
ElasticSearch
이전 작성 글: ElasticSearch 란?
이전 작성 글: ElasticSearch 에 대한 정리
기타 참고 자료
[MongoDB] 전문검색 ( Full text Search )
[MySQL] Full Text Search 전문검색 기능
검색과 쿼리
검색 Search
- 검색 ( Retrieval ) 의 사전적인 의미
- 책이나 컴퓨터에 들어 있는 자료 중 필요한 자료를 찾아냄
- 범죄나 사건을 밝히기 위한 단서나 증거를 찾기 위하여 살펴 조사함
- 데이터 시스템에서의 검색
- 수많은 대상 데이터 중에서 조건에 부합하는 데이터로 범위를 축소하는 행위
- 인터넷 쇼핑몰에 상품이 100만개가 있을 때 검색창에 "무선 이어폰" 이라고 입력해서 시스템에 있는 전체 100만개의 상품들 중 무선 이어폰과 연관된 상품만 추려내는 과정을 검색이라고 할 수 있음
- 검색 엔진 설정에 따라 상품명이 정확히 "무선 이어폰" 인 것만 보여줄지, "소니 무선 이어폰" 처럼 전체 상품명 중에 검색어를 포함하기만 하면 보여줄지 가격 ∙ 출시일 등과 같이 다른 조건들에 대해서는 어떻게 영향을 받도록 할 것인지 등을 결정할 수 있음
- 상품명이 정확히 "무선 이어폰" 인 것만 검색 하도록 조건을 엄격하게 하면 표시되는 결과 수가 적어져서 내가 찾는 상품이 나타나지 않을 수 있음
- 반대로 상품 설명에 "무선" 과 "이어폰" 이 하나라도 있는 상품을 모두 검색하도록 하면 "무선 리모컨" ∙ "이어폰 케이스" 같은 상품까지 검색이 되면서 결과가 너무 많아져서 내가 찾는 상품이 묻혀 버릴 수 있음
- 품질이 높은 검색 시스템을 구현하기 위해서는 이렇게 많은 부분들을 고민해야 함
Elasticsearch는 사용자가 이런 여러가지 검색 조건들에 대해 목표로 하는 검색 기능을 구현할 수 있도록 다양한 기능들을 제공Elasticsearch는 데이터를 실제로 검색에 사용되는 검색어인 텀 ( Term ) 으로 분석 과정을 거쳐 저장하기 때문에 검색 시 대소문자 ∙ 단수나 복수 ∙ 원형 여부와 상관 없이 검색이 가능- 이러한
Elasticsearch의 특징을 풀 텍스트 검색 ( Full Text Search ) 이라고 하며 한국어로 전문 검색 이라고도 함
Tip! Full Text Search ( 전문검색 ) 란?
- 전문검색 이란 게시물의 내용이나 제목 등과 같이 문장이나 문서의 내용에서 키워드를 검색하는 기능
- 전문검색 이란 내용 전체를 색인해서 특정 단어가 포함된 문서를 검색하는 것을 말함
- 전문검색은 이름이나 별명과 같은 단어에서 일부만 일치하는 사용자를 검색하는 기능으로도 사용 가능
Like기능과 같이 패턴 일치 검색 기능 ( 양쪽에%%을 사용한 ) 은 인덱스를 사용하지 못할 수도 있지만 전문검색은 일부만 검색하는 경우에도 전문검색 인덱스를 이용할 수 있기 때문에Like %패턴%과 같은 조회 요건에 대해서 더 빠른 검색이 가능
데이터 색인과 텍스트 분석
- 풀 텍스트 검색 (=전문검색) 을 하기 위해서는 데이터를 검색에 맞게 가공하는 작업을 필요로 하는데
Elasticsearch는 데이터를 저장하는 과정에서 이 작업을 처리- 검색을 위해 텍스트 데이터를 어떻게 처리하고 데이터를 색인 할 때
Elasticsearch에서 어떤 과정이 이루어지는지에 대해 살펴볼 예정
- 검색을 위해 텍스트 데이터를 어떻게 처리하고 데이터를 색인 할 때
역 인덱스 ( Inverted Index )
- 관계형 DB에서는 테이블에서 Text 에
fox가 포함된 행들을 가져온다고 하면 다음과 같이 Text 열을 한 줄씩 찾아 내려가면서fox가 있으면 가져오고 없으면 넘어가는 식으로 데이터를 가져 올 것

- 전통적인 RDBMS 에서는 위와 같이
like검색을 사용하기 때문에 데이터가 늘어날수록 검색해야 할 대상이 늘어나 시간도 오래 걸림- row 안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가 느림
Elasticsearch는 데이터를 저장할 때 다음과 같이 역 인덱스 ( Inverted Index ) 라는 구조를 만들어 저장
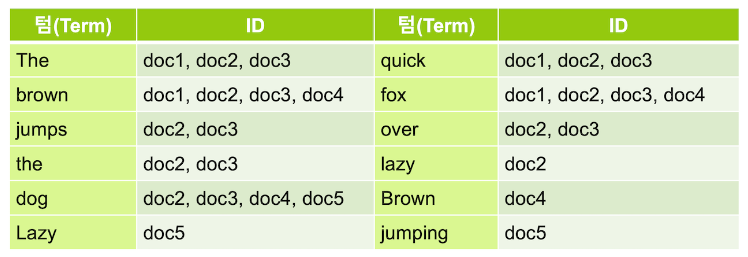
- 이 역 인덱스는 책의 맨 뒤에 있는 주요 키워드에 대한 내용이 몇 페이지에 있는지 볼 수 있는 찾아보기 페이지 에 비유할 수 있음
Elasticsearch에서는 추출된 각 키워드를 텀 ( Term ) 이라고 부름- 이렇게 역 인덱스가 있으면
fox를 포함하고 있는 도큐먼트들의 ID 를 바로 얻어올 수 있음

Elasticsearch는 데이터가 늘어나도 찾아가야 할 행이 늘어나는 것이 아니라 역 인덱스가 가리키는 ID 의 배열값이 추가되는 것 뿐이기 때문에 큰 속도의 저하 없이 빠른 속도로 검색이 가능- 이런 역 인덱스를 데이터가 저장되는 과정에서 만들기 때문에
Elasticsearch는 데이터를 입력할 때 저장이 아닌 색인을 한다고 표현
- 이런 역 인덱스를 데이터가 저장되는 과정에서 만들기 때문에
텍스트 분석 ( Text Analysis )
Elasticsearch에 저장되는 도큐먼트는 모든 문자열 ( Text ) 필드 별로 역 인덱스를 생성- 검색에 사용하는 경우에는 앞에서 설명한 역 인덱스의 예제는 실제로는 보통 아래와 같이 저장됨
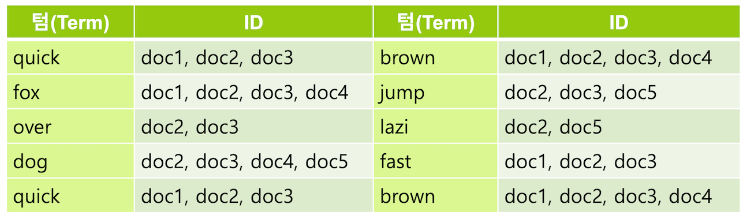
Elasticsearch는 문자열 필드가 저장될 때 데이터에서 검색어 토큰을 저장하기 위해 여러 단계의 처리 과정을 거침- 이 전체 과정을 텍스트 분석 ( Text Analysis ) 이라고 하고 이 과정을 처리하는 기능을 애널라이저 ( Analyzer ) 라고 함
Elasticsearch의 애널라이저는 0-3개의 캐릭터 필터 ( Character Filter ) 와 1개의 토크나이저 ( Tokenizer ) 그리고 0-n개의 토큰 필터 ( Token Filter ) 로 이루어짐
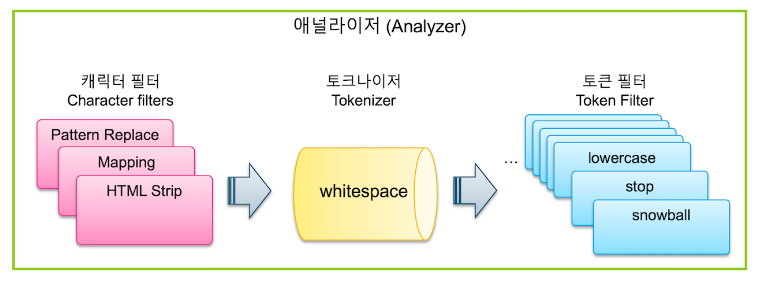
- 텍스트 데이터가 입력되면 가장 먼저 필요에 따라 전체 문장에서 특정 문자를 대치하거나 제거하는데 이 과정을 담당하는 기능이 캐릭터 필터
- 다음으로는 문장에 속한 단어들을 텀 단위로 하나씩 분리 해 내는 처리 과정을 거치는데 이 과정을 담당하는 기능이 토크나이저
- 토크나이저는 반드시 1개만 적용이 가능
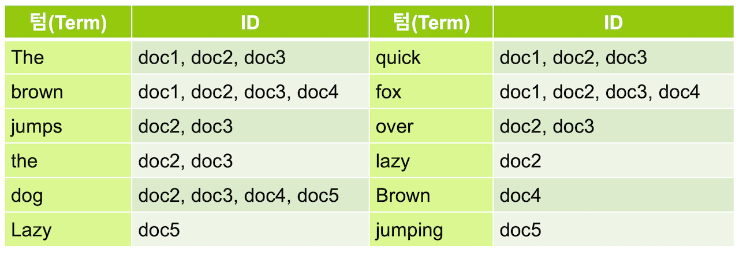
- 다음은
whitespace토크나이저를 이용해서 공백을 기준으로 텀 들을 분리 한 결과
- 다음으로 분리된 텀 들을 하나씩 가공하는 과정을 거치는데 이 과정을 담당하는 기능이 토큰 필터
- 토큰 필터는 0개 부터 여러 개를 적용할 수 있음
- 여기서는 먼저
lowercase토큰 필터를 이용해서 대문자를 모두 소문자로 바꿔줌- 이렇게 하면 대소문자 구별 없이 검색이 가능하게 됨
- 대소문자가 일치하게 되어 같은 텀이 된 토큰들은 모두 하나로 병합
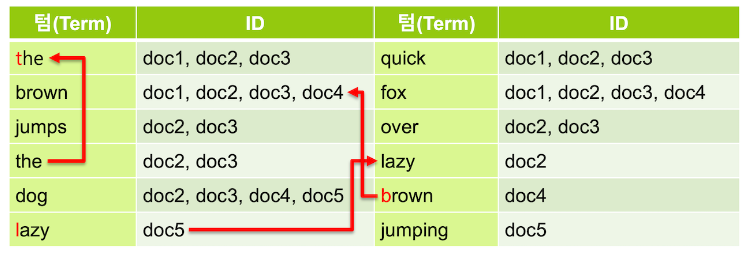
- 역 인덱스는 아래와 같이 변경됨
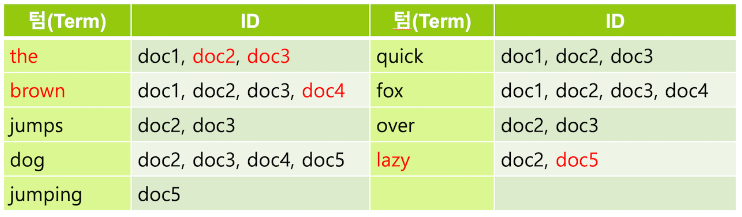
- 텀 중에는 검색어로서의 가치가 없는 단어들이 있는데 이런 단어를 불용어 ( Stopword ) 라고 함
- 보통 a, an, are, at, be, but, by, do, for, i, no, the, to 등의 단어들은 불용어로 간주되어 검색어 토큰에서 제외됨
stop토큰 필터를 적용하면 우리가 만드는 역 인덱스에서 the 가 제거
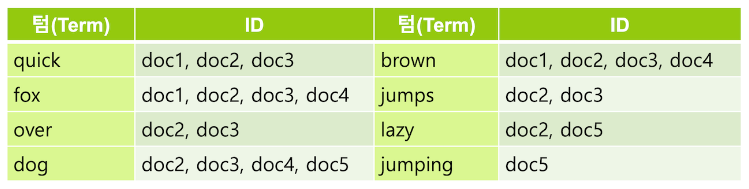
- 이제 형태소 분석 과정을 거쳐서 문법상 변형된 단어를 일반적으로 검색에 쓰이는 기본 형태로 변환하여 검색이 가능하게 함
- 영어에서는 형태소 분석을 위해
snowball토큰 필터를 주로 사용하는데 이 필터는 -s, -ing 등을 제거 - 그리고 happy, lazy 와 같은 단어들은 happiness, laziness 와 같은 형태로도 사용되기 때문에 -y 를 -i 로 변경함
snowball토큰 필터를 적용하고 나면 jumps 와 jumping 은 모두 jump 로 변경되고 동일하게 jump 로 되었기 때문에 하나의 텀으로 병합
- 영어에서는 형태소 분석을 위해
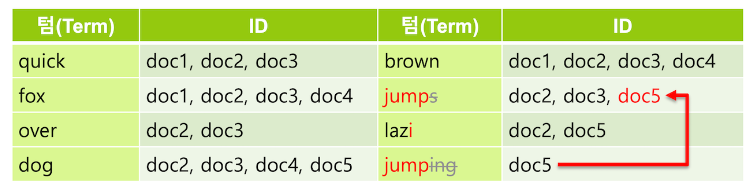
- 필요에 따라서는 동의어를 추가 해 주기도 함
synonym토큰 필터를 사용하여 quick 텀에 동의어로 fast 를 지정하면 fast 로 검색했을 때도 같은 의미인 quick 을 포함하는 도큐먼트가 검색되도록 할 수 있음- AWS 와 Amazon 을 동의어로 놓아 amazon 을 검색해도 AWS 를 찾을 수 있게 하는 등 실제로도 사용되는 사례가 많음

애널라이저 ( Analyzer )
Elasticsearch에는 애널라이저를 조합하고 그 동작을 자세히 확인할 수 있는 API 들이 존재
캐릭터 필터 ( Character Filter )
- 캐릭터 필터는 텍스트 분석 중 가장 먼저 처리되는 과정으로 색인된 텍스트가 토크나이저에 의해 텀으로 분리되기 전에 전체 문장에 대해 적용되는 일종의 전처리 도구
- 7.0 버전 기준으로 캐릭터 필터는 HTML Strip, Mapping, Pattern Replace 총 3개가 존재
char_filter항목에 배열로 입력하며 하나만 적용하거나 차례대로 입력해서 3개를 모두 적용할 수도 있음
토크나이저 ( Tokenizer )
- 데이터 색인 과정에서 검색 기능에 가장 큰 영향을 미치는 단계가 토크나이저
- 데이터 분석 과정에서 토크나이저는 반드시 한 개만 사용이 가능하며
tokenizer항목에 단일값으로 설정 - 토크나이저들 중 NGram, Lowercase 같은 토크나이저들은 대부분은 Standard 토크나이저에 같은 이름의 토큰 필터를 내장
- 데이터 분석 과정에서 토크나이저는 반드시 한 개만 사용이 가능하며
Standard, Letter, Whitespace
- 일반적으로 가장 많이 사용되고 기능이 유사하지만 분명히 다른 특징이 있는 Standard, Letter, Whitespace 3가지 토크나이저
- 분석할 문장은 "THE quick.brown_FOx jumped! @ 3.5 meters."
- Standard 토크나이저는 공백으로 텀을 구분하면서 "@"과 같은 일부 특수문자를 제거
- "jumped!"의 느낌표, "meters."의 마침표 처럼 단어 끝에 있는 특수문자는 제거되지만 "quick.brown_FOx" 또는 "3.5" 처럼 중간에 있는 마침표나 밑줄 등은 제거되거나 분리되지 않는 것을 확인할 수 있음
- Letter 토크나이저는 알파벳을 제외한 모든 공백, 숫자, 기호들을 기준으로 텀을 분리
- "quick.brown_FOx" 같은 단어도 "quick", "brown", "FOx" 처럼 모두 분리된 것을 확인할 수 있음
- Whitespace 토크나이저는 스페이스, 탭, 그리고 줄바꿈 같은 공백만을 기준으로 텀을 분리
- 특수문자 "@" 그리고 "meters." 의 마지막에 있는 마침표도 사라지지 않고 그대로 남아있는 것을 확인할 수 있음
- 3개의 토크나이저 중에 Letter 토크나이저의 경우 검색 범위가 넓어져서 원하지 않는 결과가 많이 나올 수 있고, 반대로 Whitespace 의 경우 특수문자를 거르지 않기 때문에 정확하게 검색을 하지 않으면 검색 결과가 나오지 않을 수 있음
- 따라서 보통은 Standard 토크나이저를 많이 사용
UAX URL Email
- 주로 사용되는 Standard 토크나이저도 @, / 같은 특수문자는 공백과 마찬가지로 제거하고 분리
- 그런데 요즘의 블로그 포스트나 신문기사 같은 텍스트 들에는 이메일 주소 또는 웹 URL 경로 등이 삽입되어 있는 경우가 상당히 많음
- 이 경우 Standard 토크나이저를 사용하면 이메일 주소등이 정상적으로 인식되지 않아 문제가 될 수 있는데, 이를 방지하기 위해 사용 가능한 것이 UAX URL Email 토크나이저
Pattern
- 앞에서 살펴본 토크나이저들은 다소 차이는 있지만 기본적으로는 공백을 기준으로 하여 텀 들을 분리
- 분석 할 데이터가 사람이 읽는 일반적인 문장이 아니라 서버 시스템이나 IoT 장비 등에서 수집된 머신 데이터인 경우 공백이 아닌 쉼표나 세로선 같은 기호가 값 항목의 구분자로 사용되는 경우가 종종 있음
- 이런 특수한 문자를 구분자로 사용하여 텀을 분리하고 싶은 경우 사용할 수 있는 것이 Pattern 토크나이저
- Pattern 토크나이저는 분리할 패턴을 기호 또는 Java 정규식 형태로 지정할 수 있음
- 구분자 지정은
pattern항목에 설정 - 다음은 인덱스 pat_tokenizer 에 슬래시
/를 구분자로 하는 my_pat_tokenizer 라는 사용자 정의 토크나이저를 만들고 "/usr/share/elasticsearch/bin" 를 분석하는 예제
- 구분자 지정은
PUT pat_tokenizer
{
"settings": {
"analysis": {
"tokenizer": {
"my_pat_tokenizer": {
"type": "pattern",
"pattern": "/"
}
}
}
}
}"pattern": "/"같은 단일 기호 외에도 알파벳 대문자를 기준으로 텀을 분리하도록 하는"pattern": "(?<=\\p{Lower})(?=\\p{Upper})"와 같은 정규식 ( Regular Expression ) 으로도 설정 가능
Path Hierarchy
- 디렉토리나 파일 경로 등은 흔하게 저장되는 데이터
- 앞의 Pattern 토크나이저에서 "/usr/share/elasticsearch/bin" 를 실행했을 때는 디렉토리명 들이 각각 하나의 토큰으로 분리 된 것을 확인
- 이 경우 다른 패스에 있는데 하위 디렉토리 명이 같은 경우 데이터 검색에 혼동이 올 수 있음
- Path Hierarchy 토크나이저를 사용하면 경로 데이터를 계층별로 저장해서 하위 디렉토리에 속한 도큐먼트들을 수준별로 검색하거나 집계하는 것이 가능
- 다음은 Path Hierarchy 토크나이저로 "/usr/share/elasticsearch/bin" 를 분석하는 예제
POST _analyze
{
"tokenizer": "path_hierarchy",
"text": "/usr/share/elasticsearch/bin"
}delimiter항목값으로 경로 구분자를 지정할 수 있음- 디폴트는
/ - 그리고
replacement옵션을 이용해서 소스의 구분자를 다른 구분자로 대치해서 저장하는 것도 가능 - 다음은 인덱스 hir_tokenizer 에
-구분자를/구분자로 대치하는 my_hir_tokenizer 라는 사용자 정의 토크나이저를 만들고 "one-two-three" 문장을 분석하는 예제
- 디폴트는
PUT hir_tokenizer
{
"settings": {
"analysis": {
"tokenizer": {
"my_hir_tokenizer": {
"type": "path_hierarchy",
"delimiter": "-",
"replacement": "/"
}
}
}
}
}GET hir_tokenizer/_analyze
{
"tokenizer": "my_hir_tokenizer",
"text": [
"one-two-three"
]
}토큰 필터 ( Token Filter )
- 토크나이저를 이용한 텀 분리 과정 이후에는 분리된 각각의 텀 들을 지정한 규칙에 따라 처리를 해 주는데 이 과정을 담당하는 것이 토큰 필터
- 토큰 필터는
filter(token_filter아님 ) 항목에 배열 값으로 나열해서 지정- 하나만 사용하더라도 배열 값으로 입력해야 하며 나열된 순서대로 처리되기 때문에 순서를 잘 고려해서 입력해야 함
- 토큰 필터는
Lowercase, Uppercase
- 영어나 유럽어 기반의 텍스트는 대소문자가 있어 검색할 때는 대소문자에 상관 없이검색이 가능하도록 처리 해 주어야 함
- 보통은 텀 들을 모두 소문자로 변경하여 저장하는데 이 역할을 하는 것이 Lowercase 토큰 필터
- Lowercase 토큰 필터는 거의 모든 텍스트 검색 사례에서 사용되는 토큰 필터
- Uppercase 토큰 필터는 모든 텀을 대문자로 변경하는 것 이며 Lowercase 와 동일하게 설정
Stop
- 블로그 포스트나 뉴스 기사 같은 글에는 검색에서는 큰 의미가 없는 조사나 전치사 등이 많음
- 영문에서도 the, is, a 같은 단어들은 대부분 검색어로 쓰이지 않는데 이런 단어를 한국어로는 불용어, 영어로는 Stopword 라고 함
- Stop 토큰 필터를 적용하면 불용어에 해당되는 텀 들을 제거
stopwords항목에 불용어로 지정할 단어들을 배열 형태로 나열하거나"_english_","_german_"같이 언어를 지정해서 해당 언어팩에 있는 불용어를 지정할 수도 있음- 지원되는 언어팩은 공식 도큐먼트에서 확인할 수 있으며 한, 중, 일어 등은 별도의 형태소 분석기를 사용해야 함
- 불용어 목록을 별도의 텍스트 파일로 저장하고 저장된 파일 경로를
stopwords_path항목의 값으로 지정하여 사용하는 것도 가능
Synonym
- 검색 서비스에 따라서 동의어 검색을 제공해야 하는 경우가 있습니음
- 예를 들면 클라우드 서비스 관련 정보를 검색하는 시스템에서 "AWS" 라는 단어를 검색했을 때 "Amazon" 또는 한글 "아마존" 도 같이 검색을 하도록 하면 관련된 정보를 더 많이 찾을 수 있을 것
- 이 때 Synonym 토큰 필터를 사용하면 텀의 동의어 저장이 가능
- 동의어를 설정하는 옵션은
synonyms항목에서 직접 동의어 목록을 입력하는 방법과 동의어 사전 파일을 만들어synonyms_path로 지정하는 방법이 있음
- 동의어 사전 명시 규칙에는 다음의 것들이 존재
"A, B => C"- 왼쪽의 A, B 대신 오른쪽의 C 텀을 저장
- A, B 로는 C 의 검색이 가능하지만 C 로는 A, B 가 검색되지 않음
"A, B"- A, B 각 텀이 A 와 B 두개의 텀을 모두 저장
- A 와 B 모두 서로의 검색어로 검색이 됨
NGram, Edge NGram, Shingle
NGram
Elasticsearch는 빠른 검색을 위해 검색에 사용될 텀 들을 미리 분리해서 역 인덱스에 저장- 하지만 과학 용어집 검색 같은 특정한 사용 사례에 따라 텀이 아닌 단어의 일부만 가지고도 검색해야 하는 기능이 필요한 경우도 있음
- RDBMS의
LIKE검색 처럼 사용하는 wildcard 쿼리나 regexp (정규식) 쿼리도 지원을 하지만, 이런 쿼리들은 메모리 소모가 많고 느리기 때문에Elasticsearch의 장점을 활용하지 못함 - 이런 사용을 위해 검색 텀의 일부만 미리 분리해서 저장을 할 수 있는데 이렇게 단어의 일부를 나눈 부위를 NGram 이라고 함
- 보통은 unigram (유니그램 – 1글자), bigram (바이그램 - 2자) 등으로 부름
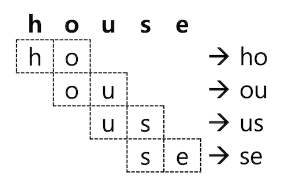
Elasticsearch는 NGram 을 처리하는 토큰 필터를 제공하며 설정은"type": "nGram"으로 함- "house" 라는 단어를 2 글자의 NGram ( bigram ) 으로 처리하면 다음과 같이 "ho", "ou", "us", "se" 총 4개의 토큰들이 추출
- ngram 토큰 필터를 사용하면 이렇게 2글자씩 추출된 텀들이 모두 검색 토큰으로 저장됨
- 이제 이 인덱스의 경우에는 검색어를 "ho" 라고만 검색을 해도 house 가 포함된 도큐먼트들이 검색됨
Tip! 주의 사항
- NGram 토큰 필터를 사용하면 저장되는 텀의 갯수도 기하급수적으로 늘어나고 검색어를 "ho" 로 검색 했을 때 house, shoes 처럼 검색 결과를 예상하기 어렵기 때문에 일반적인 텍스트 검색에는 사용하지 않는 것이 좋음
- NGram 을 사용하기 적합한 사례는 카테고리 목록이나 태그 목록과 같이 전체 개수가 많지 않은 데이터 집단에 자동완성 같은 기능을 구현하는 데에 적합
- NGram 토큰 필터에는
min_gram(디폴트 1),max_gram(디폴트 2) 옵션이 있음- 짐작할 수 있듯이 최소, 최대 문자수의 토큰을 구분하는 단위
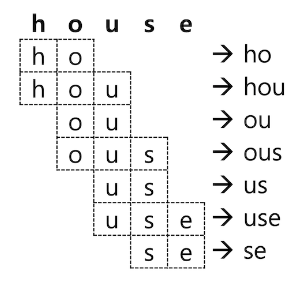
- house 를
"min_gram": 2,"max_gram": 3으로 설정하면 다음과 같이 분석되어 총 7개의 토큰을 저장
Edge NGram
- 검색을 위해 NGram 을 저장하더라도 보통은 단어의 맨 앞에서부터 검색하는 경우가 많음
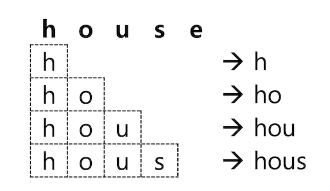
- 텀 앞쪽의 NGram 만 저장하기 위해서는 Edge NGram 토큰 필터를 이용
- 설정 방법은
"type": "edgeNGram" edgeNGram의 옵션을"min_gram": 1,"max_gram": 4으로 설정하고 "house" 를 분석하면 다음과 같이 "h", "ho", "hou", "hous" 4개의 토큰이 생성됨
- 설정 방법은
- 텀 앞쪽의 NGram 만 저장하기 위해서는 Edge NGram 토큰 필터를 이용
Shingle
- NGram 과 Edge NGram 은 모두 하나의 단어로부터 토큰을 확장하는 토큰 필터
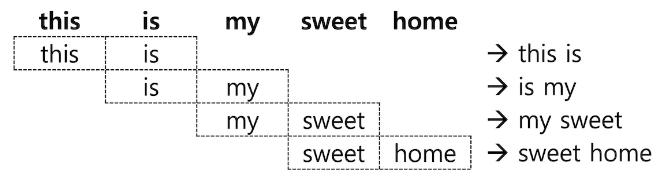
- 문자가 아니라 단어 단위로 구성된 묶음을 Shingle 이라고 하며
"type": "shingle"토큰 필터의 이용이 가능 - "this is my sweet home" 라는 문장을 분리해서 2 단어씩 Shingle 토큰 필터를 적용하면 다음과 같은 4개의 Shingle 들이 생성됨
- 문자가 아니라 단어 단위로 구성된 묶음을 Shingle 이라고 하며
- Shingle 토큰 필터에서 사용 가능한 옵션
min_shingle_size∙max_shingle_size- Shingle 의 최소 ∙ 최대 단어 개수를 지정
- 디폴트는 모두
2
output_unigrams- Shingle 외에도 각각의 개별 토큰 ( unigram ) 도 저장 하는지의 여부를 설정
- 디폴트는
true
output_unigrams_if_no_shingles- Shingle 을 만들 수 없는 경우에만 개별 토큰을 저장하는지의 여부를 설정
- 디폴트는
false
token_separator- 토큰 구분자를 지정
- 디폴트는
" "( 스페이스 )
filler_token- Shingle 을 만들 텀이 없는 경우 대체할 텍스트를 지정
- 보통은 stop 토큰 필터와 함께 사용되어
offset위치만 있고 텀이 없는 경우
- 보통은 stop 토큰 필터와 함께 사용되어
- 디폴트는
_
- Shingle 을 만들 텀이 없는 경우 대체할 텍스트를 지정
Tip! 주의 사항
- NGram, Edged NGram 그리고 Shingle 토큰 필터는 보통 일반적인 텍스트 분석에 사용하기는 적합하지 않음
- 하지만 자동 완성 기능을 구현하거나 프로그램 코드 안에서 문법이나 기능명을 검색하는 것과 같이 특수한 요구사항을 충족해야 하는 경우 유용하게 사용될 수 있음
Unique
- "white fox, white rabbit, white bear" 같은 문장을 분석하면 "white" 텀은 총 3번 저장됨
- 역 색인에는 텀이 1개만 있어도 텀을 포함하는 도큐먼트를 가져올 수 있기 때문에 중복되는 텀 들은 삭제 해 주어도 검색에는 보통 무방
- 이 경우 Unique 토큰 필터를 사용해서 중복되는 텀 들은 하나만 저장하도록 할 수 있음
Tip! 주의 사항
match쿼리를 사용해서 검색하는 경우 Unique 토큰 필터를 적용한 필드는 텀의 개수가 1개로 되기 때문에 TF ( Term Frequency ) 값이 줄어들어 스코어 점수가 달라질 수 있음match쿼리를 이용해 정확도 ( Relevancy ) 를 따져야 하는 검색의 경우에는 Unique 토큰 필터는 사용하지 않는 것이 바람직
형태소 분석 ( Stemming )
- 우리가 사용하는 언어들은 영어만 보더라도 문법에 따라 명사 뒤에 -s, -ness 등이 붙거나 동사 뒤에 -ing, -ed 등이 붙는 등 변화가 많음
- 검색을 할 때는 보통 이런 문법에 따른 단어의 변형에 상관 없이 검색이 가능해야 하기 때문에 텍스트 데이터를 분석할 때 각각의 텀에 있는 단어들을 기본 형태인 어간을 추출하는 과정을 진행해야 함
- 이 과정을 보통 어간 추출 또는 형태소 분석 이라고 하며 영어로는 Stemming 이라고 함
- 그리고 형태소 분석을 하는 도구를 형태소 분석기, 영어로는 Stemmer 라고 함
Elasticsearch에서는 다양한 형태소 분석기들을 지원하며 공식적으로 지원하지 않는 국가의 언어들도 플러그인 형태로 사용 가능하도록 오픈소스로 배포되는 분석기들이 많이 있음Elasticsearch에서 사용 가능한 형태소 분석기 중에서 가장 많이 알려진 형태소 분석 알고리즘인 Snowball 과 한글 형태소 분석기인 Nori 에 대해 살펴볼 예정
Snowball
- Snowball 은 2000년 경에 정보 검색의 선구자인 마틴 포터 박사가 개발하여 무료로 공개한 형태소 분석 알고리즘
- 보통 -ing, -s 등을 제거하여 문장에 쓰인 단어들을 기본 형태로 변경
Elasticsearch에서 Snowball 은 애널라이저, 토크나이저, 토큰 필터가 모두 정의되어 있으며 사용 방법은 용자 정의 애널라이저 부분에 설명되어 있음
노리 (Nori) 한글 형태소 분석기
- 한글은 형태의 변형이 매우 복잡한 언어
- 특히 복합어, 합성어 등이 많아 하나의 단어도 여러 어간으로 분리해야 하는 경우가 많아 한글을 형태소 분석을 하려면 반드시 한글 형태소 사전이 필요
- 오픈 소스 커뮤니티에서 개발되어
Elasticsearch에서 사용 가능한 한글 형태소 분석기는 다음과 같은 것들이 존재- 아리랑 ( Arirang )
- 은전한닢 ( Seunjeon )
- Open Korean Text
- 6.6 버전 부터 공식적으로 Nori (노리) 라고 하는 한글 형태소 분석기를 개발해서 지원을 하기 시작
- 특이하게 Nori 는 프랑스 엔지니어인 Jim Ferenczi 에 의해 처음 개발이 되었음
- Jim 은 아파치 루씬의 커미터이며
Elasticsearch의 일본어 형태소 분석기인 Kuromoji (구로모지) 역시 Jim 이 처음 개발
- Jim 은 아파치 루씬의 커미터이며
- Nori 는 은전한닢에서 사용하는 mecab-ko-dic 사전을 재 가공 하여 사용하고 있음
- 특이하게 Nori 는 프랑스 엔지니어인 Jim Ferenczi 에 의해 처음 개발이 되었음

🌱 Backend-Dev | hwaya2828@gmail.com