📌 KGAT: Knowledge Graph Attention Network for Recommendation
📖 ABSTRACT
본 논문은 정확하고 설명 가능한 추천을 위해 사용자-아이템 상호작용 모델링과 부가 정보를 함께 고려해야 한다고 주장한다.
기존의 Factorization Machine과 같은 전통적인 방법들 또한 부가 정보를 담으려 했지만 이를 지도 학습 문제로 취급하여 각 상호작용을 독립적인 인스턴스로 가정했기에 협력 신호를 추출하는 데 제한이 있었다.
본 논문은 이를 해결하기 위해 Knowledge Graph을 사용하며, 주변 노드의 중요성을 구별하기 위해 어텐션 메커니즘을 사용한다.
결과적으로 본 눈문에서 제안한 모델 KGAT는 SOTA 모델의 성능을 능가함을 보인다.
📖 INTRODUCTION
CF & SL 방법 한계점
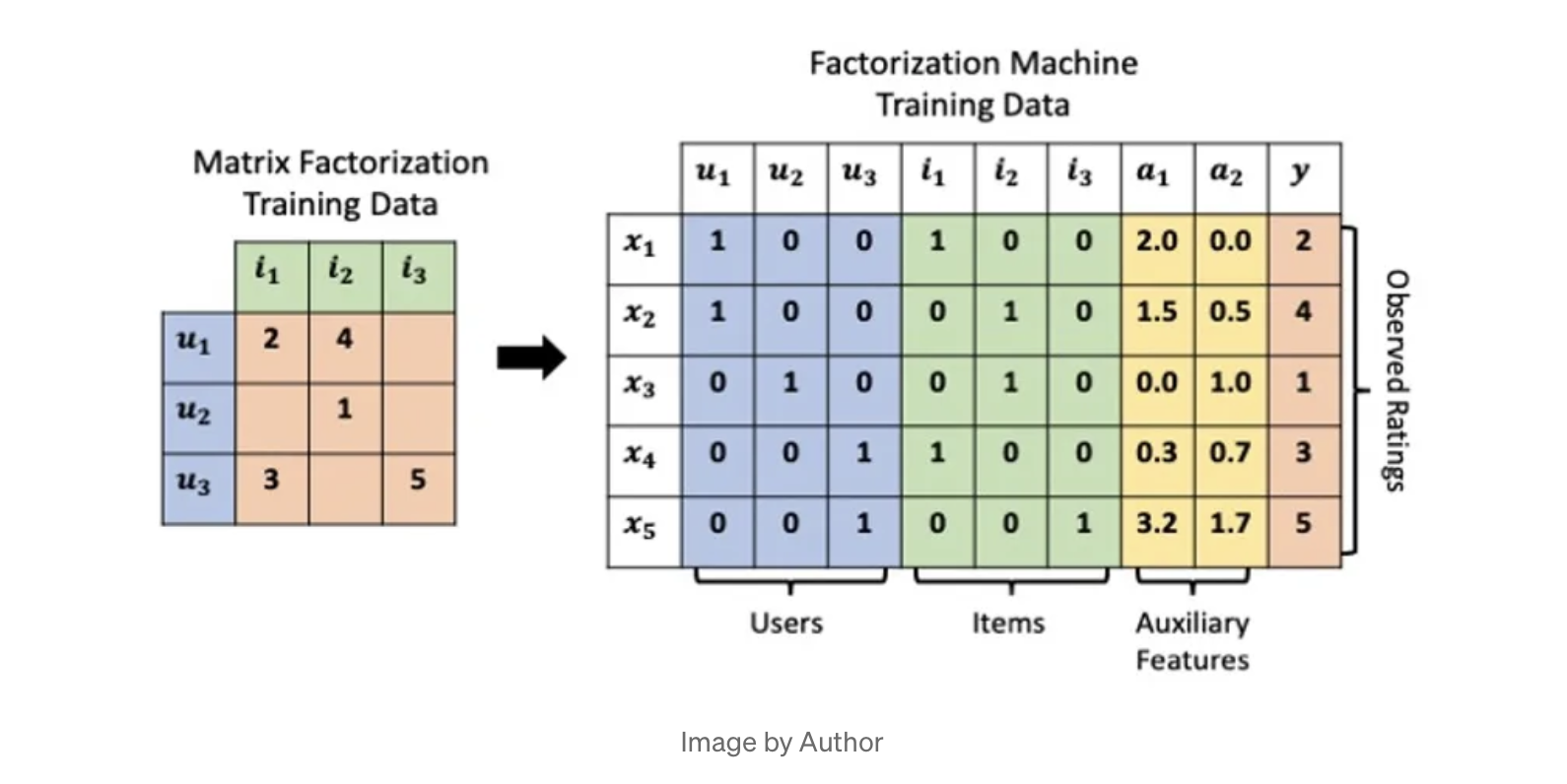
위 그림은 Factorization Machine의 Training Data로 각 상호작용이 독립적인 데이터 인스턴스로 되어 있음을 보인다.
앞서 말했듯이 전통적인 방법들은 위와 같은 방식으로 상호작용간의 관계를 고려하지 못한다는 한계점이 있다.
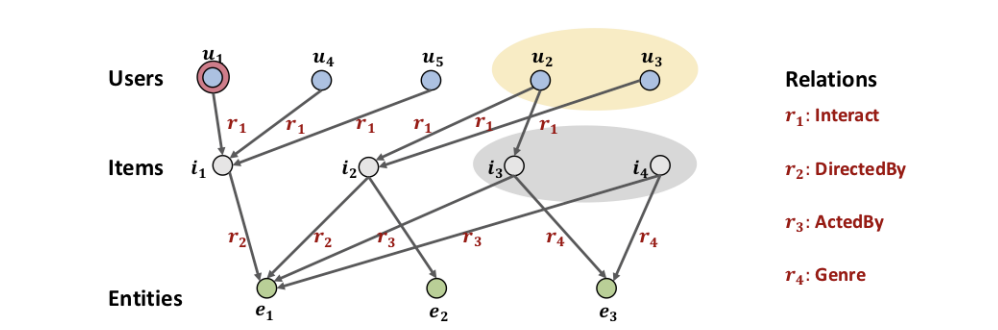
위 그림을 통해 CF와 SL의 한계점을 구체적으로 설명한다.
사용자 은 감독 이 제작한 영화 을 봤다는 상호작용이 있다.
- collaborative filltering의 경우 위 상호작용을 고려하여 영화 을 시청한 사용자인 와 의 관람 이력에 중점을 둔다.
- supervised learning model의 경우 감독 이 제작한 또 다른 영화인 를 제안한다.
결과적으로 두 방법론은 감독 이 제작한 또 다른 영화를 시청한 노란 원 안의 사용자들을 고려하지 못할 뿐더러 감독 이 출현한 즉, 다른 관계로 형성된 영화들인 회색 원 안의 영화와 같은 고차 연결성을 고려하지 못한다는 한계점을 지닌다.
본 논문은 앞서 말한 한계를 해결하는 방안으로 고차 연결성을 활용할 수 있는 지식 그래프를 사용한다.
고차 연결성의 예시는 다음과 같으며, 각각 노란 원과 회색 원으로 이동하는 방법을 나타낸다.
다만 이러한 고차 정보를 활용하는 데 있어 몇가지 해결해야 할 문제가 있다.
- 대상 사용자와 고차 관계를 가진 노드의 수는 차수의 크기에 따라 기하 급수적으로 증가하며, 이는 모델의 계산 부하를 증가시킨다.
- 고차 관계는 예측에 차등적으로 기여하기에 각각의 가중치를 부여해야 한다.
기존 협업 지식 그래프(CKG) 활용 한계점
1. Path-based methods
경로 기반 방법은 고차 경로를 추출하여 예측 모델에 입력하는 방식이다.
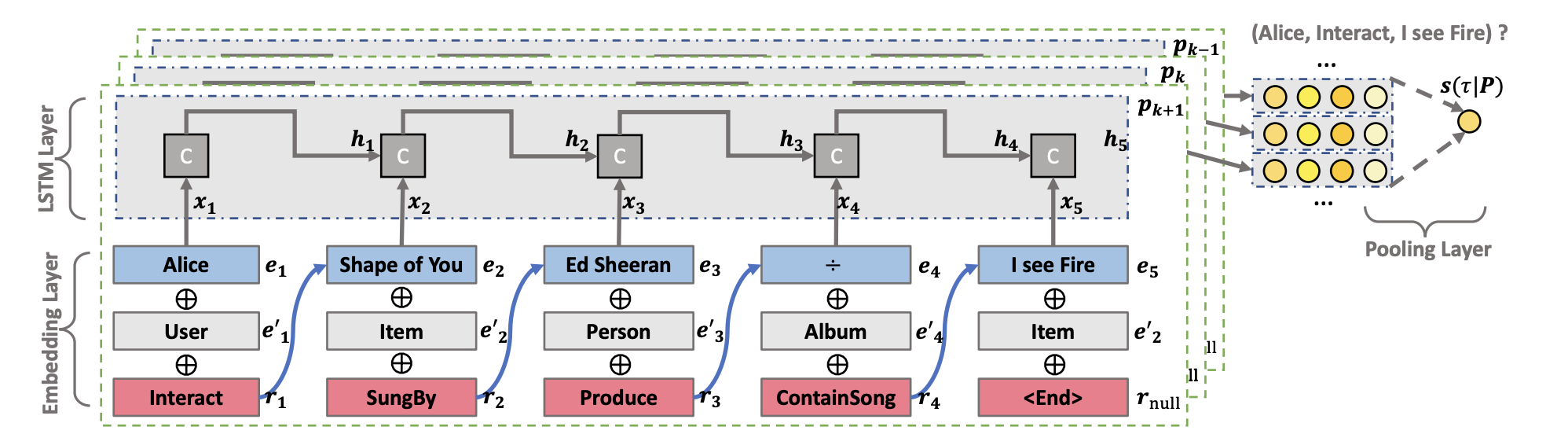
위 그림은 Explainable Reasoning over Knowledge Graphs for Recommendation 논문의 모델로 Path-based methods에 속한다.
하지만 경로 기반 방법은 다음의 몇가지 한계점을 갖는다.
- 경로 선택이 최종 성능에 큰 영향을 미치지만, 현재 경로 선택 방법론들은 추천 목표에 최적화되어 있지 않다.
- 효과적인 meta-path를 정의하기 위해서는 도메인 지식이 요구되며, 복잡한 KG의 경우 많은 meta-path를 정의해야 할 수 있어 노동 집약적이다.
2. Regularization-baed methods
정규화 기반 방법은 추천 모델 학습을 창안하기 위해 KG 구조를 캡처하는 추가 손실 항목을 고안한다.
위 그림의 방법들은 공유 항목 임베딩을 사용하여 추천 및 KG 완성 두 작업을 동시에 학습한다.
다만 이러한 방법들은 고차 관계를 직접적으로 추천 최적화된 모델에 통합하는 대신 암묵적으로만 인코딩한다는 점에서 장거리 연결성을 보장하지 않아 고차 모델링 결과에 대한 해석이 불가능하다는 한계점을 갖는다.
KGAT
본 논문에서 제안하는 모델 Knowledge Graph Attention Network(KGAT)는 지식 그래프에서 고차 정보를 효율적이고 명시적이며 end-to-end 방식으로 활용할 수 있다고 한다.
KGAT는 고차 관계 모델링에 대한 문제를 해결하기 위해 다음 두가지를 활용한다.
- 재귀적 임베딩 전파 : 노드의 임베딩을 이웃들의 임베딩을 기반으로 업데이트하고, 이러한 임베딩 전파를 재귀적으로 수행하여 선형 시간 복잡도에서 고차 연결성을 포착한다.
- 어텐션 기반 집계 : 뉴럴 어텐션 메커니즘을 사용하여 전파 중에 각 이웃의 가중치를 학습하며, 이를 통해 연속적인 전파의 언텐션 가중치는 고차 연결성의 중요성을 나타낸다.
KGAT는 다음과 같으면 면에서 기존 방법에 비해 우수한다고 한다.
- Path-based method와 비교했을 때 경로를 명시화하는 과정을 피하므로 효율적이고 편리하게 사용할 수 있다.
- Regularization-based와 비교했을 때 고차 관계를 직접적으로 예측 모델에 결합하여 모든 관련 매개변수가 추천 목표를 최적화하기 위해 맞춤 설정된다.
📖 METHODOLOGY
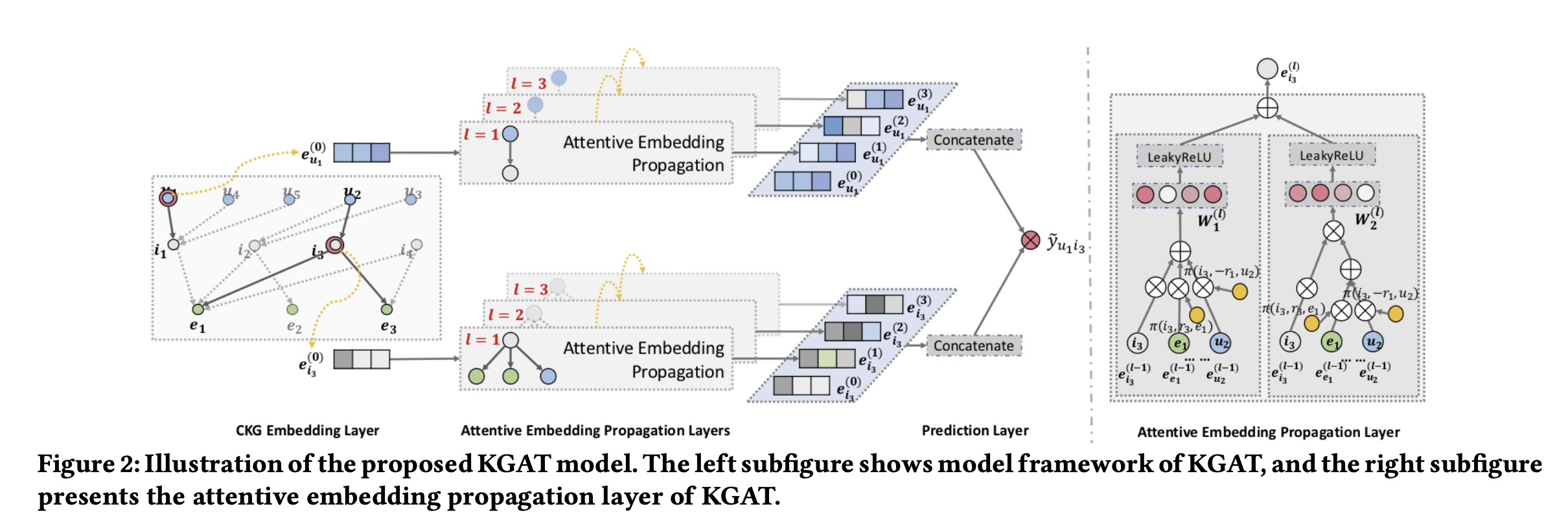
1. Embedding Layer
본 논문에서 제안하는 모델에서는 TransR 방법을 이용해 지식 그래프를 임베딩한다.
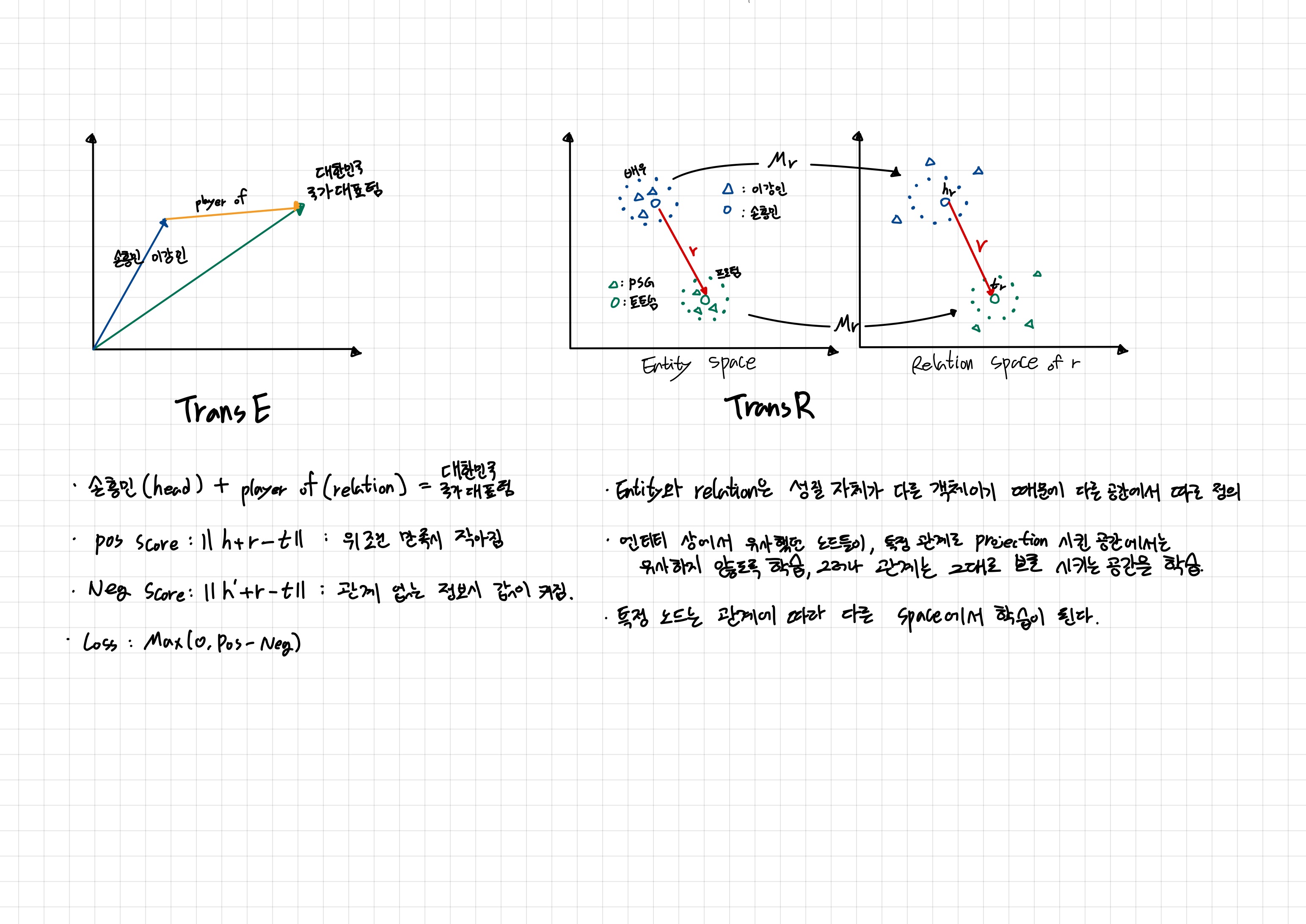
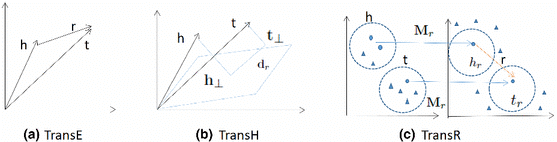
위 설명은 TransE와 TransR에 대한 내용이다.
기존의 TransE 방식은 head와 relation 그리고 tail을 효과적으로 embedding하는 데 한계가 있다.
예를 들어 손흥민과 이강인 두 선수 모두 대한민국 국가대표 팀의 선수들이라는 것은 사실이며 이를 embedding 했을 때 tail을 변형 할 경우 오류가 발생할 수 있게 된다.
만약 tail이 대한민국 국가대표 팀이 아닌 토트넘으로 변경할 경우 head 부분의 손흥민은 embedding 결과가 일치하겠지만 이강인은 사실과는 다른 embedding 결과가 될 것이다.
TransR은 head와 tail을 변환 행렬을 이용하여 다른 공간에서 바라봄으로써 이 문제를 해결한다.
관계를 그대로 보존 시키는 방향으로 각 엔티티를 재정의함으로써 TransE의 한계점을 해결한다.
다만 노드는 각 관계에 따라 다른 변환 행렬을 사용하여 embedding을 정의하는 방식으로 학습을 진행한다.
수식으로 표현하면 다음과 같다.
: head의 embedding
: relation의 embedding
: tail의 embedding
: relation 의 변환 행렬
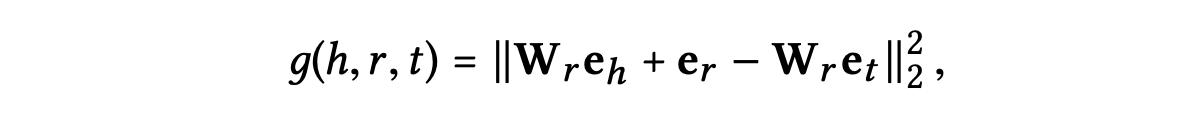
TransR의 학습은 올바른 트리플렛과 잘못된 트리플렛간의 상대적인 순서를 고려하는 pairwise ranking loss를 통해 이루어진다.
손상된 트리플렛 은 올바른 트리플렛 에서 한 엔터티를 무작위로 바꾸어 생성한다.
수식으로 표현하면 다음과 같다.
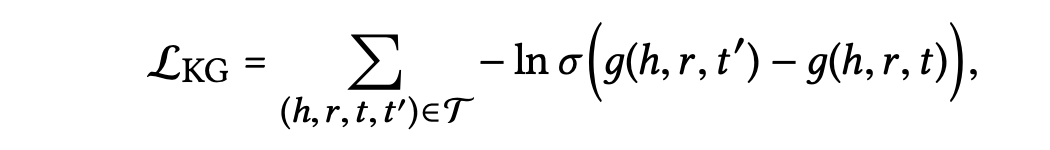
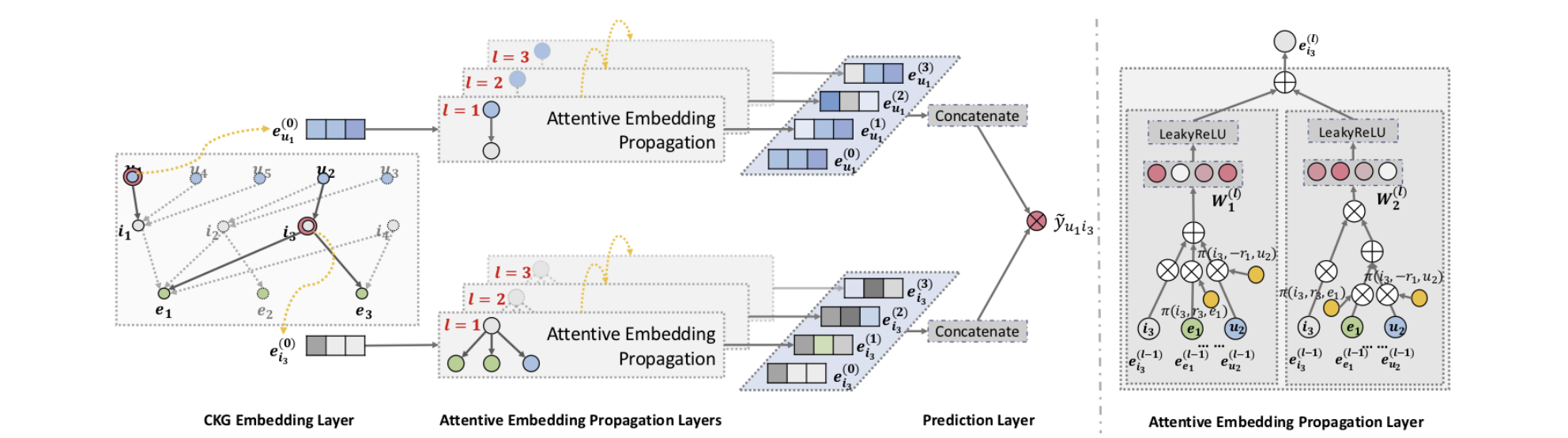
2. Attentive Embedding Propagation Layers
Attentive Embedding Propagation Layers는 세 가지 구성 요소로 이루어진 단일 계층이다.
Information Propagation
엔터티 의 1차 연결성 구조를 특성화하기 위해 자신 네트워크의 선형 결합을 계산하면 다음과 같다.
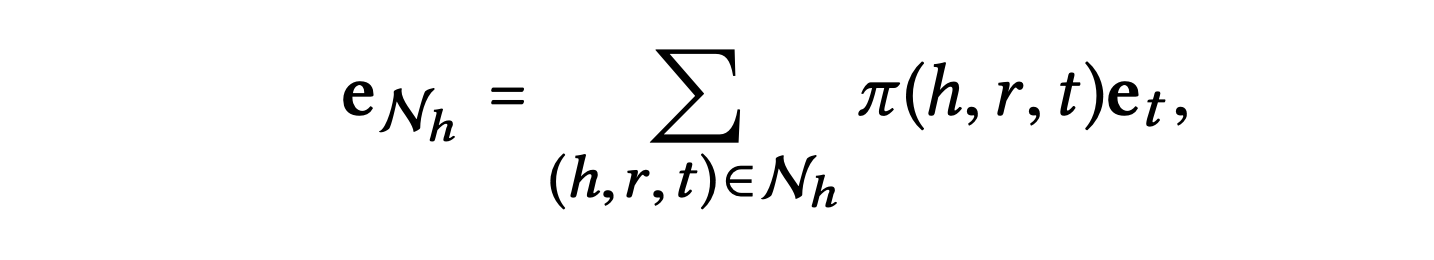
는 에지에서 각 전파에 대한 감쇠 요소를 제어한다.
Knowledge-aware Attention
앞에서 언급한 는 다음과 같이 relational attention mechanism을 통해 구현된다.
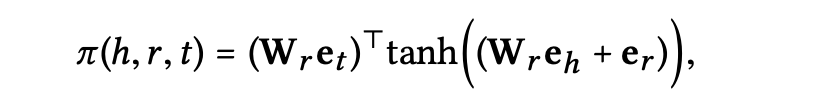
비선형 활성화 함수 은 의 공간에서 와 간의 거리가 더 가까운 엔터티에 대해 더 큰 attention score를 주어 더 많은 정보를 전파하게 한다.
이후 와 관련된 모든 트리플렛에 대해 계수를 정규화하기 위해 소프트맥스 함수를 사용한다.
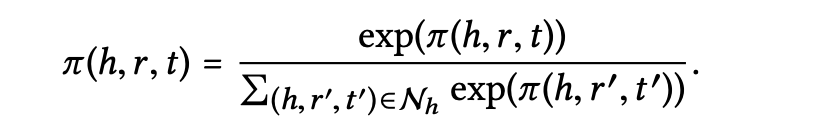
결과적으로 최종 attention score는 다음의 그림과 같이 협업 신호를 포착하기 위해 어떤 이웃 노드에 더 많은 주의를 기울여야 하는지를 제안할 수 있게 된다.
Information Aggregation:
최종 단계는 엔터티의 표현 와 네트워크의 표현 를 새로운 엔터티 h의 표현으로 집계한다.
는 세 가지 유형의 집계기를 사용한다.
- GCN Aggregator : 두 표현을 더하고 비선형 변환을 적용한다.
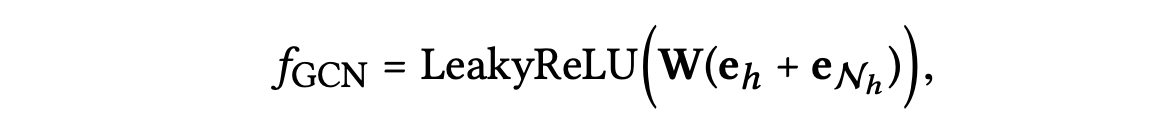
-
GraphSAGE Aggregator : 두 표현을 연결하고 비선형 변환을 적용한다.
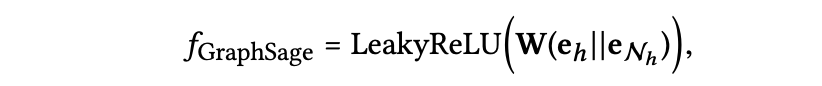
-
Bi-Interaction Aggregator : 와 사이의 두 가지 특성 상호 작용을 고려한다.
High-order Propagation
더 많은 전파 계층을 쌓아 고차원 연결성 정보를 활용할 수 있다.
-번째 단계에서 엔터티의 표현을 재귀적으로 다음과 같이 정의한다.
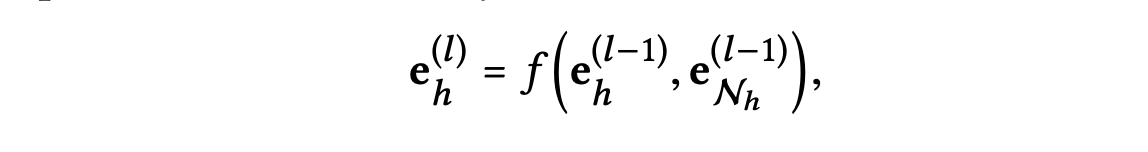
-번째 이웃 네트워크에 대한 정보를 포함하는 -번째 레이어의 엔터티 의 표현은 다음과 같이 정의한다.
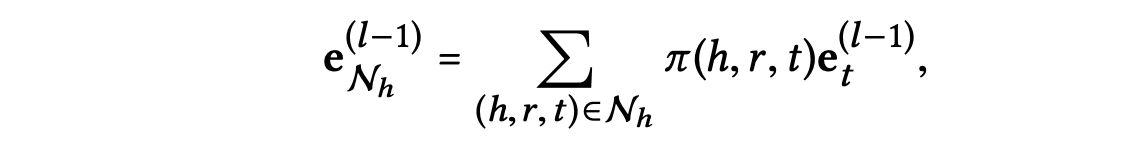
📖 Model Prediction
개의 레이어를 수행한 후에는 사용자 노드 에 대한 여러 표현 즉 {}를 얻는다.
비슷하게 아이템 노드 i에 대해서도 {}를 얻는다.
서로 다른 출력은 서로 다른 차수의 연결성 정보를 나타내며 각 단계에서의 표현을 단일 벡터로 연결한다.
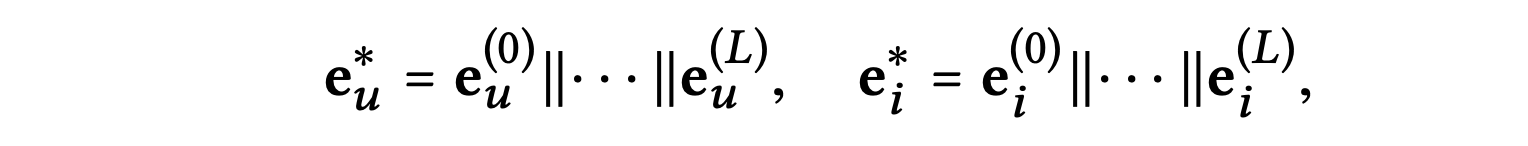
마지막으로 사용자와 아이템 표현의 내적을 수행하여 매칭 점수를 예측한다.
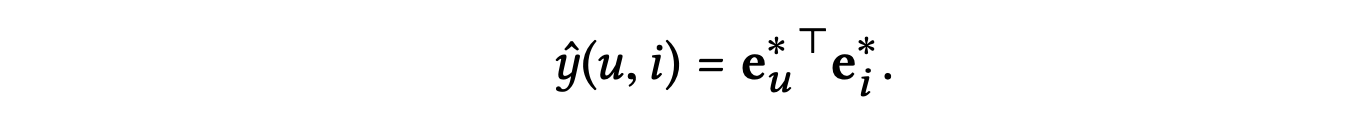
📖 Optimization
추천 모델을 최적화 하기 위해 BPR loss를 사용한다.
구체적으로는 관측된 상호작용은 더 많은 사용자 선호도를 나타내므로 이러한 관측된 상호작용에 대한 예측 값이 관측되지 않은 것들보다 높아야 한다고 가정한다.
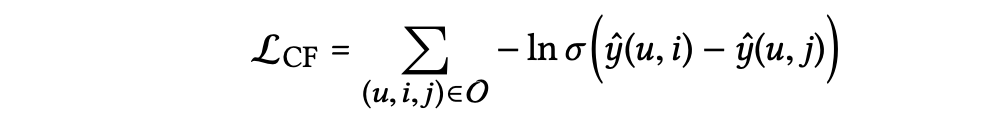
앞서 Embedding Layer의 목적함수와 결합하면 다음과 같다.
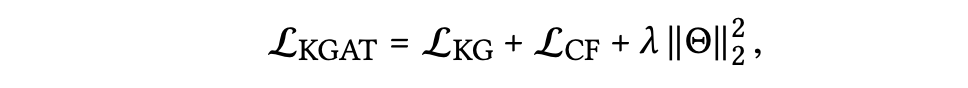
📖 EXPERIMENTS
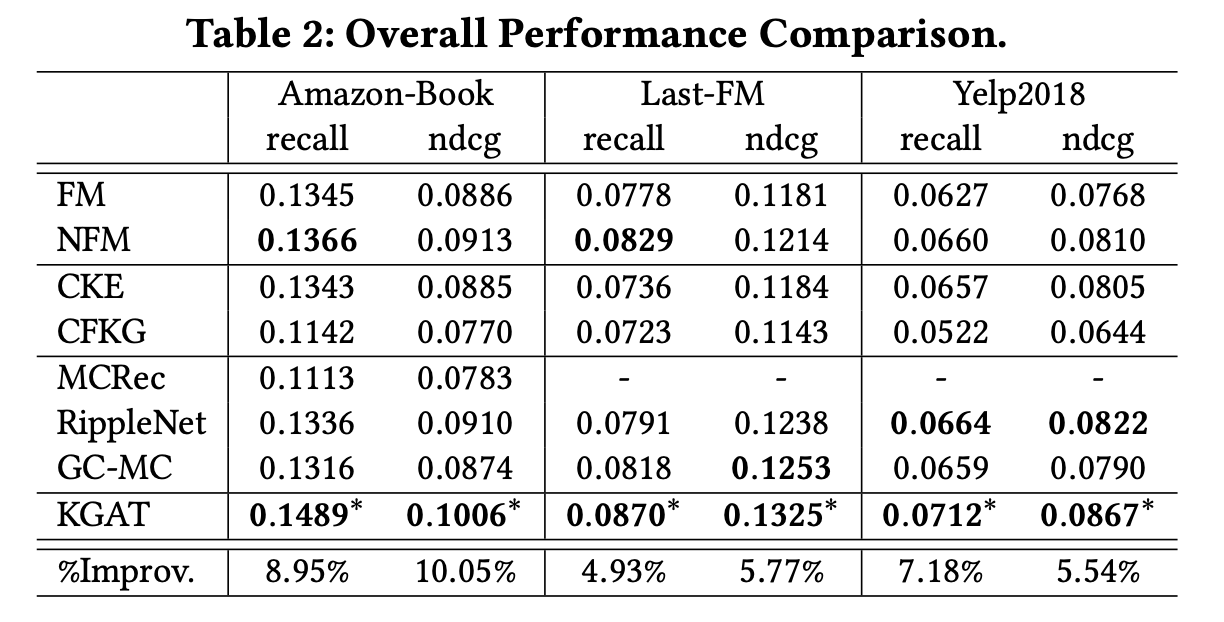
Q1. Performance Comparison
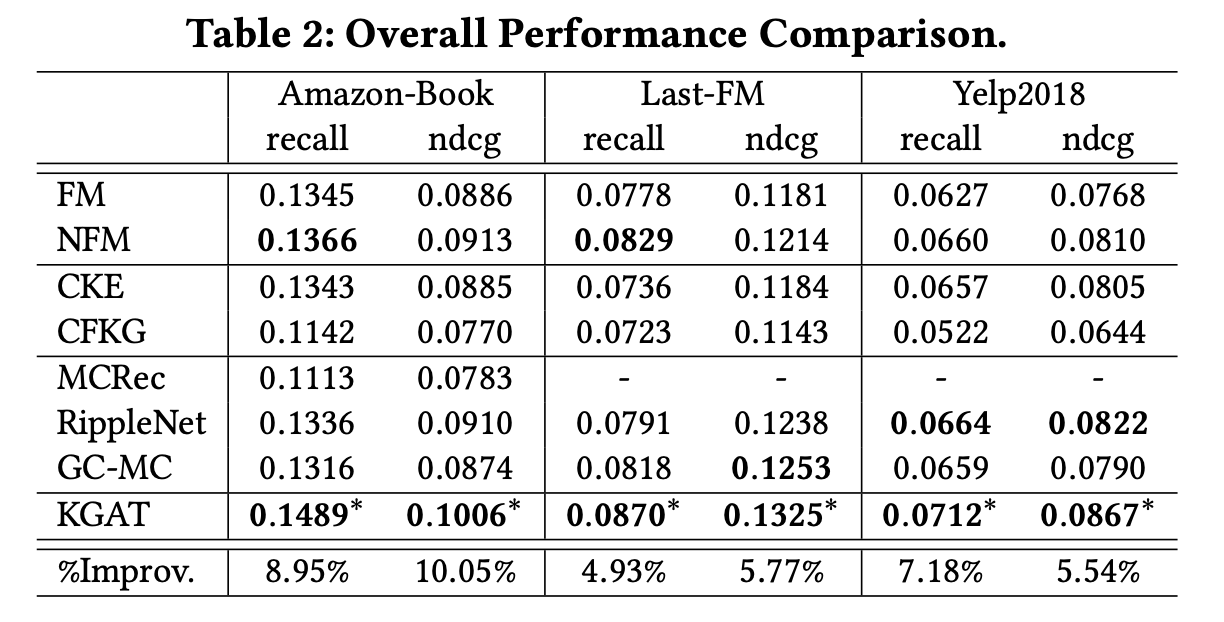
KGAT 모델은 SOTA 모델들과 비교했을 때 모든 데이터셋에서 일관되게 가장 우수한 성능을 발휘한다.
Q2. Study of KGAT
1. Effect of Model Depth
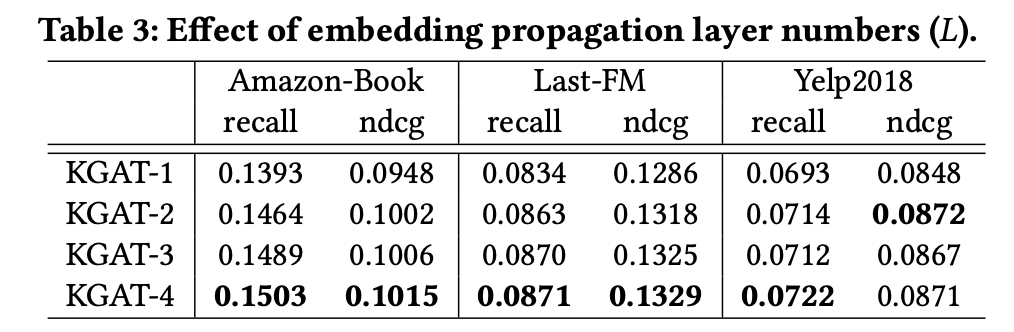
표는 KGAT 모델의 깊이를 변화시켜 여러 임베딩 전파 레이어의 효율성을 보인다.
깊이를 늘릴수록 성능이 향상됨을 알 수 있다.
다만 네 번째 부터는 소폭의 향상을 달성함에 따라 엔터티 간의 세 번째 차수 관계까지를 고려하는 것이 협력 신호를 포착하는 데 충분할 수 있음을 알 수 있다.
2. Effect of Aggregators
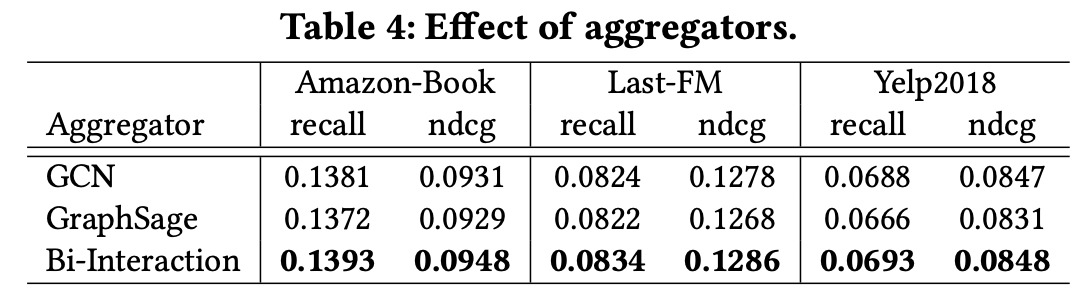
앞서 설명했듯이 KGAT는 다양한 집계기의 설정을 고려한다.
그 중 Bi-Interaction 집계 방식의 성능이 가장 우수함을 보인다.
3. Effect of Knowledge Graph Embedding and Attention Mechanism
지식 그래프 임베딩과 Attention Mechanism의 영향을 확인하기 위해 KGAT-1의 세 가지 변형을 고려한다.
- w/o K&A : 아래 두 구성요소 모두 제거
- w/o KGE : KGAT의 TransR 임베딩 구성 요소를 비활성화
- w/o Att : Attention Mechanism을 비활성화하고 를 로 설정
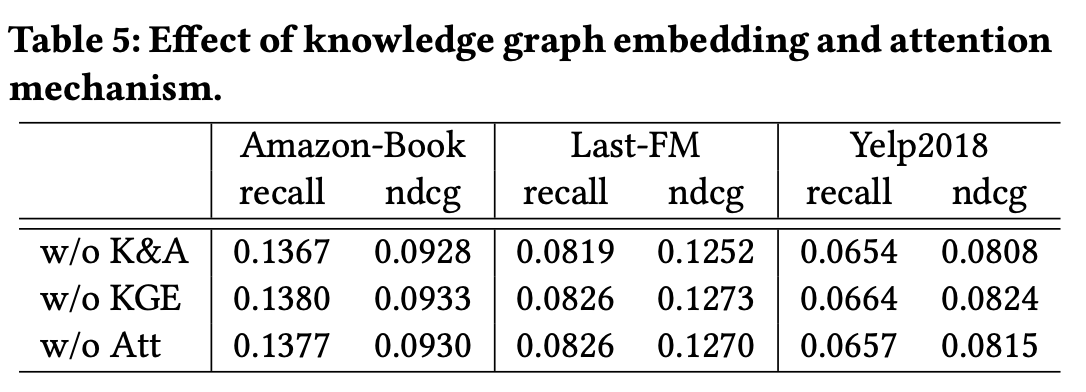
표를 통해 지식 그래프 임베딩 및 attention mechanism을 제거하면 모델의 성능이 저하됨을 알 수 있다.
Q3. Case Study
KGAT 모델은 다음 그림과 같이 Attention Mechanism을 통해 고차원 연결성을 추론에 활용하여 대상 항목에 대한 사용자 선호도를 추측하고 설명을 제공할 수 있다고 한다.
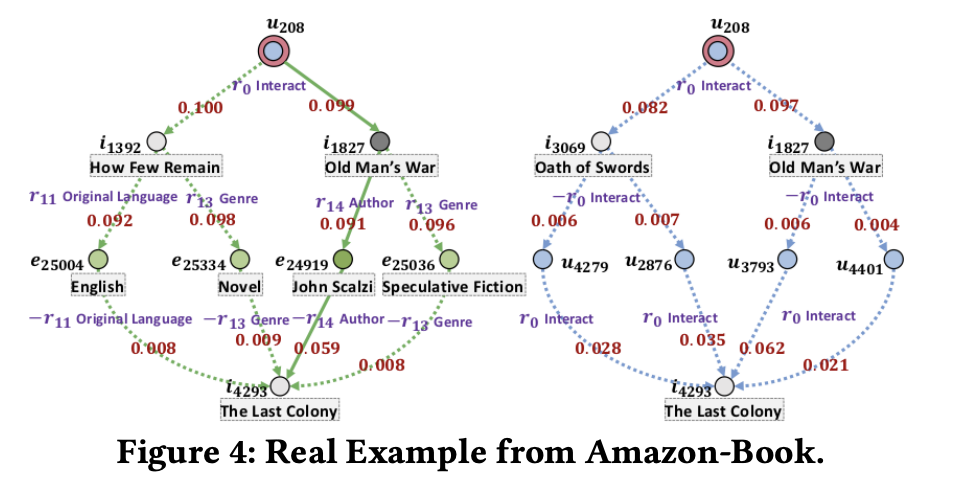
📖 CONCLUSION AND FUTURE WORK
KGAT 모델은 CKG의 고차원 연결성을 end-to-end 방식으로 모델링하여 세가지 실제 데이터셋에서 우수한 성능을 보인다.
핵심은 TransR을 활용한 embedding 방식과 attention mechanism 구조의 활용이다.
향후 연구 방향으로는 소셜 네트워크와 CKG를 통합하여 소셜 영향이 추천에 미치는 영향을 조사하고, 정보 전파와 의사 결정 프로세스를 통합하여 설명 가능한 추천에 대한 연구를 확장할 수 있다고 한다.
Reference
KGAT: Knowledge Graph Attention Network for Recommendation
[Paper Review] Knowledge Graph Attention Network (KGAT)
Factorization Machine image
Embedding based 방법론
