abstract
-
DVS란?
일반 카메라와 달리, 영상 전체를 촬영하는 것이 아니라 움직임이 있는 부분만을 감지하여 데이터를 기록하는 저전력, 고효율 카메라입니다. -
연구 방법
연구팀은 DVS가 포착한 움직임 데이터로 '모션 맵(Motion Map)'이라는 특징을 만들고, 이를 기존의 움직임 분석 기술인 '모션 경계 히스토그램(MBH)'과 결합했습니다. -
가장 중요한 결과
DVS는 일반 비디오보다 훨씬 적은 양의 데이터(희소한 정보)만 사용함에도 불구하고, 일반 비디오와 비슷한 수준의 높은 행동 인식 성능을 보였습니다. 이는 DVS가 웨어러블 기기 등에서 매우 유용하게 쓰일 수 있음을 의미합니다.
Introduction
-
문제 제기: 기존 카메라는 움직임이 없어도 모든 장면을 계속 찍기 때문에 전력과 메모리 낭비가 심합니다.
-
대안 제시: 이 논문은 '동적 비전 센서(DVS)'를 대안으로 제시합니다. DVS는 사람의 눈처럼 움직임이 있을 때만 데이터를 기록하는 저전력/고효율 카메라입니다.
-
연구 목표: 이 DVS를 사용하여 사람의 행동이나 제스처를 인식하는 방법을 개발하는 것입니다.
-
연구 방법: DVS가 만든 움직임 데이터로 '모션 맵'을 만들고, 'Bag of Visual Words' 기법을 이용해 핵심 특징을 추출했습니다. 여기에 다른 기술(MBH)을 더해 성능을 더욱 높였습니다.
-
핵심 결과: DVS는 데이터 양이 훨씬 적음에도 불구하고, 기존 비디오와 비슷한 수준의 높은 행동 인식 성능을 보여주었습니다. 이는 DVS의 잠재력이 매우 크다는 것을 시사합니다.
1.1 Related work
- 전통적인 방식 vs. 딥러닝 방식
전통적으로 행동 인식은 영상에서 움직임이나 모양에 대한 특징(MHI, HOF, MBH 등)을 추출하고, 이를 기계(SVM 등)에 학습시키는 방식으로 이루어졌습니다. 하지만 이 방식은 카메라 움직임에 취약하거나 DVS 센서처럼 색상, 배경 정보가 없는 데이터에는 적용하기 어려운 단점이 있습니다.
최근에는 딥러닝(CNN, LSTM 등)을 사용해 컴퓨터가 스스로 특징을 학습하게 하는 방식이 주류가 되었습니다. 특히 2-스트림 CNN은 영상의 정지 이미지(모양 정보)와 움직임 정보(광학 흐름)를 각각 별도의 신경망으로 학습시켜 합치는 방식으로 높은 성능을 보여줍니다.
- 이 논문의 접근 방식
이 논문은 최신 딥러닝처럼 복잡한 모델을 사용하는 대신, DVS가 제공하는 핵심 정보(움직임과 모양)에 집중합니다.
간단한 모양 기반 특징과 움직임 기반 특징을 '융합(fusion)'하는 직관적이고 쉬운 방법을 제안하며, 이 방법만으로도 충분히 좋은 성능을 낼 수 있다는 점을 강조합니다.
2. DVS Based Activity Recognition
1단계: DVS 데이터를 '모션 맵'으로 변환
DVS에서 실시간으로 출력되는 (x, y, 시간) 형태의 이벤트 데이터를 바로 분석하기 어렵기 때문에, 컴퓨터가 이해하기 쉬운 세 장의 2D 이미지로 요약합니다.
-
3D 비디오 생성: DVS 이벤트들을 짧은 시간 간격으로 묶어 30fps 비디오(3D 데이터 덩어리)를 만듭니다.
-
2D 투영 (압축): 이 3D 데이터를 각기 다른 축 방향으로 압축(평균)하여 세 종류의 2D 모션 맵을 생성합니다.
- x-y 맵: 시간 축으로 압축. 비디오 전체 시간 동안 어디에서 움직임이 발생했는지 보여줍니다. (객체의 평균 자세)
- x-t 맵: 세로 축으로 압축. 시간의 흐름에 따른 객체의 수평 움직임 패턴을 보여줍니다.
- y-t 맵: 가로 축으로 압축. 시간의 흐름에 따른 객체의 수직 움직임 패턴을 보여줍니다.
2단계: 특징 추출 및 융합을 통한 행동 인식
모션 맵이 생성되면, 전통적인 컴퓨터 비전 파이프라인(Bag of Features)을 통해 행동을 분류하고, 성능을 극대화하기 위해 두 번의 융합을 거칩니다.
-
1차 융합 (모션 맵 내부):
-
세 종류의 모션 맵 각각에서 SURF 알고리즘으로 특징점을 추출합니다.
-
k-평균 클러스터링을 이용해 이 특징점들로 '시각 단어 사전'을 만듭니다.
-
각 맵을 이 사전을 기준으로 '단어 빈도수 통계'(BoF 히스토그램)로 변환합니다.
-
이렇게 만들어진 세 개의 히스토그램을 하나로 합쳐 모양과 움직임 정보를 모두 담은 1차 특징을 완성합니다.
-
-
2차 융합 (외부 기술 결합):
-
1차 융합으로 만든 '모션 맵 특징'에, 완전히 다른 방식으로 움직임을 분석하는 최첨단 기술 MBH의 특징을 추가로 결합합니다.
-
이유: 모션 맵은 단순히 이벤트의 평균(0차 통계)을 보는 반면, MBH는 움직임의 변화율(2차 통계)을 계산합니다. 서로 다른 관점의 정보를 제공하므로, 둘을 합치면 서로의 단점을 보완하여 훨씬 더 정확한 분석이 가능합니다.
-
-
최종 분류:
- 이렇게 완성된 최종 특징 데이터를 SVM 분류기에 학습시켜 특정 행동(예: 손 흔들기, 발 차기 등)을 예측하게 합니다.
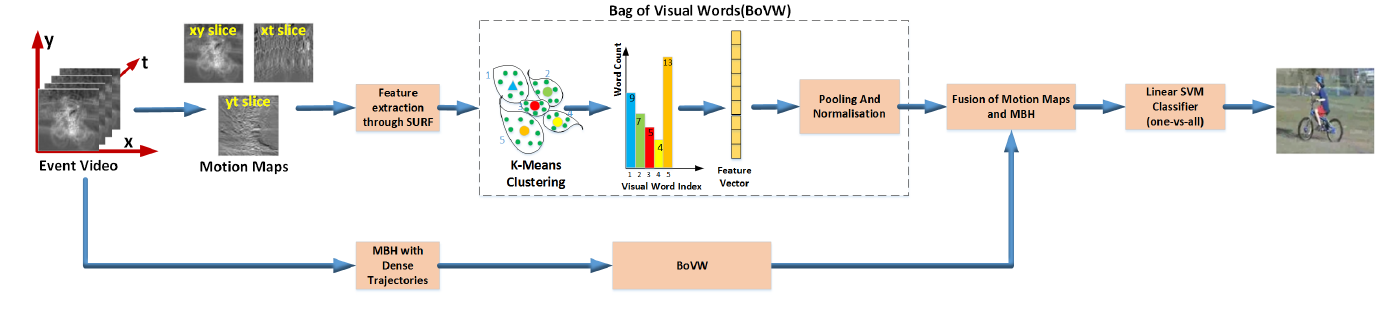
- 이렇게 완성된 최종 특징 데이터를 SVM 분류기에 학습시켜 특정 행동(예: 손 흔들기, 발 차기 등)을 예측하게 합니다.
example of figure
1단계: SURF로 특징점 추출하기
먼저, 가지고 있는 모든 훈련용 이미지(고양이 사진 10장, 바퀴 사진 10장)에 SURF를 적용해 특징점을 찾습니다.
- 고양이 얼굴 이미지에서는 😺:
- 뾰족한 귀 끝, 동그란 눈동자, 코의 모양, 수염 가닥 같은 부분들이 특징점(keypoint)으로 추출됩니다.
- 자동차 바퀴 이미지에서는 🚗:
- 바퀴살의 직선 부분, 볼트의 육각형 모양, 타이어의 무늬 같은 부분들이 특징점으로 추출됩니다.
이 단계가 끝나면, 우리는 수많은 특징점 '조각'들의 모음을 갖게 됩니다.
2단계: K-Means로 '시각적 단어 사전' 만들기
추출된 모든 특징점 조각들을 K-Means에 입력하여 비슷한 것들끼리 묶어 그룹을 만듭니다. 여기서는 4개의 그룹(K=4)으로 묶어 보겠습니다.
- 그룹 1: 뾰족한 '귀' 모양의 특징점들이 모두 한 그룹으로 묶입니다. 👉 시각적 단어 1: "귀 모양"
- 그룹 2: 동그란 '눈'이나 '코' 모양의 특징점들이 묶입니다. 👉 시각적 단어 2: "동그란 모양"
- 그룹 3: 길고 곧은 '바퀴살' 모양의 특징점들이 묶입니다. 👉 시각적 단어 3: "직선 모양"
- 그룹 4: '볼트' 같은 육각형 모양의 특징점들이 묶입니다. 👉 시각적 단어 4: "육각 모양"
이제 우리는 4개의 단어로 구성된 '시각적 단어 사전'을 갖게 되었습니다. {귀 모양, 동그란 모양, 직선 모양, 육각 모양}
3단계: BoVW로 이미지를 특징 벡터로 변환하기
새로운 이미지가 주어졌을 때, 이 이미지를 단어 사전으로 요약합니다.
예시 1: 새로운 고양이 사진이 입력될 경우
-
새 고양이 사진에서 SURF로 특징점을 찾습니다.
-
찾아낸 각 특징점이 우리 사전에 있는 4개의 단어 중 무엇과 가장 닮았는지 확인하고 빈도수를 셉니다.
- "귀 모양": 18번 나타남
- "동그란 모양": 32번 나타남
- "직선 모양": 2번 나타남 (배경의 노이즈)
- "육각 모양": 1번 나타남 (배경의 노이즈)
-
이 고양이 이미지는 최종적으로 [18, 32, 2, 1] 이라는 1차원 특징 벡터로 변환됩니다.
예시 2: 새로운 자동차 바퀴 사진이 입력될 경우
같은 과정을 거치면 [1, 3, 25, 20] 과 같은 벡터가 나올 것입니다.
4단계: 분류하기
분류기(SVM 등)는 [18, 32, 2, 1]처럼 첫 두 숫자가 큰 벡터는 '고양이'라고 학습하고, [1, 3, 25, 20]처럼 뒤 두 숫자가 큰 벡터는 '자동차 바퀴'라고 학습합니다.
3. Datasets
1. UCF11 데이터셋 (공개 벤치마크)
-
데이터 특징: 기존의 유명한 행동 인식 데이터셋인 UCF11을 DVS 버전으로 변환한 데이터입니다.
-
생성 방식: 원본 비디오를 모니터로 재생하고, 그 화면을 DAViS240C라는 DVS 센서로 다시 촬영하여 만들었습니다.
-
한계 및 의의: 이 방식 때문에 시간 해상도는 원본 비디오(약 30fps) 수준으로 제한되지만, DVS 센서 고유의 노이즈 특성을 담고 있어 실험에 사용하기에 충분합니다.
-
-
클래스 (종류): 농구 슛, 자전거 타기, 다이빙, 골프 스윙 등 총 11개의 행동으로 구성됩니다.
-
성능 검증 방식: 데이터를 25개 그룹으로 나누어, 하나씩 제외하며 테스트하는 LOO(Leave-One-Out) 교차 검증을 사용합니다.

2. DVS 제스처 데이터셋 (자체 제작)
-
데이터 특징: 연구팀이 DVS128 센서를 이용해 직접 촬영하고 제작한 데이터입니다.
-
클래스 (종류): 왼쪽/오른쪽 쓸기, 시계 방향/반대 방향 회전 등 총 10개의 손 제스처로 구성됩니다.
- 12명의 피실험자가 각 제스처를 10번씩 반복하여 총 1200개의 데이터를 확보했습니다.
-
성능 검증 방식: 12명의 피실험자를 기준으로 한 명씩 제외하며 테스트하는 12-겹 교차 검증을 사용합니다.

모션 맵 분석을 통한 핵심 관찰
생성된 모션 맵을 분석한 결과, 각 행동은 모션 맵 위에 고유한 시각적 패턴(지문)을 남기는 것으로 확인되었습니다.
-
x-y 맵: 행동의 평균적인 모양과 자세를 보여줍니다.
-
x-t, y-t 맵: 행동의 시간에 따른 리듬과 동적인 패턴을 보여줍니다.
- (예시) '그네 타기'는 y-t 맵에 강이 굽이치는 듯한 물결 모양을, '트램펄린 점프'는 x-t 맵에 규칙적인 상하 스파이크 모양을 나타냈습니다.
4.Feature Extraction and classification
이 연구는 행동 인식을 위해 기존의 우수한 기술(밀집 궤적)과 자체 제안한 기술(모션 맵) 두 가지를 모두 평가하고 활용합니다.
1. 기존 기술 평가: 밀집 궤적(Dense Trajectories) 기반
기존의 유명한 특징 기술자인 HoG, HOF, MBH의 성능을 평가하기 위한 과정입니다.
1단계: 궤적 추출
- 밀집 궤적: 비디오 화면에 수많은 점을 빽빽하게 찍은 후, 15프레임 동안 각 점들의 이동 경로를 추적하여 수많은 짧은 '움직임 궤적'을 확보합니다.
2단계: 특징 계산
-
볼륨 및 셀 분할: 각 궤적을 중심으로 32x32x15 픽셀 크기의 3D 비디오 덩어리(볼륨)를 설정하고, 이를 다시 2x2x3개의 더 작은 셀(Cell)로 나눕니다.
-
기술자 계산: 12개의 각 셀 내부에서 HoG, HOF, MBH 특징을 각각 계산합니다.
- HoG/MBH: 8방향 정보 사용 → 96차원 특징 (12셀 x 8방향)
- HOF: 9방향 정보 사용 → 108차원 특징 (12셀 x 9방향)
- MBH (수평/수직): 수평(x)과 수직(y) 움직임을 별도로 분석 → 192차원 특징 (96차원 x 2)
3단계: BoF(Bag of Features) 모델링 및 분류
-
특징 샘플링: 비디오당 약 50만 개의 방대한 궤적이 생성되므로, 계산 효율을 위해 각 훈련 비디오에서 무작위로 10만 개의 궤적을 공정하게 샘플링합니다.
-
사전(Codebook) 생성: 샘플링된 특징들을 k-평균 클러스터링하여, 500개의 대표 '시각 단어'로 구성된 사전을 만듭니다.
-
히스토그램 변환: 이 사전을 기준으로 각 비디오를 500차원의 특징 통계(히스토그램)로 변환합니다.
-
분류기 학습: 최종적으로 L2 정규화를 거친 히스토그램 데이터를 SVM 분류기에 학습시킵니다.
2. 제안 기술 평가: 모션 맵(Motion Maps) 기반
논문에서 자체적으로 제안한 모션 맵(x-y, x-t, y-t)에 대해서도 위와 동일한 Bag of Features 방식을 적용합니다.
사전 크기: 동일하게 500차원의 코드북을 사용합니다.
구현: 이 과정은 MATLAB의 내장 함수(bagOfFeatures)를 활용했습니다.
최종 분류 전략
다중 클래스 인식: 11개의 행동을 구별하기 위해 일대다(One-vs-all) 방식의 선형 SVM을 사용합니다.
성능 검증: 모든 기술자들의 성능은 LOO(Leave-One-Out) 교차 검증 방식을 통해 객관적으로 평가되며, 그 결과는 다음 섹션에서 제시됩니다.
5. Experimental Results
-
DVS의 가능성 확인: 논문에서 제안한 모션 맵은 배경 정보가 없는 깔끔한 DVS 데이터에서 더 높은 성능을 보였습니다. 반면, 기존 기술인 HoG/HOF는 모든 정보가 다 있는 원본 비디오에서 더 강한 모습을 보였습니다. 이는 모션 맵이 DVS 데이터에 최적화된 기술임을 증명합니다.
-
최고의 조합 발견: 여러 특징들을 조합해 본 결과, 모션 맵 + MBH를 융합했을 때 가장 높은 행동 인식 성능을 기록했습니다. 이는 두 기술이 서로 다른 관점에서 움직임을 분석하여 부족한 부분을 완벽하게 보완해주기 때문입니다.
-
성능 격차 해소 (핵심 결론): DVS 데이터는 정보량이 훨씬 적음에도 불구하고, 모션 맵 + MBH 융합 방법을 사용하자 기존의 컬러 비디오와 거의 대등한 수준의 성능을 달성했습니다.
-
결론적으로, 이 실험은 DVS 데이터가 정보량의 한계에도 불구하고 올바른 분석 방법만 적용하면 기존 비디오를 대체할 수 있을 만큼 강력한 잠재력을 가졌다는 것을 증명합니다.
Conclusion and Future Work
결론
-
핵심 성과: DVS 데이터에 최적화된 '모션 맵' 기술을 제안했으며, 이를 기존의 강력한 기술인 'MBH'와 융합하여 최고의 성능을 달성했습니다.
-
성능 증명: 정보량이 훨씬 적은 DVS 데이터를 사용했음에도 불구하고, 제안된 방법은 기존의 컬러 비디오(RGB)와 거의 동등한 수준의 행동 인식 성능을 보였습니다.
-
최종 결론: DVS는 색상이나 질감 정보가 없다는 한계가 있지만, 사용 가능한 정보만으로도 충분히 유용합니다. 따라서 저전력, 고속 환경에서는 기존 카메라를 효율적으로 대체할 수 있는 강력한 대안입니다.
향후 연구
-
BoF 모델 개선: 현재의 Bag-of-Features 모델은 특징들의 '위치' 정보를 무시하는 단점이 있습니다. 향후에는 특징 간의 공간적 관계를 고려하는 '공간적 상호상관도(Spatial Correlogram)' 같은 기법을 도입하여 성능을 개선할 수 있습니다.
-
DVS 전용 추적 기술 개발: 현재 사용되는 '밀집 궤적' 기술은 DVS의 노이즈까지 특징으로 잘못 감지하는 문제가 있습니다. 이 문제를 근본적으로 해결하기 위해, 노이즈는 걸러내고 실제 움직임만 정확하게 찾아 추적하는 DVS에 특화된 새로운 추적 기술을 개발해야 합니다. 이것이 DVS 기반 행동 인식 기술을 한 단계 더 발전시키는 핵심 과제입니다.
-
해결책 (DVS 전용 추적 기술): DVS 데이터의 특성을 처음부터 이해하는 새로운 추적 기술이 필요합니다.
- 작동 방식:
1. 먼저 DVS 이벤트 스트림에서 무작위로 흩어져 있는 노이즈 점들은 걸러냅니다.
2. 의미 있는 덩어리를 이루며 함께 움직이는 '진짜 객체'의 이벤트들만 식별합니다.
3. 오직 이렇게 식별된 '진짜' 움직임에 대해서만 궤적을 추적합니다.
- 작동 방식:
-
상세 내용
1. 모션 맵 (Motion Map) 상세 설명
모션 맵은 DVS 센서에서 나오는 불규칙한 (x, y, 시간) 형태의 이벤트 데이터를, 컴퓨터가 분석하기 쉬운 세 장의 의미 있는 2D 이미지로 요약하는 기술입니다. 3차원 시공간에 흩어져 있는 움직임의 점들을 서로 다른 각도에서 눌러 만든 '그림자'라고 생각할 수 있습니다.
① x-y 맵: 움직임의 공간 분포도 (어디서?)
생성 방식: 3D 데이터 덩어리를 시간(t) 축 방향에서 압축합니다.
의미: 비디오 전체 시간 동안 어디에서 움직임이 가장 많이 발생했는지를 보여주는 히트맵(Heatmap)과 같습니다. 객체가 움직인 전체 공간적 궤적과 평균적인 자세를 나타내며, MHI(움직임 이력 이미지)와 유사한 역할을 합니다.
② x-t 맵: 수평 움직임의 타임라인 (수평적으로 어떻게?)
생성 방식: 3D 데이터 덩어리를 세로(y) 축 방향에서 압축합니다.
의미: 가로축은 공간(x), 세로축은 시간(t)인 2D 이미지입니다. 시간이 흐름에 따라 객체의 수평(좌우) 위치가 어떻게 변했는지를 보여줍니다. 예를 들어, 왼쪽에서 오른쪽으로 일정한 속도로 움직였다면 이 맵에는 대각선 패턴이 나타납니다.
③ y-t 맵: 수직 움직임의 타임라인 (수직적으로 어떻게?)
생성 방식: 3D 데이터 덩어리를 가로(x) 축 방향에서 압축합니다.
의미: 가로축은 공간(y), 세로축은 시간(t)인 2D 이미지입니다. 시간이 흐름에 따라 객체의 수직(상하) 위치가 어떻게 변했는지를 보여줍니다. 예를 들어, 위아래로 손을 흔드는 동작은 이 맵에 물결(sine wave) 모양의 패턴을 만듭니다.
결론적으로, 이 세 장의 모션 맵은 하나의 복잡한 시공간 움직임을 '공간적 분포', '수평적 리듬', '수직적 리듬'이라는 세 가지 단순하지만 핵심적인 관점으로 분해하여, 컴퓨터가 행동의 패턴을 쉽게 학습하도록 돕습니다.
