
BeautifulSoup
find 사용법
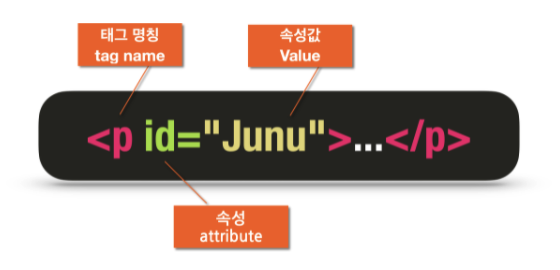
find의 목적은 원하는 태그를 찾는 것- 태그는 이름(name), 속성(attribute), 속성값(value)로 구성
- 따라서 find로 이름, 속성, 속성값을 특정하여 태그를 찾을 수 있음
find()find()함수는 조건을 만족하는 태그를 하나만 가져오는 함수
find_all()find_all()함수는 원하는 태그가 여러 개 있을 경우 해당하는 태그를 한꺼번에 가져오는 함수
- 문장 가져오기:
.string,get_text()- 태그 내의 문장을 가져오는 방법
- 차이점
.string의 경우 문자열이 없으면None을 출력하지만,get_text()의 경우 유니코드 형식으로 텍스트까지 문자열로 반환하기 때문에 아무 정보도 출력되지 않음
tag = "<p class='backend' id='hwaya'> Hello World! </p>"
soup = BeautifulSoup(tag)
# 태그 이름만 특정
soup.find('p')
# 태그 속성만 특정
soup.find(class_='backend')
soup.find(attrs = {'class':'backend'})
# 태그 이름과 속성 모두 특정
soup.find('p', class_='backend')beautifulsoup을 이용하여 태그를 찾고 이를tag객체에 담아 반환tag객체는 태그의 요소를 자신의 속성으로 가짐
tag = "<p class='backend' id='hwaya'> Hello World! </p>"
soup = BeautifulSoup(tag)
object_tag = soup.find('p')
# 태그의 이름
object_tag.name
# 결과: 'p'
# 태그에 담긴 텍스트
object_tag.text
# 결과: ' Hello World! '
# 태그의 속성과 속성값
object_tag.attrs
# 결과: {'class': ['backend'], 'id': 'hwaya'}select 사용법
select는 CSS selector로tag객체를 찾아 반환하는데 이는 CSS에서 HTML을 태깅하는 방법을 활용한 메소드- 가장 첫 번째 결과를 반환하는
select_one()은find()에, 전체 결과를 리스트로 반환하는select()는find_all()에 대응
- 가장 첫 번째 결과를 반환하는
select('태그이름')select('.클래스명')select('#아이디명')
select('태그명[속성1=값1]')select('상위태그>하위태그>하위태그')select('상위태크.클래스이름>하위태그.클래스이름')select('상위태그 하위태그')- select 함수에서 띄어쓰기를 통해 하위태그를 사용할 경우 하위태그는 자손관계에 있는 태그를 말함
select('#아이디명>태그명.클래스명')
tag = "<p class='backend' id='hwaya'> Hello World! </p>"
soup = BeautifulSoup(tag)
# 태그 이름만 특정
soup.select_one('p')
# 태그 class 특정
soup.select_one('.backend')
# 태그 이름과 class 모두 특정
soup.select_one('p.backend')
# 태그 id 특정
soup.select_one('#hwaya')
# 태그 이름과 id 모두 특정
soup.select_one('p#hwaya')
# 태그 이름과 class, id 모두 특정
soup.select_one('p.backend#hwaya')Tip! 추가 내용

find처럼 태그 이름, 속성, 속성값을 특정하는 방식은 같음- 하지만 CSS는 이 외에도 다양한 선택자(selector)를 갖기 때문에 여러 요소를 조합하여 태그를 특정하기 쉬움
- 예를 들어 특정 경로의 태그를 객체로 반환하고 싶을 때,
find의 경우 반복적으로 코드를 작성해야 하지만select는 직접 하위 경로를 지정할 수 있기 때문에 간편
# find
soup.find('div').find('p')
# select
soup.select_one('div > p')
🌱 Backend-Dev | hwaya2828@gmail.com