1. 프롬프트 엔지니어링
AI 모델로부터 원하는 결과물을 얻기 위해 입력하는 프롬프트를 최적화하는 기술
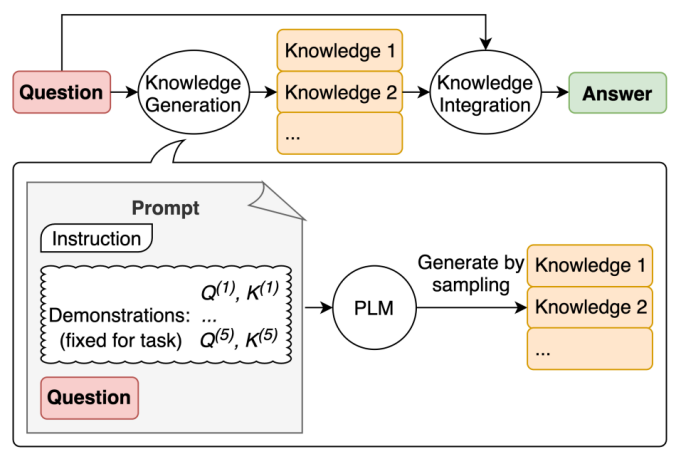
2. Generated Knowledge Prompting(GKP)
LLM에게 문제를 바로 푸는 대신 먼저 관련된 중간 지식을 생성하게 한 후, 생성된 지식을 다시 프롬프트에 포함시켜 최종 답변이나 추론을 돕는 방법
- Generated Knowledge Prompting for Commonsense Reasoning (Liu et al. 2022)
3. Chain of Thoughts (CoT)
LLM이 최정적인 답변까지 도달하기 전데 중간 reasoning 단계들을 더해줌으로써 LLM의 reasoning 능력과 함께 정확한 답을 도출할 수 있게 하는 것
-
GPT-o1 이 CoT를 기반으로 성능이 향상되었다고 한다.
-
Step by Step reasoning을 해서 여러 중간 reasoning단계로 답을 더 쉽게 도출한다.
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al. 2022)
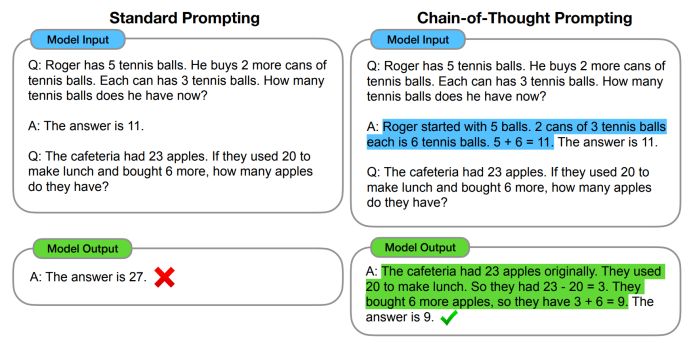
3-1. Few-shot CoT
여러 비슷한 문제를 해결하는 CoT예시들을 LLM에 입력하여 LLM이 이와 비슷하게 reasoning 단계를 따라가도록 유도하는 방식
But, 비슷한 예시 CoT 예시를 각 메뉴얼 방법에 맞게 넣어줘야 한다.
3-2. Zero-shot CoT
"Let's think step by step" 을 프롬프트에 추가하여 LLM이 예시 없이 step by step으로 생각하도록 유도하여 문제를 풀도록 하는 방식
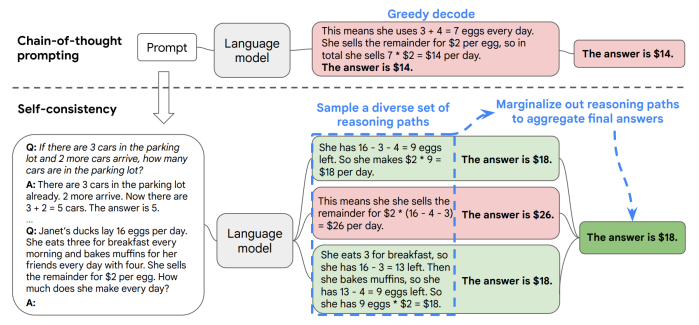
4. Self-Consistency (CoT-SC)
LLM이 문제를 여러번 서로 다른 방식으로 생각해보고, 여러개의 CoT 추론 경로 중에서 가장 많이 등장한 답을 선택하는 방식
정답은 하나이고 과정은 여러가지이므로 일관되게 등장하는 답으로 최종 답을 선택한다.
- SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT
REASONING IN LANGUAGE MODELS (Wang et al. 2022)
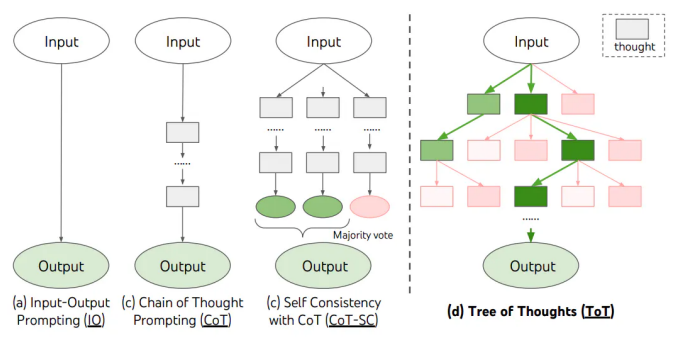
5. Tree of Thoughts (ToT)
언어 모델이 여러명의 전문가를 연기하며 단계적으로 추론 과정을 거쳐 스스로의 생각을 관찰 및 평가하고 수정하여 최종 결론을 도출하는 방법
트리기반 구조를 LLM에 적용하였고 중간에 피드백을 이용하여 유망한 경로만 남긴다.
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models (Yao et el. 2023)
이 외에도...
1. Automatic Reasoning and Tool-use (ART)
2. Prompt Chaining
3. ReAct Prompting
내 생각에는 reACT 기반으로 AI agent 아이디어가 나오지않았을까 생각이 든다!
reference
