from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from sklearn import svm
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.metrics import confusion_matrixKEY를 통해 불러온 손글씨파일을 확인한다.
#key를 통해 내용확인
cancer = load_breast_cancer()
print(cancer.keys())dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
유방암 데이터에는 30개의 변수(특징)이 있고 총 569개의 데이터(행)가 있다.
#feature를 저장
cancer_data = cancer.data
print(cancer_data.shape)(569, 30)
유방암 데이터를 잘 불러온 모습이다.
#feature데이터의 0번째 데이터의 숫자 확인
cancer_data[0]array([1.799e+01, 1.038e+01, 1.228e+02, 1.001e+03, 1.184e-01, 2.776e-01,
3.001e-01, 1.471e-01, 2.419e-01, 7.871e-02, 1.095e+00, 9.053e-01,
8.589e+00, 1.534e+02, 6.399e-03, 4.904e-02, 5.373e-02, 1.587e-02,
3.003e-02, 6.193e-03, 2.538e+01, 1.733e+01, 1.846e+02, 2.019e+03,
1.622e-01, 6.656e-01, 7.119e-01, 2.654e-01, 4.601e-01, 1.189e-01])
데이터가 569개의 행을 가지고 있으므로 라벨 또한 569행을 가지고 있다.
#라벨 저장
cancer_label = cancer.target
print(cancer_label.shape)(569,)
#라벨이 들어가 있는 모양 확인
cancer_label[0:20]array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1])
라벨은 2가지 종류가 있다. 여기서는 암이 있다, 없다로 분류 한다
#라벨들의 종류를 확인
cancer.target_namesarray(['malignant', 'benign'], dtype='<U9')
모델에 적용하기 전에 유방암 데이터는 어떤 오차행렬을 사용하는 것이 좋을까?
우리가 환자의 암이 있는지 없는지 진단을 하는 상황이라고 생각해보자, 암이 없는데 있다고 판단을 하고 종합검사를 받는 것은 큰문제가 되지 않는다. 종합검사 이후 암이 없다고 판단하면 되기 때문이다. 하지만 암이 있는데 없다고 판단하는 경우는 어떨까? 종합검사도 시행하지 않을 확률이 있으며 암이 있지만 없다고 모르는채 지내다가 암의 크기만 커질 뿐이다. 그럼 우리는 오차행렬 중에 어떤 값을 사용하는 것이 좋은 것일까? 정답은 바로 recall값이다. 민감도 라고도 한다. 암이 있지만 없다고 판단한 경우의 민감도를 파악하는 것이다.
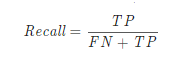
train test를 분리하여 모델에 적용하기 위해 split을 진행한다.
#train데이터롸 test데이터를 위해 split하기
X_train, X_test, y_train, y_test = train_test_split(cancer_data,
cancer_label,
test_size=0.2,
random_state=1)사이킷런을 통해 recall값을 호출 했을 경우 T인 경우의 recall값 F경우의 recall값을 호출하게 된다. 우리는 지금 실제론 양성인데 예측을 음성으로 했을 상활이 궁금하기 때문에 classification_report로 호출했을 때 양성을 의미하는 0 클래스의 민감도만을 확인한다.
의사결정나무
#모델의 적용
decision_tree = DecisionTreeClassifier(random_state=32)
decision_tree.fit(X_train, y_train)
#예측해보기
y_pred = decision_tree.predict(X_test)
# 분석결과 확인
decision_report = classification_report(y_test, y_pred)
print(decision_report)
# 오차행렬인 컴퓨전 메트릭스 확인
decision_matrix = confusion_matrix(y_test, y_pred)
print(decision_matrix)
#recall값 구하기
decision_recall=decision_matrix[0][0]/(decision_matrix[0][0]+decision_matrix[0][1])
print('의사결정 나무의 recall값 : ',decision_recall) precision recall f1-score support
0 0.93 0.90 0.92 42
1 0.95 0.96 0.95 72 micro avg 0.94 0.94 0.94 114
macro avg 0.94 0.93 0.93 114
weighted avg 0.94 0.94 0.94 114
[[38 4][ 3 69]]
의사결정 나무의 recall값 : 0.9047619047619048
랜덤포레스트
#모델의 적용
random_forest = RandomForestClassifier(random_state=32)
random_forest.fit(X_train, y_train)
#예측해보기
y_pred = random_forest.predict(X_test)
# 분석결과 확인
random_report = classification_report(y_test, y_pred)
print(random_report)
# 오차행렬인 컴퓨전 메트릭스 확인
random_matrix = confusion_matrix(y_test, y_pred)
print(random_matrix)
#recall값 구하기
random_recall=random_matrix[0][0]/(random_matrix[0][0]+random_matrix[0][1])
print('랜덤 포레스트의 recall값 : ',random_recall) precision recall f1-score support
0 0.95 0.90 0.93 42
1 0.95 0.97 0.96 72 micro avg 0.95 0.95 0.95 114
macro avg 0.95 0.94 0.94 114
weighted avg 0.95 0.95 0.95 114
[[38 4][ 2 70]]
랜덤 포레스트의 recall값 : 0.9047619047619048
SVM
#모델의 적용
svm_model = svm.SVC(kernel='linear')
svm_model.fit(X_train, y_train)
#예측해보기
y_pred = svm_model.predict(X_test)
# 분석결과 확인
svm_report = classification_report(y_test, y_pred)
print(svm_report)
# 오차행렬인 컴퓨전 메트릭스 확인
svm_matrix = confusion_matrix(y_test, y_pred)
print(svm_matrix)
#recall값 구하기
svm_recall=svm_matrix[0][0]/(svm_matrix[0][0]+svm_matrix[0][1])
print('SVM의 recall값 : ',svm_recall) precision recall f1-score support
0 1.00 0.88 0.94 42
1 0.94 1.00 0.97 72 micro avg 0.96 0.96 0.96 114
macro avg 0.97 0.94 0.95 114
weighted avg 0.96 0.96 0.96 114
[[37 5][ 0 72]]
SVM의 recall값 : 0.8809523809523809
SGD
#모델의 적용
sgd_model = SGDClassifier()
sgd_model.fit(X_train, y_train)
#예측해보기
y_pred = sgd_model.predict(X_test)
# 분석결과 확인
sgd_report = classification_report(y_test, y_pred)
print(sgd_report)
# 오차행렬인 컴퓨전 메트릭스 확인
sgd_matrix = confusion_matrix(y_test, y_pred)
print(sgd_matrix)
#recall값 구하기
sgd_recall=sgd_matrix[0][0]/(sgd_matrix[0][0]+sgd_matrix[0][1])
print('SGD의 recall값 : ',sgd_recall) precision recall f1-score support
0 1.00 0.29 0.44 42
1 0.71 1.00 0.83 72 micro avg 0.74 0.74 0.74 114
macro avg 0.85 0.64 0.64 114
weighted avg 0.81 0.74 0.69 114
[[12 30][ 0 72]]
SGD의 recall값 : 0.2857142857142857
로지스틱리스레션
#모델의 적용
logistic_model = LogisticRegression()
logistic_model.fit(X_train, y_train)
#예측해보기
y_pred = logistic_model.predict(X_test)
# 분석결과 확인
logistic_report = classification_report(y_test, y_pred)
print(logistic_report)
# 오차행렬인 컴퓨전 메트릭스 확인
logistic_matrix = confusion_matrix(y_test, y_pred)
print(logistic_matrix)
#recall값 구하기
logistic_recall=logistic_matrix[0][0]/(logistic_matrix[0][0]+logistic_matrix[0][1])
print('로지스틱의 recall값 : ',logistic_recall) precision recall f1-score support
0 1.00 0.88 0.94 42
1 0.94 1.00 0.97 72 micro avg 0.96 0.96 0.96 114
macro avg 0.97 0.94 0.95 114
weighted avg 0.96 0.96 0.96 114
[[37 5][ 0 72]]
로지스틱의 recall값 : 0.8809523809523809
print('의사결정나무의 recall값 : ',decision_recall)
print('랜덤포레스트의 recall값 : ',random_recall)
print('SVM의 recall값 : ',svm_recall)
print('sgd의 recall값 : ',sgd_recall)
print('LogisticRegression의 recall값 : ',logistic_recall)의사결정나무의 recall값 : 0.9047619047619048
랜덤포레스트의 recall값 : 0.9047619047619048
SVM의 recall값 : 0.8809523809523809
sgd의 recall값 : 0.2857142857142857
LogisticRegression의 recall값 : 0.8809523809523809
양성을 양성이라고 판단해야하는 문제에서 의사결정나무, 랜덤포레스트, 로지스틱리그레션이 비교적(?) 높은 recall값이 나왔고 SVM이나 SGD의 recall값은 0%이다. 비교적이라는 말을 적은 이유는 나의 얕은 지식으로 전체적인 정답률을 줄이더라도 양성을 음성으로 판단하는 확률을 아예 0으로 만들어서 recall값을 100%확률로 해야한다는 것으로 알고 있다. 90%이면 100명중 10명을 잘못판단한다는 것인데,, 일상에서 절대 사용할 수 없는 상황인 것이다. 현재 상황인 코로나 시기에도 하루에 1000명 정도의 양성이 나오는 데 지금 여기서 사용한 모델을 이용한다면,,, 앞으로도 확진자 수가 늘어날 수 봐껜 없는 상황이 되는 것이다.
