1. Introduction
프로젝트에서 구현하기로 한 논문(https://www.sciencedirect.com/science/article/pii/S2666521222000333?via%3Dihub#abs0015)은 데이터(MIT-BIH database, PTB-DB dataseet) 로드 후 전처리가 진행된다. 위 논문에서 데이터 전처리는 대략적으로 'Annotation,Visualization -> QRS complex detection -> Data augmentation -> Data subdivision'의 단계들을 거친다.
이 중 Data augmentation 과정에서는 'One-hot-encoding'이라는 encoding method가 사용되는데, 전처리 코드를 작성하다가 논문 리뷰때 이 부분은 간단하게만 보고 넘어갔던 기억이 나서 해당 부분을 공부해보고 정리하였다.
2. Encoding Method
우선 인코딩이란 사람의 언어를 약속된 규칙에 따라 컴퓨터가 이해하는(0과 1로 이루어진) 언어로 바꾸는 것을 통틀어 일컫는다. 즉, 일정한 규칙에 따라 '암호화, 부호화, 코드화' 하는 것을 말한다. (반대로 디코딩은 이와 반대되는 개념으로 '역코드화'의 의미를 지닌다.)
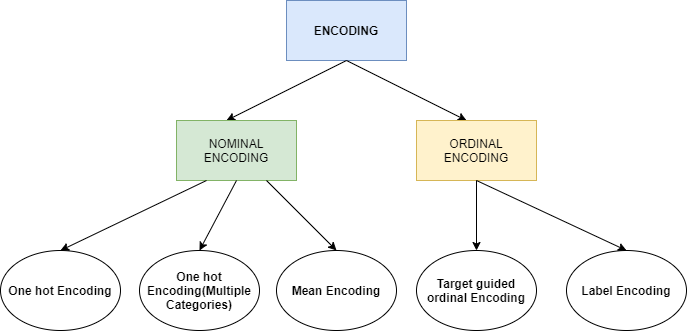
인코딩의 종류는 다양하며 아래 사진처럼 분류해 볼 수도 있다.
프로젝트를 진행 때 구현할 논문('A new vision of a simple 1D Convolutional Neural Networks (1D-CNN) with Leaky-ReLU function for ECG abnormalities classification')에서는 이 중 원-핫-인코딩 방식을 다루고 있어 그에 대해 더 알아봤다.
3. One-hot-encoding
3-1. Definition
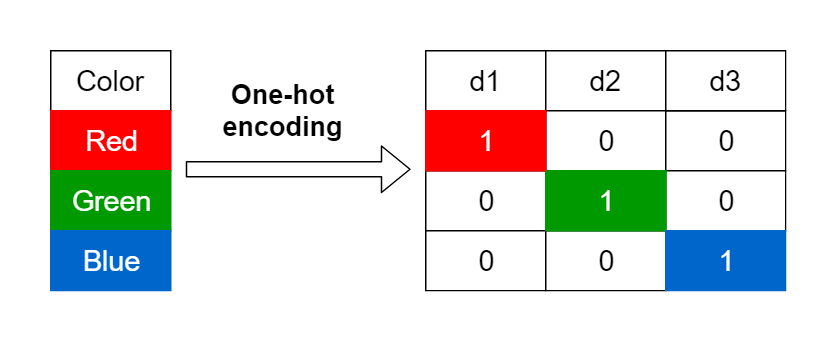
feature값의 유형에 따라 새로운 feature를 추가하고, 고유 값에 해당하는 column에만 1을 표시하고 나머지 값들은 모두 0을 갖게하는 방식으로 범주형 데이터를 수치형 데이터로 변환하는 방법 중 하나이다.
3-2. Necessity
범주형 데이터를 수치형 데이터로 변환하는 방법들 중 원-핫-인코딩의 필요성에 대해 알아보았다.
예를 들어 '컴퓨터=1, 키보드=2, 마우스=3'으로 하여 범주형 데이터를 각각 숫자에 대응시킨다고 해보자. 이 방식을 통해 각 데이터들을 숫자로 대응시키고 프로젝트를 진행하게 되면 문제가 생긴다.
대표적으로 키보드(2)를 컴퓨터(1)와 마우스(3)의 중간이라고 할 수 있을까? 또, 만약 모델이 '2.7'이라는 결과를 출력했을 경우, 이 데이터에 대해 '키보드와 마우스 사이의 어떤 값인데 마우스에 더 가깝다'와 같은 해석이 가능한 것인가와 같은 한계점들도 생긴다.
결론적으로 범주형 데이터들을 임의의 숫자들에 각각 대응시키다보면, 연속적이지 않으며 순서가 없는 범주형 데이터의 특성에 의해 데이터 해석에 문제가 생긴다.
이에 대한 해결책으로 이용될 수 있는 one-hot-encoding은 하나의 값만 1을 가지고 나머지 값들은 모두 0을 가지는 데이터로, 1값의 위치가 해당 데이터가 어떤 범주에 속하는지를 의미하게 된다.
3-3. One-hot-encoding 코드 구현
(1) sklearn
- 사이킷런의 OneHotEncoder 클래스로 가능
- 2차원 데이터가 입력값으로 필요
- 변환값을 다시 'toarray()' method를 이용해 밀집행렬로 변환해야함.(변환값이 희소행렬 형태이므로)
(2) pandas
- sklearn에서 하는 변환하는 과정을 거칠 필요 없음
- 'get_dummies()' method 사용
- 문자열 카테고리 값을 바로 변환 가능(숫자형으로 변환할 필요 없음)
import pandas as pd
df = pd.Dataframe({'item':['컴퓨터', '키보드', '마우스']})
pd.get_dummies(df)