5. 메모리
1. 메모리 주소
1. 16 진수 (Hexadecimal)
| 10진법 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16진법 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
- 16진수 앞에는 0x를 붙여 헷갈리지 않게 한다 ex. 0xa = 10
2. 10진수를 16진수로 바꾸기
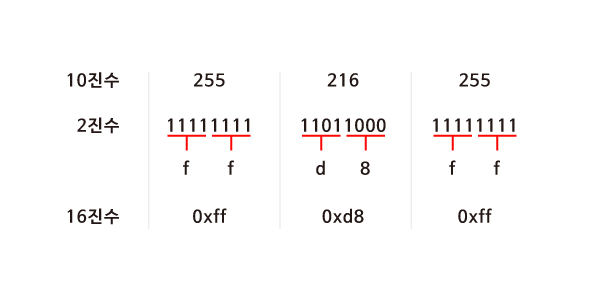 1. 10진수를 2진수로 변환한다
2. 2진수를 4자리씩 묶는다
3. 2진수로 0000에서 1111 = 16진수로 0에서 f
1. 10진수를 2진수로 변환한다
2. 2진수를 4자리씩 묶는다
3. 2진수로 0000에서 1111 = 16진수로 0에서 f
3. 16진수의 유용성
2진수는 너무 긴데 이걸 16진수로 표현하면 훨씬 간편해짐.
또한 8bit = 1byte인데 2자리의 16진수는 8자리(1byte)의 2진수로 변환되기 때문에 정보를 표현하기 쉽다. => 2자리의 16진수로 1byte의 정보를 간단히 표현 가능
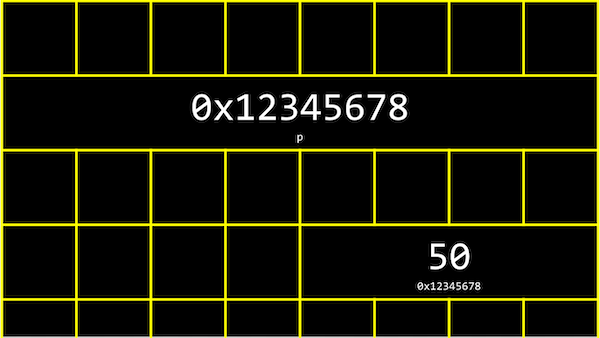
4. 메모리 주소
int n = 50은 메모리 어딘가에 4바이트(int 자료형의 크기)만큼의 자리를 차지하며 저장된다.

C에서는 변수의 메모리상 주소를 받기 위해 &라는 연산자를 사용한다.
#include <stdio.h>
int main(void)
{
int n = 50;
printf("%p\n", &n); //주석 참고
}- 주석
1. %p: 포인터(메모리 주소)를 의미하는 형식지정자
2. &: "~의 주소"를 의미하는 연산자 (Get the address)
3. 위 코드를 실행하면 0x7ffe00b3adbc와 같은 값을 얻을 수 있는데 이는 16진법으로 표현된 변수 n의 메모리주소임
*을 사용하면 그 메모리 주소에 있는 실제 값을 얻을 수 있다
(*: Go to the address)
#include <stdio.h>
int main(void)
{
int n = 50;
printf("%i\n", *&n);
}위 코드는 먼저 n의 주소를 얻고(&n), 또 다시 그 주소에 해당하는 값을 얻어(*&n) 출력한 것이다. 결국 코드를 돌리면 결과값은 50이 나온다.
5. 생각해보기
:bulb: CS50을 16진수로 표현하기
ASCII로 CS50을 표현하면 67, 83, 50
이걸 16진수로 바꾸면 0x43, 0x53, 0x32
2. 포인터
1. 포인터 변수 선언하기
1. 연산자 *의 역할
- 메모리 주소에 접근해서 거기에 저장된 값을 받아오게 함
- 포인터 역할을 하는 변수 선언
2. 포인터 변수 선언하기
#include <stdio.h>
int main(void)
{
int n = 50;
int *p = &n; // 주석 1, 2 참고
printf("3. 변수 n이 저장된 곳의 주소(포인터 p의 값)는 %p\n", p);
printf("4. 포인터 p가 가리키는 주소에 있는 값(n의 값)은 %i\n", *p); // 주석 3 참고
}- 주석
1. p: 포인터 변수 'p'를 선언함. 만약 어떤 변수에 주소를 저장하고 싶으면 그 변수의 자료형뿐만 아니라 변수 앞에 `연산자까지 써줘야 한다. 2. &n: 변수 n이 저장된 곳의 주소. n의 값이 정수이기 때문에 포인터가 가리키는 값이 정수가 되어 *p 앞에 int가 붙는다. 즉, p의 자료형은 포인터지만, p가 가리키는 변수 n의 자료형이 int이기 때문에 int *p라고 쓴다. 3. 포인터 p에 저장된 주소에 접근해 거기에 저장된 값을 읽기 위해 p 앞에 연산자*`를 써야 한다. 그리고 n은 정수형 자료이기 때문에 형식 지정자 %i를 쓴다.
2. 메모리에서 포인터는 어떻게 저장될까?
실제 컴퓨터 메모리에서 변수 p는 아래와 같이 저장된다
cf. 최신 컴퓨터에서 포인터 변수의 크기는 64bits(8bytes)로, long과 똑같은 크기임
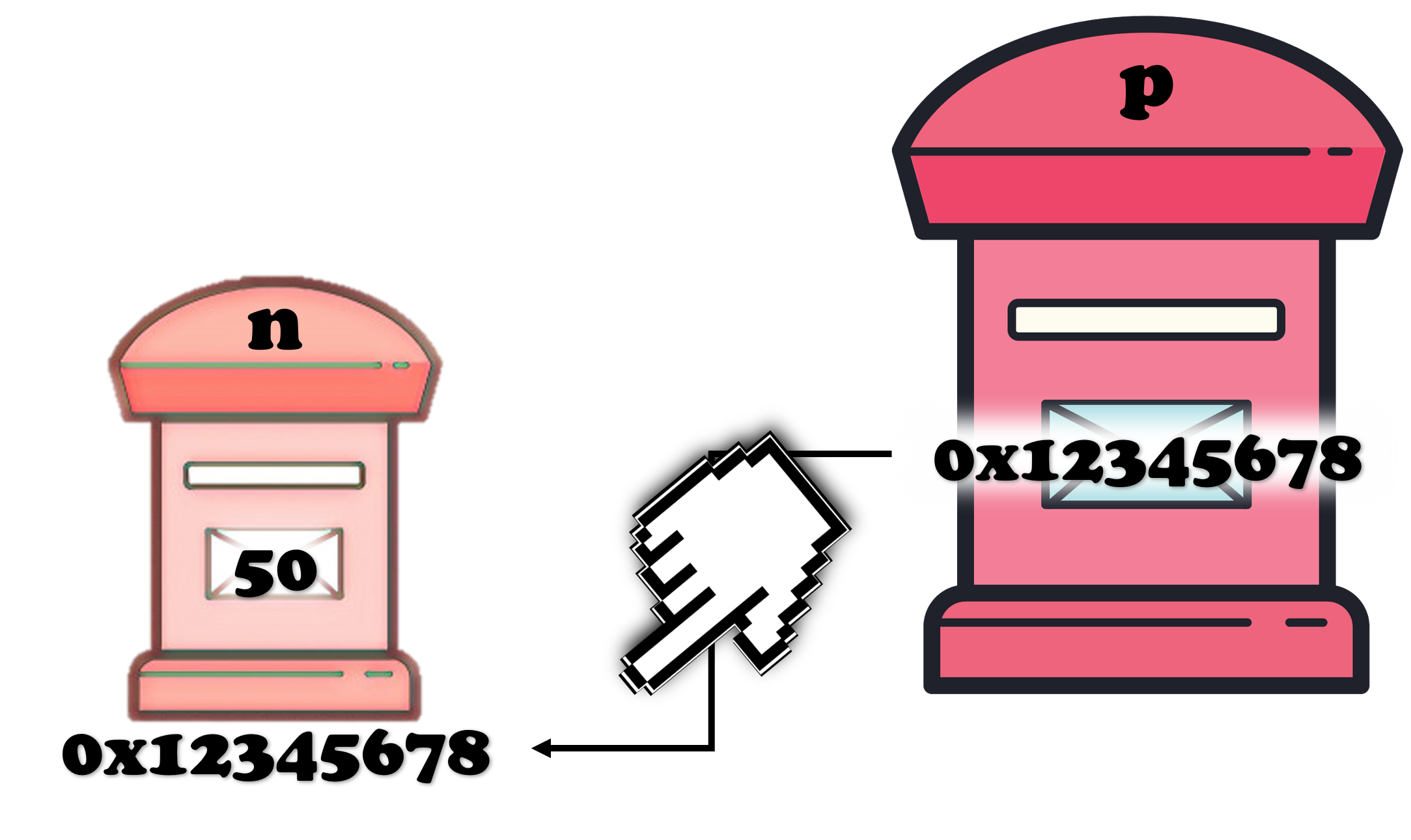
p의 개념은 대충 위와 같다. 하지만 실전에서는 p의 값, 즉 n의 주소는 별로 중요하지 않고 p가 n을 가리키고 있다는 개념 자체가 중요하게 사용된다.
이런 포인터를 기반으로 아주 정교한 데이터 구조(트리, 배열 등)들을 만들 수 있다.
3. 생각해보기
:bulb: 포인터의 크기는 메모리의 크기와 어떤 관계가 있을까요?
포인터 변수의 크기는 메모리의 크기와 비례관계에 있다.
참고: 포인터의 개념
3. 문자열
1. string s = char *s = "EMMA"
앞에서 #include <cs50.h>를 사용해야 입력할 수 있던 자료형 string은 결국 char *과 같은 의미이다.
문자열 EMMA는 결국 문자 E, M, M, A, \0의 배열이고, s[0], s[1], ...와 같이 하나의 문자가 배열의 한 부분을 나타낸다.

cf. \0: 널 종단문자. 8개의 비트(=1byte)가 모두 0으로 이루어져 있다. 00000000. 문자열의 끝을 표시한다.
결국 변수 s는 이러한 문자열을 가리키는 포인터가 되는데, 정확히 말하면 문자열 "EMMA" 에서 첫 번째 문자인 'E'(s[0])의 주소를 저장한다.
2. 코드
#include <stdio.h>
#include <cs50.h>
int main(void)
{
char *s = "EMMA"; // string s = "EMMA"와 동일한 코드임.
printf("%s\n", s);
printf("%p\n", s); // EMMA가 저장된 주소 출력
printf("%p\n", &s[0]); // s: pointer, s[0]: char, &s[0]: address of 'E' => 프로그램 돌려보면 s == &s[0] 인 것을 알게 될 것이다.
}위 프로그램을 돌려보면 결과는 다음과 같이 나온다
$ ./address2
EMMA
0x55c411ef5004
0x55c411ef50043. 생각해보기
:bulb: string 자료형을 정의해서 사용하면 어떤 장점이 있을까요?
포인터 개념을 모르는 사람도 직관적으로 문자열을 사용해 코드를 짤 수 있다.
4. 문자열 비교
1. 문자열 EMMA의 각 문자 출력해보기
char *s = "EMMA";로 선언된 변수 s의 자료형은 포인터로, 문자열 EMMA의 첫 글자인 E의 주소를 저장하고 있다. 그렇다면 s[0], s[1]와 같은 구문설탕(syntactic sugar)을 사용하지 않고 EMMA의 각 문자를 출력해보자
#include <stdio.h>
int main(void)
{
char *s = "EMMA"
printf("%p\n", *s); //주석 1 참고
printf("%p\n", *(s+1)); //주석 2 참고
printf("%p\n", *(s+2));
printf("%p\n", *(s+3));
printf("%s\n", s); //주석 3 참고
}- 주석
1. s에 저장된 주소로 가서(*s) 거기에 저장된 것을 프린트함 : E출력
2. s+1에 접근해서 거기에 저장된 것을 프린트함: M출력 (s = 0x1234 5라고 치면 s+1 = 0x12345 6이다. 서로 붙어있는 문자의 주소는 1씩 차이난다.)
3. 이 경우 문자열 전체(EMMA)를 출력하는데, s는 첫 번째 글자인 E의 주소만 저장하고 있음에도 불구하고 printf가 문자열 전체를 출력하는 이유 = printf의 형식지정자 %s 때문임. %s는 첫 문자만 출력하지 않고 해당 문자열의 전체 문자(널 종단문자를 만나기 전까지의 문자)를 출력하도록 함.
2. If (s == t)의 조건을 이용해 문자열 비교해보기
이런 프로그램을 돌리면 어떤 결과가 나올까?
#include <stdio.h>
#include <cs50.h>
int main(void)
{
char *s = get_string("s: ");
char *t = get_string("t: ");
if (s == t)
{
printf("Same\n");
}
else
{
printf("Different\n");
}
}이 프로그램을 실행시켜 s에 EMMA를 저장하고, t에 EMMA를 저장해도 결과는 Different라고 나온다. 그 이유를 그림으로 간략히 설명해보면 다음과 같다.
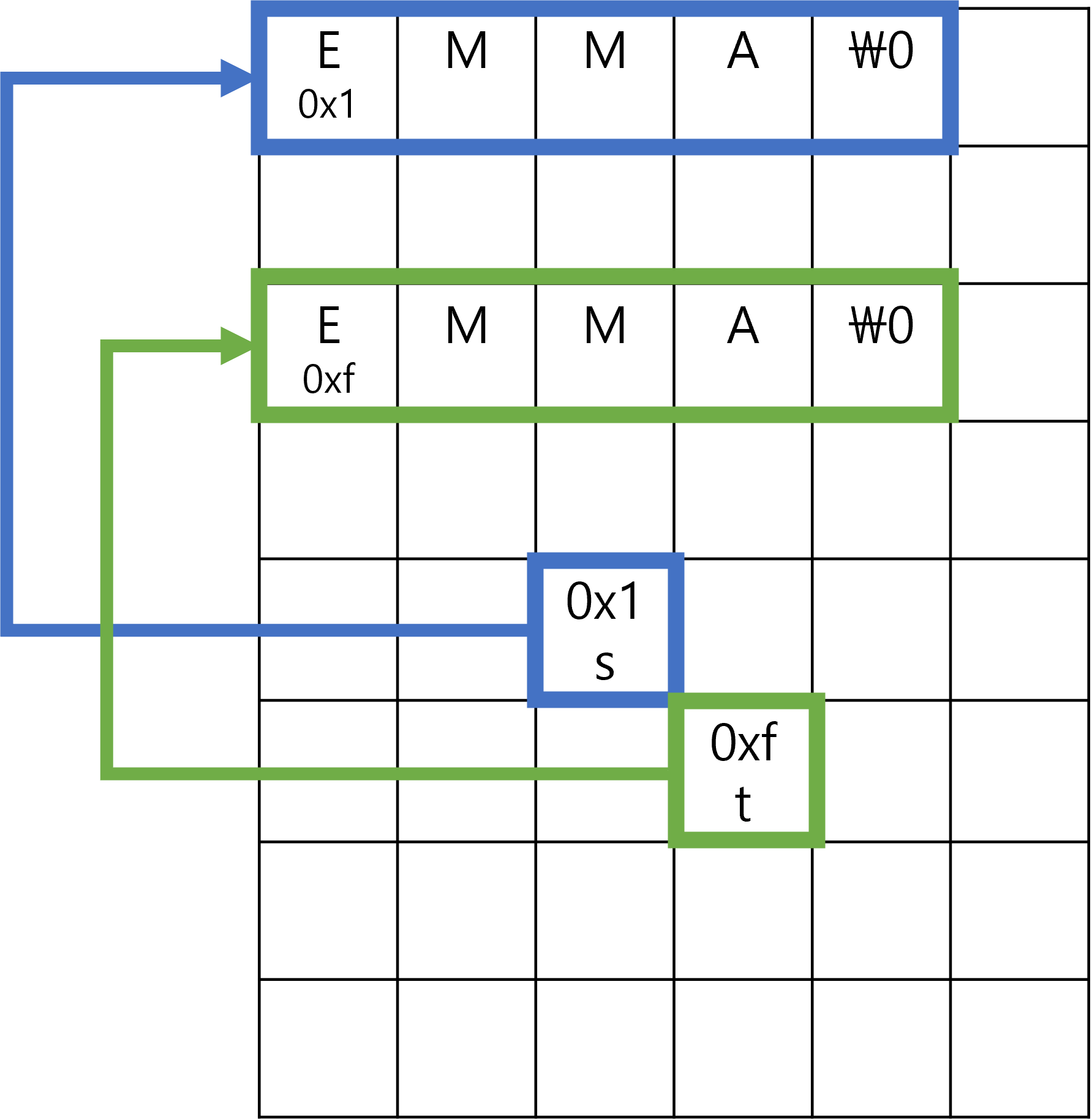
이렇듯 s와 t는 포인터고, 내용물 자체가 다르기 때문에 컴퓨터는 당연히 s와 t가 다르다고 판단한다.
3. 생각해보기
:bulb: 문자열을 비교하는 코드는 어떻게 작성해야 할까요?
#include <stdio.h>
#include <cs50.h>
// 함수 프로토타입
void compare(char *str1, char *str2);
// 본문
int main(void)
{
char *s = get_string("s: ");
char *t = get_string("t: ");
compare(s, t);
}
// 함수 정의
void compare(char *str1, char *str2)
{
for (int i = 0; *(str1+i)!='\0' || *(str2+i)!='\0';i++)
{
if (*(str1+i)-*(str2+i)==0) //같은 문자는 아스키코드도 같음
{
continue;
}
else
{
printf("Different\n");
return;
}
}
printf("Same\n");
}cf. for문의 괄호() 안에서 정의된 변수는 for문이 끝나면 사라진다
for문 전에 선언되어서 for문 안에서 조작된(ex. i++) 변수는 for문 밖에 나와서는 조작된 형태 그대로 남아있다.
ex. int i=0 -> for문 안에서 i++로 인해 i=5로 조작됨 -> for문 빠져나가도 i=5임.
5. 문자열 복사
📌핵심 단어: malloc
1. 문자열 복사하기 1 (망한 예시)
#include <stdio.h>
#include <cs50.h>
#include <ctype.h>
int main(void)
{
char *s = get_string("s: ");
char *t = s
t[0] = toupper(t[0]);
printf("%s\n", s);
printf("%s\n", t); 이 코드를 돌렸을 때 결과는 다음과 같이, s는 emma로, t는 Emma로 출력될거라고 예상한 것과 다르게 s와 t 모두 "Emma"라고 출력된다.
$ s: emma
$ Emma
$ Emma그 이유는 s라는 변수에는 “emma”라는 문자열이 아닌 그 문자열이 있는 메모리의 주소가 저장되기 때문이다.
string s 는 char *s 와 동일한 의미라는걸 떠올려보면 된다.
따라서 t도 s와 동일한 주소를 가리키고 있고, t를 통한 수정은 s에도 그대로 반영이 되게 되는 것이다.
그렇다면 두 문자열을 실제로 메모리상에서 복사하려면 어떻게 해야 할까?
아래 코드와 같이 메모리 할당 함수를 사용하면 된다.
2. 문자열 복사하기 (성공 버전)
#include <stdio.h>
#include <cs50.h>
#include <ctype.h>
#include <string.h>
int main(void)
{
char *s = get_string("s: ");
char *t = malloc(strlen(a)+1); //주석 1
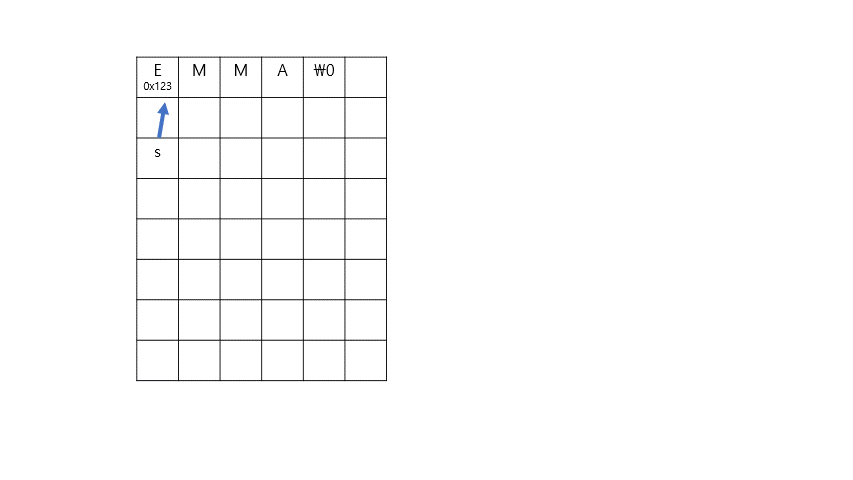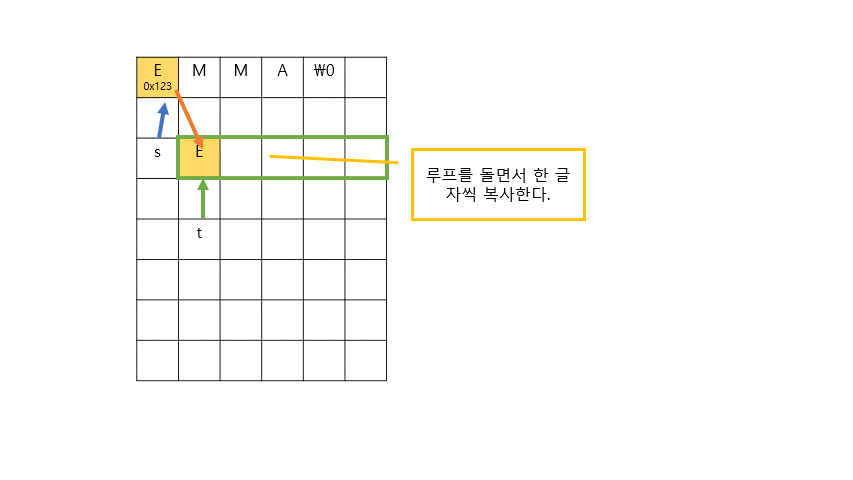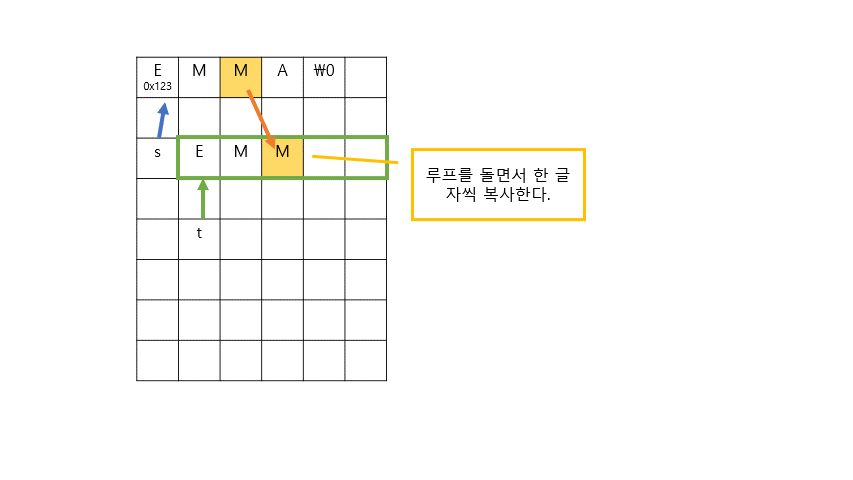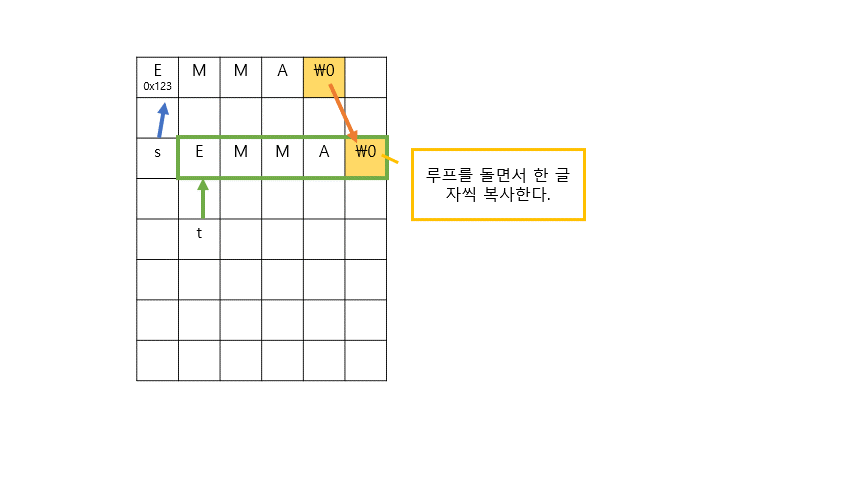
for (int i = 0, n = strlen(s); i < n+1; i++) //주석 2,3
{
t[i] = s[i];
}
t[0] = toupper(t[0]);
printf("%s\n", s);
printf("%s\n", t);
}이제 프로그램에 emma를 입력하고 프로그램을 돌리면 s는 emma로, t는 Emma로 출력된다.
- 주석
1. malloc(할당할 메모리 크기): memory allocation(메모리 할당) 함수. 정해진 크기 만큼 메모리를 할당한다. 위의 경우 s 문자열의 길이에 널 종단 문자(\0)에 해당하는 1을 더한 만큼 메모리를 할당한다.
2.for (int i = 0; i < strlen(s)+1; i++)이라고 쓰면 비효율적이다. 조건문에 함수를 쓰게 되면 루프를 돌 때마다 함수를 호출하고 조건을 검사하게 되어 시간이 오래 걸리기 때문이다. 이때n = strlen(s)라고 함수의 값을 변수로 저장하게 되면 조건검사시 함수를 호출할 필요가 없어 더 빨라진다.
3. 조건식에서 i < n+1인 경우: \0의 자리까지 고려해야 하기 때문이다.
위의 과정을 이미지로 표현하면 다음과 같다.
3. 더 간략한 코드
#include <stdio.h>
#include <cs50.h>
#include <ctype.h>
#include <string.h>
int main(void)
{
char *s = get_string("s: ");
char *t = malloc(strlen(a)+1);
strcpy(t, s); //for문 대신 strcpy 사용
t[0] = toupper(t[0]);
printf("%s\n", s);
printf("%s\n", t);
} 위에서 쓴 복잡한 for문 대신 strcpy(t, s)를 사용한다. 그러면 s의 문자열이 t에 복붙된다. 이 함수는 string.h 헤더파일에 저장되어있다.
4. 생각해보기
:bulb: 배운 바와 같이 메모리 할당을 통해 문자열을 복사하지 않고, 단순히 문자열의 주소만 복사했을 때는 어떤 문제가 생길까요?
사본의 문자열을 수정하는 것으로 착각하지만 사실은 원본의 문자열을 수정하게되는 참사가 일어난다.
6. 메모리 할당과 해제
:pushpin: 핵심 단어: valgrind, free
1. malloc과 free
malloc을 사용해 5byte의 메모리를 할당한 아래 코드를 보자
#include <stdio.h>
#include <cs50.h>
#include <ctype.h>
#include <string.h>
#include <stdlib.h> //malloc이 들어있음
int main(void)
{
char *s = get_string("s: ");
char *t = malloc(strlen(s)+1);
for (int i = 0, n = strlen(s); i < n+1; i++)
{
t[i] = s[i];
}
t[0] = toupper(t[0]);
printf("%s\n", s);
printf("%s\n", t);
}malloc은 할당한 메모리의 첫 바이트의 주소(포인터)를 반환하는 함수이다.
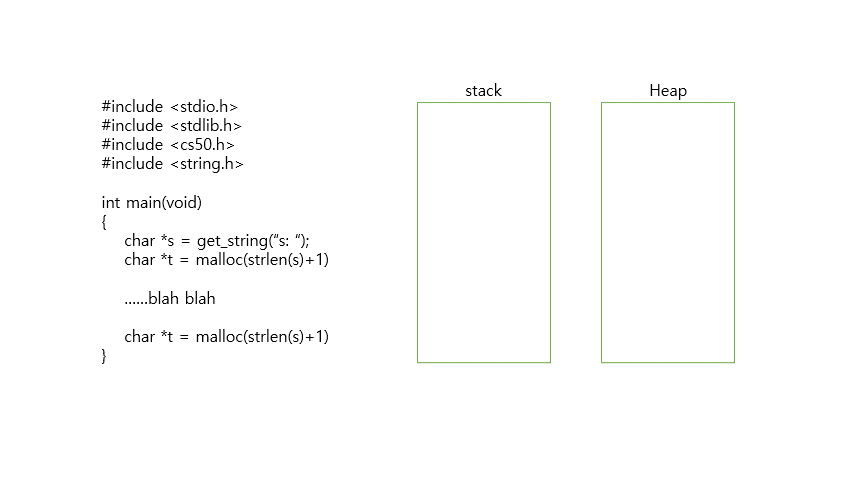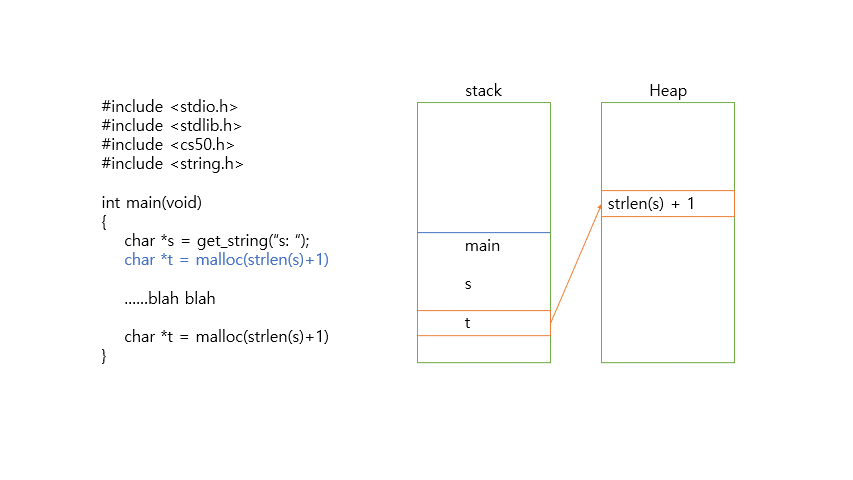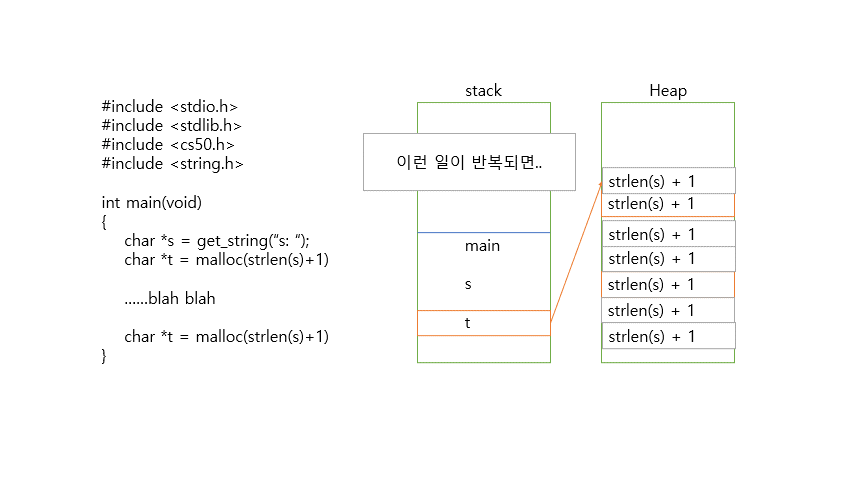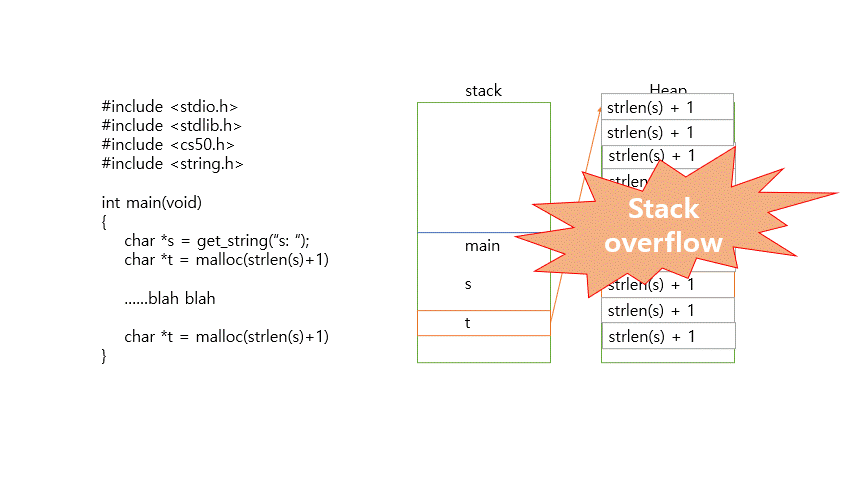
malloc 함수를 이용해 메모리를 할당한 뒤에는 free라는 함수를 이용해 메모리를 해제해줘야 한다. 그렇지 않으면 메모리에 저장한 값은 쓰레기 값으로 남게 되어 메모리 용량의 낭비(메모리 누수)가 발생하기 때문이다.
동적 메모리 할당에 대한 비디오 참고
2. valgrind를 이용해 오류찾기
valgrind라는 프로그램을 사용하면 우리가 작성한 코드에서 메모리와 관련된 문제가 있는지 확인할 수 있다. 터미널 창에
valgrind ./filename을 치면 다음과 같은 결과가 나온다.
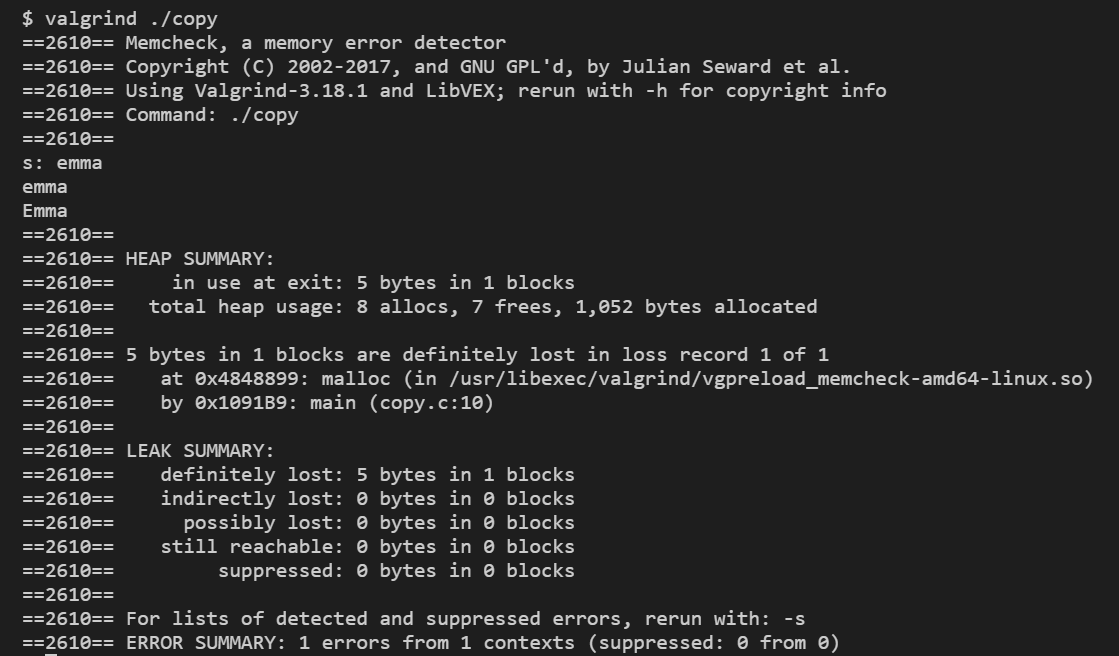
여기에서 핵심적인 내용은
5bytes in 1 blocks are definitely lost in loss record 1 of 1이다. 즉, malloc으로 할당된 5바이트가 free를 통해 해제되지 않아서 메모리 누수가 생기고 있다는 뜻이다. 이제 코드의 마지막째 줄에 (더 이상 malloc으로 할당된 메모리가 필요없을 때) free(t)를 써서 메모리 할당을 없앤 후 valgrind를 통해 검사하면 다음과 같이 오류가 없다고 나온다.
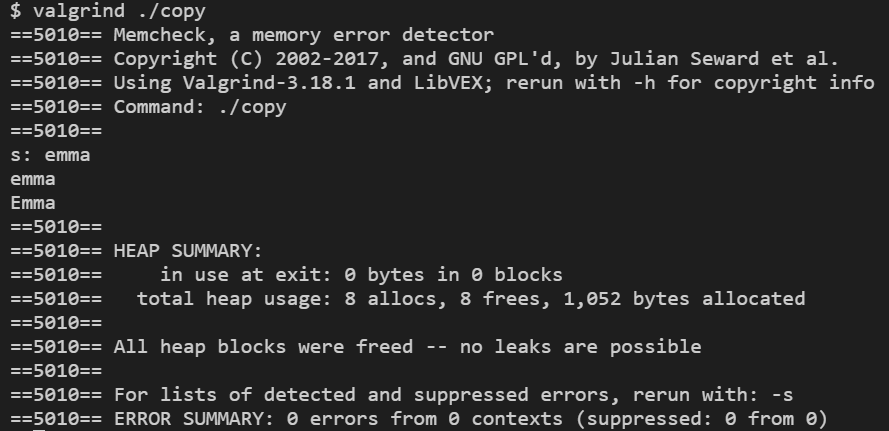
All heap blocks were freed -- no leaks are possible3. 버퍼 오버플로우와 메모리 누수
다음 코드를 보자
#include <stdlib.h>
void f(void)
{
int *x = malloc(10 * sizeof(int));
x[10] = 0;
}
int main(void)
{
f();
return 0;
}valgrind를 써서 위 코드를 검사해보면
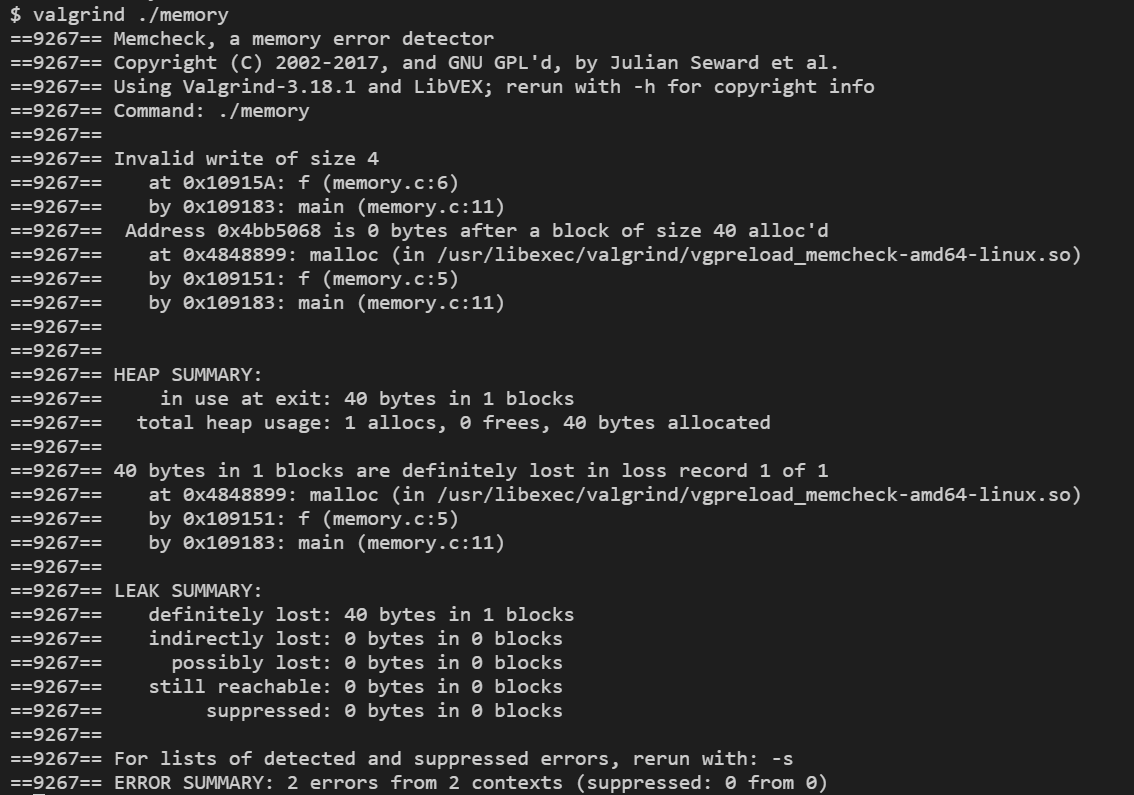
위와 같이 길게 에러를 설명하는 내용이 뜬다. 여기서 주목해야 할 것은
1. Invalid write of size 4
2. 40 bytes in 1 blocks are definitely lost in loss record 1 of 1두 내용인데 이는 각각 다음과 같은 뜻이다.
1. 코드에서는 정수 10개만을 위한 메모리를 할당했는데, x[10]을 통해 11번째 자리에 0을 할당하려고 했기 때문에 버퍼 오버플로우 발생
2. malloc을 통해 메모리를 할당한 후 free로 할당을 해제하지 않았기 때문에 메모리 누수 발생
위 오류들은 x[9]=0으로 고치고 void f(void)코드의 마지막 줄에 free(x)를 쓰면 해결된다.
4. 생각해보기
:bulb: 제한된 메모리를 가지고 프로그래밍을 할 때 메모리를 해제하지 않으면 어떤 문제가 발생할 수 있을까요?
해제하지 않은 메모리가 쌓여서 결국 스택오버플로우가 발생한다.
7. 메모리 교환, 스택, 힙
:pushpin: 핵심 단어: 스택, 힙, 포인터
1. 입력된 두 정수를 바꾸는 함수 swap을 작성해보자
#include <stdio.h>
void swap(int a, int b);
int main(void)
{
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(x,y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int a, int b)
{
int tmp = a;
a = b;
b = tmp;
}프로그램을 실행하면 에러는 안뜨지만 x와 y의 값이 바뀌지 않는다는 것을 알 수 있다. 왜 그럴까?
그 이유는 함수 swap에서 a와 b는 각각 x와 y의 값을 복제해서 가지기 때문에, 함수 실행시 a와 b의 값이 바뀌지, x와 y의 값이 바뀌는 것이 아니기 때문이다.
아래 영상을 보자

2. 메모리의 구조
위의 영상에서 메모리의 이미지가 나오는데 위에서부터 Machine code, Global, Heap, Stack이라고 써져 있다. 하나씩 알아보자
1. Machine code (코드 영역)
메모리의 맨 위쪽에는 clang과 같은 컴파일러가 코드를 컴파일한 후 나온 0과 1의 값들이 저장된다.
2. Globals (데이터 영역)
머신코드 아래에는 프로그램이 실행되는 내내 적용되는 전역 변수(global variables)들이 저장된다
3. Heap (힙 영역)
malloc과 같은 동적 할당 함수를 통해 사용자가 할당받을 수 있는 메모리 영역이다. 정보가 위에서 아래로 저장된다. 이 영역은 컴퓨터가 자동으로 관리해주지 않기 때문에 메모리의 할당/해제를 사용자가 직접 관리해줘야 한다. 잘못 관리하면 메모리 누수, 스택오버플로우와 같은 문제들이 생긴다.
4. Stack (스택 영역)
함수를 호출했을 때 함수에서 사용하는 지역변수(local variables)들을 저장하는 공간이다. 함수가 종료되면 stack에 저장된 변수들도 자동적으로 지워진다.
스택오버플로우란?
그림에서 보이듯이 스택과 힙은 같은 공간에서 서로 다른 방향으로 관리되는데, 만약 저장되는 데이터를 잘 관리하지 못해서 힙 영역과 스택 영역이 만나는 경우 스택오버플로우가 발생한다.
3. 포인터를 이용해 swap을 작성해보자
#include <stdio.h>
void swap(int *a, int *b);
int main(void)
{
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(&x, &y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
} 이 코드를 돌리면 x와 y의 값이 정상적으로 바뀌는 것을 확인할 수 있다.
작동 원리는 다음과 같다

a와 b를 각각 x와 y를 가리키는 포인터로 지정함으로서 문제를 해결한 것이다.
4. 생각해보기
:bulb: 메모리 영역을 다양하게 나누는 이유는 무엇일까요?
각 메모리에 저장되는 데이터의 종류가 다른데(코드, 전역변수, 지역변수, 사용자가 필요할 때마다 동적으로 할당하는 메모리), 이 데이터들이 저장되고 지워지는 시기는 저마다 다르다. 한 영역에서 이 모든 데이터를 관리하려면 곤란한 일이 생기므로(ex. 지워야 할 데이터가 지우면 안되는 데이터 밑에 깔려있다던지..) 메모리를 여러 영역으로 나눠서 데이터를 따로 관리하는 것이 편하다.
메모리 구조를 알아보자
8. 파일 쓰기
:pushpin: 핵심 단어: scanf, fopen, fprintf, fclose
1. 메모리 구조
- 머신코드 영역: 프로그램이 실행될 때 그 프로그램이 컴파일된 바이너리가 저장됨
- 글로벌 영역: 프로그램 안에서 저장된 전역 변수가 저장됨
- 힙 영역: malloc으로 동적 할당된 메모리의 데이터가 저장된다.
- 스택 영역: 프로그램 내 함수와 관련된 것들이 저장됨.

힙 영역에서는 malloc에 의해 메모리가 더 할당될수록 점점 사용하는 메모리의 범위가 아래로 늘어난다.
스탱 영역에서는 함수가 더 많이 호출될수록(재귀함수 등) 사용하는 메모리의 범위가 점점 위로 늘어난다.
이렇게 늘어나다가 제한된 메모리 용량 하에서 힙과 스택이 서로의 영역을 침범하는 상황이 발생할 때도 있는데, 이를 힙 오버플로우, 스택 오버플로우라고 하며, 이 둘을 뭉뚱그려서 버퍼 오버플로우라고 한다.
2. scanf: 컴퓨터에 정보를 입력해보자
1. char *s;
#include <stdio.h>
int main(void)
{
char *s = NULL; //string s와 동일.
printf("s: ");
scanf("%s", s); // 주석 참고
printf("s: %s\n", s);
}이 상태로 사용하면 "variable s is uninitialized when used here"이라는 에러가 뜸. 즉 문자열 변수 s를 만들고 싶다면 변수 s를 주소로 초기화해야 함
- 주석: scanf("형식지정자", &변수 이름) 을 쓰는게 정석이나 s는 이미 포인터(주소)이므로 굳이 &를 쓸 필요가 없음. 그리고 앞에서 만든 swap과 마찬가지로 앞서 정의한 변수들로 뭐를 하려는 함수들은 포인터를 써서 이 변수들을 관리해야 함. 그 이유는 swap()만들기에서 이미 배웠다..
2. char *s = NULL;
#include <stdio.h>
int main(void)
{
char *s = NULL;
printf("s: ");
scanf("%s", s);
printf("s: %s\n", s);
}char *s = NULL -> NULL은 특별한 포인터로, 가리키는 곳이 없다는 뜻임.
이 코드를 돌리면 s: (null)이라는 글자가 출력된다. 여기서 null은 입력받은 문자열이 저장될 메모리 공간이 할당되지 않았다는 뜻이다.
3. char *s[5];
#include <stdio.h>
int main(void)
{
char s[5]; //사용자가 EMMA를 입력한다고 가정하고 \0(널 문자)까지 고려해 크기 5의 문자 배열을 선언
printf("s: ");
scanf("%s", s); //s의 주소를 scanf에 전달해서 사용자의 입력을 받음
printf("s: %s\n", s);
}여태까지 배운 내용을 보면 배열과 포인터는 사실 연관되어 있다
배열은 메모리가 연속적으로 할당된 공간이다.
문자열은 문자가 연속적으로 있는 것이다. 문자열은 사실 그 메모리 공간 첫 번째 바이트의 주소를 의미한다.
따라서 추이적 관계에 의해 최소한 이 문맥에서 포인터는 배열과 같다고 볼 수 있다.
clang 컴파일러는 문자 배열의 이름을 포인터처럼 다룬다. 따라서 scanf에서 &를 붙이지 않고 s를 쓰는 것이다 scanf("%s", s)
위의 코드를 실행해서 s에 EMMA를 입력하면 정상적으로 프로그램이 돌아가지만 Emma Humphrey를 적으면 프로그램이 동작하지 않는다.(프로그램이 멈추거나 세그멘테이션 오류 발생) 그 이유는 문자열 s의 길이를 5로 제한해뒀기 때문이다 (사실 널 문자를 빼면 입력할 수 있는 문제는 딱 4글자임)
4. 주의: scanf는 에러체크를 하지 못함
scanf는 에러 확인을 하지 못한다. 즉, scanf("%i", &a)로 정수형을 입력받아야하는데, 사용자가 문자를 입력했다면 에러가 나고 프로그램이 멈춘다. 따라서 scanf를 사용할 때는 사용자가 제대로 된 정보를 입력했는지 에러를 확인하는 과정을 거쳐야 한다.
2. 파일에 정보 저장하기
#include <stdio.h>
#include <cs50.h>
#include <string.h>
int main(void)
{
FIlE *file = fopen("phonebook2.csv", "a"); //fopen() 참고
char *name = get_string("Name: ");
char *number = get_string("Number: ");
fprintf(file, "%s,%s\n", name, number); //fprintf() 참고
fclose(file); //fclose() 참고
}1. fopen("파일명.csv", "작업 종류")
FIlE *file = fopen("phonebook2.csv", "a");
1. FILE이라는 새로운 자료형을 가리키는 포인터변수 file을 만들었다.
2. fopen은 첫번째 인자로 열고 싶은 파일 이름, 두 번째 인자로 r(read), w(write), a(append)를 받는다.
3. 우리의 목표는 전화번호부 프로그램을 만들어 사용자로부터 이름과 번호를 입력받아 텍스트 파일에 덧붙이는 것이다.
4. fopen은 해당 파일을 가리키는 포인터를 반환한다.
5. csv: 쉼표로 분리된 값(comma separated variable)으로, 간단한 엑셀이나 Numbers같은 프로그램으로 열 수 있는 파일 형식이다.
2. fprintf(파일명, "입력하는 문자열")
파일용 printf로 파일에 출력할 수 있다.
3. fclose(파일명)
파일을 닫는다.
4. 프로그램 실행 결과
이 프로그램을 실행한 후 정보를 입력하고 터미널창에 ls를 입력해보면 phonebook2.csv라는 파일이 새로 생긴 것을 볼 수 있다. 이걸 vscode에서 열어본 후 phonebook2.c를 실행해서 정보를 입력하면 실시간으로 정보가 업데이트되는 것을 볼 수 있다. 이 파일을 다운로드할 수도 있다.
3. 생각해보기
:bulb: get_long, get_float, get_char도 비슷한 방식으로 직접 구현할 수 있을까요?
scanf("형식지정자", &변수명)에서 형식지정자만 바꿔주면 된다.
long: %ld
float: %f
char: %c
9. 파일 읽기
:pushpin: 핵심 단어: JPEG, fread
:pushpin: 학습 전 복습해야 할 내용: 3단원 8. 명령행 인자
1. JPEG파일인지 검사하는 프로그램
// 파일이름: jpeg.c
include <stdio.h>
int main(int argc, char *argv[])
{
//Ensure user ran program with two words
if (argc != 2)
{
return 1;
}
// Open file
FILE *file = fopen(argv[1], "r");
if (file == NULL)
{
return 1;
}
// Read 3 bytes(24bits) from file
unsigned char bytes[3];
fread(bytes, 3, 1, file);
// Check if bytes are 0xff 0xd8 0xff
if (bytes[0] == 0xff && bytes[1] == 0xd8 && bytes[2] == 0xff)
{
printf("Maybe its JPEG file\n"); //JPEG파일이기 위한 조건이 더 있는 것 같음(..?)
}
else
{
printf("No");
}
}1. Ensure user ran program with two words
에러체크: 사용자가 프로그램의 이름(./jpeg) 말고 파일명도 입력하길 바람
2. Open file
FILE *file = fopen(argv[1], "r");- 기대하는 사용자입력:
./jpeg 파일경로/cat.jpg-> 파일명(파일경로/cat.jpg)은 두번째 인자이므로 argv[1]이다. - 파일을 읽을 것이므로 함수의 두번째 인자는 "r"이라고 쓴다.
- 기대하는 사용자입력:
if (file == NULL): 에러체크. fopen, malloc, get_string과 같은 함수는 에러가 생기면 NULL이라는 값을 돌려줌. 여기서 문제가 생기면 1을 반환하고 프로그램 종료
3. Read 3 bytes(24bits) from file
-
unsigned char bytes[3];unsigned char: -128부터 128이 아닌 0부터 255 범위의 값 (원리 설명은 없었음. 코드 동작을 위해 일단 이렇게 쓴다고 했음)
-
fread(bytes, 3, 1, file);: 함수 인자로 배열, 읽을 바이트 수, 읽을 횟수, 읽을 파일 입력
4. Check if bytes are 0xff 0xd8 0xff
- JPEG 형식에 관한 설명 문서를 보면 모든 JPEG 파일의 첫 세 바이트는 무조건 ff, d8, ff로 시작한다. 이와 같은 규칙을 이용해 파일이 JPEG인지 알 수 있다.
- JPEG파일이기 위한 조건 (magic number)
- Common segment: FF D8
- 이 뒤에 2개 더 붙음
- 포토샵 등 편집 프로그램으로 생성/수정 된 파일: FF D8 FF E0
- 핸드폰 카메라, DSLR 등 카메라로 찍은 파일: FF D8 FF E1
- 결론: 앞 세자리 FF D8 FF는 항상 동일하다. - Trailer: FF D9
- FF D8 ~ FF D9 사이에 얼마나 많은 값이 있느냐에 따라 파일의 용량이 정해진다.
- JPEG의 파일구조
- Common segment: FF D8
2. 생각해보기
:bulb: JPEG 외에 다른 파일 형식도 그 형식임을 알려주는 약속이 있을까요?
매직넘버(Magic number)
: 파일 형식을 식별하기 위해 파일 맨 앞에 붙이는 특정 값이다. 물론 16진수로 표현된다. 위키피디아에 검색해보면 파일 확장자별로 매직넘버를 잘 정리해놓았으니 참고.
