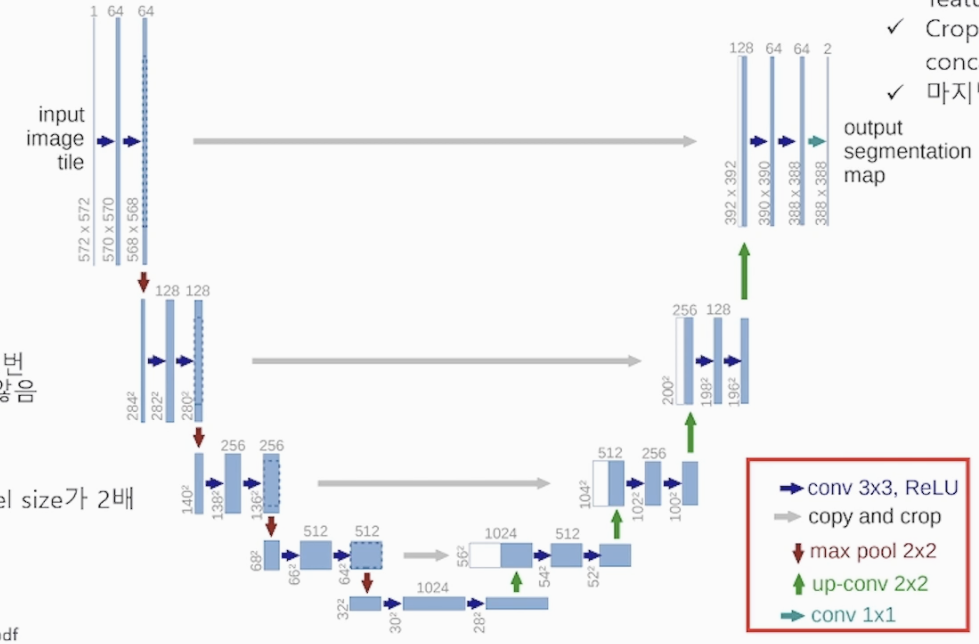
1. 머신러닝 시작하기
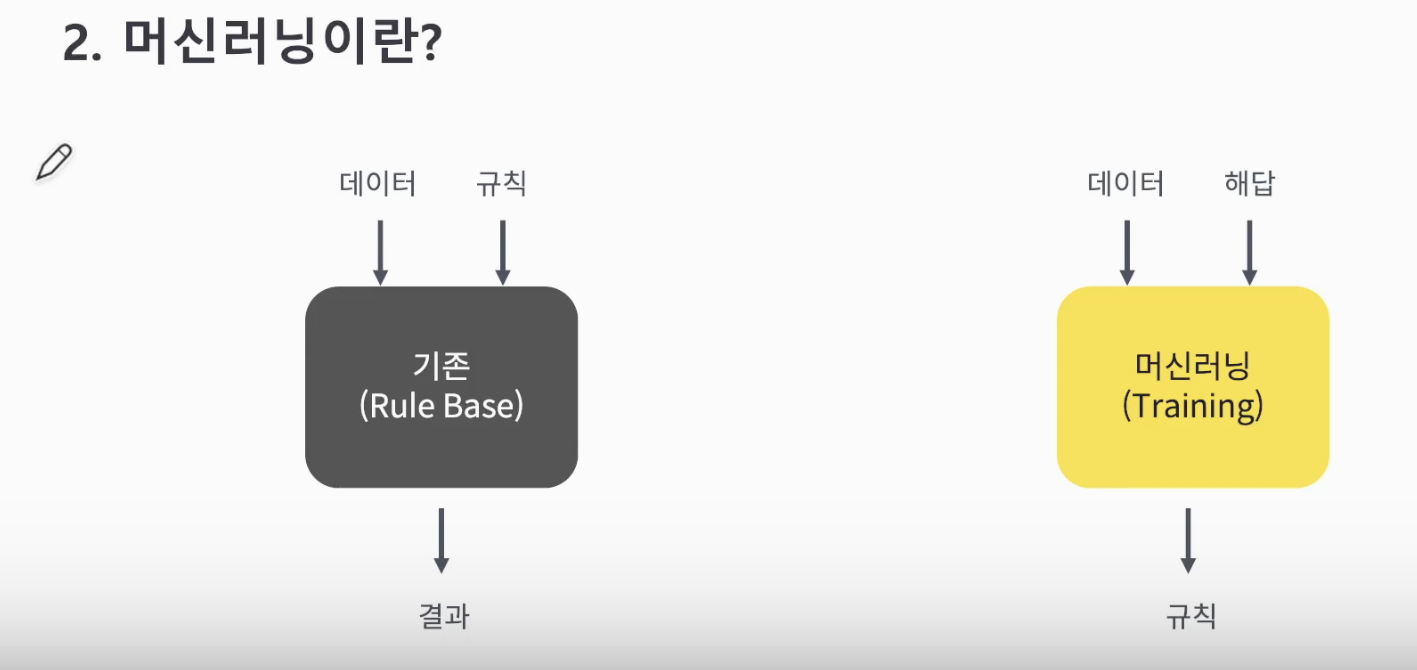
머신러닝(MachineLearning) 이란?
- Ai >= 머신 러닝 >= 딥러닝 : AI를 구현하는 방법 중 하나가 머신러닝이고, 머신러닝의 방법 중 하나가 딥러닝!!
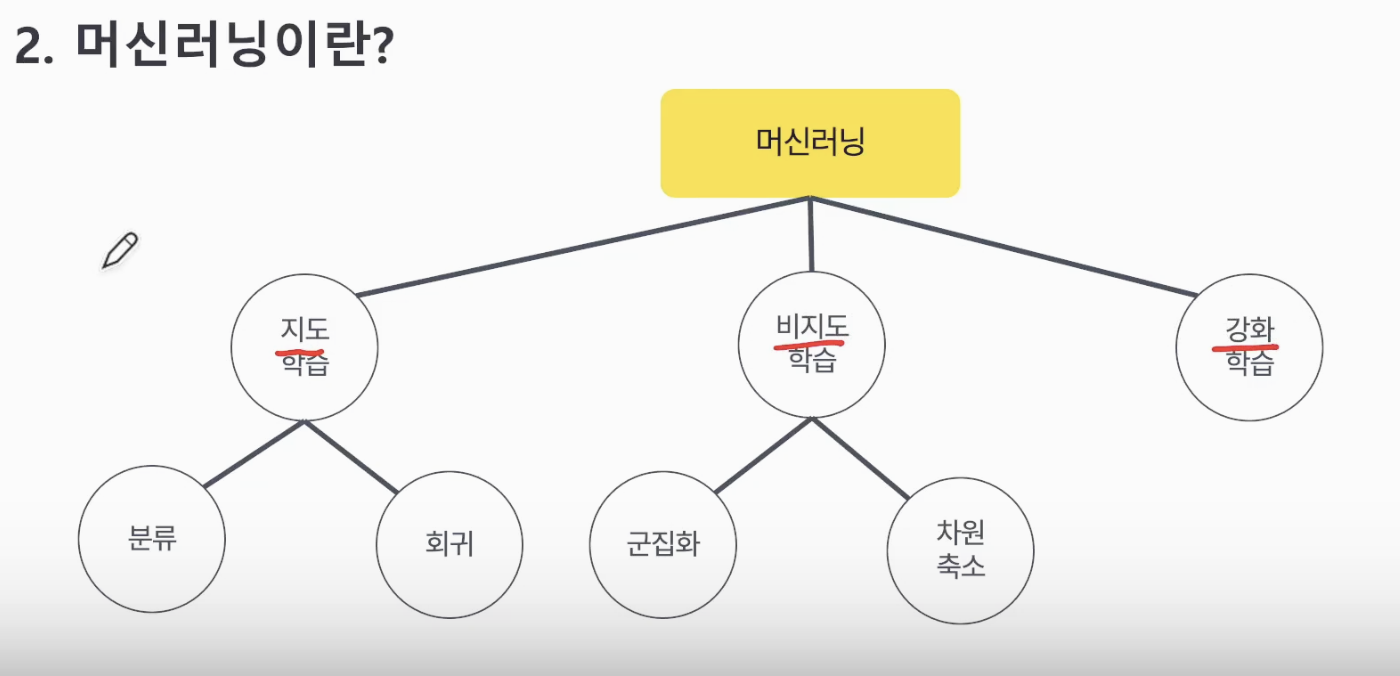
2. 머신러닝 모델
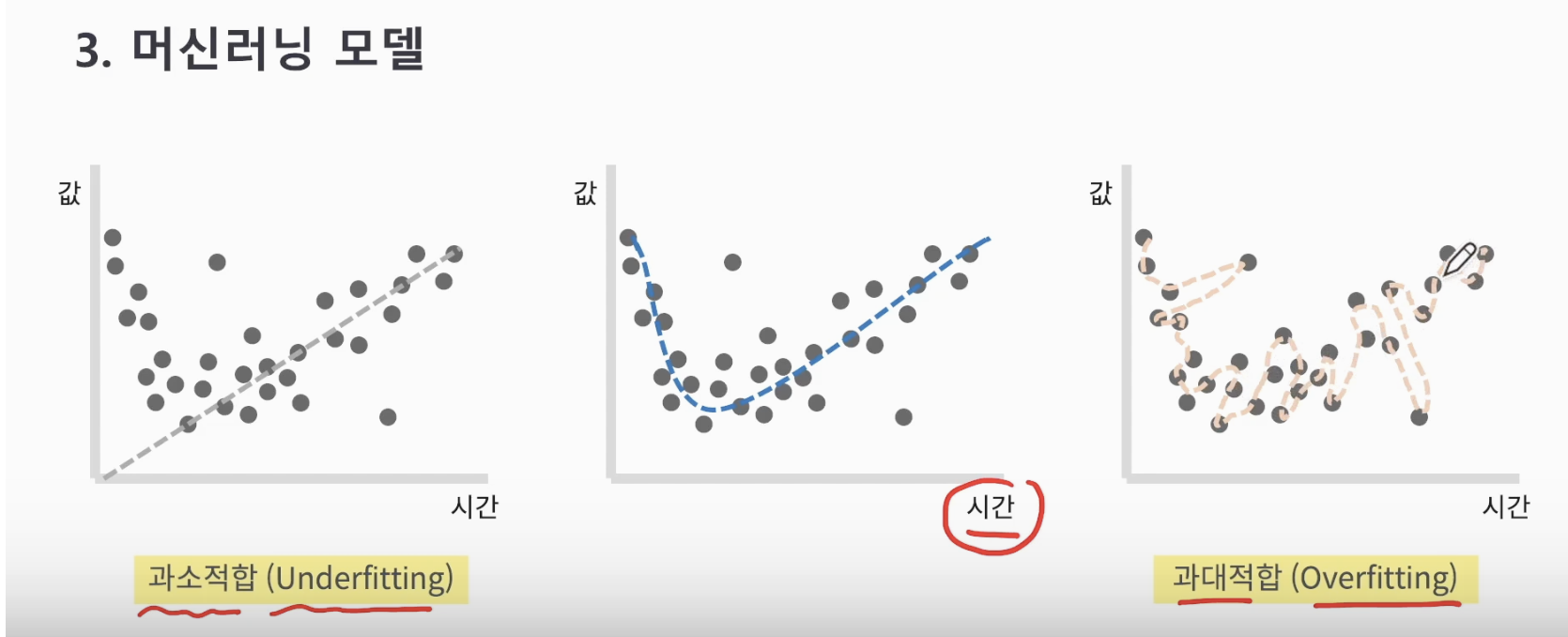
-
과소적합(Underfitting) : 데이터의 평균이 연결 되어 있지 않다. 최적화 되어 있지 않다.(패턴이 너무 단순)
-
과대적합(Overfitting) : 데이터의 평균이 전부 연결 되어 있다. 너무 최적화가 되어 있어 기능이 떨어진다. (패턴이 너무 복잡)
3. 머신러닝 프로세스
-
1) 문제 정의 : 무엇이 예측값인지, 회귀/분류 방법, 평가 방식을 선택한다
-
2) 탐색적 데이터 분석(EDA) : 데이터를 디테일하게 분석하고 분류 한다
-
3) 데이터 전처리 : 가장 많은 시간을 사용하고, 결측치, 이상치 처리
-
4) 모델 학습 : 학습 전 데이터 나누기가 선행 되야 한다!(필수), sklearn(사이킷런)이 잘 되어 있다
-
5) 예측 : Test data 값으로 분류에 맞게 측정 후 과정 별 피드백을 통해 정확한 결과 도출
4. 데이터 핸들링 1
- 라이브러리 불러오기
- DataFrame & Series
- 데이터 불러오기 및 저장(csv형식)
- 데이터 선택 & 인덱싱/슬라이싱
- Index 다루기 (row/colunm/value)
1) 라이브러리 불러오기
-
import pandas as pd (데이터 처리와 분석에 적합한 pandas import 하기 as 별칭 pd로 지정)
-
import numpy as np (수학 및 과학의 수치 계산을 위한 numpy import 하기 as 별칭 np)
2) DataFrame & Series
menu = pd.Series(['후라이드', '양념치킨', '양반후반'], name="메뉴")
price = pd.Series([12000, 13000, 13000], name='가격')
pd.DataFrame({
'메뉴' : menu,
'가격' : price
})
- menu 변수 선언 : 후라이드, 양념치킨, 양반후반을 '메뉴' colunm 생성
- price 변수 선언 : 12000, 13000, 13000 '가격' colunm 생성
- pd.DataFrame을 통해 데이터를 프레임화 한다
3) 데이터 불러오기 및 저장
data = {
"메뉴":['후라이드', '양념치킨', '간장치킨', '마늘치킨', '파닭', '닭강정', '양반후반'],
"가격":[12000, 13000, 14000, 14000, 14000, 15000, 13000],
"호수":['10호', '10호', '9호', '9호', '11호', '12호', '10호'],
"칼로리":[1000, 1400, 1600, 1800, 1300, 1500, 1300],
}
data = pd.DataFrame(data)
data.to_csv('modudak.csv')
df = pd.read_csv('modudak.csv')
- data 변수 선언 : data 안에 딕셔너리를 만들기
- data = pd.DataFrame(data) : 딕셔너리 data를 프레임화 한다
- data.to_csv('modudak.csv') : 'modudak.csv'로 csv 파일 저장
- df = pd.read_csv('modudak.csv') : df 변수는 'modudak.csv'를 읽어온다
4) 데이터 선택 & 인덱싱/슬라이싱
- 위 데이터 프레임화 형태
메뉴 가격 호수 칼로리0 후라이드 12000 10호 1000
1 양념치킨 13000 10호 1400
2 간장치킨 14000 9호 1600
3 마늘치킨 14000 9호 1800
4 파닭 14000 11호 1300
5 닭강정 15000 12호 1500
4-1) 열(column) 선택
-
df['메뉴'] : Series에서 1개만 선택할 때
메뉴
0 후라이드
1 양념치킨
2 간장치킨
3 마늘치킨
4 파닭
5 닭강정 -
df[['메뉴','가격']] : DataFrame에서 2개 이상 선택할 때 리스틍 2번 [[]] 씌어주기
메뉴 가격
0 후라이드 12000
1 양념치킨 13000
2 간장치킨 14000
3 마늘치킨 14000
4 파닭 14000
5 닭강정 15000
4-2) 행(row) 선택
- 조건을 걸어서 선택해보자! 가격이 14000원 이상, 호수가 9호인 행 선택
cond1 = df['가격'] >= 14000
cond2 = df['호수'] == '9호'
df[cond1 & cond2]
메뉴 가격 호수 칼로리
2 간장치킨 14000 9호 1600
3 마늘치킨 14000 9호 1800
-
조건이 3개일 때는 & cond3 추가하면 된다. or 조건도 가능하다('|'활용)
-
isin() 함수 활용
cond = df['호수'].isin(['9호','10호']_
df[cond]9호와 10호에 해당하는 메뉴들 출력
4-3) 인덱싱/슬라이싱
- 원하느 셀 또는 범위를 선택하는 것이 인덱싱/슬라이싱
#인덱스 명 변경하기
df['index'] = ['a','b','c','d','e','f']
df = df.set_index(keys=['index])
df
-
맨 앞 숫자인 indet 열이 알파벳으로 바뀐다
4-3-1) loc 활용
-
인덱스 명
-
인덱스 명(범위), 컬럼 명(범위)
#인덱싱 (행 전체 선택)
df.loc('a')후라이드 행이 전체 선택/출력 된다
#슬라이싱 (열 전체 선택)
df.loc[:,'가격']
df가격 열 전체 선택/출력 된다
#슬라이싱, (양념치킨 가격 선택)
df.loc['b','가격']13000
#슬라이싱 (간장치킨 메뉴와 가격)
df.loc['c','메뉴':'가격']]
메뉴 칼로리 사이 : 을 , 바꾸고 [] 한번 더 묶지 않는다면 연결 되지 않은 열도 선택 가능하다 df.loc['c',['메뉴','칼로리']]#슬라이싱 (양념부터 마늘치킨까지 메뉴와 가격 선택)
df.loc['b':'d','메뉴':'가격']
-
4-3-2) iloc 활용
-
인덱스 번호
-
인덱스 번호(범위), 컬럼 번호(범위)
#인덱싱 (행 전체)
df.iloc[0]후라이드 치킨 전체 행 출력
#가격 전체 열 출력
df.iloc[:,1]슬라이싱 (간장치킨 메뉴와 가격)
df.iloc[2, 0:2] # iloc는 리스트 특성 상 끝부분 0:2 2부분에 원하는 인덱스 +1 을 해야 한다4-3-3) set_index
df = df.set_index(keys=['컬럼 명']) #인덱스의 컬러명 변경할 수 있다
5) 데이터 행/열 추가
#할인율 컬럼 추가 (값은 0.2) 20% 할인
df['할인율'] = 0.2할인율 0.2 적용한 열 추가
#할인가 컬럼 만들기
df['할인가'] = df['가격'] * (1-df['할인가'])
df할인가 열을 추가하고 가격에 할인가를 적용한다
#결측값(NaN) 추가 해보기 (import numpy 필요하다?)
df['원산지'] = np.nan원산지 열에 NaN 결측값 대입
#행 추가
aiffel = ['아이펠치킨', 16000, '11호', 1200, 0.5, 8000, '국내산']
df.loc['new'] = aiffel
df아이펠 치킨이라는 new 메뉴 행 추가
#딕셔너리로 행 추가하기
flip = {'메뉴':'풀잎치킨','가격':10000, '호수':'10호'}
df.loc[10] = flip
신메뉴 인덱스 [10]에다가 '풀잎치킨'메뉴를 넣고, 해당 행에다가 원하는 열의 값만 추가할 수 있다
6) 값 추가하기
#후라이드의 원산지 '국내산' 값 추가하기(loc 활용)
df.loc[0,'원산지'] = '국내산'
df
후라이드의 원산지 열에 국내산 값 추가
#파닭과 닭강정의 원산지에 '브라질' 값 추가 (iloc 활용)
df.iloc[4,-1] = '브라질'
df.iloc[5,-1] = '브라질'
파닭과 닭강정의 원산지가 브라질로 바뀐다
#replace 활용 (양반후반 > 양념반후라이드반 으로 변경)
df.replace('양념후반','양념반후라이드반')
df
양념후반 메뉴명이 양념반후라이드반 으로 변경 된다
#replace 활용 (아이펠치킨 > [인기]아이펠치킨, 풀잎치킨 > [베스트]풀잎치킨 으로 2가지 동시 변경)
df = df.replace('아이펠치킨','[인기]아이펠치킨).replace('풀잎치킨','[베스트]풀잎치킨')
2가지 메뉴명이 변경 된다. (.replace를 연속하여 사용 가능하다 순서는 앞에서부터 실행된다)