1. Retrieval-Augmented Generation (RAG)란?
LLM이 외부 정보를 참조해 답변을 더 정확하게 생성할 수 있도록 도와주는 기법이다. 좀 더 구체적으로 RAG는 retrieval과 generation을 결합한 방식으로 동작한다. RAG의 과정은 질문을 입력받고, 관련된 문서를 검색한 후, 그 정보를 바탕으로 응답을 생성하는 것이다.
Retriever: 쿼리에 기반해 관련 문서 또는 passage를 외부 데이터베이스에서 검색
Generator: 검색된 문서를 참조하여 이에 기반해 좀더 정확하고 구체적인 자연어 응답을 생성
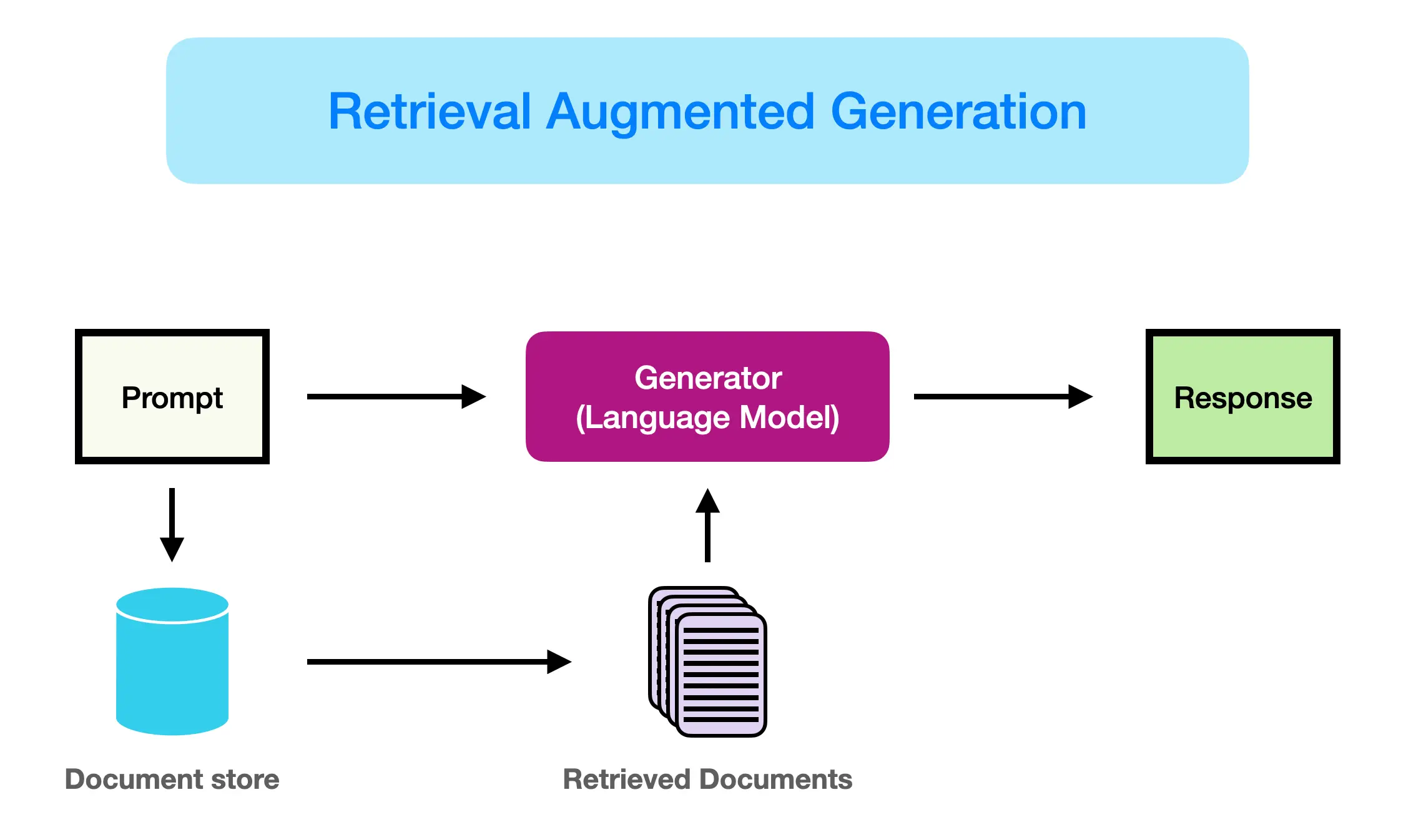
그 과정에서 sparse vector을 사용하느냐, dense embedding을 사용하느냐를 선택할 수 있다.
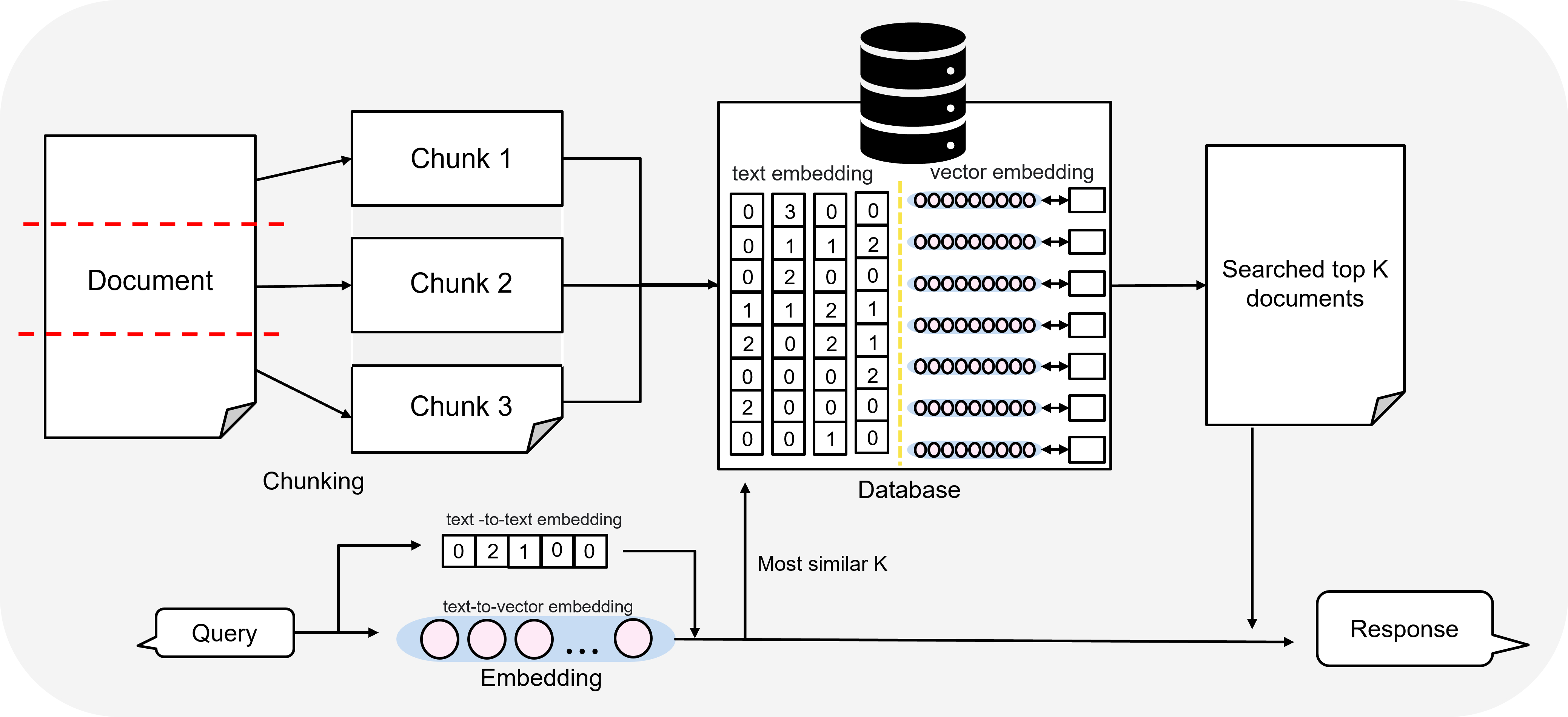
2. Retrieval: Sparse vs Dense
1. Sparse Retrieval
Sparse Retrieval은 전통적인 정보 검색 기법 (IR)이다. 문서와 쿼리를 sparse vector로 표현하고 단어 기반으로 관련성을 계산하여 검색을 사용한다.
대표적인 방법
- TF-IDF (Term Frequency-Inverse Document Frequency)
- BM25(Best Matching 25)
특징
-
벡터 공간 모델을 기반으로 하고 일반적으로 벡터 차원은 vocabulary size를 사용한다. 단어의 빈도수나 역문서빈도(Inverse Document Frequency, IDF) 등을 활용하여 유사도를 계산한다.
-
단어 단위로 검색을 하기 때문에 쿼리과 문서에서 정확히 같은 단어가 등장해야만 관련성이 높게 평가된다.
-
대부분 sparse vector로 표현된다. 즉, 대부분의 값이 0인 벡터이고 특정 단어에 대해서만 weight가 부과된다.
그래서 일반적으로 IDF (Inverse Document Frequency)를 사용하여 sprase vector을 압축하여 공간을 절약하면서 유용한 단어의 빈도를 고려한다.
장점
- 계산 효율이 높고, 대규모 인덱스 구축 및 검색이 편하다.
- 문서와 쿼리가 정확히 일치하는 단어들이 많을수록 검색 품질이 좋다.
단점
- 의미적으로 유사한 단어 (semantic similarity)를 인식하기 어렵다. 예를 들어, "자동차"와 "차"를 구분하지 못할 수 있다.
- 문맥 이해가 어렵고, 유의어 처리나 질의 변형에 취약하다.
2. Dense Retrieval
Dense Retrieval은 쿼리와 문서를 동일한 임베딩 공간 상의 dense embedding으로 변환하고, 벡터 간 시맨틱 유사도를 기준으로 검색하는 방식이다. 즉, 단어의 의미나 문맥을 이해하여 관련성을 파악한다.
대표적인 모델
- DPR (Dense Passage Retriever)
특징
-
단어 수준의 일치를 넘어선 의미적 유사도를 계산합니다. 즉, 의미적으로 유사한 단어들이나 구문을 잘 인식할 수 있다.
-
문서와 쿼리 각각 고차원 임베딩하여 벡터공간에 매핑된다. 일반적으로 128-1024차원으로 벡터 차원이 구성되고 일반적으로 Faiss로 구현되고 cosine similarity나 Euclidean distance로 유사도를 계산한다.
장점
- 시맨틱 검색을 통해 의미적으로 유의어나 변형된 문장구조 대응을 잘 할 수 있다.
단점
-
학습 비용이 높고, 사전 학습(pretraining)된 retriever가 필요하다.
-
속도 면에서 Sparse Retrieval보다 상대적으로 느릴 수 있다.
3. RAG에서 Sparse Retrieval과 Dense Retrieval의 활용
RAG는 기본적으로 Retrieval(검색)과 Generation(생성)을 결합하는 방식이다.
그러므로 Retrieval 부분에서 Sparse Retrieval과 Dense Retrieval을 조합하거나 하나를 선택적으로 사용할 수 있다.
Sparse Retrieval을 사용할 경우
-
Retrieval: 쿼리에 대한 문서 검색을 TF-IDF나 BM25와 같은 sparse 벡터 기반 기법을 사용하여 빠르게 수행한다.
-
Generation: 문서 내용에 기반한 자연어 생성 모델이 답을 생성한다.
Dense Retrieval을 사용할 경우
-
Retrieval: 쿼리와 문서 모두 임베딩을 통해 고차원 벡터로 변환된 후, 벡터 간의 유사도를 계산하여 관련된 문서를 검색한다.
-
Generation: 선택된 문서들을 바탕으로 보다 정확하고 의미있는 답변을 생성한다.
4. Sparse Retrieval vs Dense Retrieval: RAG에서의 선택 기준
속도와 효율성이 중요한 경우, Sparse Retrieval이 더 유리할 수 있다. 예를 들어 빠른 검색이 중요한 대규모 시스템에서는 Sparse Retrieval이 더 적합할 수 있다.
정확도와 semantic similarity가 중요한 경우, Dense Retrieval이 더 낫다. 유의어나 문맥을 잘 파악해야 하는 의미 기반 검색이 필요한 상황에 효과적이다.
RAG에서는 두 방식이 함께 사용되기도 한다. 예를 들어, 먼저 Sparse Retrieval을 사용하여 먼저 빠르게 후보 문서를 찾고, 그 문서들을 Dense Retrieval 모델을 통해 필터링하거나, Dense Retrieval을 사용하여 더 정교한 결과를 도출해낼 수 있다.
5. RAG 패러다임
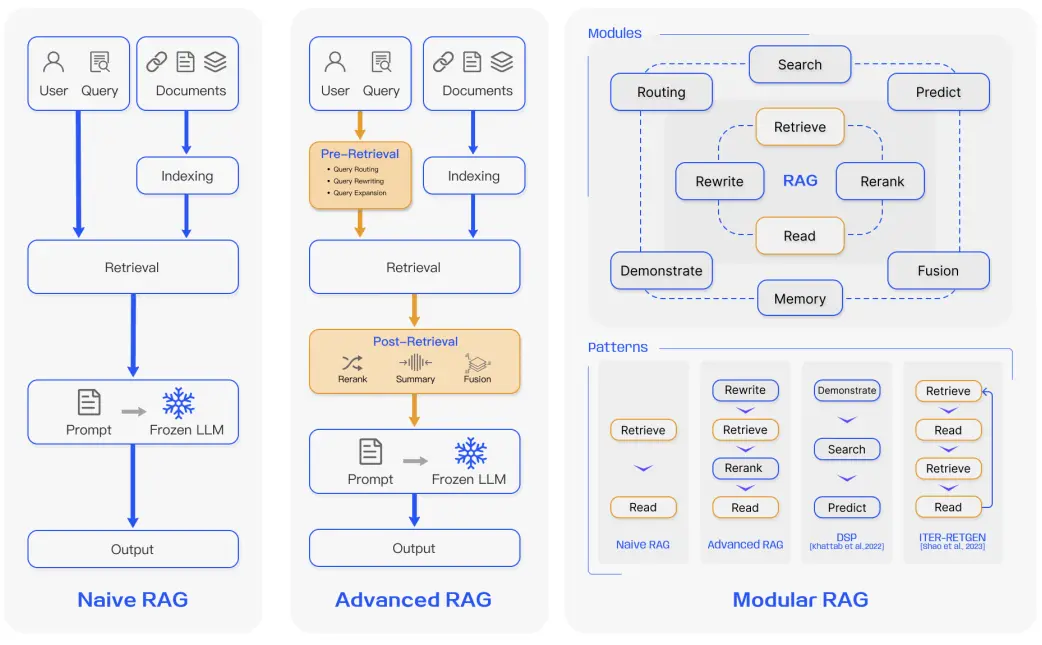
1. Naive RAG
단순한 문서 검색 후, 검색된 문서를 그대로 생성 모델에 입력하여 답변을 생성하는 기본적인 방식.
2. Advanced RAG
문서 재순위화, 필터링, 퓨전 등 추가 처리 단계를 통해 검색 결과의 품질을 향상시킨 고도화된 방식.
3. Modular RAG
검색기, 선택기, 생성기를 분리된 모듈로 구성하여 각 구성 요소를 독립적으로 교체하거나 조정할 수 있는 유연한 구조.
reference
