Lecture 7
- Welcome!
- Flat-File Database
- Relational Databases
- IMDb
JOINs- Indexes
- Using SQL in Python
- Race Conditions
- SQL Injection Attacks
- Summing Up
Welcome!
- In previous weeks, we introduced you to Python, a high-level programming language that utilized the same building blocks we learned in C.
- This week, we will be continuing more syntax related to Python.
- Further, we will be integrating this knowledge with data.
- Finally, we will be discussing SQL or Structured Query Language.
- Overall, one of the goals of this course is to learn to program generally – not simply how to program in the languages described in this course.
Flat-File Database
-
As you have likely seen before, data can often be described in patterns of columns and tables.
-
Spreadsheets like those created in Microsoft Excel and Google Sheets can be outputted to a
csvor comma-separated values file. -
If you look at a
csvfile, you’ll notice that the file is flat in that all of our data is stored in a single table represented by a text file. We call this form of data a flat-file database. -
Python comes with native support for
csvfiles. -
In your terminal window, type
code favorites.pyand write code as follows:# Prints all favorites in CSV using csv.reader import csv # Open CSV file with open("favorites.csv", "r") as file: # Create reader reader = csv.reader(file) # Skip header row next(reader) # Iterate over CSV file, printing each favorite for row in reader: print(row[1])Notice that the
csvlibrary is imported. Further, we created areaderthat will hold the result ofcsv.reader(file). Thecsv.readerfunction reads each row from the file, and in our code we store the results inreader.print(row[1]), therefore, will print the language from thefavorites.csvfile. -
You can improve your code as follows:
# Stores favorite in a variable import csv # Open CSV file with open("favorites.csv", "r") as file: # Create reader reader = csv.reader(file) # Skip header row next(reader) # Iterate over CSV file, printing each favorite for row in reader: favorite = row[1] print(favorite)Notice that
favoriteis stored and then printed. Also notice that we use thenextfunction to skip to the next line of our reader. -
Python also allows you to index by the keys of a list. Modify your code as follows:
# Prints all favorites in CSV using csv.DictReader import csv # Open CSV file with open("favorites.csv", "r") as file: # Create DictReader reader = csv.DictReader(file) # csv.DictReader()은 딕셔너리를 반환한다. # Iterate over CSV file, printing each favorite for row in reader: print(row["language"]) # reader가 딕셔너리이므로 키를 인덱스로 사용할 수 있다.Notice that this example directly utilizes the
languagekey in the print statement. -
To count the number of favorite languages expressed in the
csvfile, we can do the following:# Counts favorites using variables import csv # Open CSV file with open("favorites.csv", "r") as file: # Create DictReader reader = csv.DictReader(file) # Counts scratch, c, python = 0, 0, 0 # 한꺼번에 변수 정의 가능 # Iterate over CSV file, counting favorites for row in reader: favorite = row["language"] if favorite == "Scratch": scratch += 1 elif favorite == "C": c += 1 elif favorite == "Python": python += 1 # Print counts print(f"Scratch: {scratch}") print(f"C: {c}") print(f"Python: {python}")Notice that each language is counted using
ifstatements. -
Python allows us to use a dictionary to count the
countsof each language. Consider the following improvement upon our code:# Counts favorites using dictionary import csv # Open CSV file with open("favorites.csv", "r") as file: # Create DictReader reader = csv.DictReader(file) # Counts counts = {} # 딕셔너리 변수 counts 정의 # Iterate over CSV file, counting favorites for row in reader: favorite = row["language"] if favorite in counts: counts[favorite] += 1 else: counts[favorite] = 1 # Print counts for favorite in counts: print(f"{favorite}: {counts[favorite]}")Notice that the value in
countswith the keyfavoriteis incremented when it exists already. If it does not exist, we definecounts[favorite]and set it to 1. Further, the formatted string has been improved to present thecounts[favorite]. -
Python also allows sorting
counts. Improve your code as follows:# Sorts favorites by key import csv # Open CSV file with open("favorites.csv", "r") as file: # Create DictReader reader = csv.DictReader(file) # Counts counts = {} # Iterate over CSV file, counting favorites for row in reader: favorite = row["language"] if favorite in counts: counts[favorite] += 1 else: counts[favorite] = 1 # Print counts for favorite in sorted(counts): # counts를 sort함 -> 키값을 alphabetical order로 분류함 print(f"{favorite}: {counts[favorite]}")Notice the
sorted(counts)at the bottom of the code. -
If you look at the parameters for the
sortedfunction in the Python documentation, you will find it has many built-in parameters. You can leverage some of these built-in parameters as follows:# Sorts favorites by value import csv # Open CSV file with open("favorites.csv", "r") as file: # Create DictReader reader = csv.DictReader(file) # Counts counts = {} # Iterate over CSV file, counting favorites for row in reader: favorite = row["language"] if favorite in counts: counts[favorite] += 1 else: counts[favorite] = 1 def get_value(language): return counts[language] # Print counts for favorite in sorted(counts, key=get_value, reverse=True): # counts를 각 언어의 집계량을 기준으로 내림차순으로 정렬함. print(f"{favorite}: {counts[favorite]}")Notice that a function called
get_valueis created, and that the function itself is passed in as an argument to thesortedfunction. Thekeyargument allows you to tell Python the method you wish to use to sort items.key인자에는 함수를 입력해야 한다. -
Python has a unique ability that we have not seen to date: It allows for the utilization of anonymous or
lambdafunctions. These functions can be utilized when you want to not bother creating an entirely different function. 즉 람다는 딱 한 번 쓰고 말 함수를 간단히 정의할 때 사용한다. Notice the following modification:# Sorts favorites by value using lambda function import csv # Open CSV file with open("favorites.csv", "r") as file: # Create DictReader reader = csv.DictReader(file) # Counts counts = {} # Iterate over CSV file, counting favorites for row in reader: favorite = row["language"] if favorite in counts: counts[favorite] += 1 else: counts[favorite] = 1 # Print counts for favorite in sorted(counts, key=lambda language: counts[language], reverse=True): # key에 인자로 람다함수 입력 print(f"{favorite}: {counts[favorite]}")Notice that the
get_valuefunction has been removed. Instead,lambda language: counts[language]does in one line what our previous two-line function did. -> 람다 문법:lambda variable: expression -
We can change the column we are examining, focusing on our favorite problem instead:
# Favorite problem instead of favorite language import csv # Open CSV file with open("favorites.csv", "r") as file: # Create DictReader reader = csv.DictReader(file) # Counts counts = {} # Iterate over CSV file, counting favorites for row in reader: favorite = row["problem"] if favorite in counts: counts[favorite] += 1 else: counts[favorite] = 1 # Print counts for favorite in sorted(counts, key=lambda problem: counts[problem], reverse=True): print(f"{favorite}: {counts[favorite]}")Notice that
problemreplacedlanguage. -
What if we wanted to allow users to provide input directly in the terminal? We can modify our code, leveraging our previous knowledge about user input:
# Favorite problem instead of favorite language import csv # Open CSV file with open("favorites.csv", "r") as file: # Create DictReader reader = csv.DictReader(file) # Counts counts = {} # Iterate over CSV file, counting favorites for row in reader: favorite = row["problem"] if favorite in counts: counts[favorite] += 1 else: counts[favorite] = 1 # Print count favorite = input("Favorite: ") # 사용자가 찾길 원하는 값 입력 if favorite in counts: print(f"{favorite}: {counts[favorite]}")Notice how compact our code is compared to our experience in C.
Relational Databases
-
Google, Twitter, and Meta all use relational databases to store their information at scale.
-
Relational databases store data in rows and columns in structures called tables.
-
SQL allows for four types of commands:
Create Read Update Delete -
These four operations are affectionately called CRUD.
-
더 정확히, SQL은 다음 명령어를 사용한다.
CREAT, INSERT SELECT UPDATE DELETE, DROP : DELETE는 특정 열을 지움, DROP은 표 전체를 지움 -
We can create a SQL database at the terminal by typing
sqlite3 favorites.db. Upon being prompted, we will agree that we want to createfavorites.dbby pressingy. -> 이건 리눅스, 애플에서 통함 -
윈도우에서는
sqlite3.exe favorites.db라고 쳐야한다. -
You will notice a different prompt as we are now inside a program called
sqlite3. -
We can put
sqlite3intocsvmode by typing.mode csv. Then, we can import our data from ourcsvfile by typing.import favorites.csv favorites. It seems that nothing has happened! -
We can type
.schemato see the structure of the database. -
You can read items from a table using the syntax
SELECT columns FROM table. -
For example, you can type
SELECT * FROM favorites;which will iterate every row infavorites. -
You can get a subset of the data using the command
SELECT language FROM favorites;. -
SQL supports many commands to access data, including:
AVG COUNT :데이터 갯수 셈 DISTINCT :선택한 열을 구성하는 데이터의 종류(?) 출력 LOWER MAX MIN UPPER -
For example, you can type
SELECT COUNT(language) FROM favorites;. Further, you can typeSELECT DISTINCT(language) FROM favorites;to get a list of the individual languages within the database. You could even typeSELECT COUNT(DISTINCT(language)) FROM favorites;to get a count of those.# Searches database popularity of a problem import csv from cs50 import SQL # Open database db = SQL("sqlite:///favorites.db") # Prompt user for favorite favorite = input("Favorite: ") # Search for title rows = db.execute("SELECT COUNT(*) FROM favorites WHERE problem LIKE ?", "%" + favorite + "%") # Get first (and only) row row = rows[0] # Print popularity print(row["COUNT(*)"]) -
SQL offers additional commands we can utilize in our queries:
WHERE -- adding a Boolean expression to filter our data LIKE -- filtering responses more loosely ORDER BY -- ordering responses LIMIT -- limiting the number of responses GROUP BY -- grouping responses togetherNotice that we use
--to write a comment in SQL. -
For example, we can execute
SELECT COUNT(*) FROM favorites WHERE language = 'C';. A count is presented. -
Further, we could type
SELECT COUNT(*) FROM favorites WHERE language = 'C' AND problem = 'Mario';. Notice how theANDis utilized to narrow our results. : C와 Mario를 좋아하는 사람들 수 출력 -
Similarly, we could execute
SELECT language, COUNT(*) FROM favorites GROUP BY language;. This would offer a temporary table that would show the language and count.- 위 명령문은
language와COUNT(*) FROM favorites GROUP BY language를 같이 출력하는 명령문이다. 즉, language는 세로축 header가 된다.
- 위 명령문은
-
We could improve this by typing
SELECT language, COUNT(*) FROM favorites GROUP BY language ORDER BY COUNT(*);. This will order the resulting table by thecount. -
SELECT language, COUNT(*) FROM favorites GROUP BY language ORDER BY COUNT(*) DESC;:ORDER BY는 기본적으로 오름차순 정렬이므로 내림차순 정렬을 하고싶다면DESC명령어를 사용한다. -
We can also
INSERTinto a SQL database utilizing the formINSERT INTO table (column...) VALUES(value, ...);. -
We can execute
INSERT INTO favorites (language, problem) VALUES ('SQL', 'Fiftyville');. : (null, 'SQL', 'Fiftyville') -> 이 행이 표에 추가된다. -
We can also utilize the
UPDATEcommand to update your data. -
For example, you can execute
UPDATE favorites SET language = 'C++' WHERE language = 'C';. This will result in overwriting all previous statements where C was the favorite programming language. 따라서 기존 데이터를 백업해두고 이 명령어를 실행하는 것을 권장한다. 그리고 코드 실행 전 두번 세번 확인하고 실행해라 -
Notice that these queries have immense power. Accordingly, in the real-world setting, you should consider who has permissions to execute certain commands.
-
DELETEallows you to delete parts of your data. For example, you couldDELETE FROM favorites WHERE problem = 'Tideman';.
IMDb
-
IMDb offers a database of people, shows, writers, starts, genres, and ratings. Each of these tables is related to one another as follows:
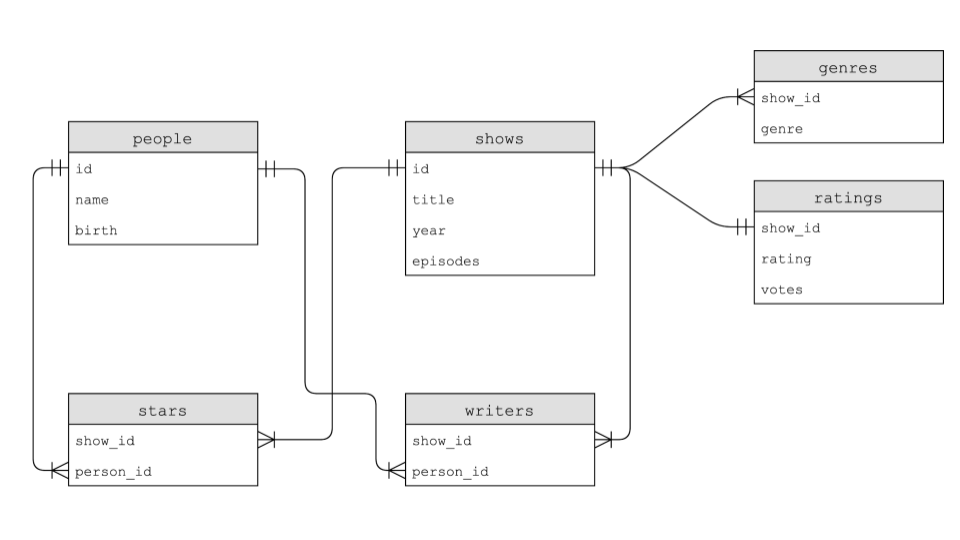
-
After downloading
shows.db, you can executesqlite3 shows.dbin your terminal window. -
Upon executing
.schemayou will find not only each of the tables but the individual fields inside each of these fields. -
As you can see by the image above,
showshas anidfield. Thegenrestable has ashow_idfield which has data that is common between it and theshowstable. -
As you can see also in the image above,
show_idexists in all of the tables. In theshowstable, it is simply calledid. This common field between all the fields is called a key. Primary keys are used to identify a unique record in a table. Foreign keys are used to build relationships between tables by pointing to the primary key in another table. -
By storing data in a relational database, as above, data can be more efficiently stored.
-
In sqlite, we have five datatypes, including:
BLOB -- binary large objects that are groups of ones and zeros INTEGER -- an integer NUMERIC -- for numbers that are formatted specially like dates (standardized form) REAL -- like a float TEXT -- for strings and the like -
Additionally, columns can be set to add special constraints:
NOT NULL : null값은 해당 열에 포함될 수 없다. UNIQUE : 이 열 안의 모든 데이터는 unique해야 함 -
아래는 shows.db의 schema이다.
``` CREATE TABLE genres ( show_id INTEGER NOT NULL, genre TEXT NOT NULL, FOREIGN KEY(show_id) REFERENCES shows(id) ); CREATE TABLE people ( id INTEGER, # 정수 name TEXT NOT NULL, # Text이고 빈칸이 없어야 함 birth NUMERIC, # 지정된 형식(날짜, 시간 등) 데이터 PRIMARY KEY(id) # id를 people 표의 기본키로 지정 ); CREATE TABLE ratings ( show_id INTEGER NOT NULL, rating REAL NOT NULL, votes INTEGER NOT NULL, FOREIGN KEY(show_id) REFERENCES shows(id) # show_id 외래키 ); CREATE TABLE shows ( id INTEGER, title TEXT NOT NULL, year NUMERIC, episodes INTEGER, PRIMARY KEY(id) # id를 기본키로 지정 ); CREATE TABLE stars ( show_id INTEGER NOT NULL, person_id INTEGER NOT NULL, FOREIGN KEY(show_id) REFERENCES shows(id), # show_id 외래키 FOREIGN KEY(person_id) REFERENCES people(id) # person_id 외래키 ); CREATE TABLE writers ( show_id INTEGER NOT NULL, person_id INTEGER NOT NULL, FOREIGN KEY(show_id) REFERENCES shows(id), FOREIGN KEY(person_id) REFERENCES people(id) ); ``` -
To illustrate the relationship between these tables further, we could execute the following command:
SELECT * FROM people LIMIT 10;. Examining the output, we could executeSELECT * FROM shows LIMIT 10;. Further, we could executeSELECT * FROM stars LIMIT 10;.show_idis a foreign key in this final query becauseshow_idcorresponds to the uniqueidfield inshows.person_idcorresponds to the uniqueidfield in thepeoplecolumn. -
We can further play with this data to understand these relationships. Execute
SELECT * FROM genres;. There are a lot of genres! -
We can further limit this data down by executing
SELECT * FROM genres WHERE genre = 'Comedy' LIMIT 10;. From this query, you can see that there are 10 shows presented. -
You can discover what shows these are by executing
SELECT * FROM shows WHERE id = 626124;-> 이런건 실수를 하기 매우 좋은 작업이다. -
We can further our query to be more efficient by executing
SELECT title FROM shows WHERE id IN ( SELECT * FROM genres WHERE genre = 'Comedy' ) LIMIT 10;Notice that this query nests together two queries. An inner query is used by an outer query.
-
We can refine further by executing
SELECT title FROM shows WHERE id IN ( SELECT * FROM genres WHERE genre = 'Comedy' ) ORDER BY title LIMIT 10; -
What if you wanted to find all shows in which Steve Carell stars? You could execute
SELECT * FROM people WHERE name = 'Steve Carell';You would find his individualid. You could utilize thisidto locate manyshowsin which he appears. However, this would be tedious to attempt this one by one. How could we next our queries to make this more streamlined? Consider the following:SELECT title FROM shows WHERE id IN (SELECT show_id FROM stars WHERE person_id = (SELECT * FROM people WHERE name = 'Steve Carell'));Notice that this lengthy query will result in a final result that is useful in discovering the answer to our question. 참고로 위의 코드에서
IN과=의 차이는 다음과 같다:IN은 오른쪽에 오는 것이 여러개(show_id는 여러개임)일 때 사용하고,=은 오른쪽에 오는 것이 단 하나일 때 사용함(person_id와 'Steve Carell'은 단 하나뿐인 값임).
JOINs
-
Consider the following two tables:
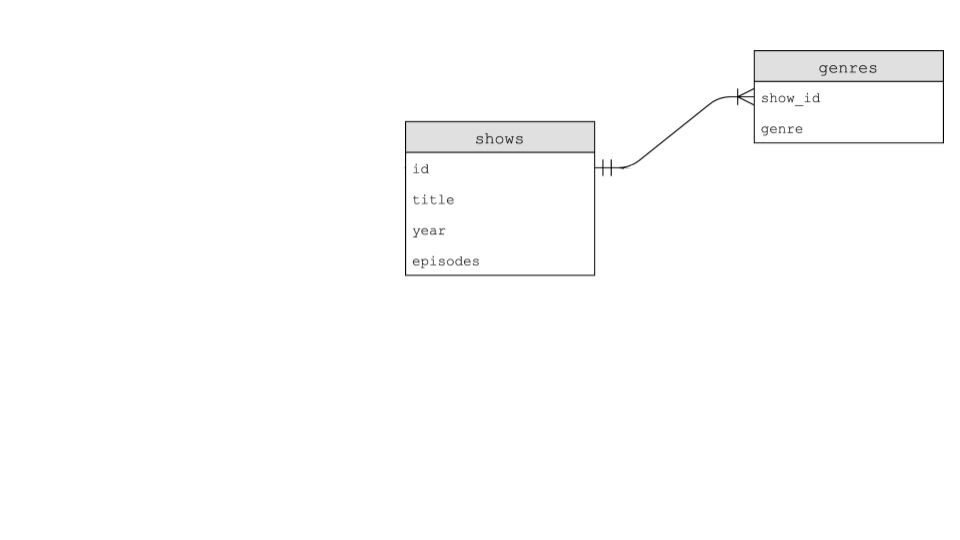
-
How could we combine tables temporarily? Tables could be joined together using the
JOINcommand. -
Execute the following command:
SELECT * FROM shows JOIN ratings ON shows.id = ratings.show_id WHERE title = 'The Office'; -
Now you can see all the shows that have been called The Office.
-
저 위의 코드 읽는 방법:
SELECT * FROM+shows JOIN ratings(shows와 ratings 테이블 병합) +ON shows.id = ratings.show_id(병합기준: show id) +WHERE title = 'The Office -
ratings.show_id: ratings 표의 show.id,shows.id: shows 표의 id -
You could similarly apply
JOINto our Steve Carell query above by executing the following:SELECT title FROM people JOIN stars ON people.id = stars.person_id JOIN shows ON stars.show_id = shows.id WHERE name = `Steve Carell`;Notice how each
JOINcommand tells us which columns are aligned to each which other columns. (위 코드는 3개의 표: people, stars, shows를 병합한다) -
This could be similarly implemented as follows (implicit join):
SELECT title FROM people, stars, shows WHERE people.id = stars.person_id AND stars.show_id = shows.id AND name = 'Steve Carell';Notice that this achieves the same results.
cf. code includingJOIN: Explicit join -
The wildcard
%operator can be used to find all people whose names start withSteve Cone could employ the syntaxSELECT * FROM people WHERE name LIKE 'Steve C%';. 와일드 카드를 사용할 때는=대신LIKE를 사용한다.
Indexes
-
While relational databases have the ability to be more fast and more robust than utilizing a
CSVfile, data can be optimized within a table using indexes. -
Indexes can be utilized to speed up our queries.
-
선형검색을 하는 것이 sqlite의 default 설정이지만, 인덱스를 도입하면 탐색시간이 log n에 가까워진다.
-
We can track the speed of our queries by executing
.timer oninsqlite3. -
To understand how indexes can speed up our queries, run the following:
SELECT * FROM shows WHERE title = 'The Office';Notice the time that displays after the query executes. -
Then, we can create an index with the syntax
CREATE INDEX title_index on shows (title);. This tellssqlite3to create an index and perform some special under-the-hood optimization relating to this columntitle. -
This will create a data structure called a B Tree, a data structure that looks similar to a binary tree. However, unlike a binary tree, there can be more than two child notes.
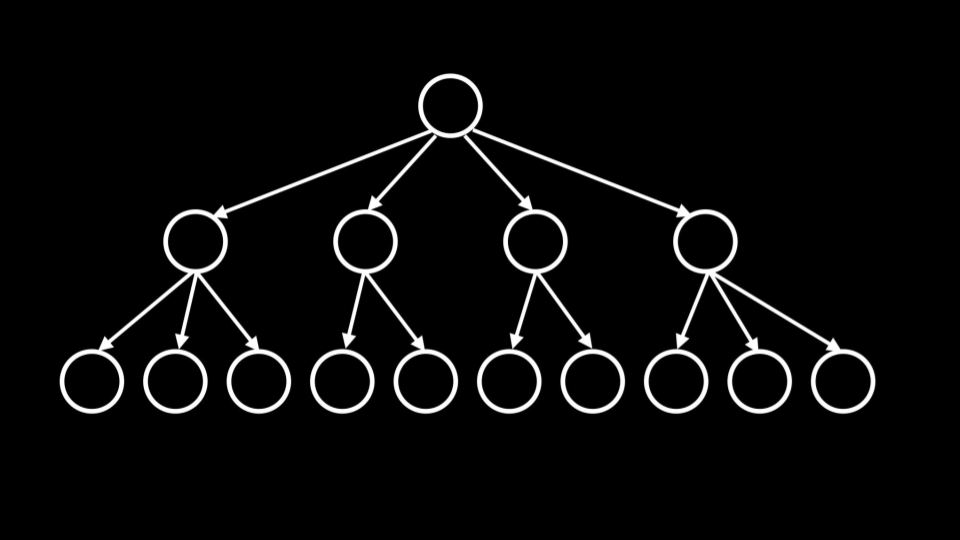
-
위와 같은 B-tree는 이진트리보다 자식노드가 많아서 자료구조가 wide한 대신, 트리의 위아래 길이가 짧다. 따라서 데이터를 검색하는 시간이 매우 짧다.
-
Running the query
SELECT * FROM shows WHERE title = 'The Office';, you will notice that the query runs much more quickly! : 인덱싱 전의 실행시간은0.035초인데 반해 인덱싱 후의 실행시간은0.001초임! -
Unfortunately, indexing all columns would result in utilizing more storage space. Therefore, there is a tradeoff for enhanced speed. 따라서 실행시간을 완벽히 줄이겠다고 모든 열을 인덱싱하는.. 그런 짓은 할 수 없다.
Using SQL in Python
-
To assist in working with SQL in this course, the CS50 Library can be utilized as follows in your code:
from cs50 import SQL -
Similar to previous uses of the CS50 Library, this library will assist with the complicated steps of utilizing SQL within your Python code. SQL을 파이썬에서 사용할 수 있도록 하는 다른 서드파티 라이브러리도 있긴 한데 초보자 수준에서 사용하긴 어렵다. 그래서 보조적으로 라이브러리 제공하는듯함.
-
You can read more about the CS50 Library’s SQL functionality in the documentation.
-
Recall where we last left off in
favorites.py. Your code should appear as follows:# Favorite problem instead of favorite language import csv # Open CSV file with open("favorites.csv", "r") as file: # Create DictReader reader = csv.DictReader(file) # Counts counts = {} # Iterate over CSV file, counting favorites for row in reader: favorite = row["problem"] if favorite in counts: counts[favorite] += 1 else: counts[favorite] = 1 # Print count favorite = input("Favorite: ") if favorite in counts: print(f"{favorite}: {counts[favorite]}") -
Modify your code as follows:
# Searches database popularity of a problem import csv from cs50 import SQL # Open database db = SQL("sqlite:///favorites.db") # Prompt user for favorite favorite = input("Favorite: ") # Search for title rows = db.execute("SELECT COUNT(*) FROM favorites WHERE problem LIKE ?", "%" + favorite + "%") #SQL문법을 text(string)취급해서 함수에 집어넣음. favorite은 변수이므로 따로 결합해준다. # SQL 명령문에 변수를 넣을 때 절대 f-string 형식으로 넣으면 안됨(해킹 위험 있음). # db.execute는 딕셔너리를 반환한다 (키:header of colunms, 값: data) # 위 명령어를 실행해 나오는 표의 header명은 COUNT(*)가 된다. 이걸 계속 쓰기 귀찮으면 "SELECT COUNT(*) AS n FROM favorites WHERE problem LIKE..."라고 n으로 헤더명을 대체해도 된다. # Get first (and only) row row = rows[0] # Print popularity print(row["COUNT(*)"])Notice that
db = SQL("sqlite:///favorites.db")provide Python the location of the database file. Then, the line that begins withrowsexecutes SQL commands utilizingdb.execute. Indeed, this command passes the syntax within the quotation marks to thedb.executefunction. We can issue any SQL command using this syntax. Further, notice thatrowsis returned as a list of dictionaries. In this case, there is only one result, one row, returned to the rows list as a dictionary.
Race Conditions
- Utilization of SQL can sometimes result in some problems.
- You can imagine a case where multiple users could be accessing the same database and executing commands at the same time.
- This could result in glitches where code is interrupted by other people’s actions. This could result in a loss of data.
- 인스타그램의 인기 게시물에 여러 사람들이 한꺼번에 좋아요를 눌렀다고 가정하자. 한 사람이 좋아요를 누를 때 게시물 안에서 일어나는 일을 작성하는 파이썬 코드가 다음과 같다고 가정하자.
```py rows = db.execute("SELECT likes FROM posts WHERE id = ?", id); likes = rows[0]["likes"] #[0]은 행, ["likes"]는 열의 인덱스다. db.execute("UPDATE posts SET likes = ? WHERE id = ?", likes+1, id); ``` - A와 B가 동시에 좋아요를 눌렀을 때, 위의 코드는 서로 다른 서버에서 작동된다고 해도 현재 likes의 값을 참조하기 때문에 `A서버가 참조한 현재 likes = B서버가 참조한 현재 likes = n`인 경우가 생길 수 있다. 이런 경우, 두 명이 좋아요를 눌러도 새로 업데이트된 좋아요 수는 `n+1`이 된다. 이걸 "race condition"이라고 한다. - 만약 좋아요 수로 게시물을 올린 사람의 수익이 결정된다면 이건 굉장히 나쁜 상황이 된다. - 왜 이런 상황이 생기는 걸까? (아주 간발의 차라고 해도) 후발주자가 현재 좋아요 값을 참조할 때, 그 좋아요 값이 선발주자에 의해 업데이트될 값이라는 것을 모르기 때문에 그렇다. - Built-in SQL features such as
BEGIN TRANSACTION,COMMIT, andROLLBACKhelp avoid some of these race condition problems. 이 방법을 이용해 위의 인스타그램 코드를 수정해보자db.execute("BEGIN TRANSACTION") rows = db.execute("SELECT likes FROM posts WHERE id = ?", id); likes = rows[0]["likes"] db.execute("UPDATE posts SET likes = ? WHERE id = ?", likes+1, id); db.execute("COMMIT")- 이 코드는 위의 세줄짜리 코드를
BEGIN TRANSACTION과COMMIT코드로 감싼 것이다. 이 상태를 "atomic"하다고 한다. - atomic은 모두 실행되거나, 모두 실행되지 않는 상태를 뜻한다.
- 이 코드는 위의 세줄짜리 코드를
SQL Injection Attacks
-
Now, still considering the code above, you might be wondering what the
?question marks do above. One of the problems that can arise in real-world applications of SQL is what is called an injection attack. An injection attack is where a malicious actor could input malicious SQL code. -
For example, consider a login screen as follows:
-
Without the proper protections in our own code, a bad actor could run malicious code. Consider the following:
rows = db.execute("SELECT COUNT(*) FROM favorites WHERE problem LIKE ?", "%" + favorite + "%")Notice that because the
?is in place, validation can be run onfavoritebefore it is blindly accepted by the query. -
You never want to utilize formatted strings in queries as above or blindly trust the user’s input.
--는 SQL에서 주석을 표시하는 문법이다.db.execute(f"SELECT * FROM users WHERE username = '{username}' AND password = '{password}'")라는 명령문으로 id와 비번을 잘 입력했는지 확인한다고 하자.- 나쁜 사람이 id로
malan@havard.edu'--입력했다. 그럼 위의 명령문은 아래와 같이 된다. db.execute(f"SELECT * FROM users WHERE username = 'malan@havard.edu'--' AND password = '{password}'"): 'malan@havard.edu'까지 올바른 문법이 되고, -- 이후로는 모두 주석처리가 된다. 따라서 비번을 뭘로 쳤든 그냥 로그인되어버린다.
-
Utilizing the CS50 Library(or third party library), the library will sanitize and remove any potentially malicious characters. -> 즉 ?를 이용해 변수를 쿼리문에 넣으면, 그 변수가 쿼리문 안에 들어가기 전에 라이브러리에서 알아서 그 변수값에 위험한 문자가 있는지 검사한다.
-
BOBBY Table: SQL Injection을 피하는 방법을 알려주는 가이드 사이트임. 참고하쇼
Summing Up
In this lesson, you learned more syntax related to Python. Further, you learned how to integrate this knowledge with data in the form of flat-file and relational databases. Finally, you learned about SQL. Specifically, we discussed…
- Flat-file databases
- Relational databases
- SQL
JOINs- Indexes
- Using SQL in Python
- Race conditions
- SQL injection attacks
See you next time!
