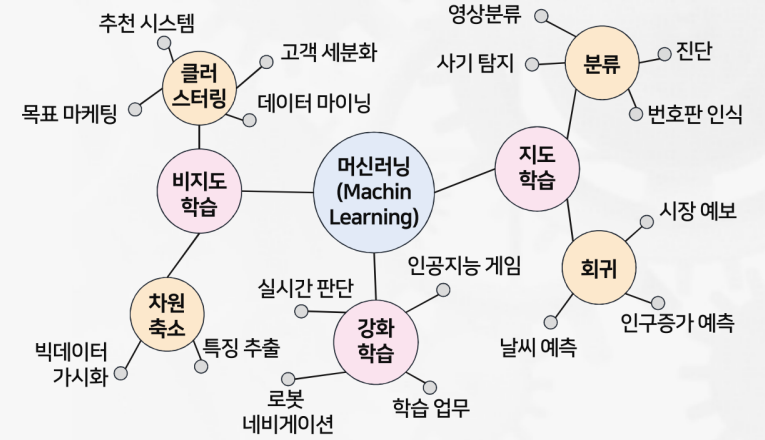
머신러닝의 종류
- 지도학습(Supervised Learning)
- 비지도학습(Unsupervised Learning)
- 강화학습(Reinforcement Learning)
머신러닝 필수 개념
지도학습(Supervised Learning)
- 정답을 알려주면서 진행되는 학습이며, 학습 시 데이터와 함께 레이블(정답)이 항상 제공되어야 함
- 주어진 데이터와 레이블을 이용해 새로운 데이터의 레이블을 예측해야 할 때 사용
- 장점: 손쉽게 모델의 성능을 평가할 수 있음
- 단점: 레이블이 없는 데이터는 레이블을 달기 위해 많은 시간을 투자해야 하는 단점 존재
- 대표적 예
비지도학습(Unsupervised Learning)
- 레이블(정답)이 없이 진행되는 학습이며 학습 시 레이블 없이 데이터만 필요함
- 데이터 자체에서 패턴을 찾아내야 할 때 사용
- 장점: 별도로 레이블을 제공할 필요가 없으므로 시간 절약 가능
- 단점: 레이블이 없으므로 모델의 성능을 평가하는 데 다소 어려움이 있음
- 대표적 예
- 클러스터링
- 차원 축소
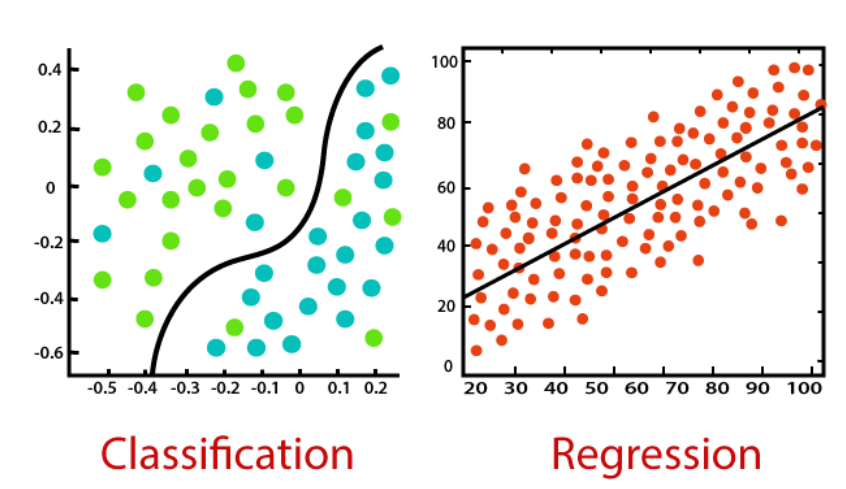
분류와 회귀
분류
- 데이터가 입력되었을 때 지도 학습을 통해 미리 학습된 레이블 중 하나 또는 여러 개의 레이블로 예측하는 것
- 이진 분류: 둘 중 하나의 값으로 분류
- 다중 분류: 여러 개 중 하나로 분류
- 다중 레이블 분류: 두 개 이상의 레이블로 분류
회귀
- 입력된 데이터 대해 연속된 값으로 예측
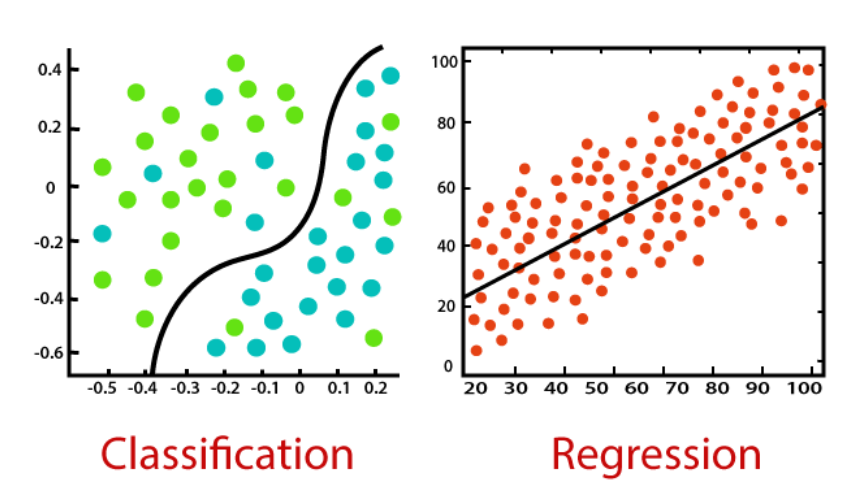
분류와 회귀의 차이점
- 분류: 내일 날씨가 추울까 더울까? hot 예측
- 회귀: 내일 기온은 몇 도 일까요? 32도 예측
과대적합과 과소적합
과소적합(underfitting)
- 모델 학습 시 충분하지 못한 특징만으로 학습되어 특정 특징에만 편향되게 학습된 것(편향이 높음)
- 테스트 데이터 뿐만 아니라 학습 데이터에 대해서도 정확도가 낮게 나올 경우 과소 적합된 모델일 가능성이 높음
- 개선 방법: 학습에 사용된 특징의 개수를 늘리는 방법을 통해 개선
과대적합(overfitting)
- 학습 데이터에 대한 정확도는 매우 높지만 테스트 데이터 또는 학습 데이터 외의 데이터에는 정확도가 낮게 나오는 것(분산이 높음)
- 특징이 필요 이상으로 많을 경우 발생
- 개선 방법: 훈련 데이터를 더 많이 모으거나 학습에 사용된 특징의 개수를 줄이는 방법을 통해 개선
혼동 행렬(뒤에서 부터 읽으면 덜 헷갈림)
- TP(True Positive): 맞는 것을 맞다고 올바르게 예측한 것
- TN(True Negative): 틀린 것을 올바르게 예측한 것
- FP(False Positive): 틀린것을 맞다고 잘못 예측한 것
- FN(False Negative): 맞는 것을 틀렸다고 잘못 예측한 것
머신러닝 모델의 성능 평가
정확도(Accuracy)
- 입력된 데이터에 대해 올바르게 예측한 비율
- 혼동 행렬 상에서는 대각선을 전체 셀로 나눈 값에 해당
TP + TN
정확도 = ----------------------
(TP + FN + FP + TN)
정밀도(Precision)
- 모델의 예측 값이 얼마나 정확하게 예측됐는가를 나타내는 지표
- False를 True라고 판단하면 안되는 경우 중요
TP
정밀도 = ------------
(TP + FP)