딥러닝
머신러닝 vs 딥러닝
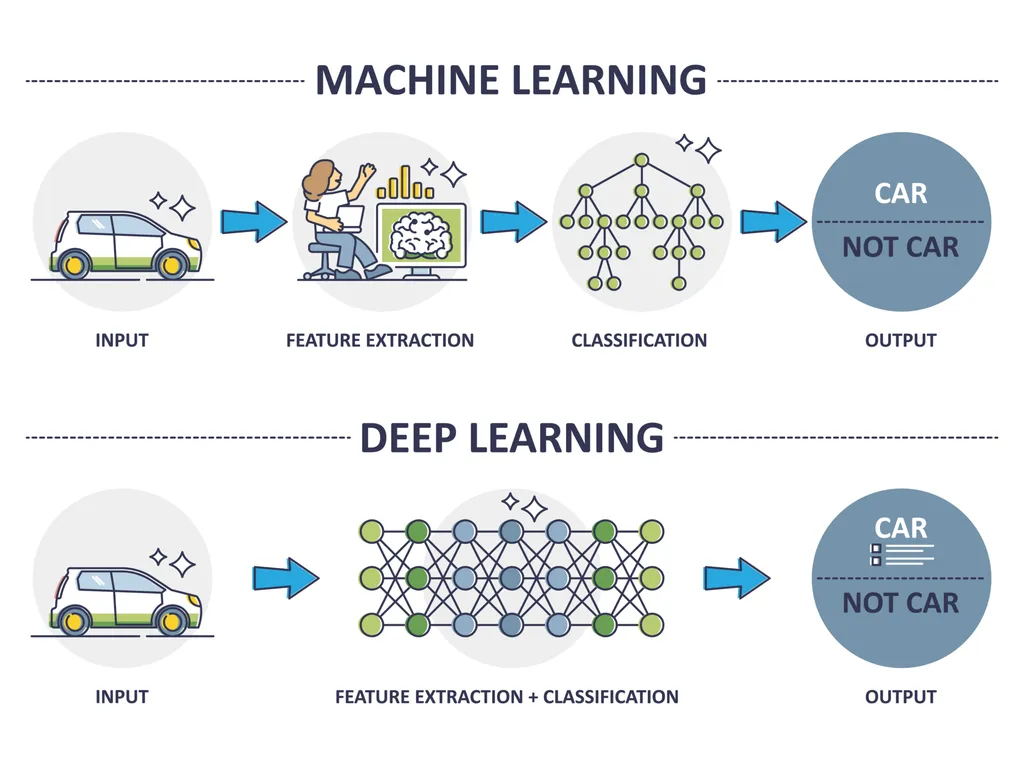
- 공통점
- 데이터로부터 가중치를 학습하여 패턴을 인식하고 결정을 내리는 알고리즘.
- 인공지능의 하위 분야
- 차이점
- 머신러닝: 데이터 안의 통계적 관계를 찾아내며 예측이나 분류를 하는 방법.
- 딥러닝: 머신러닝의 한 분야로 신경세포 구조를 모방한 인공 신경망 활용.
딥러닝의 유래
- 인공신경망 Artificial Neural Networks: 인간의 신경세포를 모방하여 만든 네트워크
- 신경세포: 이전 신경세포로 들어오는 자극을 이후 신경세포에게 전기신호로서 전달하는 기능을 하는 세포
- 퍼셉트론 Perceptron: 인공신경망의 가장 작은 단위
- 키-몸무게 데이터에 대한 퍼셉트론:

가중치
Gradient Descent를 통해 가중치를 구한다
- 회귀문제는 Mean Squared Error(MSE)를 최소화하고자 한다.
- 가중치 weight를 이리저리 움직이면서 최소의 MSE를 도출하는 가중치를 찾아야 한다.
- 이때 우리가 최소화하려는 값을 목적함수 혹은 손실함수라고 함.
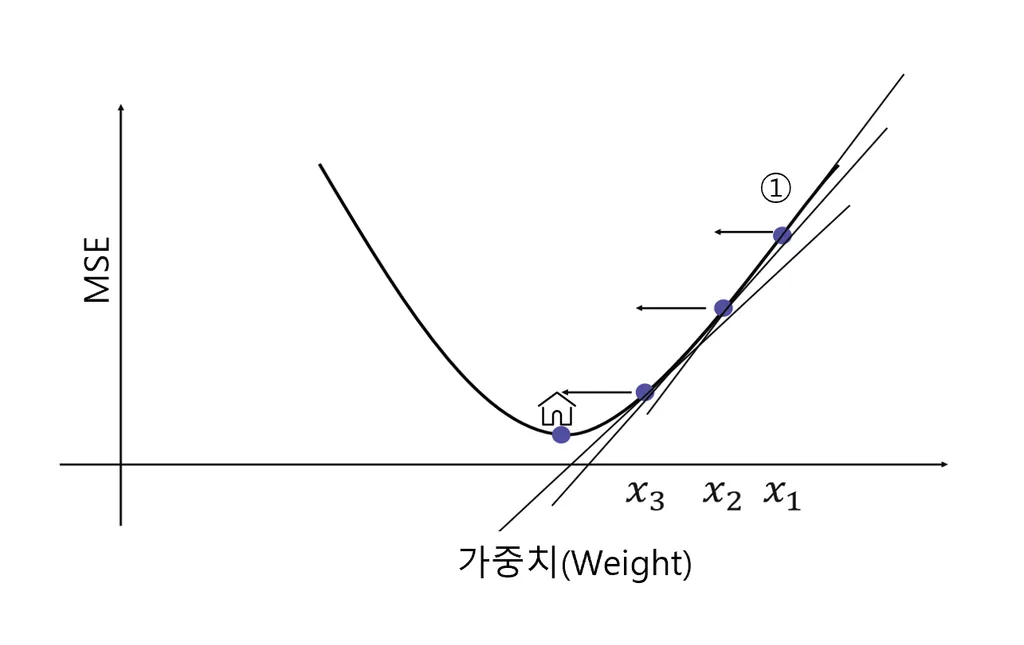
경사하강법 Gradient Descent
모델의 손실 함수를 최소솨하기 위해 모델의 가중치를 반복적으로 조정하는 최적화 알고리즘.
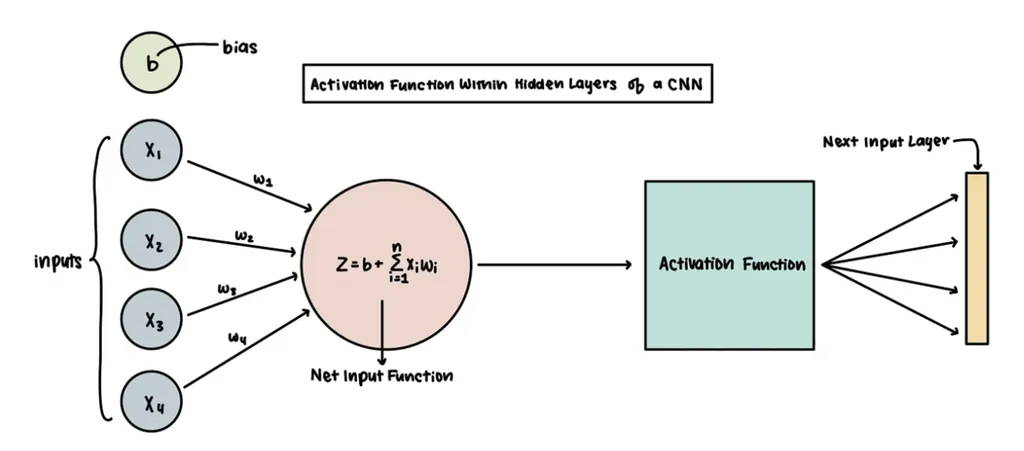
활성화 함수 Activation function
노드의 개별 입력과 가중치를 기반으로 노드의 출력을 계산하는 함수
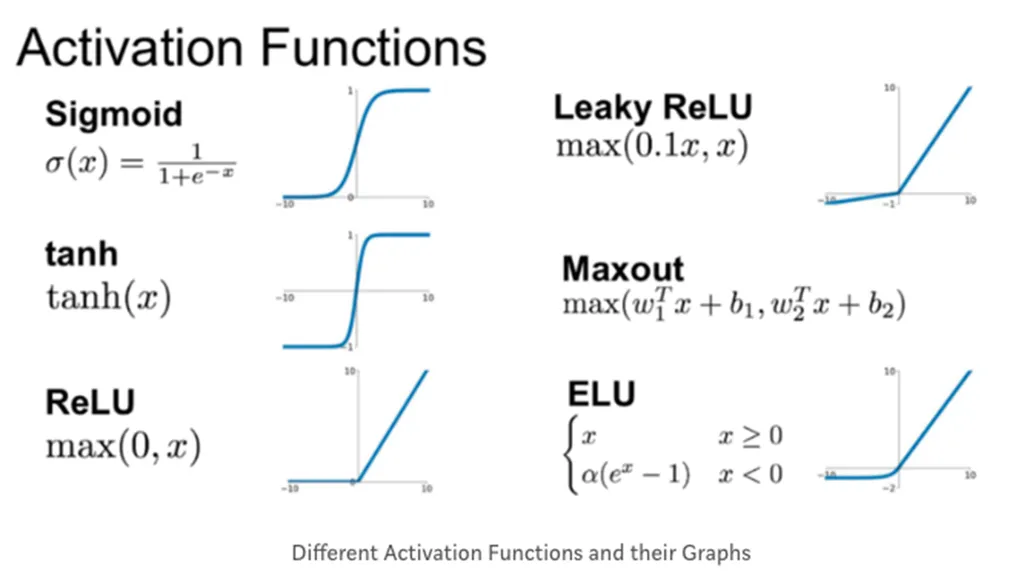
- 로지스틱 함수 외에도 다양한 활성화 함수 존재
히든 레이어 hidden layer
데이터를 비선형적으로 변환함과 동시에 데이터의 고차원적인 특징을 학습하기 위헤 입력층과 출력층 사이에 추가하는 레이어
- 인공 신경망의 학습
- 순전파 Propagation: 입력 데이터 신경망의 각 층을 통화하면서 최종 출력까지 생성되는 과정
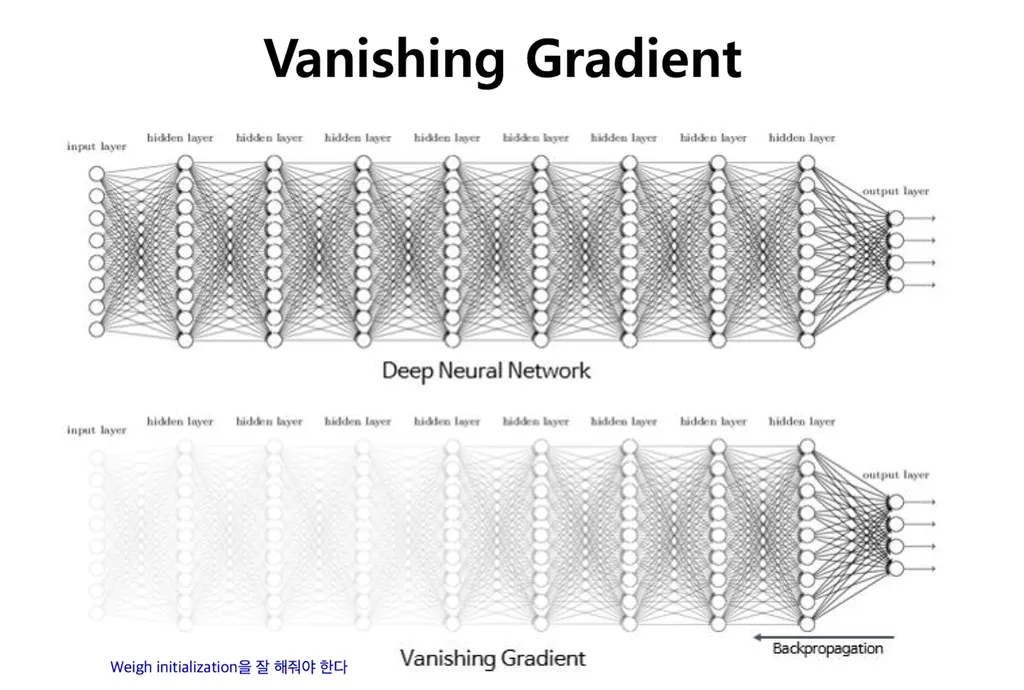
- 역전파 Backpropagation: 오류를 역방향으로 전파하여 각 층의 가중치를 조절하는 과정
- 이 과정에서 오차의 기울기가 점점 작아져 가중치가 거의 업데이터 되지 않는 기울기 소실 문제 등장
- ReLU 등의 특정 활성화함수를 통해 완화!
- Input Layer: 주어진 데이터가 벡터(Vector)의 형태로 입력됨
- Hidden Layer: Input Layer와 Output Layer를 매개하는 레이어로 이를 통해 비선형 문제를 해결할 수 있게 됨
- Output Layer: 최종적으로 도착하게 되는 Layer
- Activation function(활성화 함수): 인공신경망의 비선형성을 추가하며 기울기 소실 문제 해결함
Epoch 📌
전체 데이터가 신경망을 통과하는 한 번의 사이클
1000 epoch = 전체 데이터를 1000번 학습
batch
- 전체 훈련 데이터셋을 일정한 크기의 소그룹(batch)으로 나눈 것
iteration
- 전체 훈련 데이터셋을 여러 개의 소그룹(batch)으로 나누었을 때, 각 batch가 학습되는 횟수
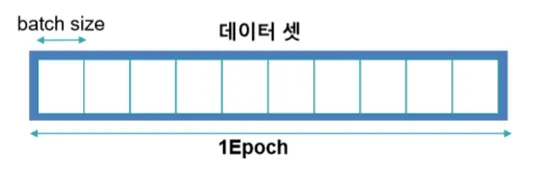
ex) 1000개의 데이터, batch size = 100이라면, 1 epoch = 10 iteration. 가중치 업데이트가 10번 일어남.
실습
Tensorflow 패키지
tensorflow.keras.model.Sequential
model.add: 모델에 대한 새로운 층을 추가함
unitmodel.compile: 모델 구조를 컴파일하며 학습 과정을 설정
optimizer: 최적화 방법, Gradient Descent 종류 선택loss: 학습 중 손실 함수 설정
- 회귀: mean_squared_error(회귀)
- 분류: categorical_crossentropy
metrics: 평가척도
mse: Mean Squared Erroracc: 정확도f1_score: f1 scoremodel.fit: 모델을 훈련 시키는 과정
epochs: 전체 훈련 데이터 셋에 대해 학습을 반복하는 횟수model.summary(): 모델의 구조를 요약하여 출력tensorflow.keras.model.Dense: 완전 연결된 층
unit: 층에 있는 유닛의 수. 출력에 대한 차원 개수input_shape:1번째 층에만 필요하면 입력데이터의 형태를 지정model.evaluate: 테스트 데이터를 사용하여 평가model.predict: 새로운 데이터에 대해서 예측 수행
단일 레이어 모델
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
from sklearn.preprocessing import StandardScaler
weights = np.array([87,81,82,92,90,61,86,66,69,69])
heights = np.array([187,174,179,192,188,160,179,168,168,174])
# Sequential 모델 초기화
model = Sequential()
# 단일 layer 추가하기
dense_layer = Dense(units= 1, input_shape=[1])
model.add(dense_layser)
model.compile(optimizer='adam', loss = 'mean_squared_error')
model.summary()
model.fit(weights, heights, epochs = 100)
# summary 결과:
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 1) 2
=================================================================
Total params: 2 (8.00 Byte)
Trainable params: 2 (8.00 Byte)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________히든 레이어를 포함한 아키텍쳐
model2 = Sequential()
model2.add(Dense(units=64, activation = 'relu', input_shape = [1]))
model2.add(Dense(units=64, activation = 'relu'))
model2.add(Dense(units= 1))
model2.compile(optimizer='adam', loss = 'mean_squared_error')
model2.summary()
model2.fit(weights, heights, epochs = 100, batch_size= 10)
# summary 결과:
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_7 (Dense) (None, 64) 128
dense_8 (Dense) (None, 64) 4160
=================================================================
Total params: 4288 (16.75 KB)
Trainable params: 4288 (16.75 KB)
Non-trainable params: 0 (0.00 Byte)딥러닝 활용 예시
자연어 처리 Natural Language Processing
- 인간의 언어를 데이터화하여 처리하는 것
ex) 단어의 빈도 수 기반 데이터 Bag of Words

-
Transformer 기반 모델 개발
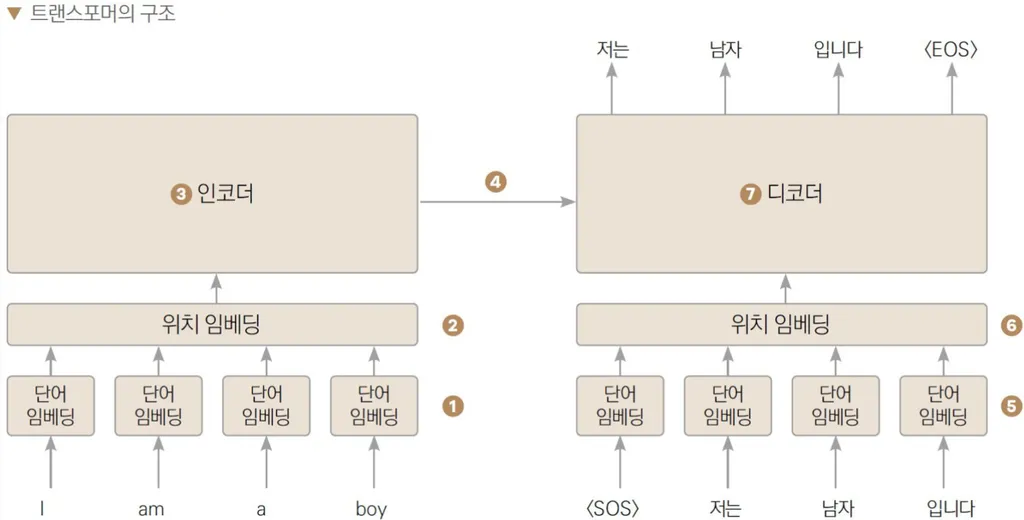
-
Large Language Model, LLM
이미지 처리
-
이미지도 RGB 숫자로 표현 가능. 3차원 (R, G, B) 데이터를 모델에 학습 시킴
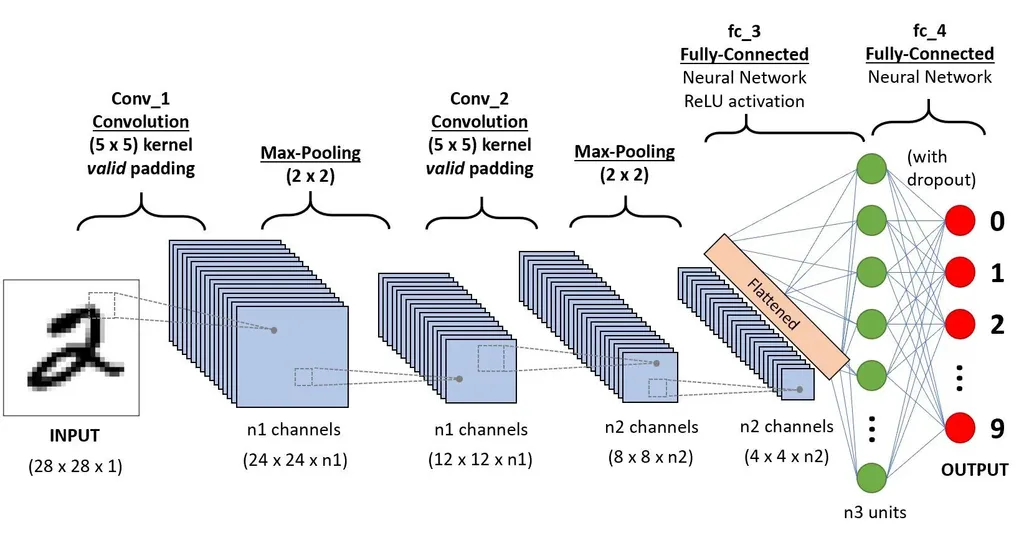
-
CNN 연산의 예시

최신 이미지 생성 모델
단순히 이미지를 입력 받는 것을 넘어서 텍스트, 이미지, 음성 등 다양한 유형의 데이터를 함께 사용하는 Mutimodal. 특히 Stable Diffusion은 접근성도 매우 뛰어남.


To Dare is To Do