Model Compression (경량화)
모델압축 또는 모델 경량화 기술들은 모델의 크기를 줄이고, 처리 속도를 개선하며, 메모리 사용량을 감소시키기 위해 사용된다.
왜 경량화가 필요한가?
- 파라미터 수를 감소시킴으로써 저장공간을 절약할 수 있다.
- 연산량이 감소하여 연상 속도가 향상된다.
- 메모리 사용향이 감소하고 배터리 수명이 향상된다. (모바일 같은 경우에 필요)
1. Pruning
불필요하거나 중요도가 낮은 Model의 weight들의 연결을 제거하여 모델의 sparsity를 높이는 방식이다.
Method
-
Structured Pruning (일반적으로 많이 사용)
그룹 단위로 channel, filter, layer 등 구조 자체를 제거하는 방법. matrix 연산이 사라져 inference 속도가 향상될 수 있음. 하지만 pruning 비율을 높게 하는 것에 한계가 있다. -
Unstructed Pruning
구조와 상관없이 특정 기준을 세워서 matrix 내 값 하나하나를 검토하여 가지치기 수행. 0근처의 weight를 가지치기한다. 필요 없다고 판단되는 weight를 0으로 만드는 것이므로 높은 비율로 pruning 가능하다. 하지만 weight를 0으로 변경할 뿐 matrix 연산은 그대로 수행해야 하기 때문에 inference 속도는 그대로이다.

Dropout과의 차이점
-
pruning : 파라미터 재사용 X
-
dropout : 파라미터 재사용 O, inference과정에서는 모든 파라미터 사용.
대표적인 pruning 기법
- L1 Regularization (L1 정규화):
L1 정규화는 모델의 손실 함수에 가중치의 L1 norm을 추가하여 가중치를 제한하는 방법. 이를 통해 작은 가중치의 연결을 0으로 수렴시키고, 희소한 모델을 만들어 pruning 효과를 얻을 수 있습니다. - Global Magnitude-based Pruning:
전체 가중치의 절댓값에 대한 분포를 계산하고, 상위 또는 하위 퍼센트의 가중치를 제거하는 방법. 예를 들어, 상위 20%의 가중치를 제거하면 상위 20%에 해당하는 가중치들이 가지치기되어 희소한 모델이 만들어집니다. - Layer-wise Magnitude-based Pruning:
각 layer에 대해 가중치의 절댓값에 대한 분포를 계산하고, 각 층에서 상위 또는 하위 퍼센트의 가중치를 제거하는 방법. 각 층에 대해 개별적으로 pruning을 수행하므로, 모델의 각 부분이 서로 다른 pruning 비율을 가질 수 있습니다. - Iterative Magnitude-based Pruning:
여러 번의 pruning iteration을 통해 점진적으로 가중치를 제거하는 방법. pruning 후에 모델을 재학습하고, 이를 반복함으로써 점진적으로 희소한 모델을 형성합니다. - Structured Pruning:
특정 패턴이나 블록 단위로 pruning을 수행하는 방법. 예를 들어, 컨볼루션 층에서 필터 전체를 제거하거나, RNN에서 특정 타임 스텝에 해당하는 연결을 제거하는 등이 있습니다. - Gradient-based Pruning:
역전파 도중에 그래디언트 정보를 기반으로 가중치를 업데이트하면서 pruning을 수행하는 방법. 이 방식은 학습 도중에 동적으로 모델을 가지치기할 수 있는 장점이 있습니다. - Taylor Approximation-based Pruning:
Taylor 근사를 사용하여 각 가중치에 대한 미분 값을 계산하고, 미분 값이 낮은 가중치를 제거하는 방법. 이는 모델의 출력에 미치는 영향이 적은 가중치를 제거하는 방식입니다.
2. Distillation
모델의 크기를 줄이고 성능을 유지하는데 초점을 맞춘 기법으로 teacher모델 (큰 모델)에서 학습한 지식을 student model (작은 모델)에 전달하는 방법
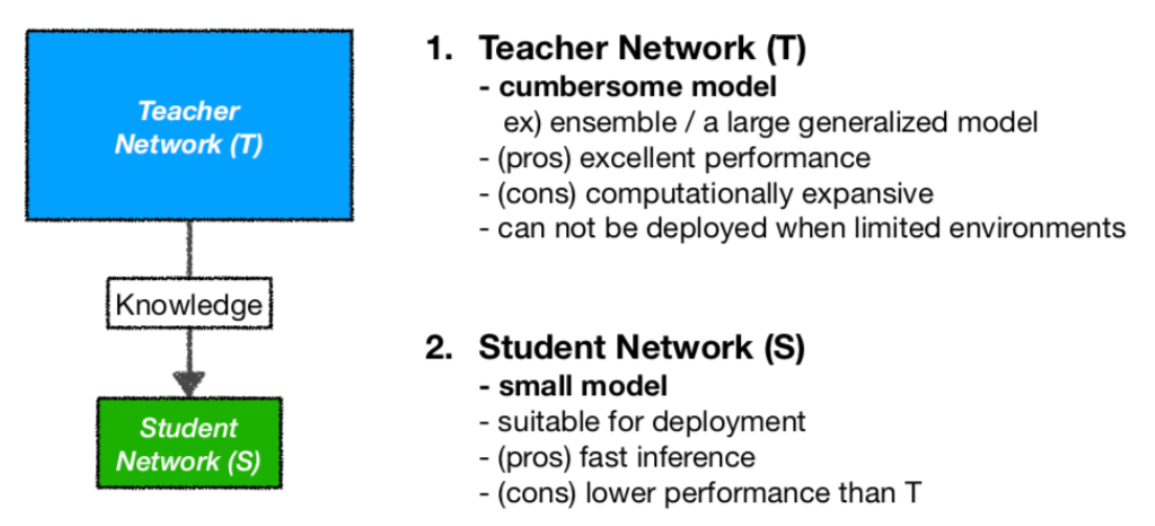
Teacher model에서 정보를 얻는 방식
- Response-Based Knowledge - 최종만 빼내는 경우
- Feature-Based Knowledge - 중간중간 layer의 결과를 빼내어 student에게 넘겨주는 경우
- Relation-Based Knowledge - 데이터 간의 정보(input layer), 여러 feature들간의 정보(hint layers), 출력 결과 간의 정보(output layer)처럼 특정 데이터 혹은 feature 간의 정보를 활용한 경우
Distilling the Knowledge in a Neural Network 논문 내용
기존의 softmax 수식에서 temperature내용만 추가됨.
softmax는 logit 값들을 입력으로 받아 각 클래스에 대한 확률이 0과 1사이에 있고 전체 합이 1이 되도록 출력하는 함수이다.
-
: 클래스 에 대한 확률 (Softmax 출력)
-
: 클래스 에 대한 logit 값 (모델의 예측값)
-
: 클래스 의 로짓에 대한 지수 함수 값
(확률이 지수 함수를 통해 스케일링됨) -
: 모든 클래스의 지수 값들의 합
(정규화 분모, 전체 클래스 확률의 합이 1이 되도록 함)
T가 1보다 크면 출력 확률 분포가 더 균등해짐. 확신이 덜한 예측, 즉 다른 경우의 수도 함께 추가 고려.
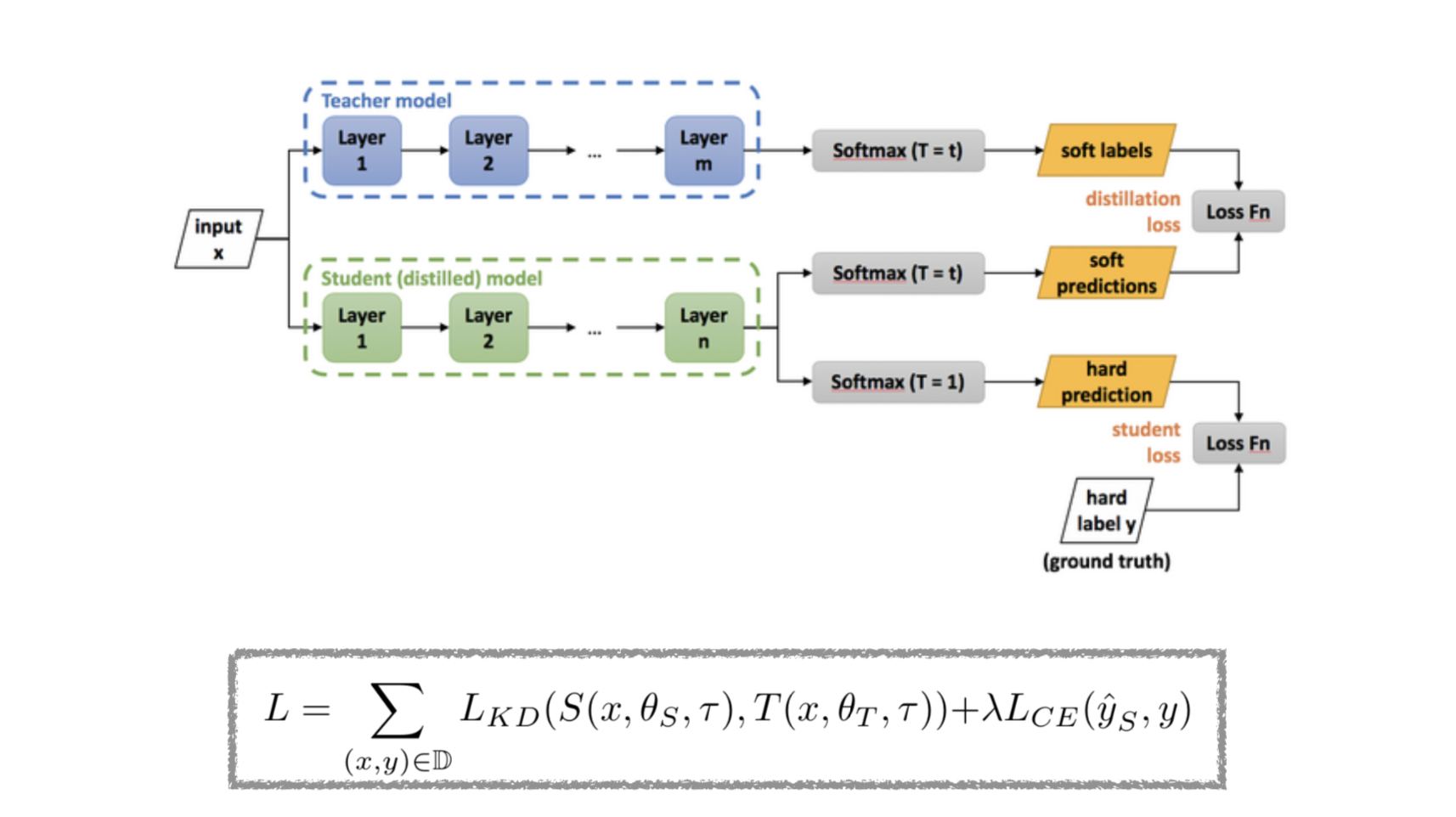
Cross Entropy Loss ()와 Distillation Loss ()로 구성됨.
- : Loss function
- : Student model
- : Teacher model
- : 하나의 입력 이미지와 해당 정답 레이블
- : 모델의 학습 파라미터
- : Temperature (온도 하이퍼파라미터)
3. Quantiation
모델의 수치적 표현을 최적화하여 계산 효율성을 높이고 메모리 요구사항을 줄이는 방법. 파라미터 수는 그대로이지만 모델의 크기가 작아진다.
32bit -> 4byte / 1byte = 8bit
모델 크기 = 파라미터 수 x 파라미터 크기 = 1억 x 4 byte = 4억 byte
1MB = 1024KB / 1KB = 1024B
Quantization 기법들
| Quantization Modes | Data Requirements | Inference Latency | Inference Accuracy Loss |
|---|---|---|---|
| Dynamic Quantization | No Data | Usually Faster | Smallest |
| Static Quantization | Unlabeled Data | Fastest | Smaller |
| Quantization Aware Training | Labeled Data | Fastest | Smaller |
1) Post-Training Quantization (학습 완료 후 양자화)
-
Dynamic quantization
Dynamic quantization이란 weight는 항상 양자화 하고, activation은 inference할 때 양자화 하는 방법입니다.
따라서 activation은 메모리에 저장될 때 floating-point형태로 저장됩니다. -
Static quantization
Static quantization은 weight와 activation을 모두 양자화 하는 방법입니다.
Static quantization은 Dynamic quantization과 다르게 activation의 scale factor와 zero point를 계산할 필요가 없어 연산이 빠른 장점이 있습니다.
2) Quantization Aware Training
- Post-Training Quantization
Post-Training Quantization은 32bit를 사용하여 저장한 floating-point형 숫자를 더 낮은 비트를 사용하여 표현하는 방법입니다. 따라서 숫자를 저장할때 정확도 손실이 발생하며, 이 모델로부터 다시 원래 숫자를 복원할 때 양자화 하기 전의 값과 차이가 발생합니다. 이 차이로부터 모델 전체의 성능저하가 발생하게 됩니다.
reference
Pruning
- https://simpling.tistory.com/50
- https://mangstor.tistory.com/24
- https://silhyeonha-git.tistory.com/42
- https://blog.may-i.io/tech-14/
Distillation
- https://velog.io/@qtly_u/%EB%AA%A8%EB%8D%B8-%EA%B2%BD%EB%9F%89%ED%99%94-%EA%B8%B0%EB%B2%95-Knowledge-Distillation
- https://baeseongsu.github.io/posts/knowledge-distillation/
Quantization
- https://wikidocs.net/250972
- https://note.mmmsk.myds.me/Study/Deep-Learning/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EC%9D%91%EC%9A%A9/(Quantization)-%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-%EC%96%91%EC%9E%90%ED%99%94-1
- https://velog.io/@woojinn8/LightWeight-Deep-Learning-2.-Quantization
- https://leimao.github.io/article/Neural-Networks-Quantization/
