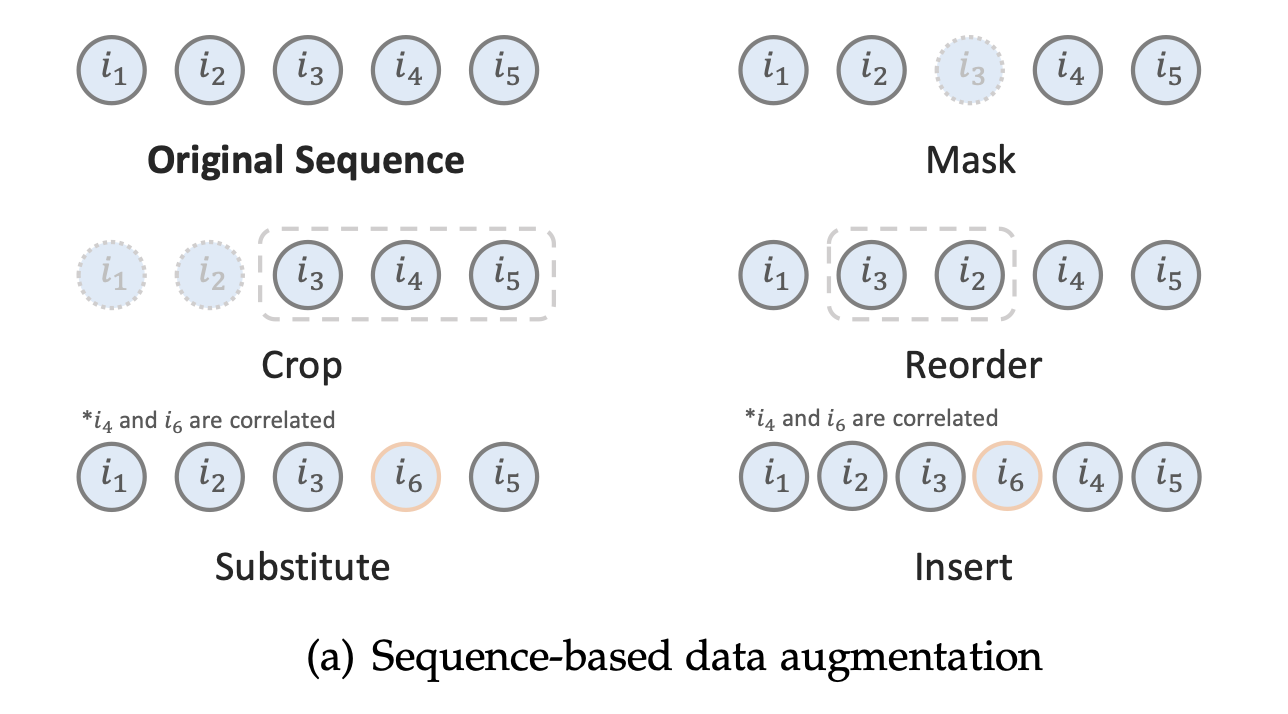
- Item Masking: BERT의 단어 마스킹과 유사한 전략으로, 항목 중 일정 비율이 무작위로 토큰 [mask]로 대체된다.
- Item Croping: 사용자의 과거 시퀀스 S가 주어졌을 때, 길이가 인 연속한 하위 시퀀스가 무작위로 선택된다.
- Item Reordering: 연속한 하위 시퀀스의 항목 순서를 섞어 증강된 시퀀스를 만들어낸다.
- Item Substitution: 짧은 시퀀스에서 특정 항목을 상관성이 높은 다른 항목으로 대체한다.
- Item Insertion: 짧은 시퀀스를 보완하기 위해 상관성이 높은 항목을 주변에 삽입한다.
Graph-Based Augmentation
주어진 사용자-아이템 그래프와 인접 행렬에 대해 일반적인 그래프 기반 증강 방법은 다음과 같다.
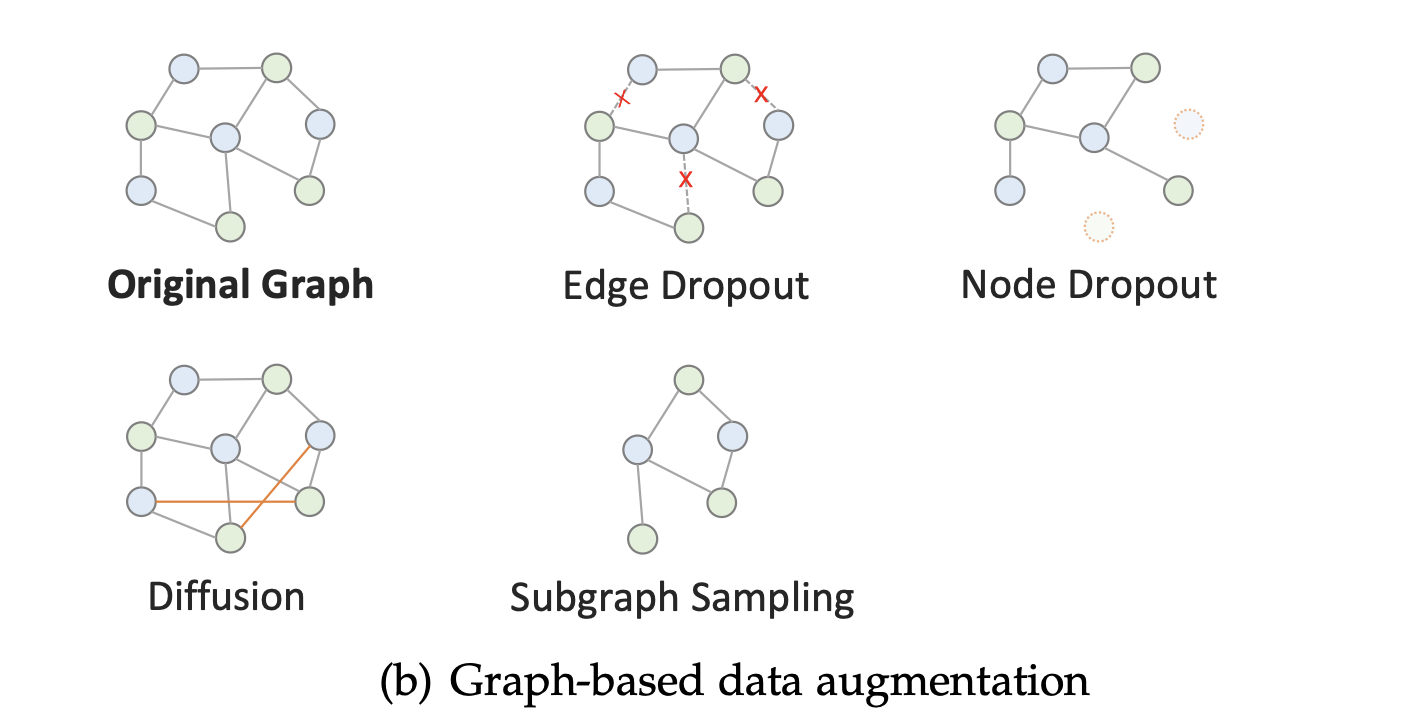
- Edge/Node Dropout: 엣지와 노드는 확률 로 그래프에서 제거된다.
- Garph Diffusion: 그래프에 엣지를 추가하여 뷰를 생성한다.
- Subgraph Sampling: 노드와 엣지의 일부를 샘플링하여 서브그래프를 형성한다.
Feature-Based Augmentation
Feature-based agumentation 작업은 속성이나 임베딩 공간 내에서 작동한다.
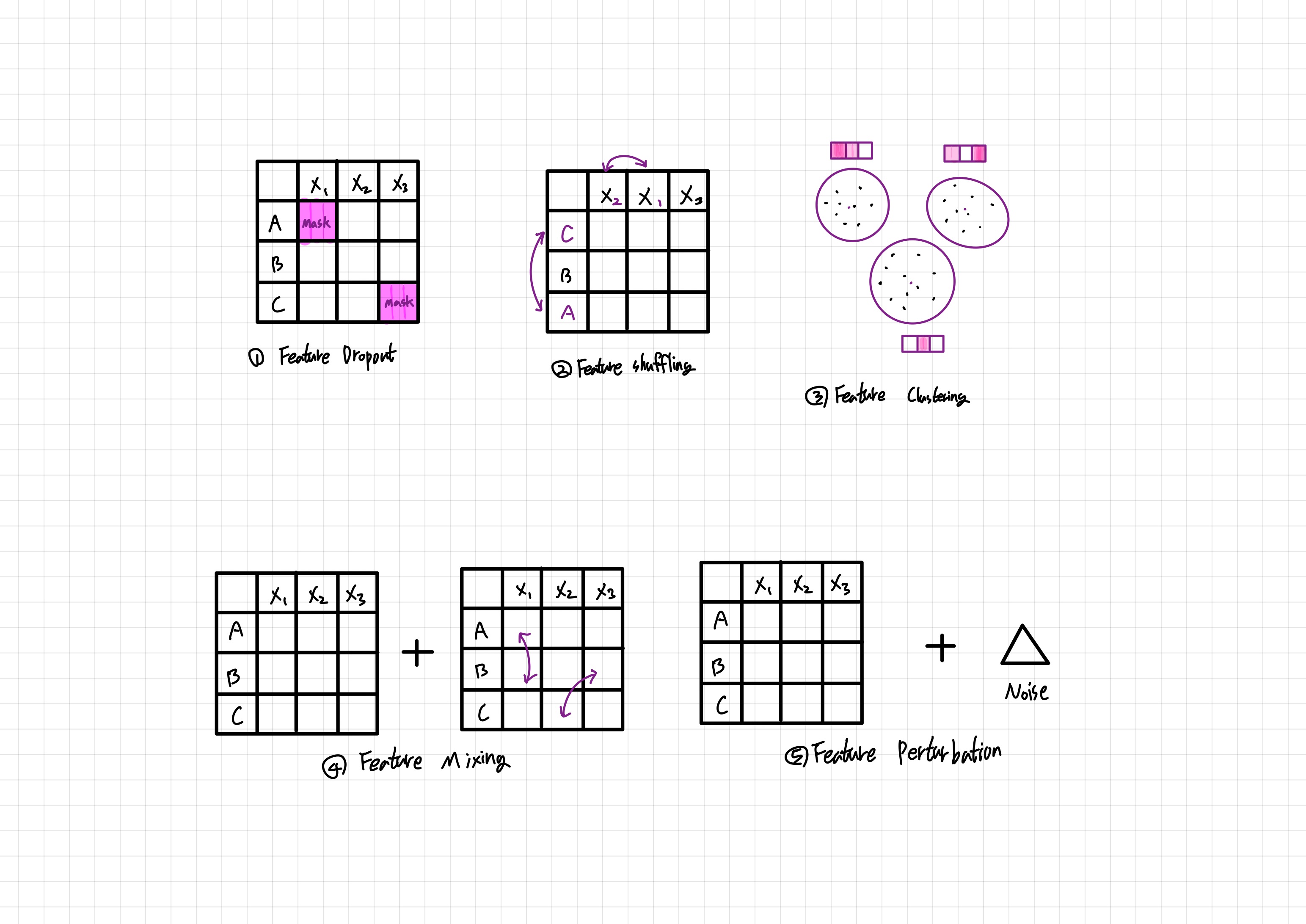
- Feature Dropout: 특성 행렬에서 일부 특성을 랜덤하게 삭제한다.
- Feature Shuffling: 특성 행렬의 행과 열을 독립적으로 섞는다.
- Feature Clustering: Clustering과 Contrastive learning을 결합한 방법으로, 특성 행렬의 행들을 클러스터링한 후, 각 클러스터의 대표 표현을 사용한다.
- Feature Mixing: 다른 사용자/아이템과 섞은 특성을 원본 사용자/아이템 특성과 합성한다.
- Feature Perturbation: 사용자/아이템 표현에 무작위 노이즈를 추가한다.
📖 CONTRASTIVE METHODS
Contrastive learning의 아이디어는 각 인스턴스(사용자/아이템/시퀀스)를 하나의 클래스로 취급하고, 임베딩 공간에서 동일한 인스턴스의 변형을 가깝게 배치하는 반면, 서로 다른 인스턴스의 변형을 멀리 배치하는 것이다.
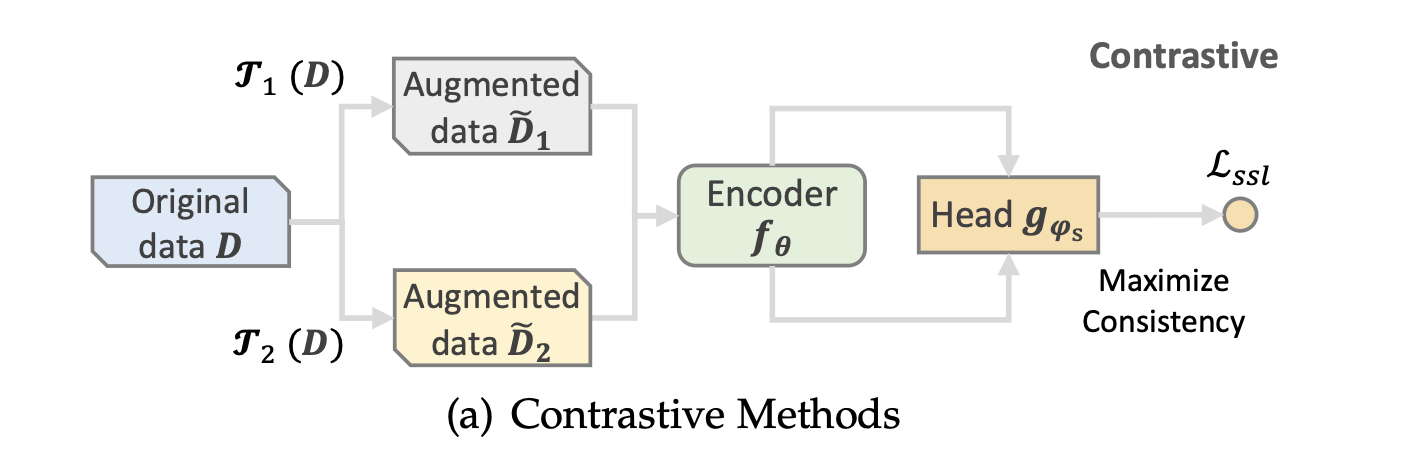
이러한 작업은 structure-level contrast, feature-level contrast 그리고 model-level contrast로 나뉜다.
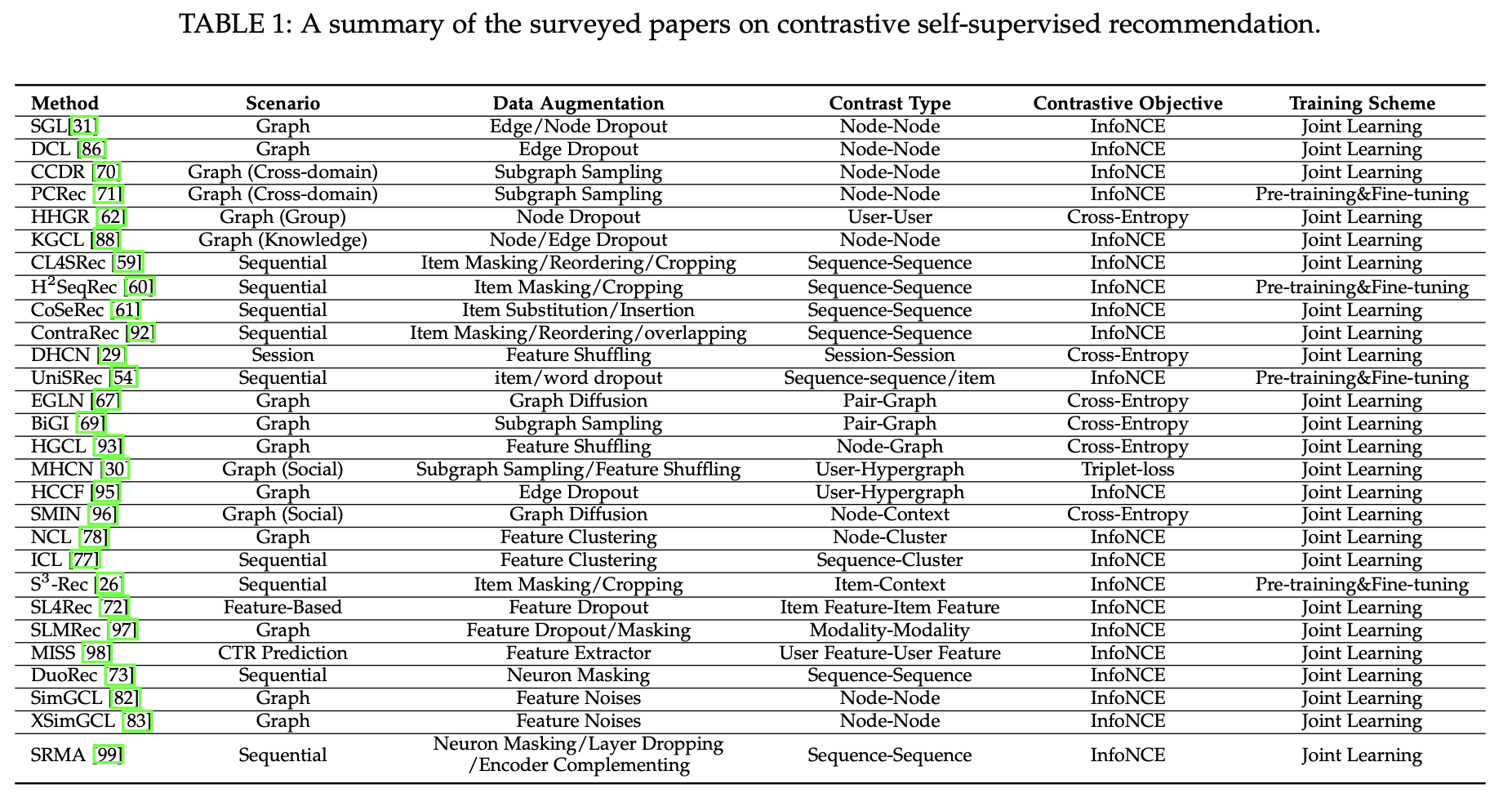
Structure-Level Contrast
structure-level contrast는 same-scale contrast와 cross-scale contrast로 나뉜다.
- same-sclae contrast는 동일한 규모의 두 객체의 뷰를 포함하여 Local-Local contrast와 Global-Global contrast 두 수준으로 나눈다.
- cross-scale contrast는 서로 다른 규모의 두 객체의 뷰를 포함하여 Local-Global Contrast와 Local-context Contrast 두 수준으로 나눈다.
Local-Local Contrast
Local-Local contrast는 그래프 기반 SSR 모델과 함께 사용되어 사용자/아이템 노드 표현 간의 상호 정보를 최대화한다.
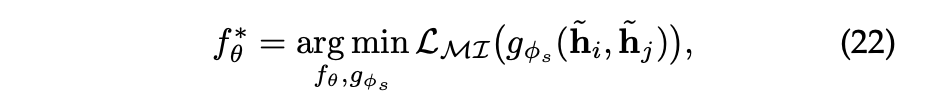
와 는 모두 증강된 노드 표현을 의미한다.
Global-Global Contrast
Global-Global Contrast는 sequential 추천 모델에서 자주 사용되며 시퀀스를 사용자의 전체적인 뷰로 간주한다.
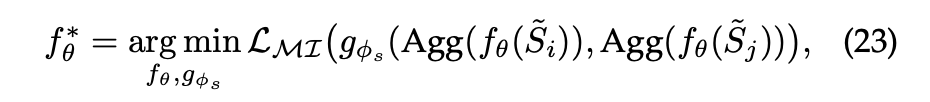
와 는 모두 증강된 시퀀스를 의미한다.
Local-Global Contrast
Local-Global Contrast는 그래프 학습에서 자주 사용되며, 전역 정보를 지역 구조 표현으로 인코딩하고 전역 및 지역 의미를 통합하는 것을 목표로 한다.
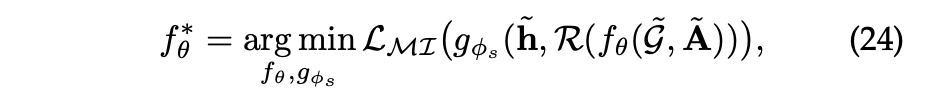
은 global-level 그래프 표현의 readout 함수로 그래프에서 노드의 특성을 요약한다.
Local-Context Contrast
Local-Context Contrast는 그래프와 시퀀스 모두에서 관찰되며, 컨텍스트는 ego-network 혹은 클러스터링을 통해 구성된다.
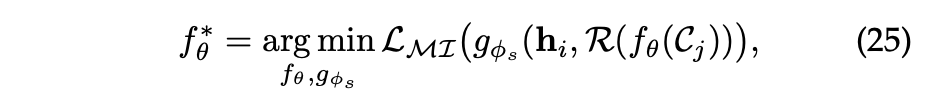
는 노드 혹은 시퀀스 의 컨텍스트를 의미한다.
Feature-Level Contrast
feature-level contrast는 structure-level contrast 대비 학술 데이터셋에서의 제한된/특성 속성 정보로 인해 덜 탐구되었다.
반면, 산업에서는 데이터가 일반적으로 다중 필드 형식으로 구성되며 사용자 프로필 및 아이템 카테고리와 같은 다양한 범주형 특성을 사용할 수 있다.
일반적으로 이 유형은 다음과 같은 형식으로 정의된다.
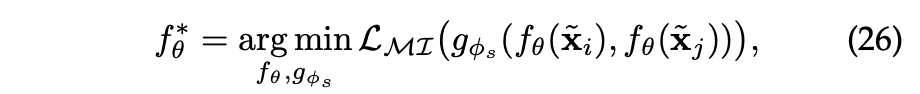
~와 ~는 위에서 설명한 feature augmentation 방식으로 입력 특성을 수정하거나 모델에서 학습한 특성 수준의 증강이다.
Model-Level Contrast
앞의 두 방식은 데이터 관점에서 self-supervised learning 신호를 추출하지만, 이들은 end-to-end 방식으로 구현되지 않았다.
또 다른 방식은 입력을 변경하기 않고 모델 아키텍처를 수정하여 필요할 때 뷰 쌍을 증강하는 것이다.
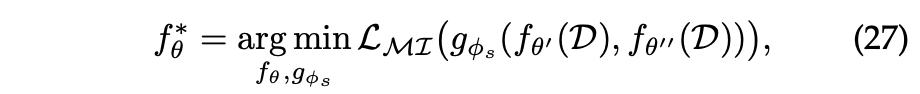
Contrastive Loss
contrastive loss의 최적화 목표는 두 표현 와 간의 상호 정보(Mutual information)를 최대화하는 것이다.
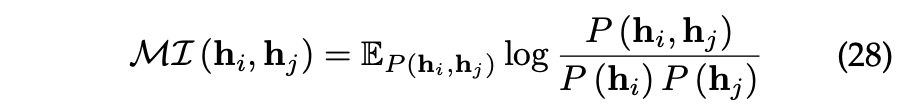
[참고] 상호 정보(MI) 정의와 최대화하는 이유
상호 정보는 두 확률 변수 간의 통계적 의존성을 측정하는 지표로, self-supervised learning에서는 데이터의 한 부분(샘플의 한 뷰)이 다른 부분(동일한 샘플의 다른 뷰)에 대해 얼마나 많은 정보를 제공하는지를 측정한다.
서로 다른 변수 간의 높은 MI는 모델이 입력 데이터의 다양한 특징 및 관계를 잡아내어 더 풍부한 표현을 학습할 수 있게 도와준다.
따라서 MI를 최대화하는 것은 모델이 두 변수 간의 의존성 및 상호 관계를 더 잘 이해하고 반영할 수 있도록 하는 목적이다.
하지만 MI를 직접 최대화하는 것은 어렵기 때문에 실질적인 방법은 그것의 lower bounds를 최대화하는 것이다.
이에 대해서는 두 가지 일반적으로 사용되는 lower bounds가 있다.
Jensen-Shannon Estimator
Jensen-Shannnon divergence(JSD)는 SSL에서 상호를 추정하는 데 사용되는 상호 정보 추정기 중 하나이다.
그래프 시나리오에서 널리 사용되며 다음과 같이 정의될 수 있다.
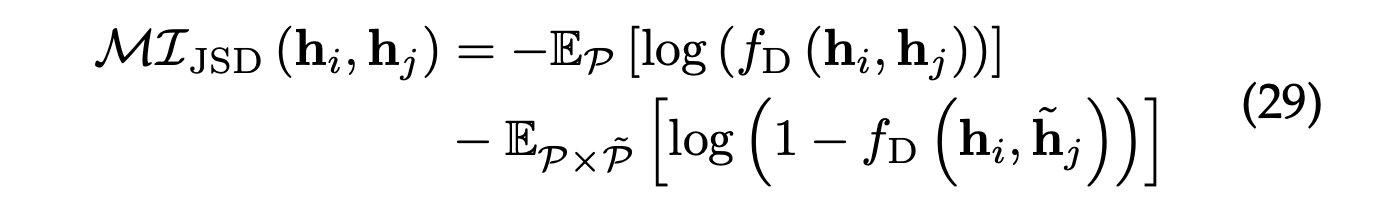
논문에서 제시된 바닐라 구현은 다음과 같은 bilinear scoreing function인
이며, dot-product 형태로도 사용된다.
JSD를 최대화하여 두 뷰 간의 상호 정보량을 효과적으로 최대화하며,이를 통해 모델은 데이터로부터 의미 있는 정보를 포착한다.
Noise-Contrastive Estimator
InfoNCE(information Noise Contrastive Estimation)은 NCE(Negative Contrastive Estimation)의 소프트맥스 기반 버전으로 사용하여 일련의 부정적인 샘플중에서 양성 샘플을 식별하는 방법이다.
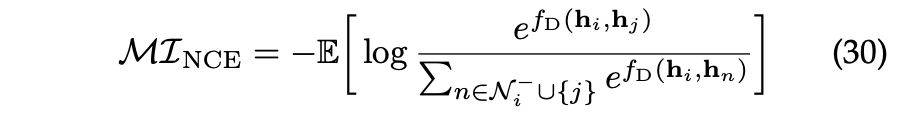
와 는 동일한 입력의 서로 다른 뷰로부터 얻은 임베딩이다.
는 두 표현 간의 유사성을 나타내는 점수이며, 는 부정적인 샘플의 수를 나타낸다.
이 손실은 양성 샘플의 확률을 최대화하고 동시에 부정적인 샘플과의 차이를 최소화하여 모델이 의미 있는 정보를 추출하도록 임베딩을 학습한다.
📖 GENERATIVE METHODS
Generative 접근 방식은 BERT와 같은 masked language models에서 영감을 받았다.
해당 방식의 모델은 자기 지도 학습 작업을 사용하여 사용자/아이템 프로필을 손상시킨 후 원래 사용자/아이템 프로필과 같아지도록 재구성하는 방향으로 훈련된다.
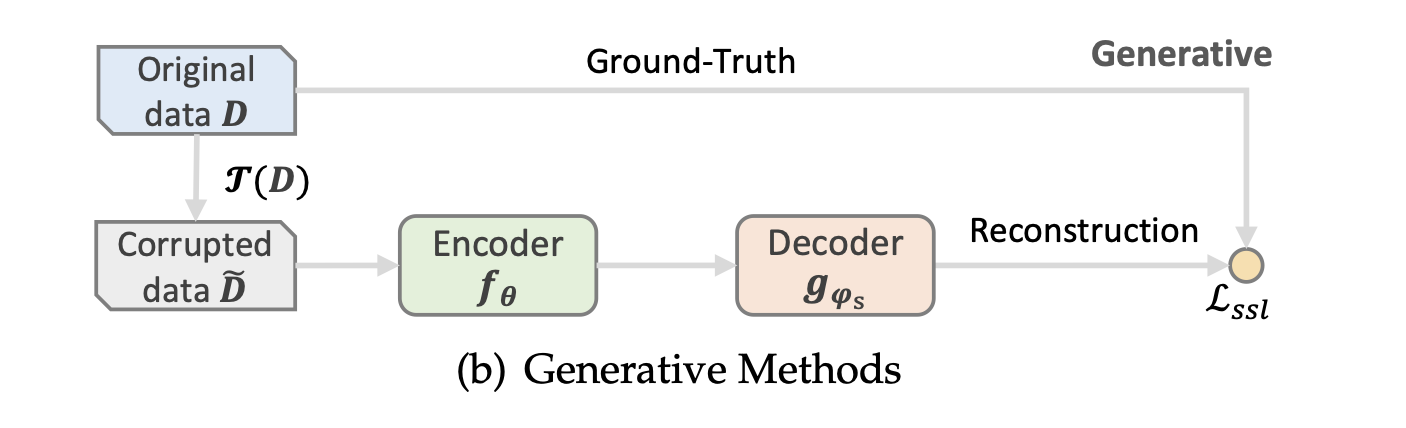
Generative 방식은 Structure Generation과 Feature Generation 두 방법으로 나뉜다.
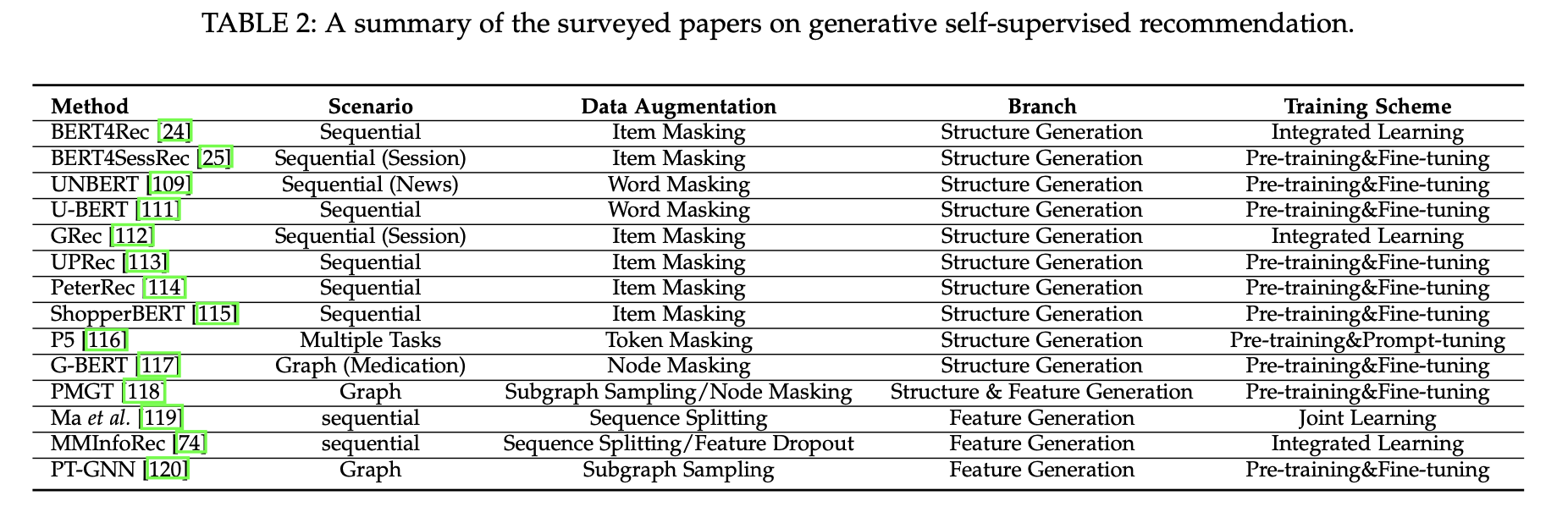
Structure Generation
Structure Generation 방식은 원래 구조에 마스킹/드롭아웃 기반의 증강 연산자를 적용하여 해당 구조의 손상된 버전을 얻는다.
시퀀스 기반 추천의 시나리오에서 구조를 복구하는 것은 다음과 같다.
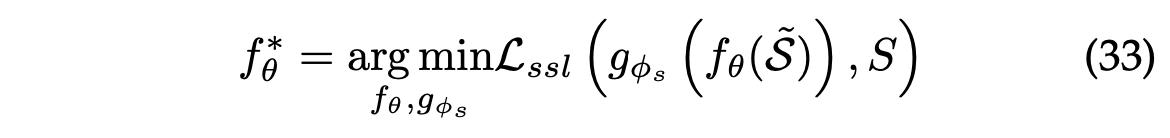
는 일부 아이템이 마스킹되어 있는(토큰 [mask]으로 대체) 손상된 시퀀스를 나타낸다.
Feature Generation
Feature Generation은 회귀 문제로 이해될 수 있으며 다음과 같다.
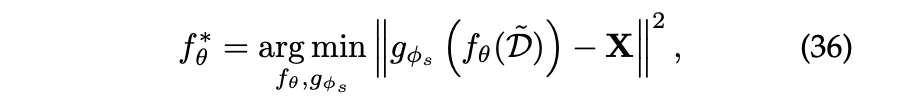
는 평균 제곱 오차 손싱을 나타내며, 는 사용자 프로필 속성, 아이템 텍스트 특성 또는 학습된 사용자/아이템 표현과 같은 일반적인 특성을 나타내는 기호이다.
📖 PREDICTIVE METHODS
Contrastive 및 Generative 방법이 주로 정적인 증강 연산자에 의존하는 것과 비교하여, Predictive 방법은 더 동적이고 유연한 방식으로 샘플과 의사 레이블을 얻는다.
샘플은 진화하는 모델 매개변수를 기반으로 예측되며, 이는 자체 지도 신호를 정제하고 최적화 목표와 일치시켜 추천 성능을 향상시킬 수 있다.
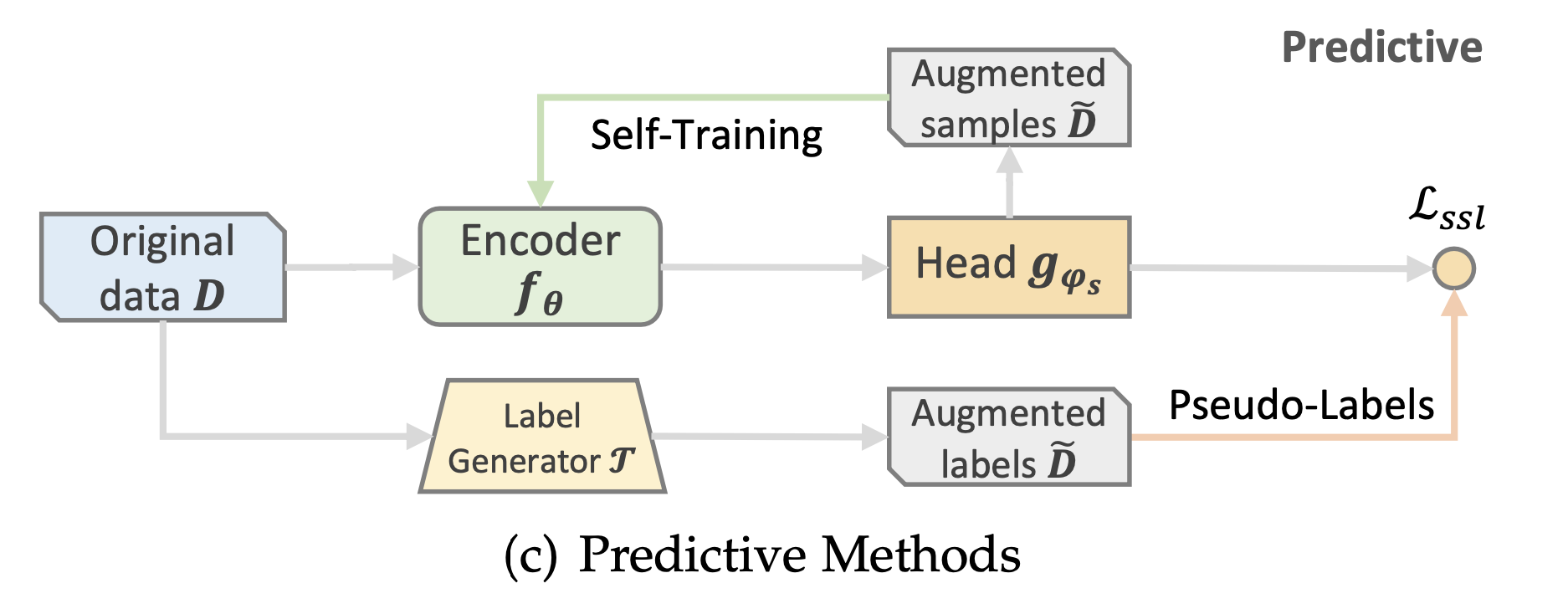
Predictive 접근 방식은 sample-based 방식과 Pseudo-label 기반 방식으로 나뉜다.
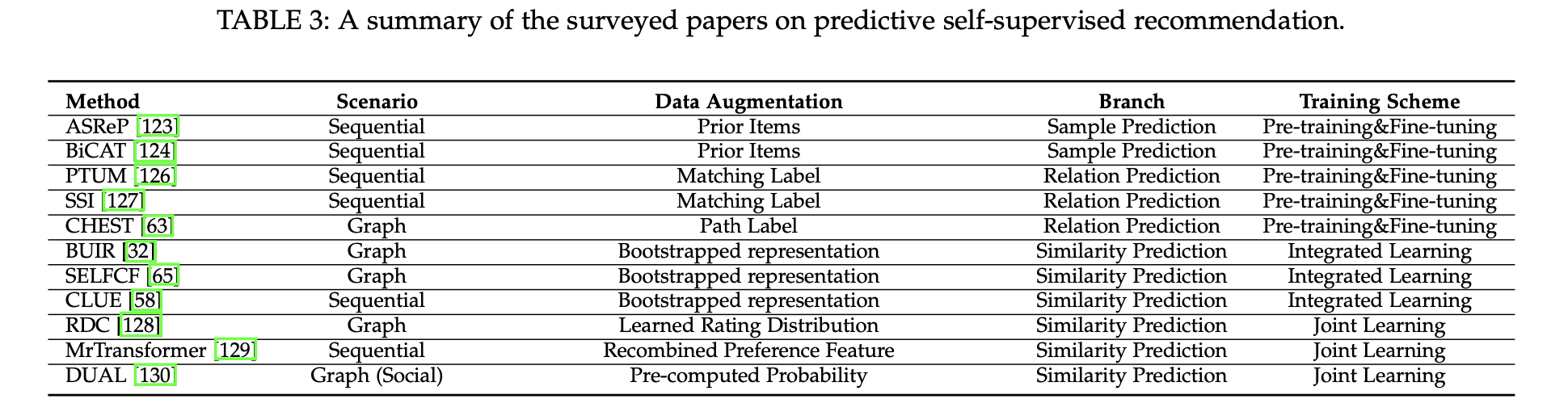
Sample Prediction
Sample prediction은 semi-supervised learning의 한 유형으로 self-supervised learning과 관련이 있다.
self-supervised learning 모델은 원본 데이터에서 사전 훈련되며, 추천 작업을 위한 잠재적으로 유용한 샘플은 사전 훈련된 매개변수를 사용하여 증강된 데이터로 예측된다.
semi-supervised learning 기반의 샘플 예측과 self-supervised learning 기반의 차이는 semi-supervised learning에서는 한정된 수의 미분류된 샘플이 사용가능한 반면, self-supervised learning에서는 샘플이 동적으로 생성된다.
Pseudo-Label Prediction
Pseudo-Label Prediction은 Relation Prediction과 Similarity Prediction으로 나뉜다.
Relation Prediction
Relation Prediction은 두 개체 간의 관계를 설명하며, 해당 관계가 존재하는지를 예측한다.
관계 예측 작업은 비용 없이 자체 생성된 가상의 레이블을 사용하는 분류 문제로 볼 수 있다.
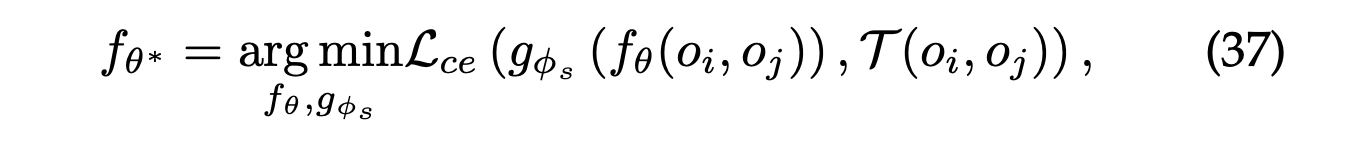
와 는 원본 데이터 에서 가져온 두 객체의 쌍이며, 는 클래스 레이블 생성기이다.
Similarity Prediction
Similarity Predcition은 사전 계산/학습된 연속값이 모델의 출력이 근사화해야 하는 대상으로 작용하는 회귀 문제로 제시될 수 있다.
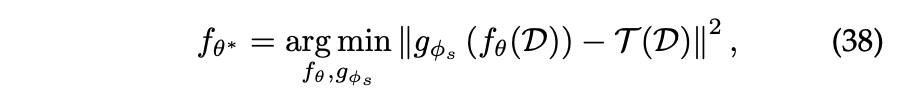
📖 HYBRID METHODS
Hybrid 방법은 다양한 self-supervised 신호를 활용하가 위해 여러 유형의 pretext task를 조합한다.
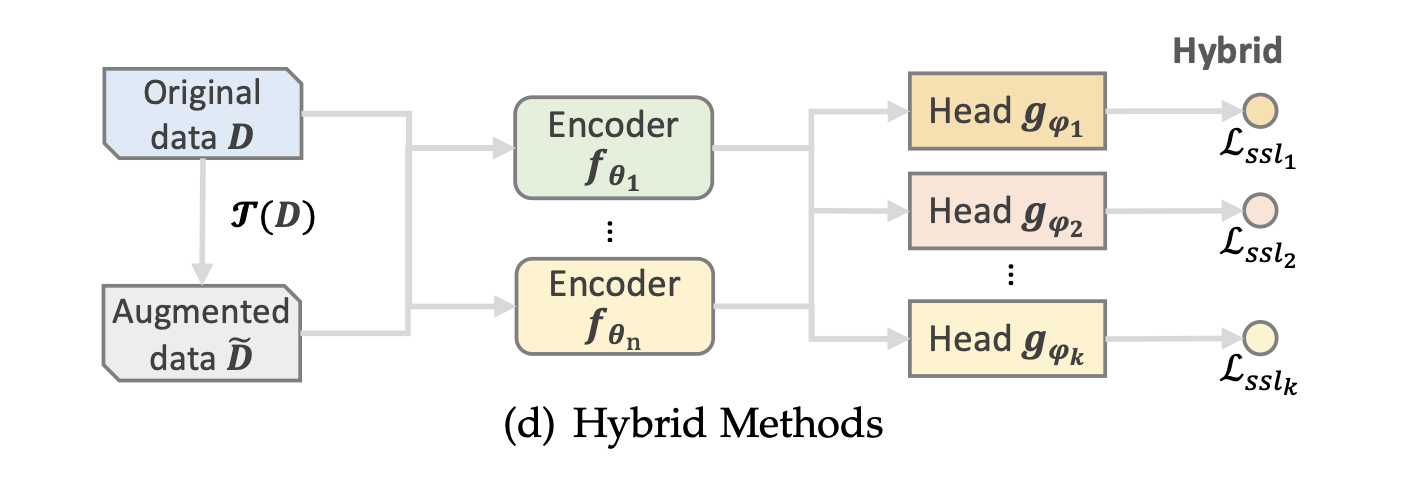
이러한 방식은 Collaborative self-supervision과 Parallel self-supervision으로 나뉜다.
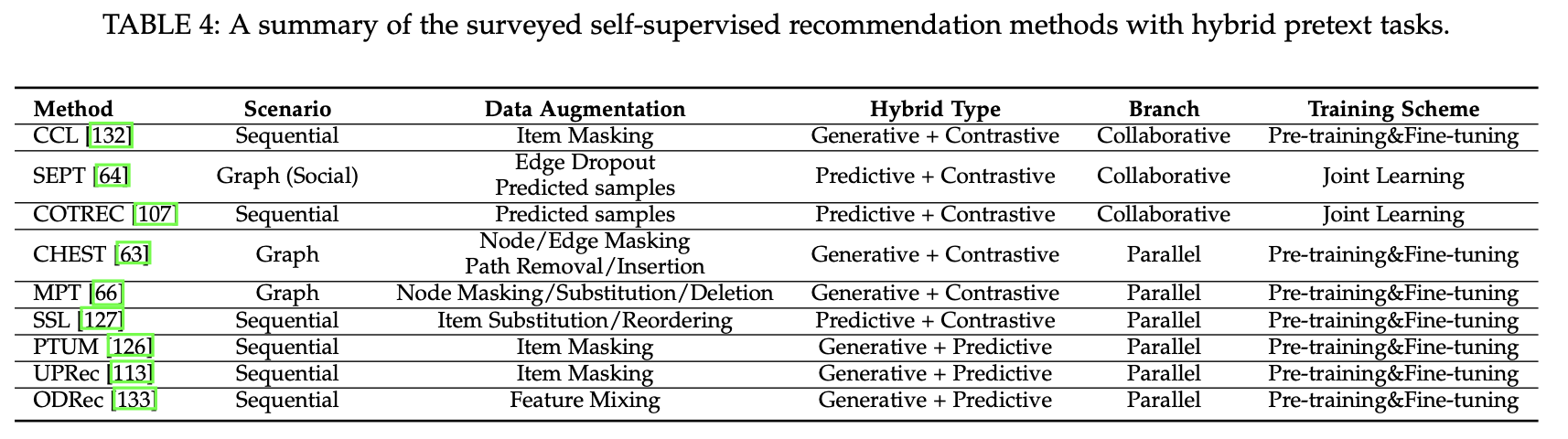
Collaborative Self-Supervision
Collaborative self-supervision은 종합적인 self-supervised 신호를 얻기 위해 여러 self-supervised 작업이 협력하여 대조적인 작업을 강화한다.
이를 통해 더 많은 정보를 제공하는 샘플을 생성한다.
Parallel Self-Supervision
Parallel self-supervision은 서로 다른 self-supervision task 간에 상관 관계가 없으며, 이들은 병렬로 작동한다.
📖 EXPERIMENTAL FINDINGS
여러 범주의 데이터 증강 기법 및 대표적인 self-supervised learning 모델들에 대한 비교 분석이 수행되었다.
엄격하고 의미있는 공정한 비교를 위해 백본으로 Light-GCN을 사용하는 그래프 기반 모델과 Transformer를 백본으로 사용하는 순차 모델이 선택되었다.
Comparison of Data Augmentations in CL
self-supervised learning 중 Contrastive 방식은 구조 수준, 특성 수준 및 모델 수준의 방법을 포함하여 다양한 데이터 증강 정근법이 있다.
다음 표의 결과를 기반으로 몇 가지 결론을 도출했다.
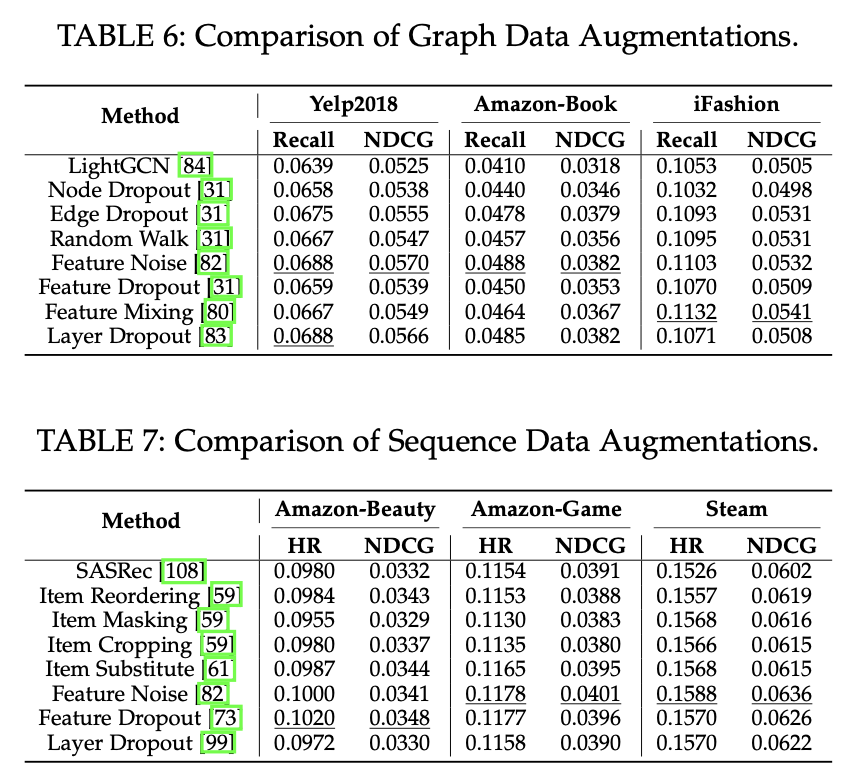
- 두 시나리오에서 특성 수준의 증강이 매우 효과적임을 보인다. 특히 특성에 노이즈를 추가하는 것이 평균적으로 가장 큰 개선을 가져온다.
- 구조 수준의 증강은 희소한 데이터셋에 대해 효과적이지 않을 뿐만 아니라 순차적인 시나리오에서는 성능 저하로 이어질 수 있다. 그러나 더 밀집한 데이터셋에서는 성능에 긍정적인 기여를 할 수 있다.
- 모델 수준의 증강 효과는 다양한 데이터셋에서 다르다. 일부 데이터셋은 상당한 향상을 보이지만, 나머지 데이터셋은 미미한 향상을 보인다.
- 순차 대조적 self-supervised learning의 경우 그래프에 비해 효과적이지 않다. 이에 대한 하나의 가능한 이유는 항목 간 전이 사이에 명확한 의미가 부족하며, 이는 Transformer 구조의 잠재력을 제한할 수 있다.
Comparison of SSR Models
self-supervised learning에서 가장 효과적인 패러다임을 식별하기 위해 그래프 및 순차적 시나리오에서 여러 인기 있는 모델을 비교했다.
다음 표의 결과를 기반으로 몇 가지 결론을 도출했다.
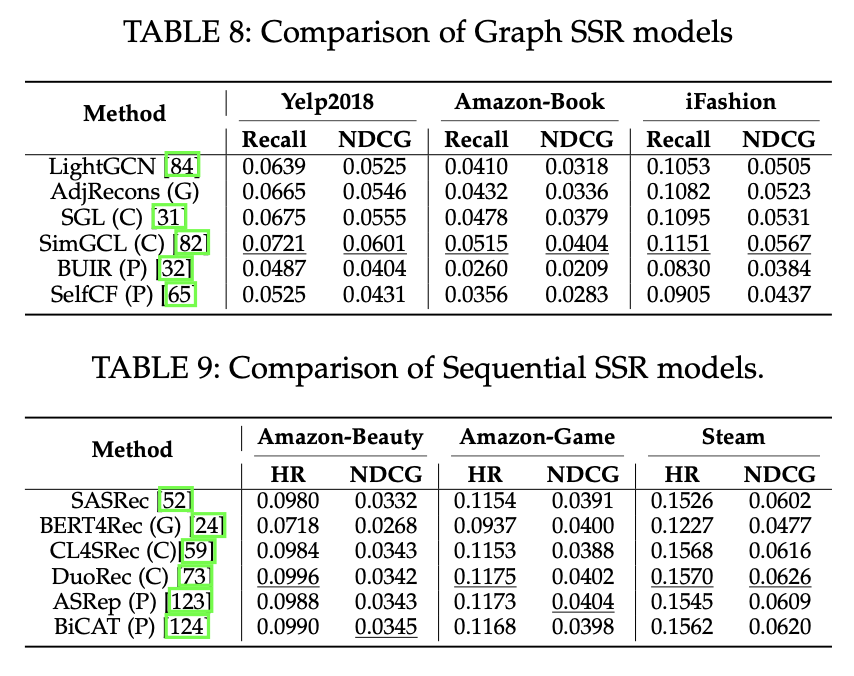
- 그래프 시나리오에서 Contrastive 방식이 뛰어난 추천 성능을 보여준다. 반면, Predictive 방식은 실망스러운 결과를 보이며 성능을 현저하게 낮추기도 한다. Generative 방식은 위 두 가지 방식 사이의 성능으로 개선을 이뤄냈음을 보인다.
- 순차적 시나리오에서 Contrastive 방식과 Predictive 방식이 유사한 성능 향상을 보이는 반면, Generative 방식은 실망스러운 결과를 보인다.
- 그래프 시나리오에서의 self-supervised learning 방법과 비교하여 순차적 시나리오에서의 self-supervised learning 방법은 개선의 여지가 있다.
📖 CONCLUSION
본 서베이 논문은 추천에 적용되는 Self-Supervised Learning을 정의하고 분류함으로써 체계적으로 접근할 수 있도록 도와주었다.
Self-Supervised Learning 방법론 중 Contrastive Learning 방식이 그래프에서 효과적인 성능 개선을 보인다는 실험 결과는 23년 진행한 여러 학회에서 관련된 논문들이 많이 출간된 이유를 뒷받침해주는 것 같아 이에 대한 모델을 공부하고싶다는 생각이 든다.
Reference
