
Index
이전 작성 글: [Database] 인덱스
DB Index 동작 원리를 알아보자
[DataBase] DB 성능을 위한 Index
DB 데이터베이스 인덱스(Index) 기본 개념과 설명
Index 란?
- 데이터베이스에는 수많은 데이터가 저장되고 읽히고 수정되고 삭제됨
- 그 과정에서 원하는 데이터를 어떻게 더 빠르게 찾아낼 것인가에 대한 문제이고 그 과정에서
Index라고 하는 것을 사용
- 그 과정에서 원하는 데이터를 어떻게 더 빠르게 찾아낼 것인가에 대한 문제이고 그 과정에서
- 여기서
Index는 MySQL 에서 사용하는B+Tree를 기준으로 함B+Tree를 사용하지 않는 다른 데이터베이스의 경우Index의 동작 원리가 다를 수 있음
Index 종류
Index는 크게 Clustered Index 와 Non Clustered Index 두 가지로 나눌 수 있음
Clustered Index
- 사용자가 설정하는
Index가 아닌 MySQL 이 자동으로 설정하는Index
- 해당 테이블에
Auto Increments값으로PK가 있다면 해당 컬럼이 Clustered Index 가 됨 - 만약 해당
PK가 없다면 컬럼 중에Unique컬럼을 Clustered Index 로 선정 Unique컬럼도 하나도 없다면 MySQL 에서 내부적으로Hidden Clustered Index Key( row ID ) 를 만들어 Clustered Index 로 사용
- MySQL 에서
Clustered Index Key로 사용하는 위 3가지 조건을 살펴보면 공통점 존재- 테이블의
count(*)과distinct key한 값이 똑같다는 점 - 그 이유는 모든 row 를 통틀어 중복이 적으면 적을수록
Index는 높은 효율을 보임
- 테이블의
- 이 때문에 MySQL 에서 자동으로 설정되는 Clustered Index 는 최대 효율을 위해 중복이 최대한 발생하지 않는 컬럼을 사용하게 됨
Non Clustered Index
- 사용자 또는 DBA 등이 설정하는 모든
Index는 Non Clustered Index 에 해당
- 멀티 컬럼
Index의 경우 최대 16개의 컬럼을 사용할 수 있고 테이블 당 인덱스의 개수는 최대 64개까지 지정이 가능- Clustered Index 까지 한다면 총 65개
B+Tree Node
- MySQL 에서는
Index의 저장 구조로B+Tree를 사용이진 트리<B-Tree<B+Tree순으로 확장되어진 자료구조
B+Tree 의 구조
- 각각의 사각형 하나를
Node혹은Page라고 부름- MySQL 에서는
Node의 사이즈가 16KB 로 설정되어 있음
- MySQL 에서는
Node중에서 최상단 레벨에 존재하는Node를Root Node라고 하고 최하단에 디스크의 주소를 가지고 있는Node레벨을Leaf Node라고 함Root와Leaf사이에 있는Node들을Branch Node라고 부름
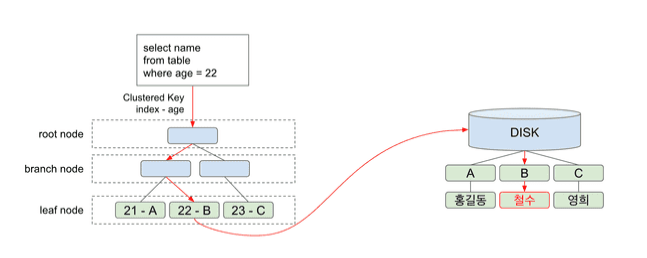
# 예시
select name from table where age=22;age컬럼이Index로 설정되어 있다고 가정하고 이 쿼리에서Index를 통해 데이터를 조회하는 방법- 우선
Root Node로 가서age=22인 값의Leaf Noe로 가기 위한 경로를 안내 받음 Root Node는Branch Node의 경로를 안내해줌Branch Node가 없어서Root Node바로 아래Leaf Node가 있다면 바로Leaf Node의 위치를 알려줄 것
Branch Node로 가면 또 아래의Branch Node혹은Leaf Node의 경로를 알려줄 것- 그렇게
Leaf Node까지 도착하게 되면Leaf Node는Index의 값과 디스크의 주소값을 가지고 있음
- 우선
- 만약 위 쿼리에서
select name이 아닌select age로 조회하는 경우B+Tree를 통해age값이 22 인 것을 이미 알고 있으니 디스크로 접근할 필요 없음- 하지만
age가 아닌name을 조회했기 때문에 디스크까지 접근해야 함 - 이 때 디스크I/O 가 발생하고
age22에 저장되어 있는 디스크 B 주소로 접근하게 됨 - 그러면 최종적으로 디스크 B 주소에 있는
철수라는 데이터를 가져오고 조회 결과를 보여주게 됨
데이터양이 많아질수록 더 빨라지는 Index 검색
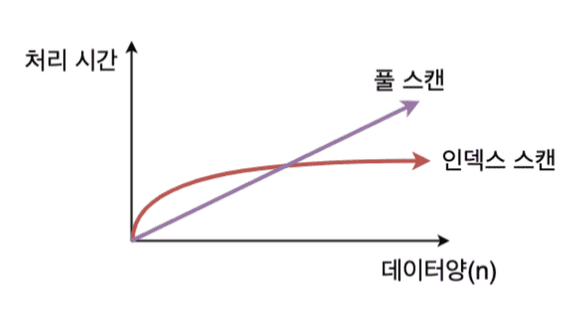
Index로 설정해두면 데이터양이 많아질수록 Full Scan 보다 Index Scan 이 더 빠름- 특정 데이터양의 시점까지는 Full Scan 이 빠르다가 이후로는 Index Scan 이 더 빠름
Full Scan 이 더 빠른 이유
- 위 그래프에서 보면 특정 시점까지는 Full Scan 이 오히려 더 빠름
Index를 통한 검색은B+Tree에서Leaf Node까지 찾아 내려간 후 해당 데이터를 찾기 위해 디스크로 접근- 그런데 Full Scan 은 이렇게
B+Tree를 찾아가는 과정 없이 디스크로 가서 바로 모든 데이터를 읽어옴
- 데이터 양이 많지 않거나
Index가 효율적으로 설정되어 있지 않은 경우 오히려 Table Full Scan 이 더 빠름 - Index Full Scan 이 실행되는 경우 Index Full Scan 의 데이터가 테이블의 모든 데이터의 양과 비슷한 경우에도 역시 Table Full Scan 이 더 빠를 수 있음
B+Tree 의 데이터 삽입
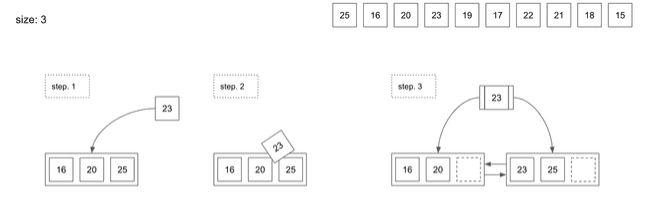
- 예시:
Node의 사이즈는 16KB 이지만 예제로 살펴보기 위해 한 개의Node는 최대 3개의 데이터를 저장할 수 있다고 가정
B+Tree의Node에서 데이터가 Overflow 발생했을 때 어떤 일이 일어날까?- step. 1 에서 이미 3개가 들어있는
Node에 새로운 데이터인23이 들어오려고 함 Index는 모든 데이터가 정렬된 상태로 저장하기 때문에23은20과25사이에 들어가려고 할 것- 그러나 데이터 개수가 넘치기 때문에 Node Split 과정이 일어나게 됨
- Split 이 발생하면 1개의 데이터가 상위
Node로 올라가게 되고 해당Node는Leaf Node를 가리키는Node Number를 저장하게 됨
- step. 1 에서 이미 3개가 들어있는
어떤 데이터가 상위 Node 로 올라가는걸까?
B+Tree기준으로는 예제에서 데이터 사이즈가 3개인 경우 새로운 데이터가 들어오면서 4개가 된 경우n/2+1번째의 데이터가 상위로 올라감4/2+1=3이므로, step. 3 처럼23이 상위로 올라감
Node Merge
Node에 데이터가 넘치는 경우Node가 2개로 나눠지는 Split 과정이 일어남- 또 반대로 3개를 저장할 수 있는
Node에 1개씩만 저장된Node가 많다고 가정한다면, 이런 경우 공간 낭비를 줄이기 위해 MySQL 이 2개의Node를 1개로 병합하는 Merge 동작이 일어남
- 또 반대로 3개를 저장할 수 있는
B+Tree 의 데이터 삽입 예제
B+Tree에 총 10개의 데이터를 넣는 경우
insert(1) - 25
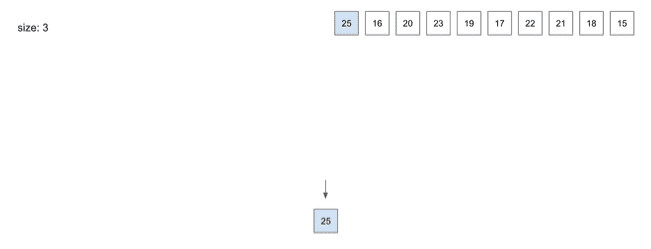
- 첫번째 데이터인
25를 넣었을 때Node에는 총 3개의 데이터를 저장할 수 있고 자리는 매우 널널함25가 그대로 저장되고 종료
insert(2) - 16
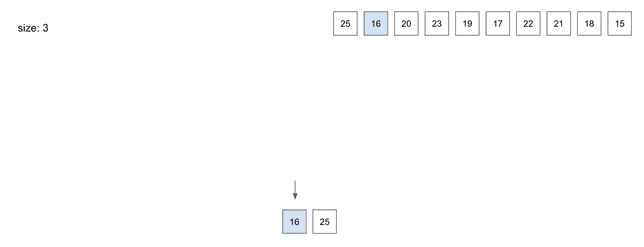
- 다음으로
16을 넣었을 때Index는 항상 정렬된 순서로 저장함- 그렇기 때문에 이미 저장된
25보다 왼쪽에 저장됨
inser(3) - 20
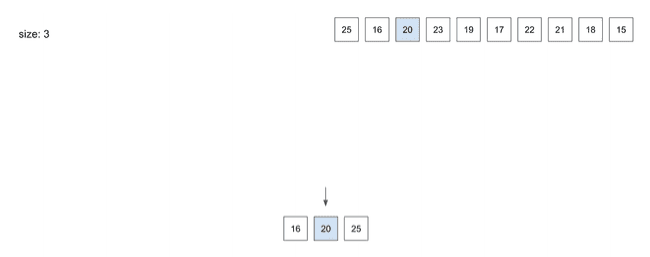
- 다음으로
20을 넣었을 때16과25사이에 저장됨
insert(4) - 23
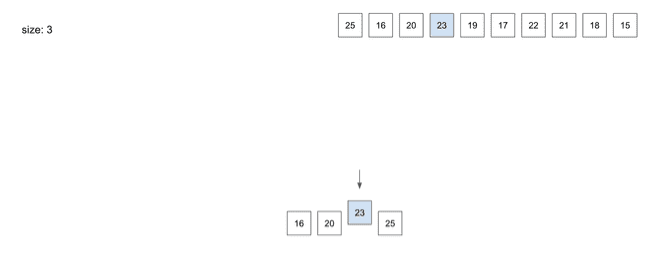
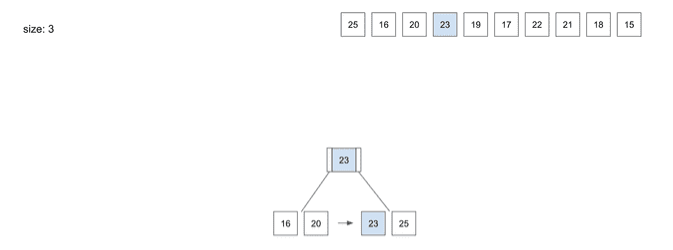
- 다음으로
23을 넣었을 때23을 넣으려고 했더니Node의 사이즈가 꽉 차는 상황이 발생n/2+1에 의한 3번째 데이터인23은 상위Node로 올라가야 함23이 상위Node로 올라가면서Root Node와Leaf Node2단계로 나뉘어짐
insert(5) - 19
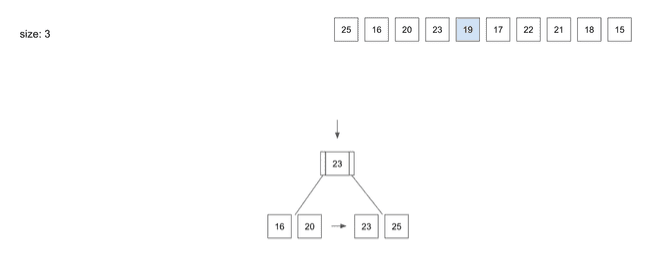
- 이제는
Root Node가 있으니 데이터가 바로 저장되지 않음Root Node부터19를 저장하기 위한Leaf Node를 찾아야 함- 먼저
Root Node에 있는23에 가서19가 가야할Leaf Node의 위치를 확인 19는23보다 작기 때문에 왼쪽의Leaf Node의 위치를 알려줄 것- 그러면
Root Node의 왼쪽 경로를 따라 내려가서 만난Leaf Node에19를 저장하게 됨
insert(6) - 17
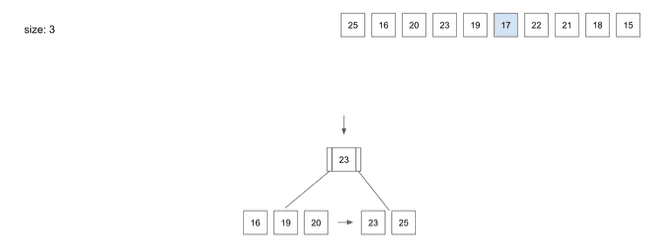
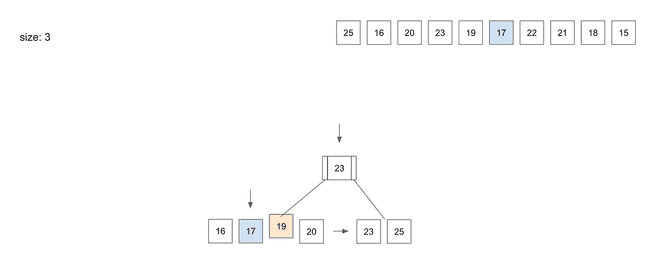
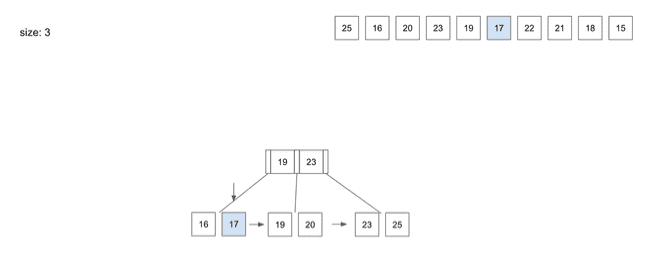
17를 넣기 위해 동일하게Root Node부터 탐색- 왼쪽
Leaf Node로 따라감 17을 저장하고 보니Node가 넘치는 문제가 발생하면서 Split 과정이 일어남- 3번째 자리에 있는
19가 상위Node로 올라가게 됨
- 왼쪽
insert(7) - 22
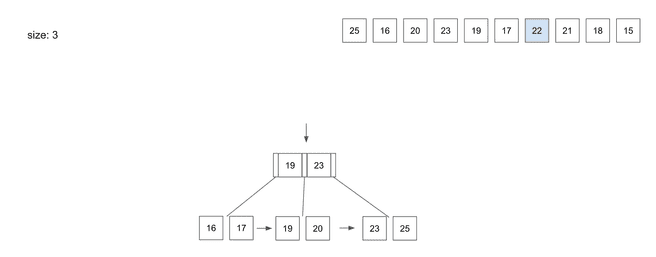
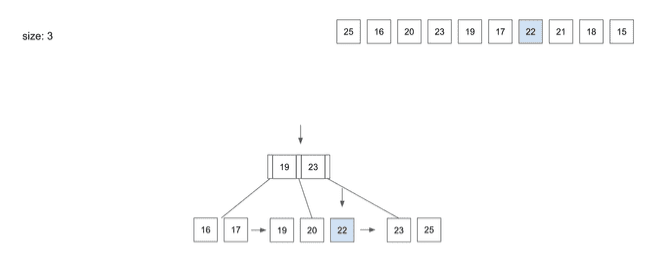
22를 저장하기 위해Root Node를 살펴보면22는19와23의 사이값Root Node에서 알려준 가운데Leaf Node로 와서22데이터를 저장
insert(8) - 21
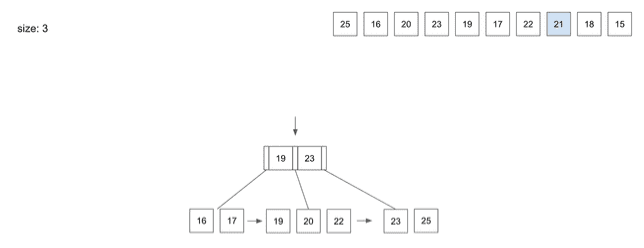
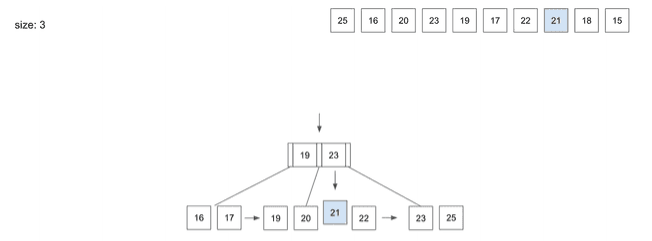
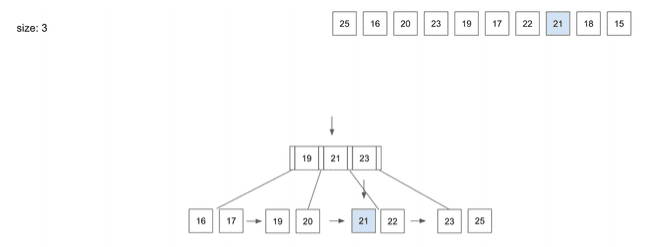
21을 저장하기 위해Root Node에서 경로를 찾아감- 가운데
Leaf Node를 알려줄 것 21을 저장하고 보니Node사이즈가 넘치게 되어 Split이 일어남- 3번째 데이터인
21이 상위Node로 올라가게 됨
- 가운데
insert(9) - 18
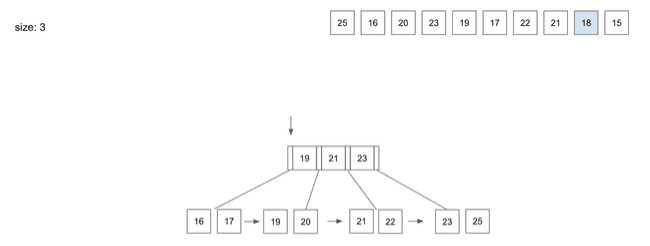
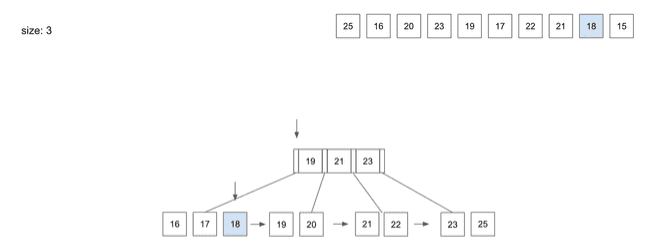
18을 넣기 위해Root Node를 살펴보면 가장 왼쪽 경로를 통해Leaf Node를 찾아감- 자리 공간이 있으니
18을 저장하고 종료
- 자리 공간이 있으니
insert(10) - 15
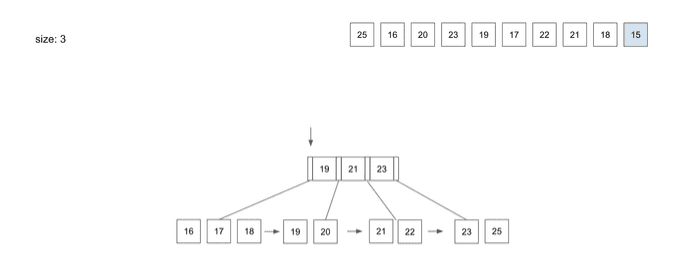
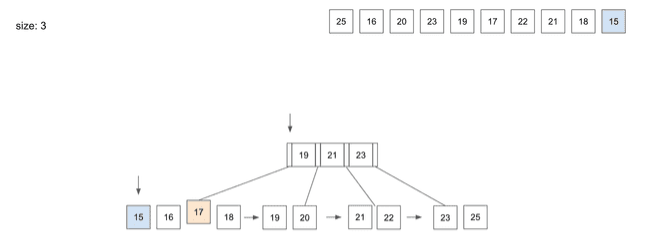
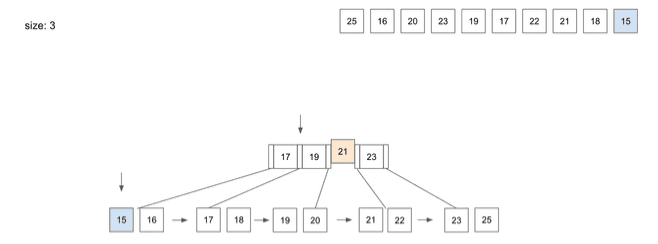
- 마지막으로 10번째 데이터인
15를 넣으려고 하면 역시19보다 작으니 가장 왼쪽 경로를 따라 찾아가게 됨15를 저장하고보니Leaf Node의 Split이 필요함- Split을 통해
Leaf Node를 두 개로 나눴고17을 상위Node로 복사 - 그러면 상위의
Root Node에서Node가 넘치는 상황 발생 - 상위
Root에서도 동일한 조건으로 Split 과정이 일어남- 여기서
Leaf Node와의 Split 차이점은 상위로 데이터를 저장할 때 중복으로 저장하지 않음 - 그 이유는
Leaf Node는 모든 데이터와 디스크 주소값을 가지고 있는 반면,B+Tree에서Root Node와Branch Node는 하위Node의 경로값만 가지고 있음
- 여기서
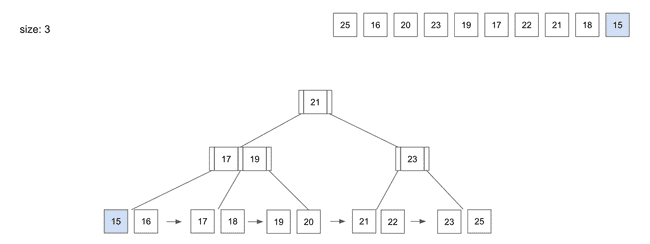
- 이제
Root,Branch,Leaf3단계가 모두 있는B+Tree구조가 되었음
delete - 19
- 데이터를 삭제할 때
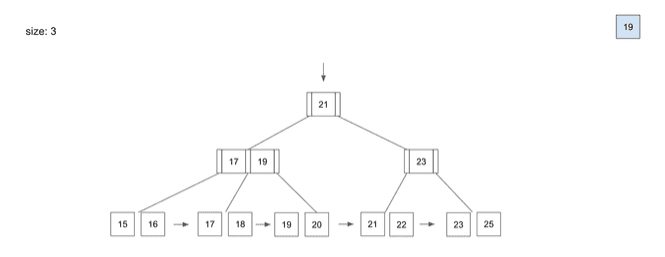
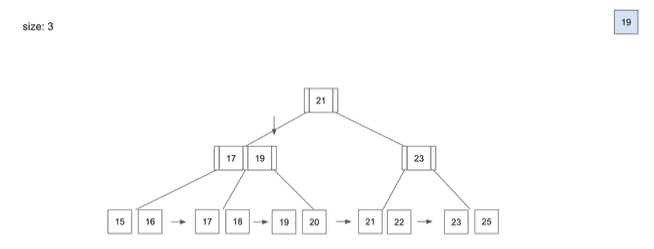
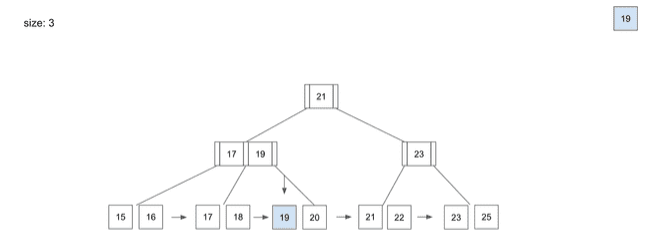
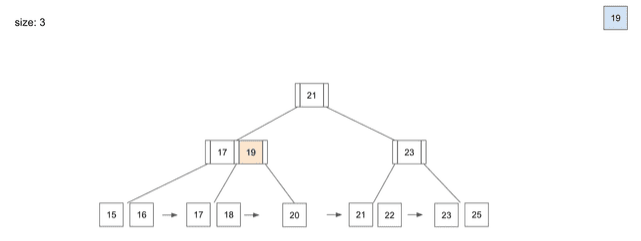
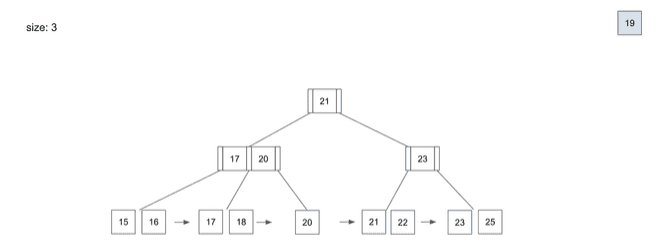
- 데이터를 삭제할 때도
Insert할 때와 동일하게Root Node부터Leaf Node를 찾아가는 과정은 동일
19라는 데이터를 삭제할 때- 역시
Root Node→Branch Node→Leaf Node순서로 데이터의 위치를 찾아갈 것 19라는 데이터를 찾았을 때Index에서 해당 데이터를 삭제19를 삭제하고 보니Branch Node에서19를 가리키고 있었는데,19라는 데이터가 삭제되어 문제 발생- 이 경우
Branch Node는 해당Leaf Node에서 가장 작은 값인20으로 다시 저장하는 동작이 일어남 Branch Node의 값을20으로 다시 바꿔주고 삭제 작업이 끝나게 됨
- 역시
update
B+Tree에서Update라는 명령은 없음Update를 실행하게 되면Delete→Insert순으로 동작이 일어남- 이 과정에서
Delete를 하면서Node에 빈 공간이 많아질 경우 두Node가 합쳐지는Merge과정이 발생할 수 있고, 위에서 살펴본 것처럼Leaf Node를 가지고 있는 값이 삭제되는 경우Branch Node가 가리키는 값을 바꿔야하는 경우가 발생할 수 있음
Index 컬럼의 설정
Index 는 조회 속도를 빠르게 하기 위해 사용한다고 했는데, 그렇다면 조회 속도를 높이기 위해 Index 는 많으면 많을수록 좋은걸까?
B+Tree의 동작 과정을 생각해보면 답변이아니요라는 것을 알 수 있음
Select는Index에 의해 더 빨라지겠지만Update,Delete,Insert의 동작이 더 느려지게 됨- 새로운 데이터가 생겼을 때
Index가 1개면 위 과정이 1번이겠지만Index가 20개라면 20번 실행되어야 함
- 새로운 데이터가 생겼을 때
그렇다면 어떤 컬럼에 Index 를 설정하면 좋을까?
- MySQL 에서 자동 설정하는 Clustered Index 의 조건을 다시 한번 생각해보면, 테이블에서 모든 row 에 중복이 적으면 적을수록 좋음
- 카디널리티 ( Cardinality ) 가 높은 컬럼이 좋음
- 즉, 데이터의 중복이 적으면 적을수록 좋음
Tip! Cardinality 란?
- 카디널리티는 전체 행에 대한 특정 컬럼의 중복 수치를 나타내는 지표
- 중복도가 '낮으면' 카디널리티가 '높다'고 표현
- 중복도가 '높으면' 카디널리티가 '낮다'고 표현
Index의 손익분기점이라고 표현하는데, 상황에 따라 다르겠지만 보통 전체 데이터의 5 - 10% 정도로 걸러지는 경우index를 사용했을 때 좋은 효율을 낼 수 있음- 이 내용은 테이블의 데이터가 100만건 정도일 때의 조건이고, 1000만건 혹은 그 이상으로 데이터가 많아진다면 손익분기점은 더 낮아짐
- 데이터가 1000만건 이상인 테이블에서는 보통 5% 정도로 걸러져야 효율이 좋음
- 그리고 20% 가 넘어가는 경우 오히려 Table Full Scan 이 빠를 수 있음
- 이 내용은 테이블의 데이터가 100만건 정도일 때의 조건이고, 1000만건 혹은 그 이상으로 데이터가 많아진다면 손익분기점은 더 낮아짐
- 활용도가 높은, 즉 많이 사용되는 컬럼을
Index로 사용하는게 좋음
Index 로 설정했지만 왜 Full Scan 으로 동작할까?
- MySQL 의 경우
explain을 통해 쿼리가 어떻게 실행되는지 살펴볼 수 있음- 분명
where에Index컬럼을 사용했지만 Full Scan 으로 동작
- 분명
컬럼의 가공
B+Tree는 해당Index의 데이터값을 그대로 저장하고 있음- 그런데 데이터를 가공하여 비교하는 경우
Index를 통한 검색이 불가능
- 그런데 데이터를 가공하여 비교하는 경우
# 예시 1
where price * 0.9 > 10000
# 예시 2
where price > 10000 / 0.9price가Index로 설정되어 있다고 하더라도price * 0.9에 대한 결과값은 알 수 없음- 따라서 예시 1 쿼리의 경우 예시 2 쿼리처럼
0.9를 오른쪽으로 보내어 쿼리를 실행해야Index를 통한 검색을 할 수 있음
- 따라서 예시 1 쿼리의 경우 예시 2 쿼리처럼
!= (부정형)
- 부정형으로
where을 사용하는 경우 해당 데이터를 제외한 모든 데이터를 검색해야 함- Full Scan 으로 동작하는 사례
like 앞 %
B+Tree는 데이터의 첫 글자를 기준으로 정렬하여 저장하고 있음- 그런데
like쿼리를 통해 앞에%를 붙이는 경우 모든 데이터를 찾아야하는 Full Scan 으로 동작하게 됨
- 그런데
count(*)
count(*)라는건 모든 데이터를 한바퀴 돌아야 몇 개인지 알 수 있음- 따라서 Full Scan 으로 동작함
멀티 컬럼에서 두번째 컬럼을 조건으로 사용하는 경우
- 예시:
age,name으로 멀티 컬럼Index가 설정된 경우B+Tree는age로 정렬한 후name으로 정렬한 데이터를 저장하고 있음- 그런데
name만을 조건으로 사용하면Index를 통한 검색을 할 수 없음 - 반대로
age가 첫번째 조건이기 때문에where age만 하면Index검색이 됨
- 그런데
멀티 컬럼 Index 에서 순서를 바꾸는 경우
age,name순으로Index를 지정하고 나서where name, age로 조건을 주는 경우,B+Tree는age, name순으로 정렬된 데이터를 가지고 있기 때문에Index검색을 할 수 있음- 반대의 순서로
where을 주더라도 데이터베이스에 존재하는 옵티마이저가 컬럼 순서를 바꿔서 조회 Index검색이 되기는 함- 옵티마이저가 없다면
Index로 실행되지 않는 경우
- 반대의 순서로

🌱 Backend-Dev | hwaya2828@gmail.com