Attention Is All You Need (Ashish Vaswani et al. 2017)
1. Background
기존의 시계열 데이터 처리 방법은 RNN, LSTM, GRU 방법을 사용했다.
하지만 이 방법들은 병렬 연산이 불가능 하였다.
그래서 이 논문에서는 transformer라는 병렬연산 가능한 모델을 제안하였다.
2. Model Architecture
왼쪽은 Encoder이고 오른쪽은 Decoder 이다.
-> Transformer는 번역하는 모델이기 때문에 Encoder에서는 source 언어문장을 처리하고, Decoder는 Encoder에서 전달된 문장을 target 언어문장으로 번역하여 생성하는 데 사용됩니다.
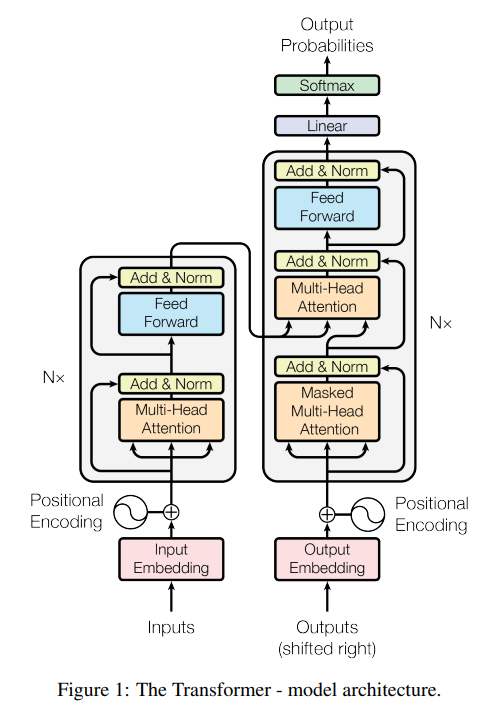
3. Encoder
Encoder에는 positional Encoding과 multi-head attention으로 이루어져 있다.
3-1. Positional Encoding
왜 필요한가?
- 기존의 RNN 계열 모델로 시계열 분석을 수행할때 차례로 단어들의 순서가 기록된다. 하지만 transformer에서는 input token이 병렬로 들어가고, 입력순서가 기록되어 있지 않기때문에 위치정보를 추가로 주입해 줘야 한다.
- 뒤에서 Multi-Head Attention을 통해서 query와 key정보를 내적하게 되는데 이때 순서가 달라도 내적값은 모두 같다. 순서가 다를 경우 강조가 다르게 될 경우가 있고, 동음이의가 들어왔을 때는 문맥상 다른 의미로 쓰이는 경우도 존재하기 때문에 순서가 필요하다.
수식
- 단어의 위치 (position, 0부터 시작)
- 임베딩 벡터의 차원 인덱스
- 임베딩 벡터의 총 차원 수 (예: 512)
임베딩의 짝수 인덱스에는 sine, 홀수 인덱스에는 cosine 값을 사용한다.
주파수가 다른 sin/cos 함수를 이용해서 각 위치 pos마다 고유한 패턴을 갖는 벡터를 생성합니다.
이렇게 하면 모델은 위치 간의 상대적 거리나 주기성 같은 정보를 인코딩된 벡터로부터 추론할 수 있습니다.
이 외에도..
- Absolute positional encoding
- 각 위치마다 고정된 벡터 부여
- e.g. 토큰 A는 3번째 위치이다.
- Relative positional encoding
- 위치간 상대거리 정보만 반영
- e.g. 토큰 A는 토큰 B보다 2칸 뒤에 있다.
3-2. Multi-Head Attention
1. attention이란?
- attention을 통해 주목해야 할 특정 몇몇 단어에 더 높은 가중치를 부여하여 집중하는 것
2. self-attention 이란?
- 같은 문장 내에서 단어들 간의 관계, 즉 연관성을 고려하여 attention을 계산한다.
3. Query, Key, Value란?
- Query: input sequence에서 관련된 부분을 찾으려는 정보벡터
- Key: 관계의 연관도를 결정하기 위해 query와 비교하는데 사용되는 벡터
- Value: 특정 key에 해당하는 입력 시퀀스의 정보로 가중치를 구하는데 사용되는 벡터
4. Multi-Head Attention이란?
- 여기서는 특정 단어가 문장의 다른 단어들과 얼마나 유사한지, 중요한지 알기위해 계산하는 부분이다. Q,K를 곱한 후 V를 곱하게 된다.
- 이때 Q=K=V이다.
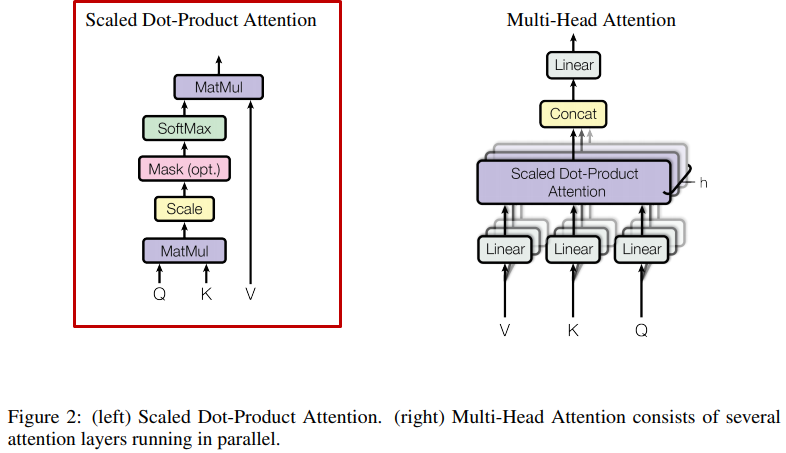
그냥 attention (가중치 합) 은 내적으로 각 단어에 대한 내적을 각각 구하기 때문에 위치 정보나 주변 맥락 정보가 없다(주위 키는 고려하지 않음으로). 하지만 multi-head attention을 진행하게 되면 self-attention layer들을 지나기 때문에 어느 특정한 단어는 문장의 맥락 정보를 고려한 임베딩으로 바뀌게 된다. (문장의 다른 단어들과 관련도가 반영되게 된다)
왜냐하면 각 단어들을 전체 문장의 단어들과 내적을 해서 유사도를 구하고 그 값을 다음 layer의 input으로 넣어주게 되기 때문이다.
5. Scaled dot product attention 이란?
왜 필요한가?
- Query와 Key의 길이가 커질 수 록 내적 값 역시 커질 가능성이 높기 때문에 softmax 기울기가 0인 영역에 도달할 가능성이 높다.
- 그래서 내적 값이 softmax의 기울기가 0인 영역에 도달하지 못하도록 scaling하는 것이다.
-
: Key 벡터의 차원 수
-
: Query와 Key 간의 유사도 (내적) 행렬
-
: 스케일링 인자 (값이 커질수록 softmax의 gradient가 작아지는 것을 방지)
4. Decoder
Decoder은 Cross Attention과 Masked Multi-Head Attention으로 이루어져 있다.
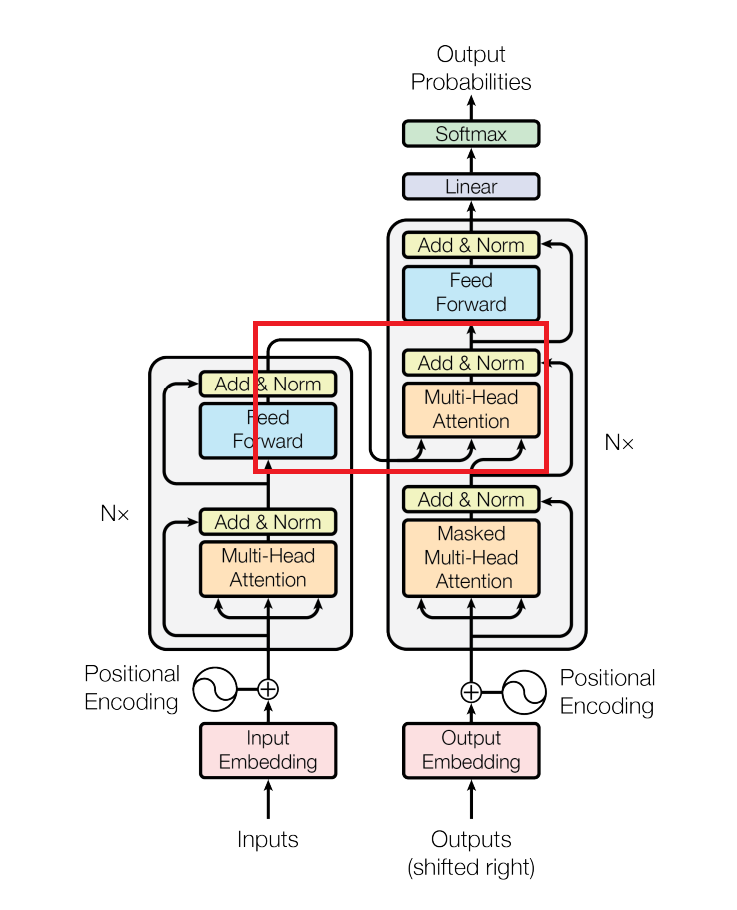
1. Cross Attention
Cross Attention은 Encoder에서 얻은 결과를 Decoder에 넣는 부분을 의미한다.
이때 Query Key, Value 이다.
- Query는 Decoder의 이전 layer에서 전달되며 현재 번역 작업이 어디까지 진행하였는지에 대한 데이터를 가지고 있다. (target 언어의 토큰값이 들어간다)
- Key, Value는 Encoder에서 indexing 된 토큰들이 들어가게 된다.
결론적으로 Encoder에서 계산한 Key, Value를 곱해서 source 언어에서 단어들간 어떤 관계가 있는지 찾은뒤 Decoder에서 Query를 곱하게 된다. 이 과정을 거치면서 target 언어에 해당하는 token과 source 언어에 해당되는 token의 연관성을 찾게 된다.
2. Masked Multi-Head Attention
transformer의 기능은 번역이기 때문에 번역 타겟 문장의 첫 단어부터 순차적으로 단어를 예측한다.
- 한국어-> 영어로 번역한다고 치면
- 한국어 문장 정보는 모두 Encoder에 넣어서 쓴다. 그 때 번역할 문장 예시는 N번째 단어를 예측할때는 N-1까지 Decoder에 입력해서 Decoder가 N번째 단어를 예측하도록 한다.
- <SOS>+ 문장을 넣어서 최종적으로 문장 + <EOS> 가 나오도록 하는 방법.
- 이 방법은 Decoder에서 Multi-head attention을 거치기 때문에 학습을 하면서 모든 문장정보를 사용하는 것이다. 하지만 실제로 번역할때는 사용자가 어떤 문장을 넣을지 모르기 때문에 이렇게 학습하면 안된다.
그래서 masking을 하여 현재 필요한 토큰과 과거정보만 전달하고 미래정보는 주지 않는다.
이때 masking은 내적 결과에 극단적인 음수값을 줘서 exp 했을 때 0이 되도록 하는 것이다.
reference
- https://www.youtube.com/watch?v=6s69XY025MU&list=LL&index=27&t=1087s
- https://www.blossominkyung.com/deeplearning/transformer-mha
- https://tigris-data-science.tistory.com/entry/%EC%B0%A8%EA%B7%BC%EC%B0%A8%EA%B7%BC-%EC%9D%B4%ED%95%B4%ED%95%98%EB%8A%94-Transformer1-Scaled-Dot-Product-Attention
-https://cypsw.tistory.com/entry/Transformer-%EC%9D%98-CrossAttention
