여러 개의 컬럼 동시에 가져오기
df[['A', 'B']]
df.loc[:,['B', 'C']]
불리언 인덱싱
데이터 불러오기
import seaborn as sns
data = sns.load_dataset('tips')
df = pd.DataFrame(data)조건에 맞는 값 찾기
- 조건이 참이 경우만 가져옴
df[df['sex'] == 'Male']
여러 조건 적용하기
- AND 조건: df[(조건1) & (조건2)]
df[(df['sex'] == 'Male') & (df['smoker'] == 'Yes')]
: 흡연자인 남성 조회
- OR 조건: df[(조건1) | (조건2)]
df[(df['sex'] == 'Male') | (df['smoker'] == 'Yes')]
: 흡연자이거나 남성인 사람 조회
loc로 조건 적용하기
df.loc[df['size']>3, :]
: 조건이 맞는 행, 모든 열 조회
df.loc[df['size']>3, 'tip':'smoker']
: 조건이 맞는 행의 tip부터 smoker까지의 열 조회
df.loc[df['size']>3, ['tip','smoker', 'size']]
: 조건이 맞는 행의 특정 열 조회
isin()
df[df['size'].isin([1, 2])]
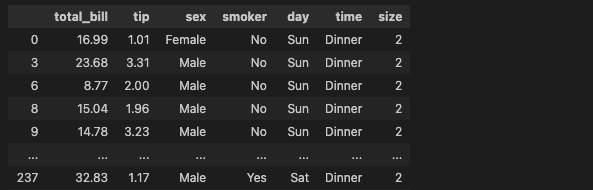
- size가 [1, 2]에 있는 행 조회
df[df['day'].isin(['Sat', 'Sun'])]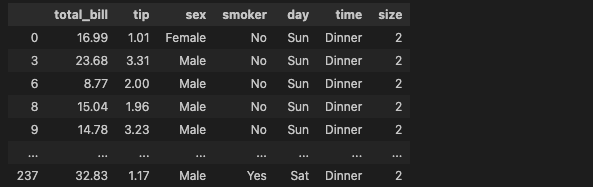
- day가 ['Sat', 'Sun']에 있는 행 조회
조건을 변수에 저장
조건이 하나
condition = df['tip'] < 2
df[condition]조건이 두 개 이상
con1 = df['size'] >= 3
con2 = df['tip'] < 2
df[con1 & con2]
df[con1 | con2]cond = ((df['sex'] == 'Male') & (df['tip'] > 3))
df[cond]⭐️조건을 적용해 찾은 결과값이 pandas series일 때 값만 가져오는 방법
condition1 = (samsung_mean['year'] == 2020) & (samsung_mean['month'] == 3)
samsung_mean.loc[condition1, 'Close']위 코드는 조건을 loc에 적용한 경우이고,
samsung_mean.loc[2, 'Close']위 코드는 같은 loc를 사용했지만 조건이 아닌 행 값을 입력한 경우이다.
둘 다 loc를 이용하였음에도 위 코드의 결과는
14 50168.181818
Name: Close, dtype: float64위처럼 pandas series로 반환이 되고, 아래 코드는 해당 위치의 스칼라값이 반환이 된다. 조건을 적용한 경우에도 아래 경우처럼 스칼라 값만 알고 싶다면
condition1 = (samsung_mean['year'] == 2020) & (samsung_mean['month'] == 3)
samsung_mean.loc[condition1, 'Close'].item()위 코드처럼 .item()을 붙여주면 된다.
데이터 추가하기
df['created_at'] = '2024-01-04'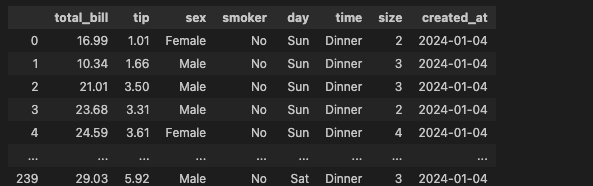
list로 새 컬럼에 여러 값 추가하기
df['KFC'] = [50, 10, 30]날짜 데이터로 바꿔주기
df['created_at'].dtype결과: dtype('O') -> 오브젝트 타입
df['created_at'] = pd.to_datetime(df['created_at'])결과: datetime64[ns]로 변경됨
데이터끼리 연산하기
df['revenue'] = df['total_bill'] + df['tip']
To Dare is To Do