
비동기 작업
동기
- synchronous, 동시에 일어나는
- 동기는 말 그대로 동시에 일어난다는 뜻으로 요청과 그 결과가 동시에 일어난다는 약속
- 바로 요청을 하면 시간이 얼마가 걸리던지 요청한 자리에서 결과가 주어져야 함
- 요청과 결과가 한 자리에서 동시에 일어남
- A노드와 B노드 사이의 작업 처리 단위(Transaction)를 동시에 맞춤
비동기
- asynchronous, 동시에 일어나지 않는
- 비동기는 동시에 일어나지 않는다를 의미하는 것으로 요청과 결과가 동시에 일어나지 않을거라는 약속
- 요청한 그 자리에서 결과가 주어지지 않음
- 노드 사이의 작업 처리 단위를 동시에 맞추지 않아도 됨
Tip! 블록과 논블록
- 비동기 방식 블록과 논블록의 차이를 간략하게 설명하자면, 학생이 시험지를 선생에게 건넨 후 가만히 앉아 채점이 끝나서 시험지를 돌려받기만을 기다린다면 학생은 블록 상태
- 하지만 학생이 시험지를 건넨 후 선생에게 채점이 완료되었다는 전송을 받기 전까지 다른 과목을 공부한다거나 게임을 한다거나 다른 일을 하게 되면 학생의 상태는 논블록 상태
장단점
- 동기와 비동기는 상황에 따라서 각각의 장단점이 있음
- 동기 방식은 설계가 매우 간단하고 직관적이지만 결과가 주어질 때까지 아무것도 못하고 대기해야 하는 단점이 있음
- 비동기 방식은 동기보다 복잡하지만 결과가 주어지는데 시간이 걸리더라도 그 시간 동안 다른 작업을 할 수 있으므로 자원을 효율적으로 사용할 수 있는 장점이 있음
Message Broker
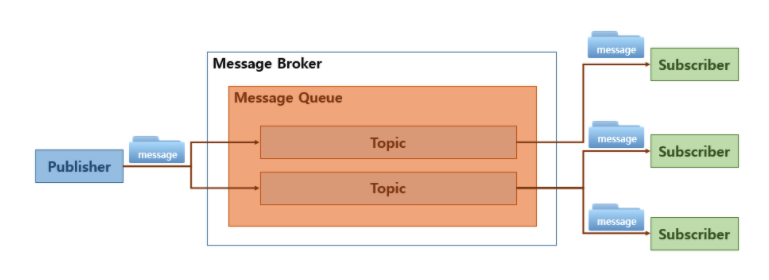
- 메시지 브로커(Message Broker)는 송신자(Publisher)로부터 전달받은 메시지를 수신자(Subscriber)로 전달해주는 중간 역할이며 응용 소프트웨어 간에 메시지를 교환할 수 있게 함
- 이 때 메시지가 적재되는 공간을 메세지 큐(Message Queue)라고 하며 메시지의 그룹을 토픽(Topic)이라고 함
- DW, AS라는 두 개의 서버가 있을 때
- DW는 실시간으로 데이터를 수집하고 관리하는 서버
- AS는 이 데이터를 가공하여 사용하는 서버
- AS에서 DW에 있는 데이터를 사용하기위해서 어떻게 해야할까?
- 가장 일반적인 방법은 DW에서
Oracle,MySQL과 같은 RDB에 적재하고, AS에서는 이 DB에서 조회해서 쓰는 것 - 그러나 실시간으로 처리하기 위해서는 최신의 데이터만 빠르게 조회를 해야하는데, 실시간으로 데이터가 계속 쌓이는 Table을 빠르게 조회하는 것은 힘듦
- 조회 성능을 높이기 위해 테이블에 INDEX를 걸면 INSERT 속도가 느려지므로 실시간 처리에는 적합하지 않음
- 가장 일반적인 방법은 DW에서
- 메시지 브로커를 사용하는 방법은 어떨까?
- DW에서는 수집한 데이터를 바로 메세지 큐에 적재(Publish)하고 AS는 메시지를 소비(Subscribe)하여 바로 사용하게 됨
- 메시지 브로커를 사용하면 AS에서는 별도의 조회 과정이 필요없이, 메세지 큐에 적재되는 메시지를 감시하고 있다가 메시지가 적재되면 바로 가져다가 사용할 수 있음
- 이처럼 메시지 브로커는 송신자가 보낸 메시지를 메시지 큐에 적재하고 이를 수신자가 받아서 사용하는 구조
- 이러한 구조를
Pulibsh/Subscribe(Pub/Sub) Pattern이라고 하며,Producer/Consumer Pattern이라고도 함 - 메시지 브로커는 대표적으로
Apache Kafka,Redis,RabbitMQ등이 있음
- 이러한 구조를
- 실시간 데이터를 처리할 때 DB에서 조회하는 것보다 메시지 브로커를 이용하여 처리하는 것이 성능이 뛰어나다는 것을 알 수 있는데 단점도 존재
- DB를 사용하는 경우 쿼리를 이용하여 원하는 데이터만 필터링하여 조회할 수 있지만, 메시지 브로커를 이용하면 큐에 적재된 그대로 사용하기 때문에 불가능
- 따라서, 적재할 때 필터링된 데이터를 적재하던가 적재된 데이터를
Logstash를 이용하여 필터링해서 사용해야 함 - 또한, 메시지 큐에 적재된 메시지는 주로 7일을 보관하기 때문에 장기간 보관해야하는 경우 별도의 저장소에 저장해야함
비동기 처리 과정
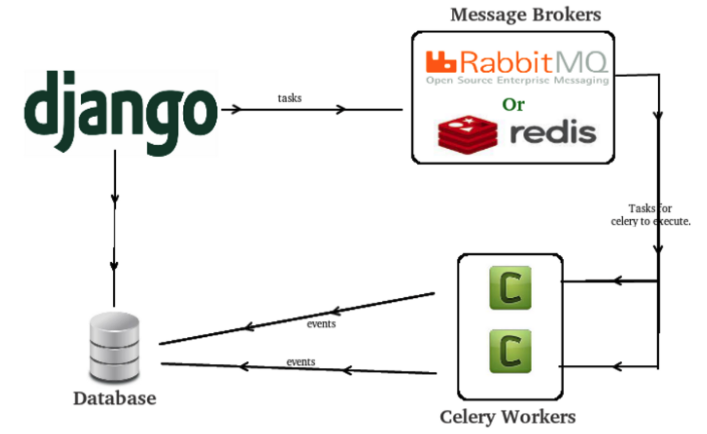
- Celery는 일꾼, 해야 할 일들을 처리
- Reids는 주인, 메시지 브로커를 담당
- Celery란?
- 샐러리(Celery)는 안 보이는 곳에서 열심히 일하는 백그라운드 일꾼
- 처리해야 할 일을 큐(Queue)로 쌓아두고 큐에 쌓인 일을 일꾼들이 가져다가 열심히 일을 함
- 파이썬 언어로 작성되어 있음
- 샐러리는 파이썬 언어로 작성되어 있기 때문에 가상환경 위에서
pip를 이용해 설치- 설치 예시 :
$ pip install 'celery[redis] pip를 이용해 샐러리 모듈과 레디스와의 연동을 위한 의존성 패키지를 한 번에 설치- 레디스를 설치하지 않아도 일단 의존성 패키지는 설치 되며
작은 따옴표('')를 붙여줘야 설치 진행
- 설치 예시 :
- Redis란?
- 레디스(REDIS, REmote Dictionary Server)는 실제 컴퓨터 메모리를 이용한 캐쉬
Key와Value값을 이용해 처리할 작업을 샐러리에게 보낸 다음, 캐쉬 시스템에서 해당Key를 없애는 방식으로 동작- 좋은 점은 로컬과 DB사이에서 자료가 왔다갔다 하는 것보다 메모리에서 캐쉬를 가져다 쓰는 것이 훨씬 빠르다는 것
- 따라서 특정 데이터를 반복적으로 돌려줘야 한다면 메모리 캐쉬를 사용하면 좋음
- 레디스는 인 메모리를 이용하기 때문에
wget으로 설치
# 설치 예시
$ wget http://download.redis.io/redis-stable.tar.gz
$ tar xvzf redis-stable.tar.gz
$ cd redis-stable
$ make
$ redis-server # redis 실행
$ redis-cli ping # 정상 설치되었는지 확인
> PONG # PONG 메시지를 띄우면 설치 성공Celery
- 샐러리는 메시지 브로커와 파이썬 작업 프로세스를 연결해서 이러한 비동기 작업을 수행할 수 있는 시스템을 제공
- 비동기 작업은 즉각적인 결과(응답)를 제공하기 어려운 작업을 수행할 때 활용될 수 있음
- 예를 들어 대용량 작업을 동시에 처리하거나 사용자 요청에 무거운 연산이 포함되는 경우를 들 수 있음
- 보통 비동기 작업을 요청하고 나면 즉시 응답을 받지 않아도 계속 다른 일을 수행할 수 있기 때문에 동시 작업이 가능
- 하지만 작업마다 소요되는 시간이 다르고 실행 환경도 달라 중복 작업이 발생하지 않아야 하며 작업이 누락되지 않도록 하는 것도 매우 중요
- 이렇게 대기중인 작업(Job)을 관리하고 작업자(Worker)에서 제대로 전달되기 위해서는 중간 단계에서 관장하는 시스템이 필요
- 이 때 등장하는 개념이 브로커(Broker)
- 브로커는 작업 메세지를 전달받은 대기열 큐에 보관했다가 적절한 작업자에게 메세지를 전달해서 작업을 수행하도록 함
- 샐러리는 메세지를 전달하는 역할(Publisher)과 메시지를 가져와 작업을 수행하는 역할(Worker)을 담당하게 됨
- 샐러리는 메시지로 작업(Task)을 주고 받는 시스템이기 때문에 중간에 브로커 역할을 하는 분리된 중계 시스템이 필요
Redis
레디스란?
- 레디스는 메모리 기반의 “키(
Key)-값(Value)” 구조 데이터 관리 시스템이며, 모든 데이터를 메모리에 저장하고 조회하기에 빠른 Read • Write 속도를 보장하는 비 관계형 데이터베이스 - 레디스는 크게 5가지
문자열(String),셋(Set),정렬된 셋(Sorted Set),해시(Hash),리스트(List)의 데이터 형식을 지원 - 레디스는 빠른 오픈 소스 인 메모리 키-값 데이터 구조 스토어이며, 다양한 인 메모리 데이터 구조 집합을 제공하므로 사용자 정의 애플리케이션을 손쉽게 생성할 수 있음
레디스의 특징
- 영속성을 지원하는 인 메모리(=메모리 기반의) 데이터 저장소
- 읽기 성능 증대를 위한 서버 측 복제를 지원
- 레디스가 실행중인 서버가 충돌하는 경우 장애 조치 처리와 함께 더 높은 읽기 성능을 지원하기 위해 슬레이브가 마스터에 연결
- 전체 데이터베이스의 초기 복사본을 받는 마스터(Master) - 슬레이브(Slave) 복제를 지원
- 마스터에서 쓰기가 수행되면 슬레이브 데이터 세트를 실시간으로 업데이트하기 위해 연결된 모든 슬레이브로 전송
- 쓰기 성능 증대를 위한 클라이언트 측 샤딩(Sharding)을 지원
- 샤딩(Sharding)이란?
- 파티셔닝(Partitionong)과 동일하며, 같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법을 의미
String,Set,Sorted Set,Hash,List와 같은 다양한 데이터형을 지원
레디스의 장점
- 리스트 • 배열과 같은 데이터를 처리하는데 유용
value값으로String,Set,Sorted Set,Hash,List등 여러 데이터 형식을 지원하기에, 다양한 방식으로 데이터를 활용할 수 있음
- 리스트형 데이터 입력과 삭제가 MySQL에 비해서 10배 정도 빠르다고 함
- 여러 프로세스에서 동시에 같은
key에 대한 갱신을 요청할 경우,Atomic처리로 데이터 부정합 방지Atomic처리 함수를 제공 (=원자성을 잘 지킴)
- 여러 프로세스에서 동시에 같은
- 메모리를 활용하면서 영속적인 데이터 보존
- 명령어로 명시적으로 삭제하지만
Expires를 설정하지 않으면 데이터가 삭제되지 않음 - 스냅샷(기억장치) 기능을 제공하여 메모리의 내용을
*.rdb파일로 저장하여 해당 시점으로 복구할 수 있음
- 명령어로 명시적으로 삭제하지만
- 레디스 서버는 1개의 싱글 쓰레드로 수행되며, 따라서 서버 하나에 여러 개의 서버를 띄우는 것이 가능
- 마스터 - 슬레이브 형식으로 구성이 가능
- 데이터 분실 위험을 없애주는 것이 마스터 - 슬레이브 방식
레디스의 데이터 처리
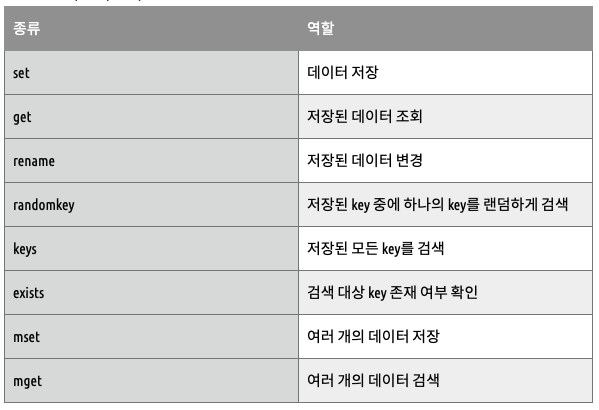
- 데이터 입력•수정•삭제•조회에 대하여 아래와 같은 명령이 제공됨
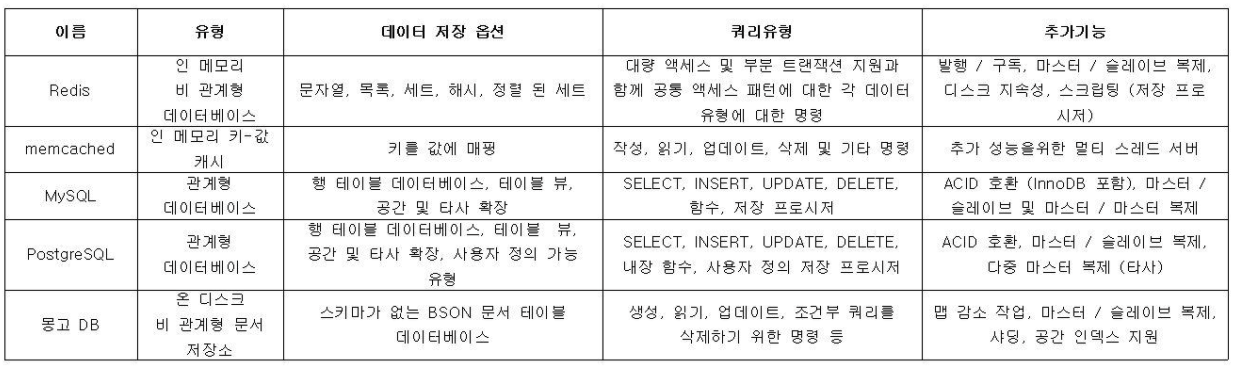
레디스와 다른 데이터베이스 및 소프트웨어와 비교

🌱 Backend-Dev | hwaya2828@gmail.com