1. Introduction
1-1. Pytorch는...
GPU와 CPU를 사용하는 딥 러닝에 최적화된 텐서 라이브러리
-> 최신 연구 환경에서 지배적, 커뮤니티에서 널리 채택되고 대부분의 출판물/사용 가능한 모델에서 사용
1-2. colab 사용시 import 코드
!pip install torch
import numpy as np
import torch2. Tensor
2-1. Tensor란?
Numpy의 배열과 유사한 자료형으로 다차원의 행렬. (=n차원의 행렬)
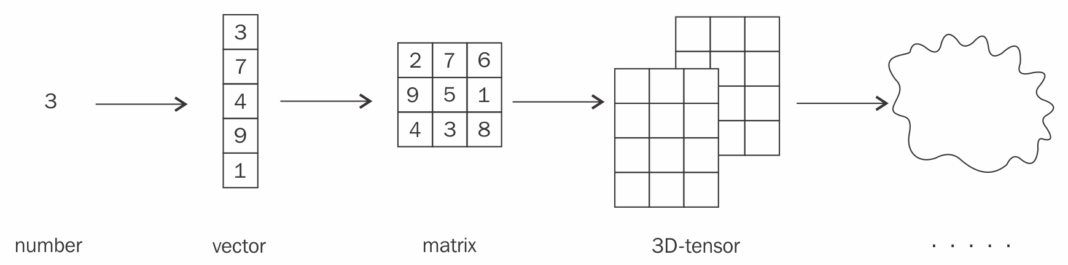
ex) 0D Tensor(Scalar), 1D Tensor(Vector), 2D Tensor(Matrix), 3D부터는 주로 그냥 Tensor라 칭함.
2-2. Tensor생성 코드들
torch.ones() ## 각 element가 1인 tensor를 만들어줌
torch.zeros() ## 각 element가 0인 tensor를 만들어줌
torch.arange() ## 주어진 범위 내의 정수를 순서대로 생성
torch.rand() ## 0과 1사이의 uniform dist에서 난수를 생성해서 tensor로 만들어줌
torch.ones_like() ## 기존의 tensor와 같은 모양의 원소가 1인 tensor를 만들어줌
torch.zeros_like() ## 기존의 tensor와 같은 모양의 원소가 0인 tensor를 만들어줌
-> 'ones'나 'zeros'대신 다른 들어가도 적용되어 기존의 tensor와 같은 모양의 입력된 숫자를 원소로 갖는 tensor를 만들어줌
2-3. Tensor.device
## 현재 해당 tensor가 어느 device에 있는지 확인
a = torch.tensor([1,2,3])
a.device
## 현재 GPU를 사용할 수 있는 환경인지 확인
torch.cuda.is_available()
## GPU 이름 체크(cuda: 0에 연결된 그래픽 카드 기준)
torch.cuda.get_device_name(device=0)
## 사용 가능한 GPU의 개수 체크
torch.cuda.device_count()
## tensor를 GPU에 할당(2가지 방법 존재)
a = torch.tensor([1., 2., 3.]).cuda()
b = torch.tensor([1., 2., 3.]).to("cuda")
이후 'a.device'나 'b.device'코드를 실행하면 첫 번째 GPU에 올라간 것을 확인할 수 있음. (코드 실행했을 때 결과: device(type='cuda', index=0 )CUDA(Compute Unified Device Architecture): GPU(그래픽 처리 장치)에서 수행하는 병렬처리 알고리즘을 산업 표준언어를 사용하여 작성할 수 있게 하는 GPGPU기술.
2-4. nn.Module() - Neural Network Class 생성
'nn.Module()' -> 모든 neural network 모형의 기본이 되며, 각 layer의 함수와 신경망 구조를 정의할 때 사용한다.
## 'torch.nn' : neural network 설계할 때 필요한 대부분의 기본적인 layer 구조를 제공해줌
import torch.nn as nn
class MyLinear(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.W = torch.FloatTensor(input_dim, output_dim)
self.b = torch.FloatTensor(output_dim)
def forward(self,x): ## input으로 x받음
## matmul: input으로 받은 x와 위에 선언해놓은 weight matrix를 matrix multiplication 해줌
y = torch.matmul(x, self.W) + self.b

🍮