사이킷런으로 분석할 수 있는 머신러닝을 공부합시다!
사이킷런에서 제공하는 데이터는 여러 종류가 있습니다.
[https://scikit-learn.org/stable/datasets.html] 링크를 통해 확인해 주세요.
- 저는 그중에 wine, cancer, handwritten 데이터로 공부를 했습니다.
코드 확인 [https://github.com/RobotPoly/exploration/tree/main/(E-2)MachineLearning]
머신러닝 알고리즘 소개
- 의사결정 나무
- 랜덤포레스트
- SVM
- SGD
- 로지스틱 리그레션
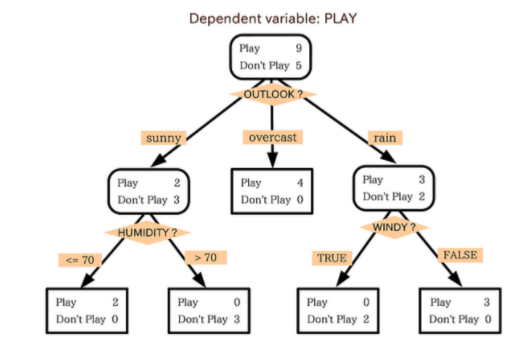
의사결정나무
- 의사결정나무는 데이터를 분석하여 이들 사이에 존재하는 패턴을 예측 가능한 규칙들의 조합으로 나타내며, 그 모양이 ‘나무’와 같다고 해서 의사결정나무라 불립니다.
- 자세한 계산과정은,, 컴퓨터가 진행 해 줄 것입니다.
- 우리가 알아야 할 것은 의사결정나무의 적절한 가지치기 정도 입니다.
[https://ratsgo.github.io/machine%20learning/2017/03/26/tree/] 참고링크
랜덤포레스트
- 랜덤포레스트는 여러 의사결정나무를 생성하여 다수결로 class를 분류해줍니다.
- 그래서 의사결정나무의 단편적인 모델를 보완해줍니다. - 우리가 설정해주는 것은 얼마나 많은 의사결정나무를 생성할 것인지 이고 내부적인 변수선택과정은 모델이 해줄 것입니다.
-[https://shate-programming.tistory.com/28] 참고링크
SVM(support vector machine)
- 변수의 수에 따른 고차원 영역에서 훈련을 통해 가장 적절한 선형, 또는 비선형을 통해 최적의 영역을 분리한다. 즉 , 최적의 분리 영역을 찾는다.
- 선형으로 불가능한 분리영역을 비선형으로 분리해줄 수 있는 장점이 있다.
- [https://shate-programming.tistory.com/28] 참고링크
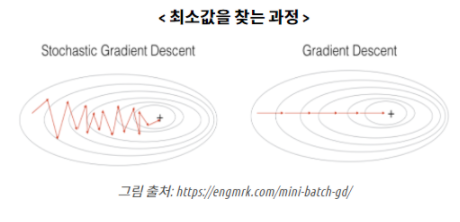
SGD(Stochastic Gradient Descent)
- 수학에서 배운 경사하강법을 이용해서 최적의 값을 찾는다.
- 경사하강을 할때 확률적인 요소를 넣어 확률적으로 하나의 기울기 최적점에 빠지지않고 전체로 부터 최적의 기울기를 찾아주는 것 입니다.
- 확률적인 부분이기 때문에 항상 최적점을 찾는 것은 아닙니다.
- [https://everyday-deeplearning.tistory.com/entry/SGD-Stochastic-Gradient-Descent-%ED%99%95%EB%A5%A0%EC%A0%81-%EA%B2%BD%EC%82%AC%ED%95%98%EA%B0%95%EB%B2%95] 참고 링크
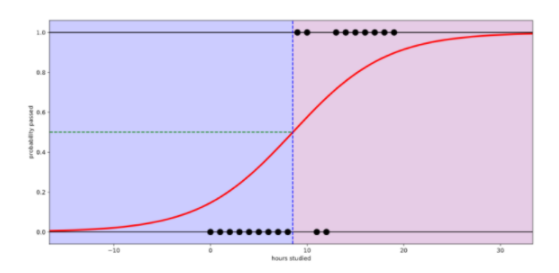
로지스틱 리그레션(Logistic Regression)
- 회귀를 사용하여 데이터가 어떤 범주에 속할 확률을 0에서 1 사이의 값으로 예측하고 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 지도 학습 알고리즘입니다.
- [http://hleecaster.com/ml-logistic-regression-concept/]
- 각각 모델은 어떤 데이터인지에 따라 서로 다른 성능을 보입니다. 파이썬 코드를 확인하고 싶은 분은 제 깃헙에서 확인해보세욥!
- 데이터는 사이킷런에서 불러와서 하면 되기때문에 다운은 따로 필요없습니다.
[https://github.com/RobotPoly/exploration/tree/main/(E-2)MachineLearning]

인공지능 파이팅!