데이터를 분석할 때 편리할 수 있도록 기능을 제공하는 알고리즘
데이터를 불러올 수 있음
데이터를 분석하는데 필요한 알고리즘을 불러올 수 있음
데이터를 전처리할 때 필요한 기능이 있음
평가를 통해 정확도를 확인할 수 있음.
- sklearn.datasets (데이터 셋 제공)
sklearn.utils.Bunch (데이터 셋의 데이터 타입)
sklearn.preprocessing (데이터 전처리)
sklearn.model_selection.train_test_split (학습용 데스트용 데이터셋 분리할때 사용)
sklearn.metrics(알고리즘 성능을 측정하는 함수 제공)
sklearn.ensemble(앙상블 알고리즘)
sklearn.linear_model
sklearn.naive_bayes
sklearn.neighbors
sklearn.svm
sklearn.tree
sklearn.cluster
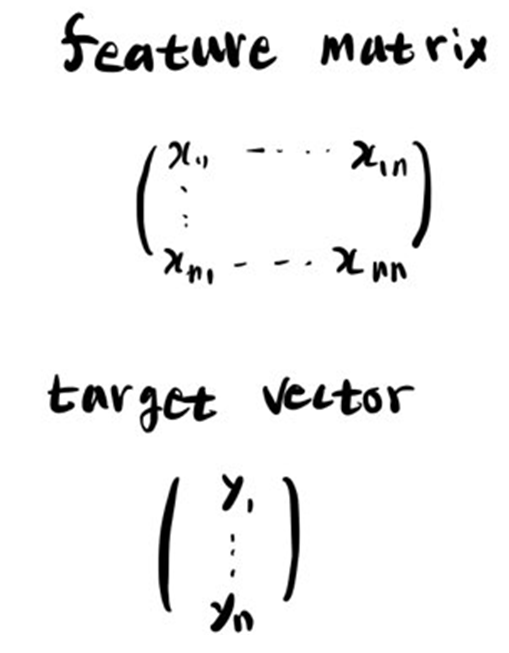
보통 알고리즘을 이용할 때 행렬과 같은 표현식으로 분석을 할 필요가 있음
사이킷 런에서 제공하는 데이터 셋 모듈
datasets.load_boston(): 회귀- 미국 보스턴 집값 예측
datasets.load_breast_cancer(): 분류- 유방암 판별
datasets.load_digits(): 분류- 0 ~ 9 숫자 분류
datasets.load_iris(): 분류- iris 품종 분류
datasets.load_wine(): 분류- 와인 분류
wine 데이터를 통해 데이터 타입 확인
from sklearn.datasets import load_wine
data = load_wine()
type(data)sklearn.utils.Bunch
print(data){'data': array([[1.423e+01, 1.710e+00, 2.430e+00, ..., 1.040e+00, 3.920e+00,
1.065e+03],
[1.320e+01, 1.780e+00, 2.140e+00, ..., 1.050e+00, 3.400e+00,
1.050e+03],
[1.316e+01, 2.360e+00, 2.670e+00, ..., 1.030e+00, 3.170e+00,
1.185e+03],
사이킷 런을 통해 데이터를 호출하면 딕셔너리 형태의 데이터를 받음.
data.keys()dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
# 데이터값들을 확인
data.dataarray([[1.423e+01, 1.710e+00, 2.430e+00, ..., 1.040e+00, 3.920e+00,
1.065e+03],
[1.320e+01, 1.780e+00, 2.140e+00, ..., 1.050e+00, 3.400e+00,
1.050e+03],
#데이터 크기확인
data.data.shape(178, 13)
#데이터 차원을 확인
data.data.ndim2
# 타겟 확인(라벨)
data.targetarray([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,....
#위 데이터와 같은 행의 수를 가지고 있음
data.target.shape(178,)
# 컬럼 네임 확인
data.feature_names['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols','proanthocyanins', 'color_intensity',
'hue', 'od280/od315_of_diluted_wines', 'proline']
#위 데이터 열의 개수와 동일한 것을 알 수 있음
len(data.feature_names)13
#분류하고자 하는 데이터 라벨
data.target_namesarray(['class_0', 'class_1', 'class_2'], dtype='<U7')
#불러온 데이터에대한 정보를 확인할 수 있음
print(data.DESCR)종합해서 데이터를 분석하고자 할때는 아래와 같이 코딩을 하면 끝!
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 데이터셋을 sklearn에서 불러올 수 있음
data = load_wine()
# 모듈에서 제공하는 기능을 통해 분리
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=11)
# 훈련
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 정확도
print("정확도 = ", accuracy_score(y_test, y_pred))