
Crawling
크롤링이란?
- 크롤링(crawling) 또는 스크래핑(scraping)은 웹 페이지를 가져와서 데이터를 추출해 내는 방법을 말함
- 이렇게 크롤링하는 소프트웨어를 크롤러(crawler)라고 함
Tip! 크롤링(crawling) 가능 여부 확인
- 크롤링을 무작정 하다가 보면 맞게 작성한 것 같은 코드에서 아무 데이터도 못 얻고 있는 것을 확인할 수 있음
- 이럴 때 크롤링 할 사이트가 크롤링이 가능한 사이트인지 확인해야 함
- 크롤링 가능 여부를 확인하는 방법은 사이트명 뒤에
/robots.txt를 붙여 확인 가능
크롤링 관련 패키지
- 웹 크롤링 두 가지 단계
- 원하는 웹 페이지의
html문서를 싹 긁어옴 html문서에서 원하는 것을 골라서 사용
- 원하는 웹 페이지의
requests
# 설치
pip install requestshtml문서를 가져올 때 사용하는 패키지requests는 사용자 친화적인 문법을 사용하여 다루기 쉬우면서 안정성이 뛰어남- 그래서 파이썬 기본 라이브러리에 포함된
urllib패키지보다 자주 사용됨
# 사용 방법
# requests 패키지 가져오기
import requests
# 가져올 url 문자열로 입력
url = 'https://www.naver.com'
# requests의 get 함수를 이용해 해당 url로 부터 html이 담긴 자료를 받아옴
response = requests.get(url)
# 정상적으로 받아졌다면 200이라는 상태코드를 반환
print(response.status_code)
# 얻고자 하는 html 문서가 여기에 담기게 됨
html_text = response.text selenium
# 설치
pip install seleniumselenium패키지는chromedriver를 이용해chrome을 제어하기 위해 사용- 크롤링을 하다보면 무엇인가 입력하거나 특정 버튼을 눌러야 하는 상황이 발생하는데 이때
selenium을 이용
- 크롤링을 하다보면 무엇인가 입력하거나 특정 버튼을 눌러야 하는 상황이 발생하는데 이때
# 사용 방법
# selenium의 webdriver를 사용하기 위한 import
from selenium import webdriver
# selenium으로 무엇인가 입력하기 위한 import
from selenium.webdriver.common.keys import Keys
# 페이지 로딩을 기다리는데에 사용할 time 모듈 import
import time
# 크롬 드라이버 실행 (경로 예: '/Users/Roy/Downloads/chromedriver')
driver = webdriver.Chrome('chromedriver의 경로를 입력할 것')
# 크롬 드라이버에 url 주소 넣고 실행
driver.get('https://www.google.co.kr/')
# 페이지가 완전히 로딩되도록 3초동안 기다림
time.sleep(3)
# 검색어 창을 찾아 search 변수에 저장
search = driver.find_element_by_xpath('//*[@id="google_search"]')
# search 변수에 저장된 곳에 값을 전송
search.send_keys('코딩유치원 파이썬')
time.sleep(1)
# search 변수에 저장된 곳에 엔터를 입력
search.send_keys(Keys.ENTER)Tip! 크롬 드라이브 자동 설치
뻥뚫리는 파이썬 코드 모음 - 셀레니움 설치와 크롬 드라이버 자동 처리from selenium import webdriver import chromedriver_autoinstaller # 크롬 드라이버 버전 확인 chrome_ver = chromedriver_autoinstaller.get_chrome_version().split('.')[0] try: driver = webdriver.Chrome(f'./{chrome_ver}/chromedriver.exe') except: chromedriver_autoinstaller.install(True) driver = webdriver.Chrome(f'./{chrome_ver}/chromedriver.exe')
beautifulsoup4
# 설치
pip install beautifulsoup4- 마지막으로
beautifulsoup4라는 패키지는 매우 길고 정신없는html문서를 잘 정리되고 다루기 쉬운 형태로 만들어 원하는 것만 쏙쏙 가져올 때 사용- 이 작업을 파싱(Parsing)이라고도 부름
import requests
# 주로 bs로 이름을 간단히 만들어서 사용함
from bs4 import BeautifulSoup as bs
response = requests.get('https://www.google.co.kr')
# html을 잘 정리된 형태로 변환
html = bs(response.text, 'html.parser')
# find 함수로 특정 이미지를 선택하는 코드
google_logo = html.find('img', {'id':'hplogo'})HTML & CSS 정리
HTML

- HTML은 HyperText Markup Language의 약자
- 웹 페이지는 HTML 문서라고도 불리며, HTML 태그들로 구성됨
- 각각의 HTML 태그는 웹 페이지의 디자인이나 기능을 결정하는데 사용
- HTML 태그는 태그 이름을 꺾쇠 괄호(
<>)로 감싸서 표현- HTML 태그는 보통 시작 태그(start tag, opening tag)와 종료 태그(end tag, closing tag)의 한 쌍으로 구성
- 종료 태그는 시작 태그와 전부 똑같지만, 태그 이름 앞에 슬래시(
/)가 존재 - 태그에 따라 시작 태그만 있고 종료 태그가 없는 태그도 존재
<img><br><hr>등과 같이 종료 태그 없이 시작 태그만을 가지는 태그를 빈 태그(empty tag)라고 함
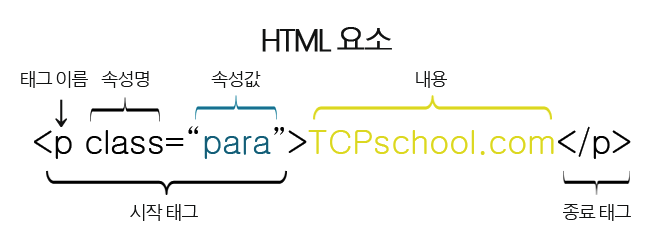
- HTML 요소(element)는 여러 속성을 가질 수 있으며, 이러한 속성(attribute)은 해당 요소에 대한 추가적인 정보를 제공
- 또한 HTML 요소는 시작 태그로 시작해서 종료 태그로 끝남
- 속성은 HTML 요소 중에서도 언제나 시작 태그 내에서만 정의되며, 속성 이름과 속성값(value)으로 표현
- HTML은 수많은 태그로 이루어져있어서 각 태그에 속성을 부여하여 구분 가능하도록 만들어줌
- 각 태그별로 속성이 다양하지만 꼭 기억해야할 속성명 2가지는
id와classid: 하나의 웹페이지에 하나만 쓸 수 있는 고유한 이름으로<태그이름 id="속성값">와 같이 쓰임class: 비슷한 형태를 가진 요소에 여러번 사용할 수 있는 이름으로<태그이름 class="속성값">와 같이 쓰임
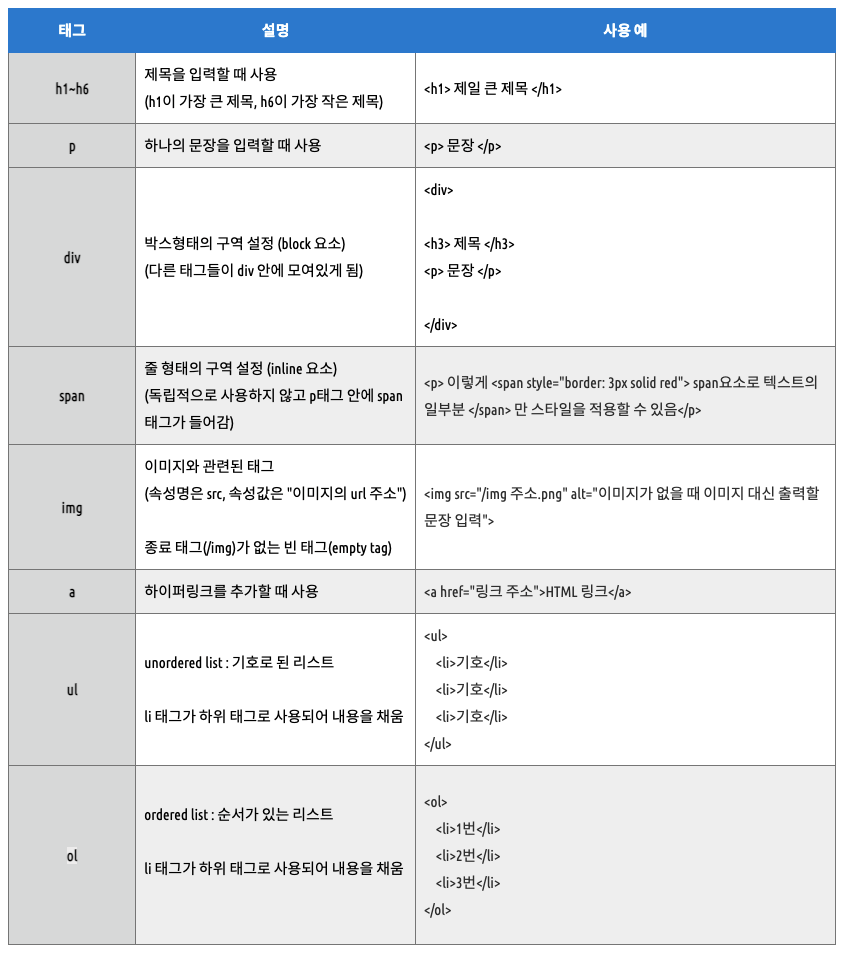
Tip! HTML 태그 종류
CSS
- CSS는 Cascading Style Sheets의 약자
- CSS는 HTML 요소들이 각종 미디어에서 어떻게 보이는가를 정의하는 데 사용되는 스타일 시트 언어
- HTML만으로 웹 페이지를 제작할 경우 HTML 요소의 세부 스타일을 일일이 따로 지정해 주어야만 하는데 이 작업은 매우 많은 시간이 걸리며, 완성한 후에도 스타일의 변경 및 유지 보수가 매우 힘들어짐
- 이러한 문제점을 해소하기 위해 W3C(World Wide Web Consortium)에서 만든 스타일 시트 언어가 바로 CSS
- CSS는 웹 페이지의 스타일을 별도의 파일로 저장할 수 있게 해주므로 사이트의 전체 스타일을 손쉽게 제어할 수 있음
- 또한, 웹 사이트의 스타일을 일관성 있게 유지할 수 있게 해주며, 그에 따른 유지 보수 또한 쉬워짐
- 이러한 외부 스타일 시트는 보통 확장자를
.css파일로 저장
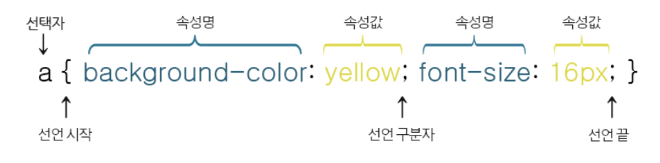
- CSS의 문법은 선택자(selector)와 선언부(declaratives)로 구성
- 선택자는 CSS를 적용하고자 하는 HTML 요소(element)를 가리킴
- 선언부는 하나 이상의 선언들을 세미콜론(
;)으로 구분하여 포함할 수 있으며, 중괄호({ })를 사용하여 전체를 둘러쌈 - 각 선언은 CSS 속성명(property)과 속성값(value)을 가지며, 그 둘은 콜론(
:)으로 연결 - 이러한 CSS 선언(declaration)은 언제나 마지막에 세미콜론(
;)으로 끝마침
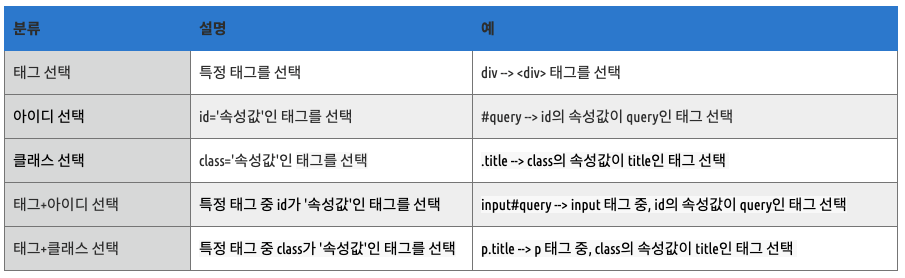
Tip! CSS 선택자 종류
정적 크롤링 & 동적 크롤링
정적 크롤링
- 정적 크롤링은 정적인 데이터를 수집하는 방법
- 정적인 데이터란 변하지 않는 데이터를 의미
- 즉 한 페이지 안에서 원하는 정보가 모두 드러날때 정적 데이터라고 할 수 있음
- 정적 크롤링은 한 페이지 내에서 모든 작업이 이루어지기 때문에 속도가 매우 빠르다는 장점을 가짐
동적 크롤링
- 동적 크롤링은 동적인 데이터를 수집하는 방법
- 동적인 데이터란 입력•클릭•로그인 등과 같이 페이지 이동이 있어야 보이는 데이터를 말함
- 정적 크롤링 수집하는 속도가 느리다는 단점이 있지만 더 많은 정보를 수집할 수 있다는 장점이 있음
Tip! 추가 내용
- 정적 페이지에서 정보를 수집 하느냐 동적 페이지를 하느냐에 따라서 사용되는 파이썬 패키지는 달라짐
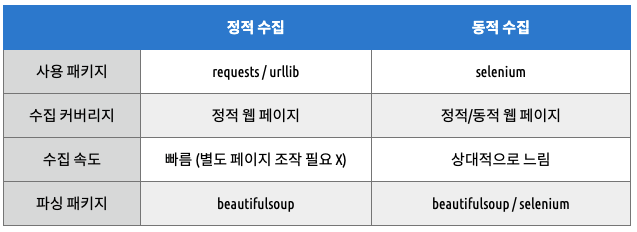
정적 수집
- 정적 수집은 멈춰 있는 페이지의
html을requests혹은urllib패키지를 이용해 가져와서beautifulsoup패키지로 파싱하여 원하는 정보를 수집- 여기서 파싱(parsing)이란 복잡한 html 문서를 잘 분류, 정리하여 다루기 쉽게 바꾸는 작업을 말함
- 바로 해당
url의html을 받아와서 수집하기 때문에 수집 속도가 빠르다는 특징이 있지만, 여기저기 모두 사용할 수 있는 범용성은 떨어진다는 특징이 있음
동적 수집
- 동적 수집은 계속 움직이는 페이지를 다루기 위해서
selenium패키지로chromdriver를 제어- 특정
url로 접속해서 로그인을 하거나 버튼을 클릭하는 식으로 원하는 정보가 있는 페이지까지 도달
- 특정
- 이때
driver.find_elements_by_함수를 이용해html을 곧바로 지목해서 추출할 수도 있고,driver.page_source함수를 이용해 전체html을 받아 올 수도 있음html전체를 받아와서beautifulsoup로 하면, 페이지에서 하나하나 가져오는 것보다 수집 속도가 빠른 특징이 있음
- 동적 수집의 특징은 정적 수집과 반대라고 생각하면 됨
- 브라우저를 직접 조작하고 브라우저가 실행될때까지 기다려주기도 해야해서 그 속도가 느리다는 특징이 있음
Tip! find 관련 함수
selenium패키지
driver.find_element(s)_by_의 뒤에xpath(),id(),class_name(),tag_name()를 사용beautifulsoup패키지
find_all(),find()함수

🌱 Backend-Dev | hwaya2828@gmail.com