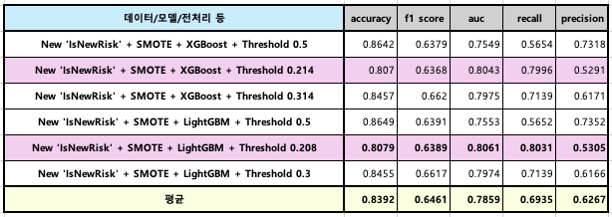
오늘 프로젝트 진행 내용
- 새로운 데이터로 모델 학습 재진행
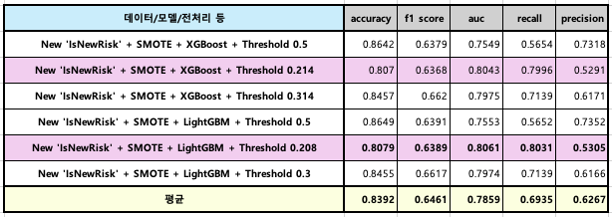
- 모델이 이탈할 것이라고/이탈하지 않을 것이라고 예상한 고객 대상 군집화
1. 이상치 제거
2. 스케일링 (표준화, 정규화)
3. 원핫 인코딩
4. 상관관계 확인을 통해 높은 상관관계를 가지는 컬럼 제거하기
5. PCA를 통한 차원 축소
6. 엘보우 기법을 통해 최적의 k 찾기
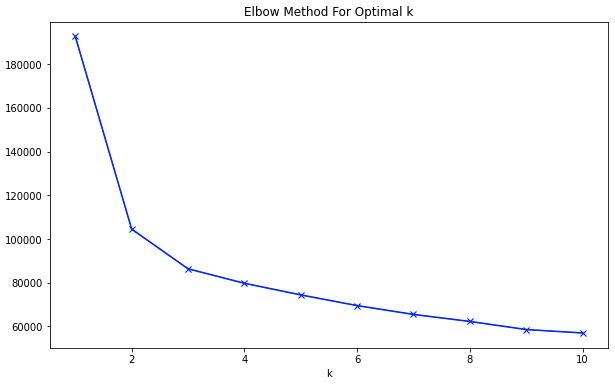
# 최적의 k로 클러스터링
optimal_k = 2 # 엘보우 기법으로 찾은 최적의 k를 설정
kmeans = KMeans(n_clusters=optimal_k, init='k-means++', random_state=42)
clusters = kmeans.fit_predict(pca_features)
# 실루엣 계수로 클러스터링 성능 평가
silhouette_avg = silhouette_score(pca_features, clusters)
print(f'Silhouette Score for {optimal_k} clusters: {silhouette_avg}')
# Silhouette Score for 2 clusters: 0.5283211567128504회고
잘한 점
- 집중해서 프로젝트에서 맡은 바를 수행하였다. LightGBM, XGBoost 돌리기, 군집화 등.
개선점
- 내 코드든 남의 코드든 코드를 쓸 때는 오류가 없는지, 놓친 부분이 없는지, 실수가 없는지 꼼꼼히 잘 살피기!
- 오전 9-10시 조금 더 알차기 보내기
배운 점
- 엘보우 차트는 최적의 k를 찾기 위한 방법일 뿐, 우리가 군집화를 통해 전하고자 하는 바를 먼저 정하는 것이 좋다!
- PCA 신기하다 ...

To Dare is To Do