SIMD란?
Single instruction, multiple data 동일한 연산을 여러 데이터 지점에 동시에 수행한다.
이는 CPU 마다 명령어 집합이 다르다.
예를들어 ARM 아키텍처의 NEON, Intel이나 AMD의 MMX, AVX2, SSE 등등이 있다.
참고로 이 글에 나오는 코드는 godbolt사이트에서 ARM64 또는 Macbook Pro M4를 이용해서 실험했다.
따라서 SIMD 병렬화 종류 중에서 NEON을 기준으로 설명한다.
SIMD 병렬화의 원리
SIMD는 멀티스레드, 멀티프로세스처럼 동시에 처리한다는 개념이 있지만, 동작 방식이 다르다.
SIMD는 연산을 할 때 하나의 레지스터에서 여러개의 연산을 동시에 수행한다.
일반적인 레지스터가 숫자 하나를 담는다면, SIMD용 레지스터는 숫자를 4개,8개,16개 등등 한번에
여러개를 담을 수 있다.
예를들어 어떤 A,B 두개의 배열이 있고 그 두개의 배열 각 인덱스에 있는 원소의 합을 C배열에
다시 쓰는 작업을 한다고 해보자.
만약 배열의 크기가 1000이고 반복문에서 C[i] = A[i] + B[i]를 반복하고 싶다고 하자.
SIMD가 아닌 SISD (Single instruction, single data)라면,
바로 떠오르듯이 아래와 같은 방식으로 순차적으로 하나씩 처리할 것이다
for (int i=0; i<1000; i++) {
C[i] = A[i] + B[i];
}하지만 SIMD는, 이를 4개, 8개 등등으로 한번에 묶어서 처리한다.
참고로 한번에 몇개를 올리느냐는 레지스터에 따라 다르다
예를들어 SIMD용 레지스터가 128비트고, 처리해야할 데이터 타입이 32bit int라면,
32*4=128이므로 4개를 한번에 올려서 동시에 처리할 수 있다고 보면 된다.
만약 위 코드의 A,B,C배열이 int배열이라면 4개씩 처리하게 된다.
즉, C[i] = A[i] + B[i]에서는 하나의 레지스터에 0,1,2,3번 인덱스에 있는 데이터가 올라가고,
그 다음에는 4,5,6,7번 이런식으로 한번에 올려서 처리한다고 생각하면된다.
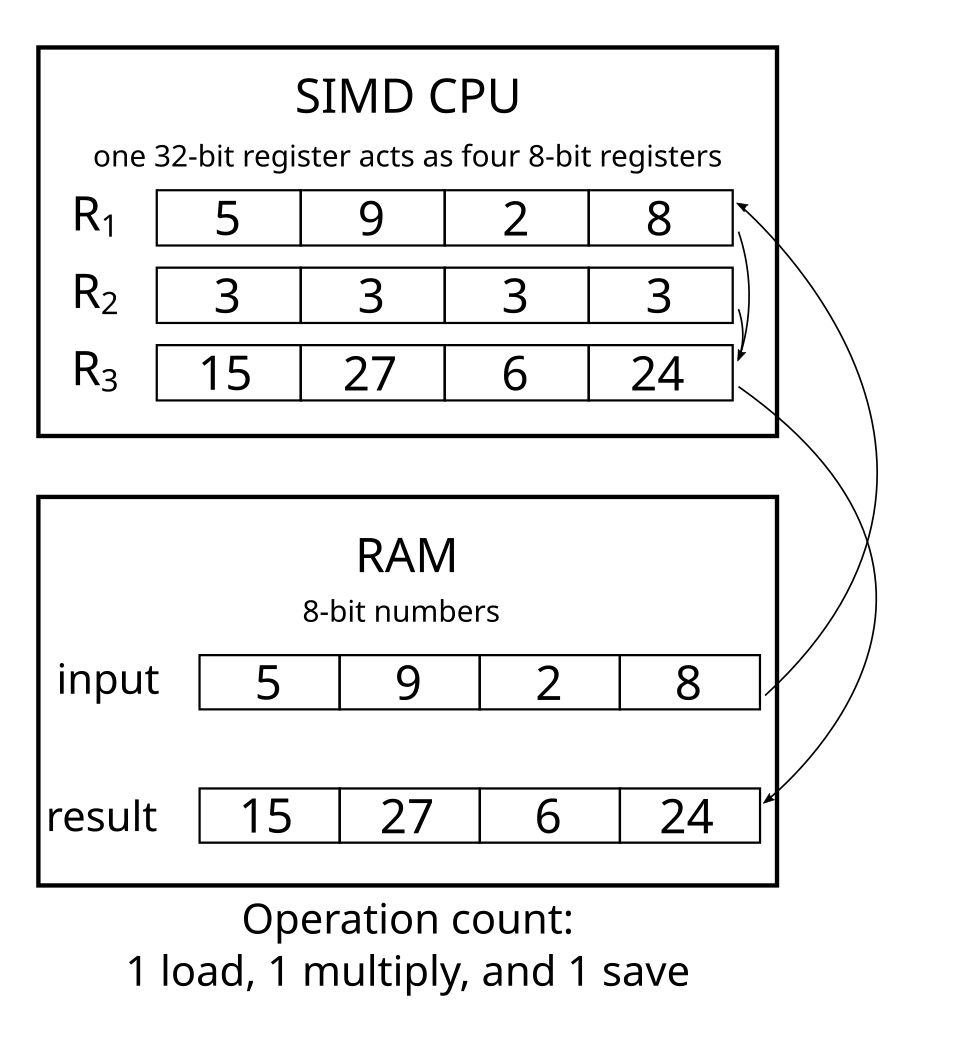
무슨말인지 그림으로 확인해보면
(출처 : 위키백과)
위 이미지에서는, 두 배열의 각 원소들의 곱을 R3에 저장한다고 보면 된다.
실제 어디에 사용되는가?
그러면 이 SIMD를 통한 성능향상은 실제 어디에서 사용되는지 확인해보자.
복잡하게 멀리갈 것도 없이, C/C++에서는 이미 컴파일러가 for loop등을 자동으로 최적화할 때 사용된다.
아까 봤던 C[i] = A[i] + B[i] 예시의 컴파일 결과를 직접 확인해보자.
로컬에서 직접 빌드해서 어셈블리어를 확인해봐도 되고, 코드 변화에 따라 실시간으로 어셈블리어를 확인하고 다양한 아키텍처에서 확인할 수 있는 https://godbolt.org를 사용해볼 수도 있다.
#include <iostream>
int main() {
int a[160] = {1,};
int b[160] = {2,};
int c[160] = {3,};
for (int i =0; i<160; i++) {
c[i] = a[i] + b[i];
}
for (int i =0;i<160;i++) {
std::cout << c[i] << "\n";
}
return 0;
}나는 현재 개발을 할 때 맥북을 사용하고 있어서, ARM 아키텍처로 빌드해보기 위해
사이트에서 컴파일러 종류를 ARM64 gcc 15.2.0으로 설정하고 테스트해봤다.
결과로 나온 어셈블리어 코드 중에서, c[i] = a[i] + b[i];가 가리키는 어셈블리어 부분을 확인해보자.
ldr q31, [x0], 16
ldr q30, [x2], 16
add v30.4s, v31.4s, v30.4s
str q30, [x1], 16결과에서 add v30.4s, v31.4s, v30.4s부분이 바로 SIMD (NEON)이 적용된 부분이다.
해당 부분은 v31과 v30에 담긴 4개의 32비트 값(.4s)을 각각 더해 결과를 v30에 저장하는 과정이다.
아까 언급했듯이, 몇개를 동시에 처리할지는 레지스터의 크기와 처리할 타입에 따라 달라지는데,
NEON은 128비트 레지스터를 사용하고 또 int는 32비트이므로 동시에 처리할 수 있는 크기는 4개다.
컴파일러가 자동으로 최적화 하는 부분 말고도, 속도가 매우 중요한 작업 (예를들어 암호화나 복호화, 멀티미디어 처리, 머신러닝 등등)에도 사용된다.
파이썬을 써본 사람이라면 numpy를 알텐데, 이 numpy가 파이썬의 리스트보다 어떤 경우에는
훨씬 빠르다는 말을 들어봤을 것이다.
이 numpy가 빠른 이유 중에 하나가 SIMD 병렬화를 수행하기 때문이다.
실제로 numpy의 문서를 확인해보면 (링크)
NumPy comes with a flexible working mechanism that allows it to harness the SIMD features that CPUs own, in order to provide faster and more stable performance on all popular platforms. Currently, NumPy supports the X86, IBM/Power, ARM7 and ARM8 architectures.
성능 향상이 어느정도 되는지 테스트
성능이 향상이 된다는데, 또 눈으로 직접 확인을 안해볼 수가 없었다.
최적화 성능과 비교해보기 위해 릴리즈모드 빌드 + -O3 최적화를 사용하였다.
사용한 컴파일 명령어는 아래와 같다 (파일이름은 main.cpp)
clang++ -std=c++20 -O3 -fno-vectorize main.cpp -o neon_test
./neon_test참고로 -fno-vectorize를 옵션을 추가한 이유는, 컴파일러가 자동으로 벡터화를 하기 때문에
직접 NEON벡터화한 것과 벡터화되지 않은 것을 비교해보기 위해 추가한 플래그다.
이후에 컴파일러가 직접 SIMD병렬화를 하는 경우와 병렬화가 되지 않는 경우를 비교해볼 때는
저 -fno-vectorize 옵션을 빼야된다!!
첫번째로 실험할 코드는 다음과 같다
#include <iostream>
#include <vector>
#include <chrono>
#include <random>
#include <cmath>
#include <arm_neon.h> // Apple Silicon NEON 헤더
// 데이터 크기 설정 (5천만 개)
const int DATA_SIZE = 50000000;
// 1. 일반적인 스칼라 덧셈 함수 (SISD)
void add_scalar(const float* a, const float* b, float* result, int n) {
for (int i = 0; i < n; ++i) {
result[i] = a[i] + b[i];
}
}
// 2. NEON SIMD 덧셈 함수
// float는 32비트이므로, 128비트 NEON 레지스터에 4개씩 담을 수 있음
void add_neon(const float* a, const float* b, float* result, int n) {
int i = 0;
// 4개씩 묶어서 처리 (Loop Unrolling)
// n-4까지 루프를 돌리는 이유는 마지막에 남는 자투리(4개 미만) 처리를 위함
for (; i <= n - 4; i += 4) {
// 메모리에서 데이터 로드 (Load)
float32x4_t va = vld1q_f32(&a[i]); // a[i] ~ a[i+3]
float32x4_t vb = vld1q_f32(&b[i]); // b[i] ~ b[i+3]
// 벡터 덧셈 (Add) - 한 번의 명령어로 4개의 덧셈 수행
float32x4_t vr = vaddq_f32(va, vb);
// 결과를 메모리에 저장 (Store)
vst1q_f32(&result[i], vr);
}
// 남은 데이터(나머지) 처리 (일반 방식으로 처리)
for (; i < n; ++i) {
result[i] = a[i] + b[i];
}
}
int main() {
std::cout << "Initializing data (" << DATA_SIZE << " elements)..." << std::endl;
// 메모리 할당 (std::vector 사용)
// *주의: NEON 로드/스토어 성능 최적화를 위해 메모리 정렬(align)을 하면 더 좋지만,
// 최신 아키텍처에서는 정렬되지 않은 로드도 성능 저하가 적으므로 기본 vector 사용
std::vector<float> a(DATA_SIZE);
std::vector<float> b(DATA_SIZE);
std::vector<float> res_scalar(DATA_SIZE);
std::vector<float> res_neon(DATA_SIZE);
// 랜덤 데이터 채우기
std::mt19937 gen(42);
std::uniform_real_distribution<float> dis(0.0f, 100.0f);
for (int i = 0; i < DATA_SIZE; ++i) {
a[i] = dis(gen);
b[i] = dis(gen);
}
std::cout << "Data ready. Starting benchmark.\n" << std::endl;
// --- Scalar 테스트 ---
auto start = std::chrono::high_resolution_clock::now();
add_scalar(a.data(), b.data(), res_scalar.data(), DATA_SIZE);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> scalar_duration = end - start;
std::cout << "Scalar Logic Time: " << scalar_duration.count() << " ms" << std::endl;
// --- NEON 테스트 ---
start = std::chrono::high_resolution_clock::now();
add_neon(a.data(), b.data(), res_neon.data(), DATA_SIZE);
end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> neon_duration = end - start;
std::cout << "NEON SIMD Time : " << neon_duration.count() << " ms" << std::endl;
// --- 결과 검증 ---
// 결과가 같은지 확인 (부동소수점 오차 고려)
bool correct = true;
for (int i = 0; i < DATA_SIZE; ++i) {
if (std::abs(res_scalar[i] - res_neon[i]) > 1e-5) {
correct = false;
std::cout << "Mismatch at index " << i << std::endl;
break;
}
}
if (correct) {
std::cout << "\nResults match! Verification successful." << std::endl;
std::cout << "Speedup: " << scalar_duration.count() / neon_duration.count() << "x" << std::endl;
} else {
std::cout << "\nResults do NOT match!" << std::endl;
}
return 0;
}내 노트북으로 빌드하고 테스트하기 위해, 현재 나는 애플실리콘 맥북을 쓰기 때문에 arm_neon헤더를 사용했다
결과는
Scalar Logic Time: 14.8127 ms
NEON SIMD Time : 10.036 ms성능이 30%정도 향상되었다.
참고로, 아까 컴파일할 때 옵션 중에 -fno-vectorize 옵션을 빼고 빌드하게되면,
오히려 직접 NEON을 사용한게 컴파일러 자동 최적화한 것과 속도가 비슷하거나 오히려 느려질 수 있다.
컴파일러도 이정도 수준의 SIMD 최적화는 알아서 해준다.
단지 나는 일단 직접 최적화를 했을 때 성공하는지와 어느정도의 향상이 있는지를 확인하기 위해 자동 벡터화 옵션을 제거하고 확인한 것이다.
사실 15ms에서 10ms는 그렇게 큰 느낌은 안들기 때문에,
SIMD 병렬화의 성능 체감을 위해서 조금 더 복잡한 연산을 사용해봤다.
#include <iostream>
#include <vector>
#include <chrono>
#include <random>
#include <cmath>
#include <arm_neon.h> // Apple Silicon NEON 헤더
// 데이터 크기 설정 (5천만 개)
const int DATA_SIZE = 50000000;
// 1. 일반적인 스칼라 덧셈 함수 (SISD)
void add_scalar(const float* a, const float* b, float* result, int n) {
for (int i = 0; i < n; ++i) {
float val = a[i] + b[i];
// 일부러 복잡한 연산을 넣음 (CPU를 바쁘게 함)
for(int j = 0; j < 10; ++j) {
val = std::sqrt(val) + (val * 0.123f);
}
result[i] = val;
}
}
// 2. NEON SIMD 덧셈 함수
// float는 32비트이므로, 128비트 NEON 레지스터에 4개씩 담을 수 있음
void add_neon(const float* a, const float* b, float* result, int n) {
int i = 0;
// 4개씩 묶어서 처리 (Loop Unrolling)
// n-4까지 루프를 돌리는 이유는 마지막에 남는 4개 미만의 데이터를 처리를 위함
for (; i <= n - 4; i += 4) {
float32x4_t va = vld1q_f32(&a[i]);
float32x4_t vb = vld1q_f32(&b[i]);
float32x4_t vr = vaddq_f32(va, vb);
// NEON으로 10번 반복 연산
float32x4_t const_val = vdupq_n_f32(0.123f);
for(int j = 0; j < 10; ++j) {
vr = vaddq_f32(vsqrtq_f32(vr), vmulq_f32(vr, const_val));
}
// 결과를 메모리에 저장 (Store)
vst1q_f32(&result[i], vr);
}
// 남은 데이터(나머지) 처리 (일반 방식으로 처리)
for (; i < n; ++i) {
result[i] = a[i] + b[i];
}
}
int main() {
std::cout << "Initializing data (" << DATA_SIZE << " elements)..." << std::endl;
std::vector<float> a(DATA_SIZE);
std::vector<float> b(DATA_SIZE);
std::vector<float> res_scalar(DATA_SIZE);
std::vector<float> res_neon(DATA_SIZE);
// 랜덤 데이터 채우기
std::mt19937 gen(42);
std::uniform_real_distribution<float> dis(0.0f, 100.0f);
for (int i = 0; i < DATA_SIZE; ++i) {
a[i] = dis(gen);
b[i] = dis(gen);
}
std::cout << "Data ready. Starting benchmark.\n" << std::endl;
// --- Scalar 테스트 ---
auto start = std::chrono::high_resolution_clock::now();
add_scalar(a.data(), b.data(), res_scalar.data(), DATA_SIZE);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> scalar_duration = end - start;
std::cout << "Scalar Logic Time: " << scalar_duration.count() << " ms" << std::endl;
// --- NEON 테스트 ---
start = std::chrono::high_resolution_clock::now();
add_neon(a.data(), b.data(), res_neon.data(), DATA_SIZE);
end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> neon_duration = end - start;
std::cout << "NEON SIMD Time : " << neon_duration.count() << " ms" << std::endl;
// --- 결과 검증 ---
// 결과가 같은지 확인 (부동소수점 오차 고려)
bool correct = true;
for (int i = 0; i < DATA_SIZE; ++i) {
if (std::abs(res_scalar[i] - res_neon[i]) > 1e-5) {
correct = false;
std::cout << "Mismatch at index " << i << std::endl;
break;
}
}
if (correct) {
std::cout << "\nResults match! Verification successful." << std::endl;
std::cout << "Speedup: " << scalar_duration.count() / neon_duration.count() << "x" << std::endl;
} else {
std::cout << "\nResults do NOT match!" << std::endl;
}
return 0;
}이 코드의 경우 결과가
Scalar Logic Time: 241.255 ms
NEON SIMD Time : 74.3596 ms약 3배가 빨라졌다.
(참고로 이 경우에서도 컴파일러가 충분히 최적화할 수 있는 레벨이라서,
-fno-vectorize 컴파일 옵션을 제거하면 직접 수동으로 NEON화 한 것과 성능이 비슷하거나
오히려 더 빠르다)
마지막 3번째로 실험할 코드는 아래와같다.
이번에는 더 복잡하게 행렬곱 코드를 가져왔다.
#include <iostream>
#include <vector>
#include <chrono>
#include <random>
#include <cmath>
#include <arm_neon.h> // Apple Silicon NEON 헤더
// 행렬 크기 설정 (1024 x 1024) -> 약 10억 번의 연산 수행
const int N = 1024;
// 1. 일반 스칼라 행렬 곱셈 (Naive implementation)
// O(N^3) 알고리즘
void matmul_scalar(const float* A, const float* B, float* C, int n) {
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
float sum = 0.0f;
for (int k = 0; k < n; ++k) {
// C[i][j] += A[i][k] * B[k][j]
sum += A[i * n + k] * B[k * n + j];
}
C[i * n + j] = sum;
}
}
}
// 2. NEON SIMD 행렬 곱셈
// 한 번에 4개의 열(column)을 계산
void matmul_neon(const float* A, const float* B, float* C, int n) {
for (int i = 0; i < n; ++i) {
// j는 4씩 증가 (한 번에 4개의 float 결과 계산)
for (int j = 0; j < n; j += 4) {
// 결과 누적을 위한 레지스터 초기화 (0.0f, 0.0f, 0.0f, 0.0f)
float32x4_t sum_vec = vdupq_n_f32(0.0f);
for (int k = 0; k < n; ++k) {
// A[i][k] 값 하나를 가져와서 4개짜리 벡터로 복사 (Broadcast)
// 예: A[i][k]가 2.0이면 -> {2.0, 2.0, 2.0, 2.0}
float32x4_t a_val = vdupq_n_f32(A[i * n + k]);
// B[k][j] 부터 4개를 로드
// { B[k][j], B[k][j+1], B[k][j+2], B[k][j+3] }
float32x4_t b_vec = vld1q_f32(&B[k * n + j]);
// FMA (Fused Multiply-Add) 연산 수행
// sum_vec += a_val * b_vec
// 곱하기와 더하기를 한 번의 사이클에 처리하여 매우 빠름
sum_vec = vfmaq_f32(sum_vec, a_val, b_vec);
}
// 계산된 4개의 결과를 메모리 C[i][j] ~ C[i][j+3]에 저장
vst1q_f32(&C[i * n + j], sum_vec);
}
}
}
int main() {
std::cout << "Initializing matrices (" << N << "x" << N << ")..." << std::endl;
// 데이터 정렬 등은 생략하고 일반 vector 사용 (충분한 성능 차이 확인 가능)
// 1차원 배열로 펼쳐서 사용 (Row-major)
std::vector<float> A(N * N);
std::vector<float> B(N * N);
std::vector<float> C_scalar(N * N, 0.0f);
std::vector<float> C_neon(N * N, 0.0f);
// 랜덤 데이터 채우기
std::mt19937 gen(42);
std::uniform_real_distribution<float> dis(0.0f, 1.0f);
for (int i = 0; i < N * N; ++i) {
A[i] = dis(gen);
B[i] = dis(gen);
}
std::cout << "Benchmarking started.\n" << std::endl;
// --- Scalar Test ---
auto start = std::chrono::high_resolution_clock::now();
matmul_scalar(A.data(), B.data(), C_scalar.data(), N);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> scalar_time = end - start;
std::cout << "Scalar Time: " << scalar_time.count() << " ms" << std::endl;
// --- NEON Test ---
start = std::chrono::high_resolution_clock::now();
matmul_neon(A.data(), B.data(), C_neon.data(), N);
end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> neon_time = end - start;
std::cout << "NEON Time : " << neon_time.count() << " ms" << std::endl;
// --- 검증 (Verification) ---
std::cout << "\nVerifying results..." << std::endl;
bool correct = true;
for (int i = 0; i < N * N; ++i) {
// 부동소수점 연산 순서 차이로 인한 미세한 오차 허용 (epsilon)
if (std::abs(C_scalar[i] - C_neon[i]) > 1e-3) {
std::cout << "Mismatch at index " << i << ": "
<< C_scalar[i] << " vs " << C_neon[i] << std::endl;
correct = false;
break;
}
}
if (correct) {
std::cout << "Results Match!" << std::endl;
std::cout << "------------------------------------------------" << std::endl;
std::cout << "Speedup: " << scalar_time.count() / neon_time.count() << "x" << std::endl;
std::cout << "------------------------------------------------" << std::endl;
} else {
std::cout << "Results DO NOT Match!" << std::endl;
}
return 0;
}결과는
Scalar Time: 843.653 ms
NEON Time : 227.064 ms
이것도 약 3.5배정도 빠르다.
참고로 마지막 코드의 경우, -fno-vectorize 옵션을 제거해도 성능 향상이 비슷한 수준으로 나온다.
즉, 이는 컴파일러가 위 스칼라 코드는 자동으로 최적화하지 못했다는 뜻이다.
왜 마지막 코드만 최적화 되지 않는지에 대해서는 다음 글에서 작성해보도록 하겠다.
이렇게 SIMD의 처리 원리를 보면 생각해볼 수 있는 것은,
처리방식을 보면 알듯이 순차적으로 4개씩 순서대로 묶어서 처리했다.
하지만 만약에 한번에 처리할 데이터 일부가 서로 의존적인 관계라면??
-> SIMD 병렬화를 할 수가 없다.
예를들어 C[i] = A[i] + B[i]가 아니라 A[i] = A[i-1] + B[i]이라고 하자.
그러면 한번에 4개를 올릴 수가 없는게, 예를들어 1번 인덱스를 처리하려면 0번인덱스가 먼저 처리
되어야 하고, 2번 인덱스가 처리되려면 1번인덱스를 먼저 처리하는 순서를 가져야한다.
즉, 동시에 0,1,2,3번 인덱스를 작업할 수 없다.
또한 위 예시에서처럼 4개씩 처리하거나, 아니면 만약에 32bit int가 아니라 16비트 타입이였다면 한번에 8개를 처리할 수 있는데, 중요한건 4개든 8개든 16개든 만약에 처리하고자 하는 데이터가
이렇게 4의 배수, 8의 배수, 16의 배수 등이 아닌 상황에서는 직접 나머지 데이터를 일반 스칼라 방식으로 처리하는 코드를 직접 작성해줘야한다 (단, SIMD병렬화 코드를 직접 작성하는 경우)
그리고 NEON과 다르게 AVX2같은 경우에는 메모리가 aligned 되어야해서 이렇게 배열 바로 만들어서 하는 경우 Segment Fault같은 오류가 발생할 수 있다.
다음 글로는 어느 상황에서 컴파일러가 최적화가 동작하고 어느 상황에서는 동작하지 않는지 등에 대해서 작성했다.
다음 글 : 링크
