thesis
1.thesis study

AlexNet → ResNet 순서로 논문 읽기CNN의 구조(합성곱, 활성화 함수, 풀링 등) 익히기ResNet이 왜 좋은지 이해하기 (Skip Connection 개념)최신 연구 따라가기ResNet과 ViT 비교하면서 읽기ViT의 Self-Attention 개념 익히
2.Attention/Transformer
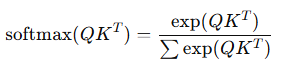
Attention은 입력 데이터 중에서 가장 중요한 정보를 선택적으로 집중하여 학습하는 메커니즘입니다.기존 RNN, CNN과 다르게 모든 입력을 동시에 고려하며, 유의미한 관계를 학습할 수 있습니다.입력 데이터(텐서)는 가중치 행렬 W 를 통과하면서 변환됩니다.변환이
3.Contextual Transformer Networks for Visual Recognition_1
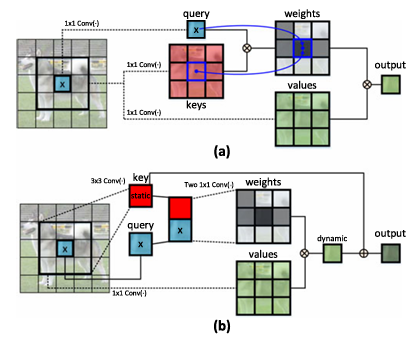
Transformer와 자체-어텐션(self-attention) 기법은 자연어 처리(NLP) 분야에서 혁신적인 발전을 이뤄냈으며, 최근에는 컴퓨터 비전(CV)에서도 Transformer 스타일의 아키텍처가 등장하여 경쟁력 있는 성능을 보이고 있습니다.하지만 대부분의 기
4.Contextual Transformer Networks for Visual Recognition_2

✅ 초기 모델들은 층을 깊게 쌓는 방식으로 성능을 향상AlexNet (8층) → VGG (16층) → GoogleNet (22층) → ResNet (152층)✅ 이후, ConvNet 아키텍처의 성능을 강화하기 위해 다양한 혁신적인 기법들 등장 Transformer의 자
5.Contextual Transformer Networks for Visual Recognition_3
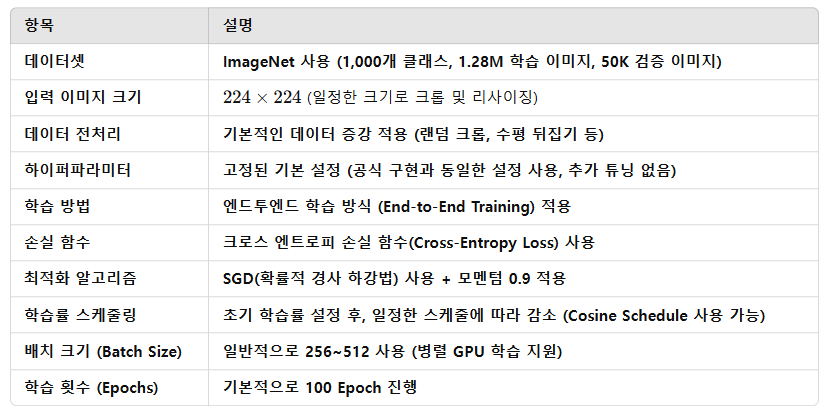
📌 ImageNet에서 CoTNet 이미지 인식 실험 정리✅ 데이터셋: ImageNet1,000개 클래스(Class)128만 개 학습 이미지 (Training Images)50,000개 검증 이미지 (Validation Images)✅ 평가 방식: Top-1 & To
6.Dynamic Vision Sensors for Human Activity Recognition

abstract DVS란? 일반 카메라와 달리, 영상 전체를 촬영하는 것이 아니라 움직임이 있는 부분만을 감지하여 데이터를 기록하는 저전력, 고효율 카메라입니다. 연구 방법 연구팀은 DVS가 포착한 움직임 데이터로 '모션 맵(Motion Map)'이라는 특징을 만들고
7.Large language models can be zero-shot anomaly detectors for time series?
이 논문은 "SIGLLM"이라는 새로운 프레임워크를 통해 대규모 언어 모델(LLM)을 시계열 데이터의 이상 징후를 별도의 학습 없이(zero-shot) detection 하는 연구를 제시합니다. 연구진은 시계열 데이터를 텍스트로 변환하여 LLM이 처리할 수 있도록 하는
8.LogLLM: Log-based Anomaly Detection Using Large Language Models
최근 대규모 언어 모델(LLM)을 활용한 방법들이 등장했지만, 이들 역시 다음과 같은 문제점을 가집니다:프롬프트 엔지니어링 기반 방법: LLM의 내장된 지식에만 의존하여 특정 데이터셋에서는 성능이 떨어집니다.미세 조정 기반 방법: LLM을 특정 데이터에 맞게 조정하지만
9.Learning from Noise: Enhancing DNNs for Event-Based Vision through Controlled Noise Injection
이벤트 카메라는 뉴로모픽 카메라라고도 불리며, 높은 시간 해상도, 낮은 지연 시간, 에너지 효율성 덕분에 기존 프레임 기반 카메라의 강력한 대안으로 주목받고 있습니다. 이 카메라는 각 픽셀의 밝기 변화를 독립적으로 감지하는 독특한 방식으로 작동하여 , 로봇 공학, 자율