
Hadoop
Hadoop 이란?
- 하둡 ( Hadoop ) 은 비정형 데이터를 포함한 빅데이터를 다루기 위한 가장 적절한 플랫폼
- 하둡은 2007년 첫 탄생 이후 3점대 버전까지 나온 성숙한 기술
- 인덱싱 라이브러리
Lucene오픈소스로 공개- = Information Indexing Library
- 검색 엔진에 들어가는 색인기
- 검색기에 해당하는 코어 기술
Lucene을 기반으로Nutch프로젝트 탄생- 오픈 소스 검색 엔진
Nutch를 진행하면서Hadoop프로젝트 시작
- 하둡은 분산 파일 처리 시스템 ( Hadoop Distributed File System ) 과 저장되어 있는 데이터를 병렬로 처리하는 맵 리듀스 ( Hadoop MapReduce ) 를 포함
- 분산 파일 처리 시스템의 데이터를 SQL 로 다루기 위해 만들어진
Hive( 이어서Spark탄생 ) - 정형화된 데이터에 대해서는 가능
- 비정형 또는 반정형 데이터의 경우 SQL 로 다루기 어렵기 때문에 하둡 맵 리듀스 필요
- 분산 파일 처리 시스템의 데이터를 SQL 로 다루기 위해 만들어진
- 기존에는 많은 데이터를 저장하기 위해 큰 비용이 들었음
- 하둡 덕분에 이제는 더 이상 그렇지 않게 되면서 많은 데이터를 저장한 다음 분석 가능해졌음
- 기록되지 않던 사람들의 생활이 데이터로 남기 시작
- IoT 의 핵심 중 하나는 많은 센서 ( Sensor )
- 센서의 특징은 숨만 쉬어도 데이터를 뿜어내는 것
- 데이터가 많아지면 경쟁은 어디에서 일어나는가?
- 하둡과 같은 오픈 소스 빅데이터 플랫폼 기술이 발전하면서 데이터 저장 및 분석 인프라의 가격 경쟁력이 확보됨
- 이에 따라 데이터 분석의 역량ㅇ 새로운 가치 창출의 기회를 만들어내는 시대가 됨
- 많은 회사가 아래와 같은 데이터 분석 환경을 구축
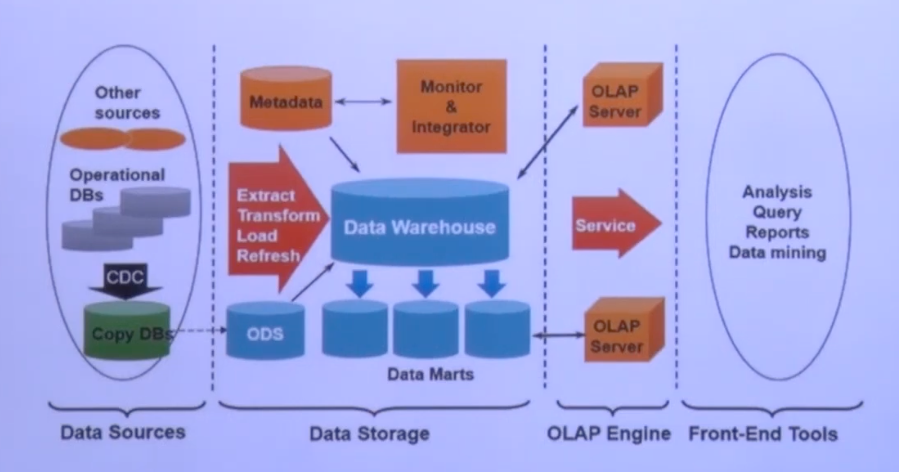
- 데이터 사이언티스트 ( Data Scientist )
- 데이터에서 패턴을 찾아내어 비지니스 기회로
하둡 분산 파일 시스템 ( HDFS ) 이해
Tip! 구글 플랫폼의 철학
- 한 대의 고가 장비보다 여러 대의 저가 장비가 낫다
- 데이터는 분산 저장한다
- 시스템 ( H/W ) 은 언제든 죽을 수 있다 ( Smart S/W )
- 시스템은 확장이 쉬워야 한다
- 하둡 특성
- 수천 대 이상의 리눅스 기반 범용 서버들을 하나의 클러스터로 사용
- 마스터-슬레이브 구조
- 파일은 블록 ( block ) 단위로 저장
- 블록 데이터의 복제본 유지로 인한 신뢰성 보장 ( 기본 3개의 복제본 )
- 높은 내고장성 ( Fault-Tolerance )
- 데이터 처리의 지역성 보장
- 하둡 클러스터 네트워크 및 데몬 구성
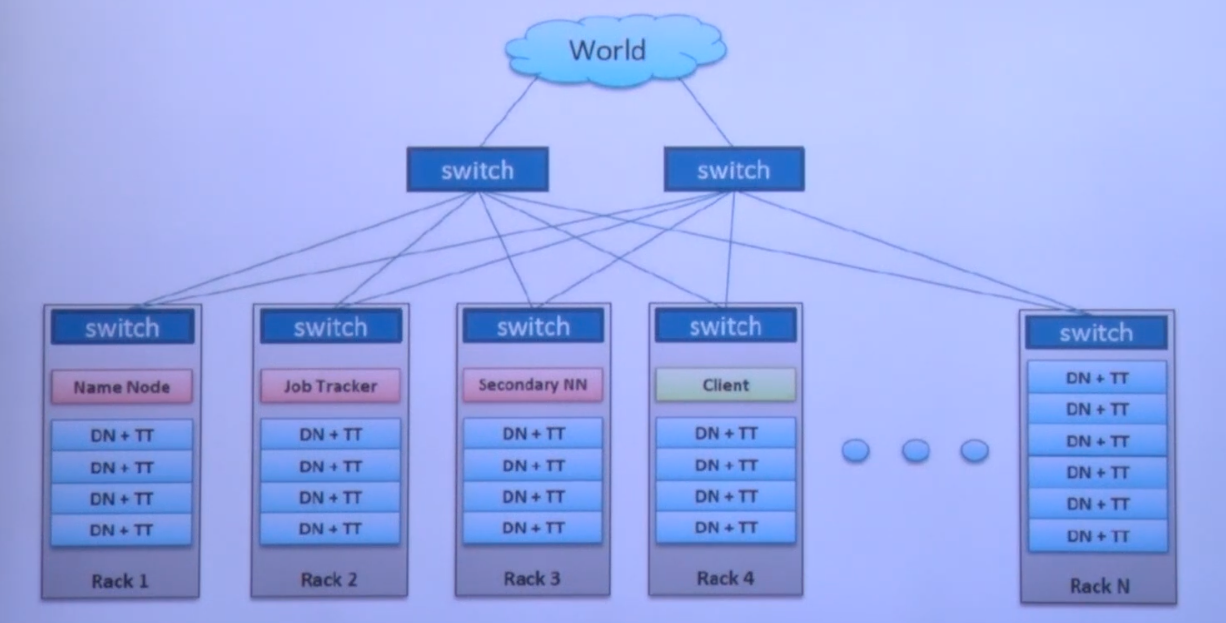
- 하둡에서 블록 ( Block ) 이란?
- 하나의 파일을 여러 개의 Block 으로 저장
- 설정에 의해 하나의 Block 은 64MB 또는 128MB 등의 큰 크기로 나누어 저장
- 블록 크기가 128MB 보다 적은 경우는 실제 크기 만큼만 용량을 차지함
- 하둡에서 블록 ( Block ) 하나의 크기가 큰 이유는?
- HDFS 의 블록은 128MB 와 같이 매우 큰 단위
- 블록이 큰 이유는 탐색 비용을 최소화할 수 있기 때문
- 블록이 크면 하드디스크에서 블록의 시작점을 탐색하는 데 걸리는 시간을 줄일 수 있고, 네트워크를 통해 데이터를 전송하는데 더 많은 시간을 할당이 가능함
- 하둡 저장 특징
- 데이터를 조각내어 서버 내 분산 저장
- 데이터를 복사하여 여러 개를 저장
- 블록 크기 분할과 추상화에 따른 이점
- 블록 단위로 나누어 저장하기 때문에 디스크 사이즈보다 더 큰 파일을 보관할 수 있음
- 블록 단위로 파일을 나누어 저장하기 때문에 700G * 2 = 1.4T 크기의 HDFS 에 1T 의 파일 저장 가능
- 파일 단위보다 블록 단위로 추상화를 하면 스토리지의 서브 시스템을 단순하게 만들 수 있으며, 파일 탐색 지점이나 메타 정보를 저장할 때 사이즈가 고정되어 있으므로 구현이 용이함
- 내고장성을 제공하는데 필요한 복제 ( Replicatin ) 을 구현할 때 매우 적합
- 같은 파일을 분산 처리하여 데이터 처리 성능을 개선할 수 있음
- 같은 노드에 같은 블록이 존재하지 않도록 복제하여 노드가 고장일 경우 다른 노드의 블록으로 복구할 수 있음
- 블록의 지역성 ( Locality )
- 네트워크를 이용한 데이터 전송 시간 감소
- 대용량 데이터 확인을 위한 디스크 탐색 시간 감소
- 적절한 단위의 블록 크기를 이용한 CPU 처리 시간 증가
- 참고
- 클라우드 스토리지를 이용 ( 예시: S3 ) 하는 경우 HDFS 를 사용하는 것보다 성능 저하가 있을 수 있음
- 블록 캐싱
- 데이터 노드에 저장된 데이터 중 자주 읽는 블록은 블록 캐시 ( Block Cache ) 라는 데이터 노드의 메모리에 명시적으로 캐싱할 수 있음
- 파일 단위로 캐싱할 수도 있어서 조인에 사용되는 데이터들을 등록하여 읽기 성능을 높일 수 있음
- 네임 노드 ( NameNode ) 역할
- 전체 HDFS 에 대한 Name Space 관리
- DataNode 로 부터 Block 리포트를 받음
- Data 에 대한 Replication 유지를 위한 커맨더 역할 수행
- 파일 시스템 이미지 파일 관리 ( fsimage )
- 파일 시스템에 대한 Edit Log 관리
- 보조 네임 노드 ( SNN )
- 네임 노드 ( NN ) 와 보조 네임 노드 ( SNN )
- Active & Standby 구조 아님
- fsimage 와 edits 파일을 주기적으로 병합
- 체크 포인트
- 1시간 주기로 실행
- edits 로그가 일정 사이즈 이상이면 실행
- 이슈 사항
- 네임 노드가 SPOF
- 보조 네임 노드의 장애 상황 감지 툴 없음
- 네임 노드 ( NN ) 와 보조 네임 노드 ( SNN )
- 데이터 노드 ( DataNode ) 역할
- DataNode 는 물리적으로 로컬 파일 시스템에 HDFS 데이터를 저장
- DataNode 는 HDFS 에 대한 지식이 없음
- 일반적으로 레이드 구성을 하지 않음 ( JBOD 구성 )
- 블록 리포트
- NameNode 가 시작될 때, 그리고 주기적으로 로컬 파일 시스템에 있는 모든 HDFS 블록들을 검사 후 정상적인 블록의 목록을 만들어 NameNode 에 전송
- Rack Awareness
- 블록을 저장할 때, 2개의 블록은 같은 랙에, 나머지 하나의 블록은 다른 랙에 저장하도록 구성
- 랙 단위 장애 발생 ( 전원, 스위치 등 ) 에도 전체 블록이 유실되지 않도록 구성
- 블록을 저장할 때, 2개의 블록은 같은 랙에, 나머지 하나의 블록은 다른 랙에 저장하도록 구성
- HDFS 세이프 모드
- HDFS 의 세이프 모드 ( SafeMode ) 는 데이터 노드를 수정할 수 없는 상태
- 세이프 모드가 되면 데이터는 읽기 전용 상태가 되고, 데이터 추가와 수정이 불가능 하며 데이터 복제도 일어나지 않음
- 관리자가 서버 운영 정비를 위해 세이프 모드를 설정할 수 있음
- 네임 노드에 문제가 생겨서 정상적인 동작을 할 수 없을 때 자동으로 세이프 모드로 전환
- 주로 Missing Block 이 발생하는 경우, 혹은 클러스터 재구동 시 블록 리포트를 다 받기 전까지 Safe Mode 로 동작
- 세이프 모드 상태일 때 파일 복사를 시도하면 아래와 같은 에러 메시지 발생
put: Cannot create file/user/sample.txt._COPYING_. Name Node is in safe mode.- HDFS 세이프 모드 명령어 및 복구
- HDFS 운영 중 Safe Mode 에 진입한 경우, 네임 노드의 문제인지 데이터 노드의 문제인지 파악이 필요하며,
fsck명령으로 HDFS 의 무결성을 체크하고,hdfs dfsadmin -report명령으로 각 데이터 노드의 상태를 확인하여 문제를 확인하고 해결한 후 세이프 모드를 해제 해야 함
- HDFS 운영 중 Safe Mode 에 진입한 경우, 네임 노드의 문제인지 데이터 노드의 문제인지 파악이 필요하며,
# 세이프 모드 상태 확인
$ hdfs dfsadmin -safemode get
Safe mode is OFF
# 세이프 모드 진입
$ hdfs dfsadmin -safemode enter
Safe mode is ON
# 세이프 모드 해제
$ hdfs dfsadmin -safemode leave
Safe mode is OFF- 커럽트 블록
- HDFS 는 하트비트를 통해 데이터 블록에 문제가 생기는 것을 감지하고 자동으로 복구를 진행함
- 다른 데이터 노드에 복제된 데이터를 가져와서 복구하지만, 모든 복제 블록에 문제가 생겨서 복구하지 못하게 되면 커럽트 상태가 됨
- 커럽트 상태의 파일들은 삭제하고, 원본 파일을 다시 HDFS 에 올려주어야 함
- HDFS 휴지통 설정 및 명령어
- HDFS 는 데이터 삭제 시 영구적 데이터를 삭제하지 않도록 휴지통 ( Trash ) 설정을 할 수 있음
fs.trash.interval- 체크포인트를 삭제하는 시간 간격 ( 분 )
- 0 이면 휴지통 기능을 끔
fs.trash.checkpoint.interval- 체크포인트를 확인하는 간격 ( 분 )
fs.trash.interval과 같거나 작아야 함- 체크포인터가 실행될 때마다 체크 포인트를 생성하고 유효기간이 지난 체크포인트는 삭제
- HDFS Balancers
- 하둡을 운영하다보면, 서로 다른 스펙의 데이터 노드를 하나의 클러스터로 구성하게 됨
- 이 경우 노드 간 디스크 크기가 다를 수 있고, 전체 데이터의 밸런싱이 되지 않는 문제가 발생할 수 있음
- 신규 데이터 노드를 추가하는 경우에도 발생할 수 있음
- 이 경우 NameNode 에서 데이터 적재량이 적은 노드를 우선적으로 선정하여 Block 을 추가하는데, 이 때 특정 노드에 부하가 몰릴 수 있음
- HDFS Balancers 설정
- 하둡 파일 (
hdfs-site.xml) 설정 중 Balancer 와 연관딘 중요한 설정이 있음 - 이 설정들은 보통 하둡 클러스터 운영에 문제가 없도록 방어적으로 설정하는 것이 일반적임
- 명령어로도 설정을 반영할 수 있음
- 하둡 파일 (
# hdfs-site.xml
<property>
<name>dfs.datanode.balance.max.concurrent.moves</name>
<value>50</value>
</property>
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>104857600</value>
</property>
# 명령어 예제
$HADOOP_HOME/bin/hdfs dfsadmin -setBalanceBandwith 104857600- WEB HDFS REST API
- HDFS 는 REST API 를 이용하여 파일을 조회하고 생성∙수정∙삭제하는 기능을 제공함
- 이 기능을 이용하여 원격지에서 HDFS 의 내용에 접근하는 것이 가능
# hdfs-site.xml
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:50070</value>
</property>
# 파일 리스트 예제
$ curl -s http://127.0.0.1:50070/webhdfs/v1/user/hadoop/?op=LISTSTATUS- HDFS 암호화
- KMS ( Key Management Server )
- 하둡 KMS 는 KeyProvider API 를 기반으로 하는 암호화 키 관리 서버 ( RestAPI 제공 )
- 네임 노드 고가용성 ( High Availability )
- HDFS 고가용성은 이중화된 두 대의 서버인 액티브 ( Active ) 네임 노드와 스탠바이 ( Stanby ) 네임 노드를 이용하여 지원
- 액티브 네임 노드와 스탠바이 네임 노드는 데이터 노드로부터 블록 리포트와 하트비트를 모두 받아서 동일한 메타 데이터를 유지하고, 공유 스토리지를 이용하여 에디트 파일을 공유
- 액티브 네임 노드는 네임 노드의 역할을 수행하고, 스탠바이 네임 노드는 액티브 네임 노드와 동일한 메타 데이터 정보를 유지하다가, 액티브 네임 노드에 문제가 발생하면 스탠바이 네임 노드가 액티브 네임 노드로 동작
- 액티브 네임 노드에 문제가 발생하는 것을 자동으로 확인하는 것이 어렵기 때문에 보통 주키퍼를 이용하여 장애 발생 시 자동으로 변경될 수 있도록 구성함
- 에디트 로그 공유 방식 1: NFS ( Network File System )
- NFS 를 이용하는 방법은 에디트 파일을 공유 스토리지를 이용하여 공유하는 방법
- 공유 스토리지에 에디트 로그를 공유하고 펜싱을 이용하여 하나의 네임 노드만 에디트 로그를 기록함
- Split Brain 위험이 존재하고 한계점이 있음
- NFS ( Network File System ) 공유 방식의 문제점
- NN 두 개가 모두 Active NN 가 될 수 있는 상황이 발생하여, 동시에 Shared Storage 의 데이터를 수정하면 NameNode 의 중요 정보가 Crash 되며, 분산 환경에서는 이 상태를 Split Brain 이라고 함
- 두 개의 Active NN 가 발생하는 상황을 막기 위해
dfs.ha.fencing.methods설정을 통해 Active NN 을 Kill 시키거나 Shared Storage 를 unmount 해줌sshfence인 경우 아래처럼 NameNode 를 Kill 시킴fuser -v -k -n tcp <namenode port>
- 그렇지만 네트워크 장애의 경우, 기존 Active NameNode 가 ZooKeeper 와 Standby NameNode 로만 통신이 되지 않고, SharedStorage 와 통신이 되는 상황이라면?
- 이런 경우 Standby NameNode 에서 Fencing 처리는 네트워크 단절로 수행할 수 없으며, 기존 Active NameNode 는 여전히 Live 한 상태가 됨
- Split Brain 발생 가능성 존재
- 에디트 로그 공유 방식 2: Joural Node 그룹 사용
- QJM ( Quorum Journal Manager ) 은 NameNode 내부에 구현된 HDFS 전용 구현체로, 고가용성 에디트 로그를 지원하기 위한 목적으로 설계됨
- QJM 은 저널 노드 그룹에서 동작하며, 각 에디트 로그는 전체 저널 노드에 동시에 쓰여짐
- 주키퍼의 동작 방식과 유사함
- HDFS 고가용성은 액티브 네임 노드를 선출하기 위해 주키퍼를 이용
- Joural Node 사용 시 Failover 절차
- Active NameNode 는 에디트 로그 처리용
epoch number를 할당 받음- 이 번호는 uniq 하게 증가하는 번호로 새로 할당 받은 번호는 이전 번호보다 항상 큼
- Active NameNode 는 파일 시스템 변경 시 JouralNode 로 변경 사항을 전송
- 전송 시
epoch number를 같이 전송
- 전송 시
- JouralNode 는 자신이 가지고 있는
epoch number보다 큰 번호가 오면 자신의 번호를 새로운 번호로 갱신하고 해당 요청을 처리 - JouralNode 는 자신이 가지고 있는 번호보다 작은
epoch number를 받으면 해당 요청은 처리하지 않음- 이런 요청은 주로 Split Brain 상황에서 발생하게 됨
- 기존 NameNode 가 정상적으로 Standby 로 변하지 않았고, 이 NameNode 가 정상적으로 Fencing 되지 않은 상태
- Standby NameNode 는 주기적 ( 1분 ) 으로 JournalNode 로부터 이전에 받은 에디트 로그의
txid이후의 정보를 받아 메모리의 파일 시스템 구조에 반영 - Active NameNode 장애 발생 시 Standby NameNode 는 마지막 받은
txid이후의 모든 정보를 받아 메모리 구성에 반영 후 Active NameNode 로 상태 변환 - 새로 Active NameNode 가 되면 1번 항목을 처리
- Active NameNode 는 에디트 로그 처리용
- HDFS Federation
- 이중화와는 다른 개념
- 하나의 네임 노드에서 관리하는 파일, 블록 개수가 많아지면 물리적 한계가 있음
- 이를 해결하기 위해 HDFS Federation 을 하둡 2.0 이상에서 지원
- HDFS 페더레이션을 사용하면 파일, 디렉토리의 정보를 가지는 네임 스페이스와 블록의 정보를 가지는 블록 풀을 각 네임 노드가 독립적으로 관리
- 네임 스페이스와 블록 풀을 네임 스페이스 볼륨이라 하고 네임 스페이스 볼륨은 독립적으로 관리되기 때문에 하나의 네임 노드에 문제가 생겨도 다른 네임 노드에 영향을 주지 않음
- 아파치 주키퍼 ( ZooKeeper ) 란?
- 주키퍼는 분산 시스템의 코디네이터로 주로 아래와 같은 목적으로 사용됨
- 설정 관리 ( Configuration Management )
- 분산 클러스터 관리 ( Distributed Cluster Management )
- 명명 서비스 ( Naming service: DNS )
- 분산 동기화 ( Distributed Synchronization: locks, barriers, queues )
- 분산 시스템에서 리더 선출 ( Leader election in distributed system )
- 중앙집중형 신뢰성 있는 데이터 저장소 ( Centralized and highly reliable data registry )
- 주키퍼는 분산 시스템의 코디네이터로 주로 아래와 같은 목적으로 사용됨
- 아파치 주키퍼 ( ZooKeeper ) 구성
- 주키퍼는 n개의 서버로 단일 클러스터를 구성하며 이를 서버 앙상블이라고 함
- 주키퍼 서비스는 복수의 서버에 복제되며, 모든 서버는 데이터 카피본을 저장
- Leader 는 구동 시 주키퍼 내부 알고리즘에 의해 자동 선정
- Followers 서버들은 클라이언트로부터 받은 모든 업데이트 이벤트를 리더에게 전달
- 클라이언트는 모든 주키퍼 서버에서 읽을 수 있으며, 리더를 통해 쓸 수 있고 과반수 서버의 승인 ( 합의 ) 가 필요함
- 아파치 주키퍼 ( ZooKeeper ) 데이터 모델
- 절대 경로로
/로 구분됨 - 변경이 발생하면 버전 번호가 증가함
- 데이터는 항상 전체를 읽고 씀
- ZNode 는 1M 이하의 데이터를 가질 수 있으며, 자식 노드를 가질 수 있음
- 영속 종류에 따라 분류
- 영구 노드 ( Persistent Nodes )
- 명시적으로 삭제되기 전까지 존재함
- 임시 노드 ( Ephemeral Nodes )
- 세션이 유지되는 동안 활성 ( 세션이 종료되면 삭제됨 )
- 자식 노드를 가질 수 없음
- 순차 노드 ( Sequence Nodes )
- 경로의 끝에 일정하게 증가하는 카운터 추가됨
- 영구 및 임시 노드 모두에 적용 가능
- 영구 노드 ( Persistent Nodes )
- 절대 경로로

🌱 Backend-Dev | hwaya2828@gmail.com