예시로, 아래와 같은 예시 테이블을 활용하여, 자주 쓰이는 Pandas의 Series 및 DataFrame의 속성(Attributes)과 메서드(Method)에 대해 정리해보자.
data_with_stock # example DataFrame.dtypes
data_with_stock.dtypes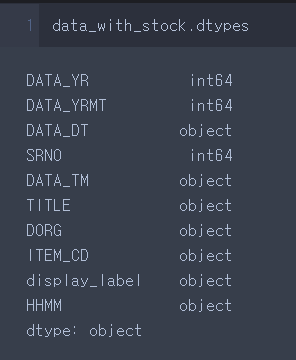
.head(), .sample()
data_with_stock.head(3)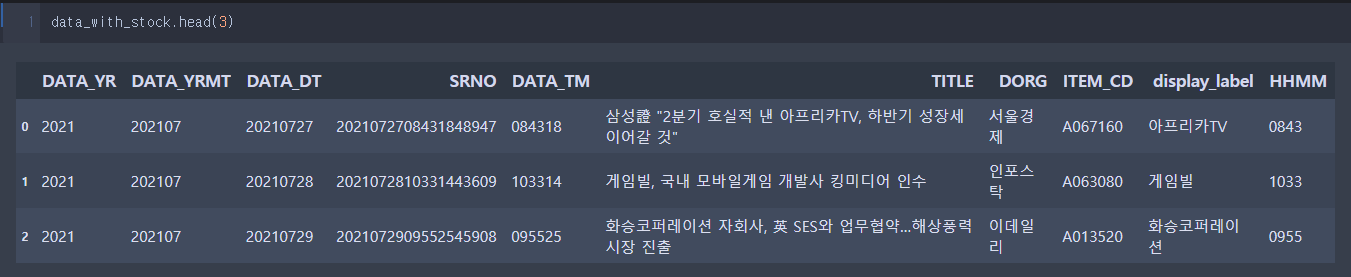
data_with_stock.sample(3, random_state=42) # random_state : set seed number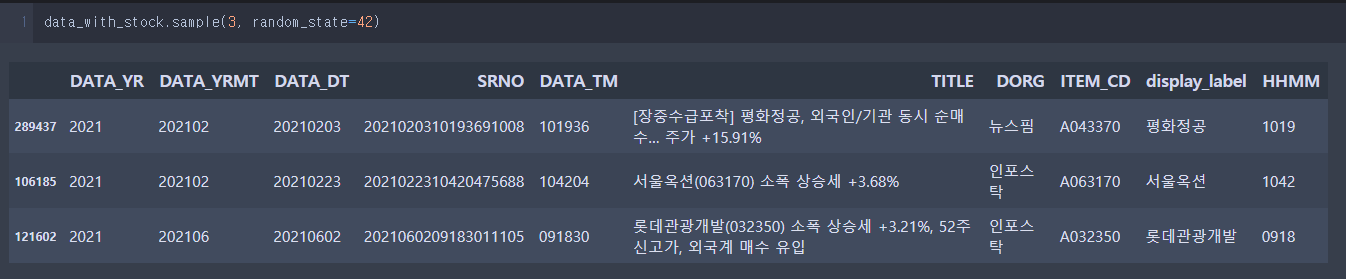
.value_counts()
data_with_stock.value_counts()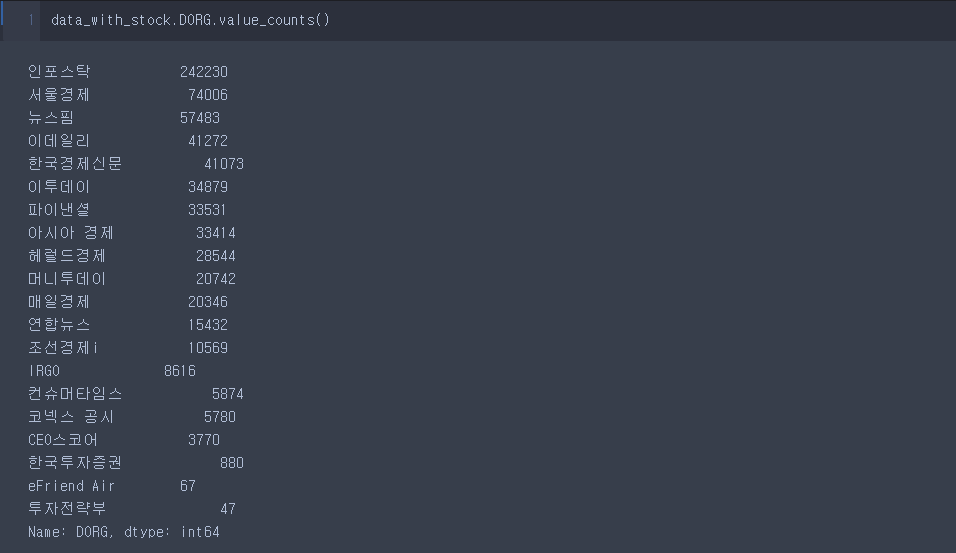
.size, .shape
data_with_stock.size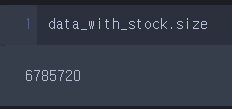
data_with_stock.shape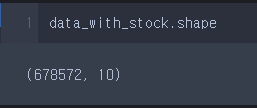
참고로, 아래와 같이 shape의 첫 번째 원소로 size와 같은 정보를 얻을 수 있다.
data_with_stock.shape[0].unique()
data_with_stock.DORG.unqiue()
.count()
.count() 메서드는 na가 아닌 Series의 길이를 반환한다. 일례로, data_with_stock 테이블에 .size 속성을 적용한 값과 data_with_table.DORG Series에 메서드를 적용한 값이 다른 것을 볼 수 있다.
data_with_stock.DORG.count()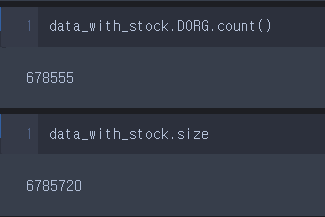
.min(), .max(), .mean(), median(), std()
해당 메서드들은 Pandas Series 뒤에 붙어 해당 연산을 수행해준다. 나의 예시 DataFrame에 numeric 변수가 없어 부득이하게 생략하도록 하겠다ㅠ
사용법 지금까지와 같으니 참고!
data_with_stock.COLUMN_NAME.min()
data_with_stock.COLUMN_NAME.max()
data_with_stock.COLUMN_NAME.mean()
data_with_stock.COLUMN_NAME.median()
data_with_stock.COLUMN_NAME.std().describe()
numeric 변수나 Series에 대해 위의 연산자를 일일히 사용하여 EDA를 하는게 귀찮게 느껴질 수 있다.
그럴 때, 이 .describe() 메서드를 써주면 된다.
1) Series의 dtype이 문자인 경우
data_with_stock.DORG.describe()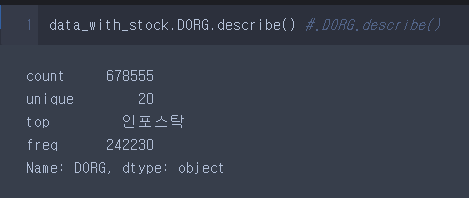
2) Series의 dtype이 numeric(float, int)인 경우
data_with_stock.DATA_YRMT.describe()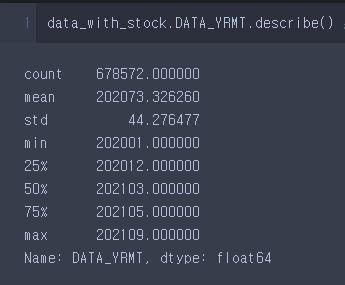
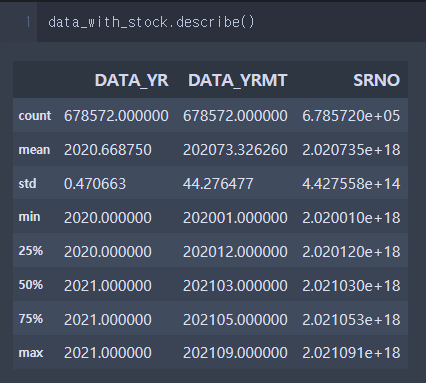
3) DataFrame에 적용했을 경우
data_with_stock.describe()Python이 numeric으로 인식한 컬럼에 대해서만 요약 통계량 값을 제시해준다.
.quantile()
data_with_stock.DATA_DT.astype(int).quantile(0.01)
data_with_stock.DATA_DT.astype(int).quantile(0.99)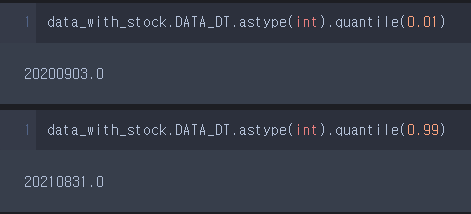
.isna()
Series의 원소가 na인지를 bool Series로 반환한다.
data_with_stock.DORG.describe()
.fillna()
이는 Series내의 na인 값을 특정 값으로 대체시키는 메서드이다.
data_with_stock.DORG.fillna({원하는 값}).dropna()
이는 Series내의 na인 값을 제거하는 메서드이다.
data_with_stock.DORG.dropna().hasnans
이는 Pandas series가 하나라도 na값을 가졌는지(any) 여부를 bool값으로 반환한다.
data_with_stock.DORG.hasnans.notna
이는 Pandas Series값이 na이 아닌가에 대한 Series를 반환하는 함수이다. 이는 .isna()결과를 logical not으로 뒤집어 표현한 것과 같다.
data_with_stock.DORG.notna()참고 문헌은 아래와 같다.
